PCCL: Process Group-Aware Scalable and Generic Collective Algorithm Synthesizer
Pith reviewed 2026-06-27 21:06 UTC · model grok-4.3
The pith
PCCL synthesizes near-optimal topology-aware collective algorithms for arbitrary process groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
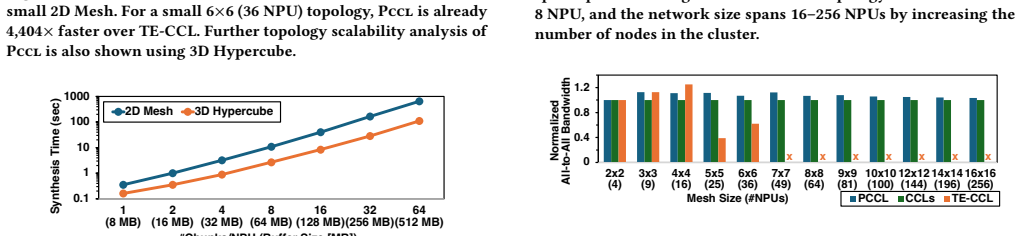
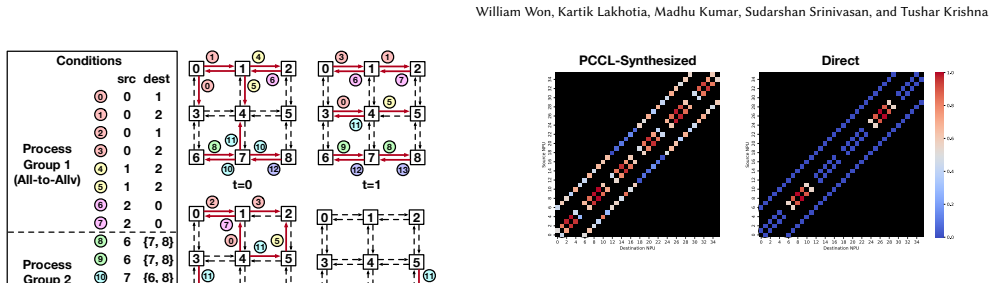
PCCL is a scalable and generic framework for synthesizing topology-aware collective algorithms. PCCL is process group-aware and capable of generating near-optimal collective algorithms even when only a subset of devices participates in collective operations. PCCL synthesizes arbitrary collective patterns, including 512-NPU All-to-All synthesis in 11.68 minutes.
What carries the argument
PCCL, the process group-aware synthesis framework that generates topology-aware collective algorithms for device subsets without exhaustive search.
If this is right
- Collective algorithms become available for process groups of any size without custom redesign.
- Arbitrary collective patterns can be synthesized efficiently at large scale.
- Communication bottlenecks in distributed training can be reduced by using subset-specific algorithms.
- Synthesis time stays practical even for configurations with hundreds of devices.
Where Pith is reading between the lines
- The method could support dynamic changes to process groups during a single training run.
- Integration with existing libraries might allow automatic replacement of default collectives.
- Similar synthesis ideas could apply to other communication primitives such as point-to-point messaging in heterogeneous clusters.
Load-bearing premise
The synthesis procedure can produce algorithms that remain near-optimal when restricted to arbitrary process groups without requiring exhaustive search or full knowledge of every possible subset configuration.
What would settle it
Measure the communication latency of the algorithm PCCL produces for a 512-NPU All-to-All on the target hardware topology and compare it directly against the latency of a hand-optimized or exhaustively searched baseline for the same subset.
Figures
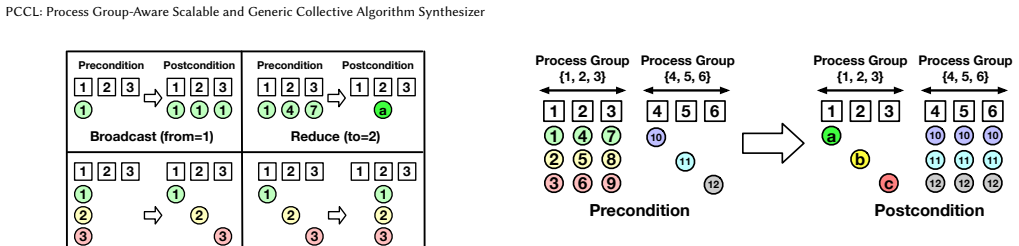

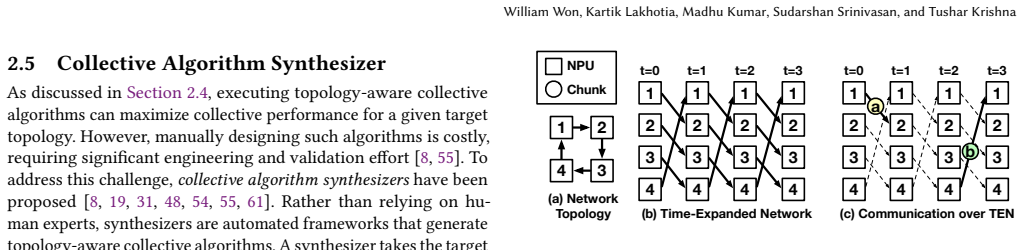


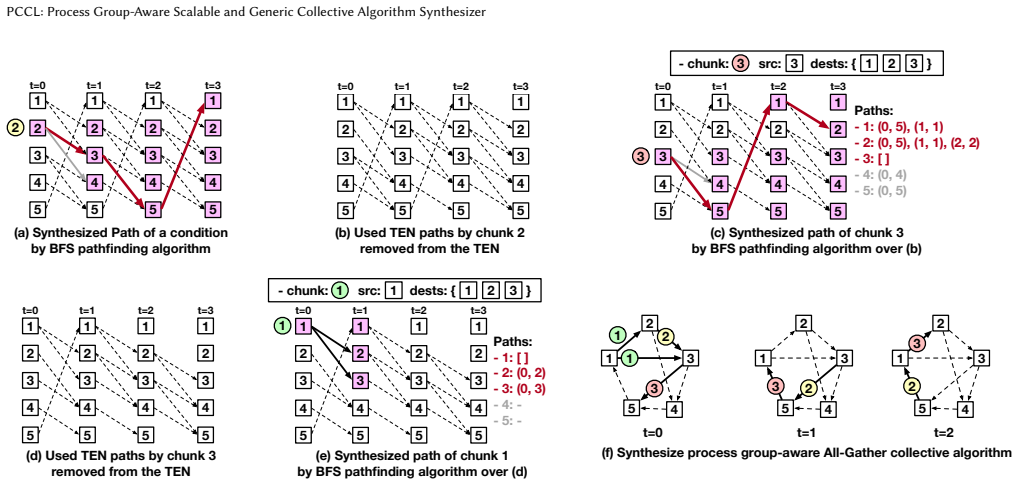



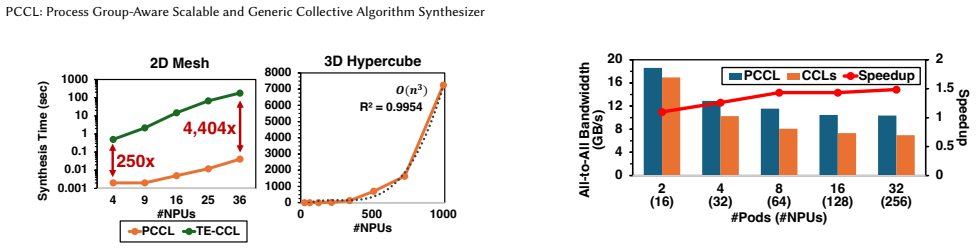


read the original abstract
Distributed machine learning has become increasingly important due to the massive scale of large-scale generative models. Both model parameters and data are distributed across many compute devices, which requires frequent collective communications to synchronize activations and parameter updates. Such collective communications have become a major bottleneck. While the performance of the collective algorithm depends on the physical network topology, the baseline collective algorithms in collective communication libraries are largely topology-agnostic. Collective algorithm synthesizers address this inefficiency by automatically generating topology-aware collective algorithms. However, prior works have largely overlooked that collective communication typically occurs only among a subset of devices, known as process groups. Additionally, most existing synthesizers are limited in the range of target collective patterns they can generate. We propose PCCL, a scalable and generic framework for synthesizing topology-aware collective algorithms. PCCL is process group-aware and capable of generating near-optimal collective algorithms even when only a subset of devices participates in collective operations. PCCL synthesizes arbitrary collective patterns, including 512-NPU All-to-All synthesis in 11.68 minutes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PCCL, a scalable and generic framework for synthesizing topology-aware collective algorithms for distributed ML. PCCL is process group-aware, generates near-optimal algorithms even when only a subset of devices participates, and supports arbitrary collective patterns, with a reported example of 512-NPU All-to-All synthesis completed in 11.68 minutes.
Significance. If the near-optimality claims hold under the stated constraints, PCCL would address an important gap in prior collective synthesizers by handling process groups and arbitrary patterns, potentially yielding practical performance gains in large-scale systems where subset communications are common. The reported synthesis time for a large All-to-All instance demonstrates scalability.
major comments (2)
- [Abstract] Abstract: the central claim that PCCL produces near-optimal algorithms for arbitrary process groups lacks any described evaluation methodology, baselines, or error analysis, preventing assessment of whether the synthesis procedure actually maintains optimality when the active set is a sparse or irregular subset.
- [Abstract] Abstract: no information is given on how process-group constraints are encoded into the search space or objective function; without this, it is impossible to verify that the near-optimality guarantee does not implicitly rely on full-mesh assumptions or exhaustive enumeration, which is load-bearing for the process-group-aware contribution.
minor comments (1)
- The abstract would be strengthened by a one-sentence outline of the internal representation or search technique used by PCCL.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on the abstract. The points raised correctly identify that the abstract's brevity leaves key aspects of the process-group-aware claims without supporting detail. We will revise the abstract to incorporate concise descriptions of the evaluation methodology and constraint encoding, while ensuring the full manuscript already provides the necessary depth in later sections. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PCCL produces near-optimal algorithms for arbitrary process groups lacks any described evaluation methodology, baselines, or error analysis, preventing assessment of whether the synthesis procedure actually maintains optimality when the active set is a sparse or irregular subset.
Authors: We agree the abstract does not describe the evaluation methodology. Section 5 of the manuscript presents the experimental methodology, including baselines (NCCL, prior synthesizers), test cases with sparse and irregular process groups, and quantitative error analysis relative to optimal bounds obtained via exhaustive search on smaller instances. We will revise the abstract to briefly reference this evaluation approach and the observed near-optimality results for subset communications. revision: yes
-
Referee: [Abstract] Abstract: no information is given on how process-group constraints are encoded into the search space or objective function; without this, it is impossible to verify that the near-optimality guarantee does not implicitly rely on full-mesh assumptions or exhaustive enumeration, which is load-bearing for the process-group-aware contribution.
Authors: Section 3 details the encoding: the search space is restricted to the induced topology of the active process group, and the objective function minimizes communication cost over only the participating devices without assuming a full mesh or performing exhaustive enumeration. The synthesis algorithm remains scalable by construction. We will add a short clarifying phrase to the abstract describing this encoding. revision: yes
Circularity Check
No circularity: new synthesis framework without load-bearing derivations or fitted predictions
full rationale
The paper presents PCCL as a new scalable framework for topology-aware collective algorithm synthesis that handles arbitrary process groups. No equations, fitted parameters, self-citations as uniqueness theorems, or ansatzes are described in the provided abstract or claims. The work is a systems contribution focused on synthesis procedure and empirical timing (e.g., 512-NPU All-to-All), not a derivation chain that reduces outputs to inputs by construction. This matches the default expectation of no significant circularity for such papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MPI 4.1. 2023. Introduction and Overview. https://www.mpi-forum.org/docs/ mpi-4.1/mpi41-report/node114.htm. William Won, Kartik Lakhotia, Madhu Kumar, Sudarshan Srinivasan, and Tushar Krishna
2023
-
[2]
ADC Telecommunications. 2009. Fundamentals of Ethernet Technology. https: //www.adckcl.com/in/en/library/White_Papers/Enterprise/401270IN.pdf
2009
-
[3]
AMD. 2020. AMD Infinity Fabric Link. https://www.amd.com/content/dam/ amd/en/documents/instinct-tech-docs/other/56978.pdf
2020
-
[4]
AMD. 2025. RCCL documentation. https://rocm.docs.amd.com/projects/rccl/en/ docs-6.3.3/index.html
2025
-
[5]
ASTRA-sim. [n. d.]. ASTRA-sim Validation. https://astra-sim.github.io/astra- sim-docs/validation/validation.html
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[7]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang
-
[8]
A Survey on Mixture of Experts in Large Language Models.IEEE Transac- tions on Knowledge and Data Engineering, 1–20. doi:10.1109/tkde.2025.3554028
-
[9]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madanlal Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing optimal collective algorithms. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming(Virtual Event, Republic of Korea)(PPoPP ’21). Association for Computing Machinery, New York, NY, ...
-
[10]
Jiamin Cao, Shangfeng Shi, Jiaqi Gao, Weisen Liu, Yifan Yang, Yichi Xu, Zhi- long Zheng, Yu Guan, Kun Qian, Ying Liu, Mingwei Xu, Tianshu Wang, Ning Wang, Jianbo Dong, Binzhang Fu, Dennis Cai, and Ennan Zhai. 2025. SyCCL: Exploiting Symmetry for Efficient Collective Communication Scheduling. In Proceedings of the ACM SIGCOMM 2025 Conference(New York, NY, ...
-
[11]
Cerebras. 2024. Cerebras Demonstrates Trillion Parameter Model Training on a Single CS-3 System - Cerebras. https://www.cerebras.ai/press-release/cerebras- demonstrates-trillion-parameter-model-training-on-a-single-cs-3-system
2024
-
[12]
M. Cho, U. Finkler, M. Serrano, D. Kung, and H. Hunter. 2019. BlueConnect: Decomposing all-reduce for deep learning on heterogeneous network hierarchy. IBM Journal of Research and Development63, 6 (2019), 1:1–1:11. doi:10.1147/JRD. 2019.2947013
work page doi:10.1147/jrd 2019
-
[13]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Se- bastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James B...
2023
-
[14]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft Collective Communication Language. In ASPLOS 2023(Vancouver, BC, Canada)(ASPLOS 2023). Association for Computing Machinery, New York, NY, USA, 502–514. doi:10.1145/3575693.3575724
-
[15]
Epoch AI. 2023. Key Trends and Figures in Machine Learning. https://epoch.ai/ trends. Accessed: 2025-04-11
2023
-
[16]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res.23, 1, Article 120 (Jan. 2022), 39 pages
2022
-
[17]
E. Gabrielyan and R.D. Hersch. 2003. Network topology aware scheduling of collective communications. InProceedings of the 10th International Conference on Telecommunications (ICT ’03). 1051–1058. doi:10.1109/ictel.2003.1191583
-
[18]
Roger W. Hockney. 1994. The communication challenge for MPP: Intel Paragon and Meiko CS-2.Parallel Comput.20, 3 (1994), 389–398. doi:10.1016/S0167- 8191(06)80021-9
-
[19]
Lee, Anjali Sridhar, Shruti Bhosale, Carole-Jean Wu, and Benjamin Lee
Haiyang Huang, Newsha Ardalani, Anna Sun, Liu Ke, Hsien-Hsin S. Lee, Anjali Sridhar, Shruti Bhosale, Carole-Jean Wu, and Benjamin Lee. 2023. Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference. In arXiv:2303.06182 [cs.DC]. https://arxiv.org/abs/2303.06182
arXiv 2023
-
[20]
Jiayi Huang, Pritam Majumder, Sungkeun Kim, Abdullah Muzahid, Ki Hwan Yum, and Eun Jung Kim. 2021. Communication Algorithm-Architecture Co-Design for Distributed Deep Learning. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). 181–194. doi:10.1109/ISCA52012. 2021.00023
-
[21]
Ian Cutress. 2019. Analyzing Intel’s Discrete Xe-HPC Graphics Disclosure: Ponte Vecchio, Rambo Cache, and Gelato. https://www.anandtech.com/show/15188/ analyzing-intels-discrete-xe-hpc-graphics-disclosure-ponte-vecchio/5
2019
-
[22]
Intel. 2021. Intel oneAPI Collective Communications Library. https://www.intel.com/content/www/us/en/docs/oneccl/developer-guide- reference/2021-15/overview.html
2021
-
[23]
Sylvain Jeaugey. 2019. Massively Scale Your Deep Learning Training with NCCL 2.4. https://developer.nvidia.com/blog/massively-scale-deep-learning-training- nccl-2-4/
2019
-
[24]
Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, Clifford Young, Xiang Zhou, Zongwei Zhou, and David A Patterson. 2023. TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. InProceedings of the 50th Annual Inter...
-
[25]
Dally, Steve Scott, and Dennis Abts
John Kim, Wiliam J. Dally, Steve Scott, and Dennis Abts. 2008. Technology- Driven, Highly-Scalable Dragonfly Topology. In2008 International Symposium on Computer Architecture. 77–88. doi:10.1109/ISCA.2008.19
-
[26]
B. Klenk, N. Jiang, G. Thorson, and L. Dennison. 2020. An In-Network Architec- ture for Accelerating Shared-Memory Multiprocessor Collectives. InProceedings of the 47th Annual International Symposium on Computer Architecture (ISCA ’20). 996–1009. doi:10.1109/isca45697.2020.00085
-
[27]
Sabuj Laskar, Pranati Majhi, Sungkeun Kim, Farabi Mahmud, Abdullah Muzahid, and Eun Jung Kim. 2024. Enhancing Collective Communication in MCM Accel- erators for Deep Learning Training. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 1–16. doi:10.1109/HPCA57654. 2024.00069
-
[28]
Kevin Lee and Shubho Sengupta. 2022. Introducing the AI Research SuperCluster — Meta’s cutting-edge AI supercomputer for AI research. https://ai.meta.com/ blog/ai-rsc/
2022
-
[29]
Yiran Lei, Dongjoo Lee, Liangyu Zhao, Daniar Kurniawan, Chanmyeong Kim, Heetaek Jeong, Changsu Kim, Hyeonseong Choi, Liangcheng Yu, Arvind Kr- ishnamurthy, Justine Sherry, and Eriko Nurvitadhi. 2025. FAST: An Efficient Scheduler for All-to-All GPU Communication. InarXiv:2505.09764(2025-10-10). arXiv. version: 2. arXiv:2505.09764 [cs] doi:10.48550/arXiv.2505.09764
-
[30]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala
-
[31]
PyTorch distributed: experiences on accelerating data parallel training. Proc. VLDB Endow.13, 12 (Aug. 2020), 3005–3018. doi:10.14778/3415478.3415530
-
[32]
Youjie Li, Iou-Jen Liu, Yifan Yuan, Deming Chen, Alexander Schwing, and Jian Huang. 2019. Accelerating Distributed Reinforcement Learning with In-Switch Computing. InProceedings of the 46th International Symposium on Computer Architecture (ISCA ’19). 279–291. doi:10.1145/3307650.3322259
-
[33]
Xuting Liu, Behnaz Arzani, Siva Kesava Reddy Kakarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth Kandula, and Luke Marshall. 2024. Rethinking Ma- chine Learning Collective Communication as a Multi-Commodity Flow Problem. InProceedings of the ACM SIGCOMM 2024 Conference(Sydney, NSW, Australia) (ACM SIGCOMM ’24). Association for Computing Machinery,...
-
[34]
Junchao Ma, Dezun Dong, Cunlu Li, Ke Wu, and Liquan Xiao. 2021. PAARD: Proximity-Aware All-Reduce Communication for Dragonfly Networks. In2021 IEEE Intl Conf on Parallel and Distributed Processing with Applications, Big Data and Cloud Computing, Sustainable Computing and Communications, So- cial Computing and Networking (ISPA/BDCloud/SocialCom/SustainCom)...
work page doi:10.1109/ispa-bdcloud-socialcom-sustaincom52081.2021.00045 2021
-
[35]
Mellanox Technologies. 2008. InfiniBand Technology Overview. https://network. nvidia.com/pdf/whitepapers/WP_InfiniBand_Technology_Overview.pdf
2008
-
[36]
Hiroaki Mikami, Hisahiro Suganuma, Pongsakorn U-chupala, Yoshiki Tanaka, and Yuichi Kageyama. 2019. Massively Distributed SGD: ImageNet/ResNet-50 Training in a Flash. InarXiv:1811.05233 [cs.LG]
Pith/arXiv arXiv 2019
-
[37]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient large-scale language model training on GPU clusters using megatron- LM. InProceedings of the International Conference for High ...
-
[38]
NVIDIA. 2025. NVIDIA Collective Communications Library. https://developer. nvidia.com/nccl
2025
-
[39]
NVIDIA. 2025. NVLink and NVLink Switch. https://www.nvidia.com/en-us/data- center/nvlink/. PCCL: Process Group-Aware Scalable and Generic Collective Algorithm Synthesizer
2025
-
[40]
Anselm Paulus, Michal Rolínek, Vít Musil, Brandon Amos, and Georg Martius
-
[41]
InProceedings of the 38th International Conference on Machine Learning (ICML ’21), Vol
CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Pro- gramming Constraints. InProceedings of the 38th International Conference on Machine Learning (ICML ’21), Vol. 139. 8443–8453
-
[42]
Sundar Pichai and Demis Hassabis. 2024. Our next-generation model: Gemini 1.5. https://blog.google/technology/ai/google-gemini-next-generation-model- february-2024/
2024
-
[43]
Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, ...
Pith/arXiv arXiv 2022
-
[44]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed- MoE: Advancing Mixture-of-Experts Inference and Training to Power Next- Generation AI Scale. InarXiv:2201.05596 [cs.LG]. https://arxiv.org/abs/2201.05596
arXiv 2022
-
[45]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis(Atlanta, Georgia)(SC ’20). IEEE Press, Article 20, 16 pages
2020
-
[46]
Emil Rakadjiev, Taku Shimosawa, Hiroshi Mine, and Satoshi Oshima. 2015. Parallel SMT Solving and Concurrent Symbolic Execution. In2015 IEEE Trust- com/BigDataSE/ISPA, Vol. 3. 17–26. doi:10.1109/Trustcom.2015.608
-
[47]
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna
-
[48]
In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)
ASTRA-SIM: Enabling SW/HW Co-Design Exploration for Distributed DL Training Platforms. In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 81–92. doi:10.1109/ISPASS48437.2020. 00018
-
[49]
Saeed Rashidi, William Won, Sudarshan Srinivasan, Srinivas Sridharan, and Tushar Krishna. 2022. Themis: a network bandwidth-aware collective scheduling policy for distributed training of DL models. InProceedings of the 49th Annual International Symposium on Computer Architecture(New York, New York)(ISCA ’22). Association for Computing Machinery, New York,...
arXiv 2022
-
[50]
Amedeo Sapio, Marco Canini, Chen-Yu Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan R. K. Ports, and Peter Richtárik. 2019. Scaling Distributed Machine Learning with In-Network Aggregation. InarXiv:1903.06701 [cs.DC]
arXiv 2019
-
[51]
Justin Selig. 2022. The Cerebras Software Development Kit: A Technical Overview. https://f.hubspotusercontent30.net/hubfs/8968533/Cerebras%20SDK% 20Technical%20Overview%20White%20Paper.pdf?utm_campaign=Tech% 20Leadership%20PR%202022&utm_source=SDK_WP
arXiv 2022
-
[52]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh
-
[53]
In20th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 23)
TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches. In20th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 23). USENIX Association, Boston, MA, 593–612. https: //www.usenix.org/conference/nsdi23/presentation/shah
-
[54]
Aashaka Shah, Abhinav Jangda, Binyang Li, Caio Rocha, Changho Hwang, Jithin Jose, Madan Musuvathi, Olli Saarikivi, Peng Cheng, Qinghua Zhou, Roshan Dathathri, Saeed Maleki, and Ziyue Yang. 2025. MSCCL++: Rethinking GPU Com- munication Abstractions for Cutting-edge AI Applications. InarXiv:2504.09014 (2025-08-21). arXiv. arXiv:2504.09014 [cs] doi:10.48550/...
-
[55]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InarXiv:1701.06538 [cs.LG]. https: //arxiv.org/abs/1701.06538
Pith/arXiv arXiv 2017
-
[56]
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. 2005. Optimization of Collective Communication Operations in MPICH.Int. J. High Perform. Comput. Appl.19, 1 (Feb. 2005), 49–66. doi:10.1177/1094342005051521
-
[57]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. In arXiv:2302.13971 [cs.CL]. https://arxiv.org/abs/2302.13971
Pith/arXiv arXiv 2023
-
[58]
Rellermeyer
Joost Verbraeken, Matthijs Wolting, Jonathan Katzy, Jeroen Kloppenburg, Tim Verbelen, and Jan S. Rellermeyer. 2020. A Survey on Distributed Machine Learn- ing.ACM Comput. Surv.53, 2, Article 30 (March 2020), 33 pages. doi:10.1145/ 3377454
2020
-
[59]
Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee, Nikhil Devanur, Jorgen Thelin, and Ion Stoica. 2020. Blink: Fast and Generic Collectives for Distributed ML. InProceedings of Machine Learning and Systems, I. Dhillon, D. Papailiopoulos, and V. Sze (Eds.), Vol. 2. 172–186. https://proceedings.mlsys. org/paper_files/paper/2020/file/cd3a9a55f7f3723133fa...
2020
-
[60]
William Won, Midhilesh Elavazhagan, Sudarshan Srinivasan, Swati Gupta, and Tushar Krishna. 2024. TACOS: Topology-Aware Collective Algorithm Synthe- sizer for Distributed Machine Learning. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). 856–870. doi:10.1109/MICRO61859. 2024.00068
-
[61]
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. 2023. ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 283–294. doi:10.1109/ISPASS57527.2023.00035
-
[62]
William Won, Saeed Rashidi, Sudarshan Srinivasan, and Tushar Krishna. 2024. LIBRA: Enabling Workload-Aware Multi-Dimensional Network Topology Opti- mization for Distributed Training of Large AI Models. In2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 205–216. doi:10.1109/ISPASS61541.2024.00028
-
[63]
xAI. 2025. Colossus. https://x.ai/colossus
2025
-
[64]
Zikai Xiong. 2025. High-Probability Polynomial-Time Complexity of Restarted PDHG for Linear Programming. InarXiv:2501.00728 [math.OC]. https://arxiv. org/abs/2501.00728
arXiv 2025
-
[65]
Jinsun Yoo, William Won, Meghan Cowan, Nan Jiang, Benjamin Klenk, Srinivas Sridharan, and Tushar Krishna. 2024. Towards a Standardized Representation for Deep Learning Collective Algorithms. In2024 IEEE Symposium on High- Performance Interconnects (HOTI). 33–36. doi:10.1109/HOTI63208.2024.00017
-
[66]
Liangyu Zhao, Saeed Maleki, Ziyue Yang, Hossein Pourreza, and Arvind Kr- ishnamurthy. 2025. ForestColl: Throughput-Optimal Collective Communica- tions on Heterogeneous Network Fabrics. InarXiv:2402.06787 [cs.NI]. https: //arxiv.org/abs/2402.06787
arXiv 2025
-
[67]
Xiaoyang Zhao, Zhe Zhang, and Chuan Wu. 2024. AdapCC: Making Collective Communication in Distributed Machine Learning Adaptive. In2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS). 25–35. doi:10. 1109/ICDCS60910.2024.00012
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.