On the Geometry of On-Policy Distillation
Pith reviewed 2026-06-27 22:45 UTC · model grok-4.3
The pith
On-policy distillation follows its own update geometry in parameter space rather than sitting between supervised fine-tuning and reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
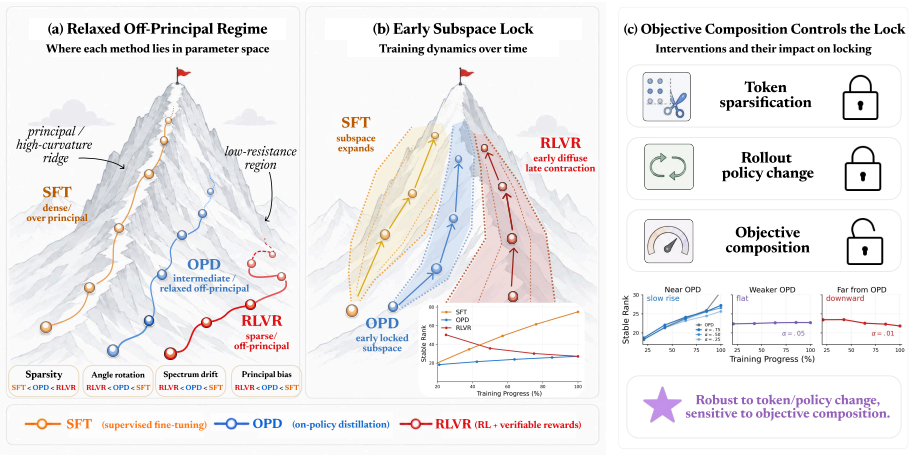
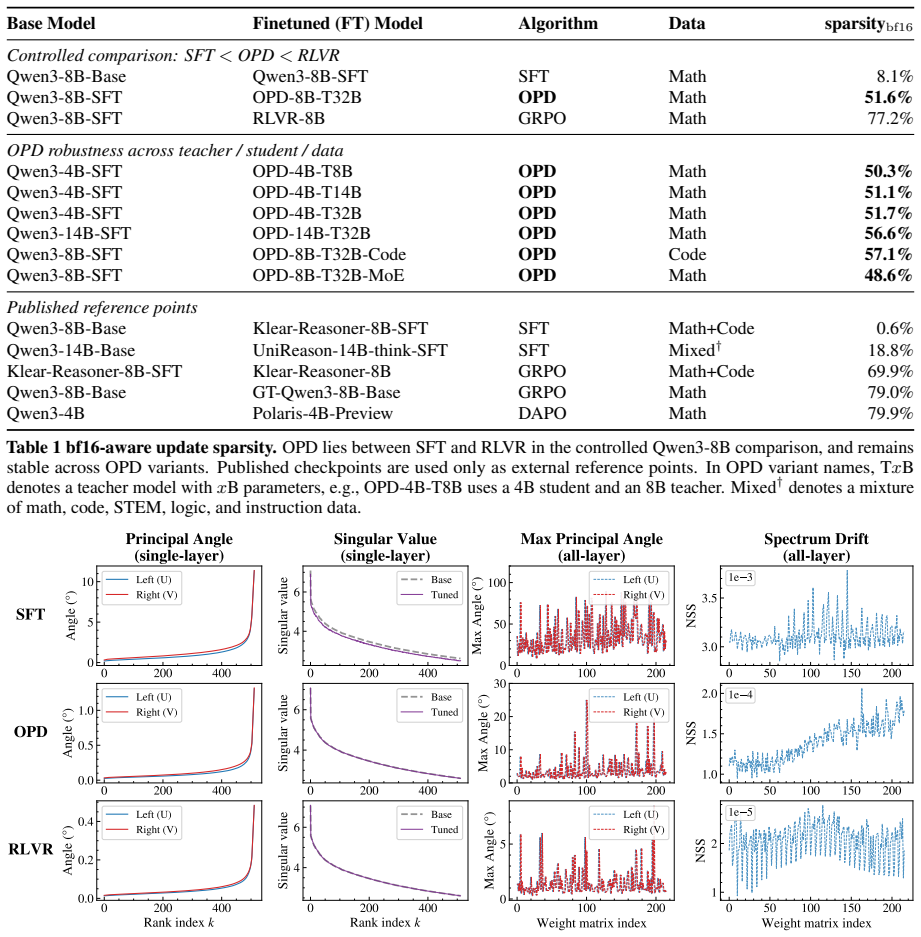
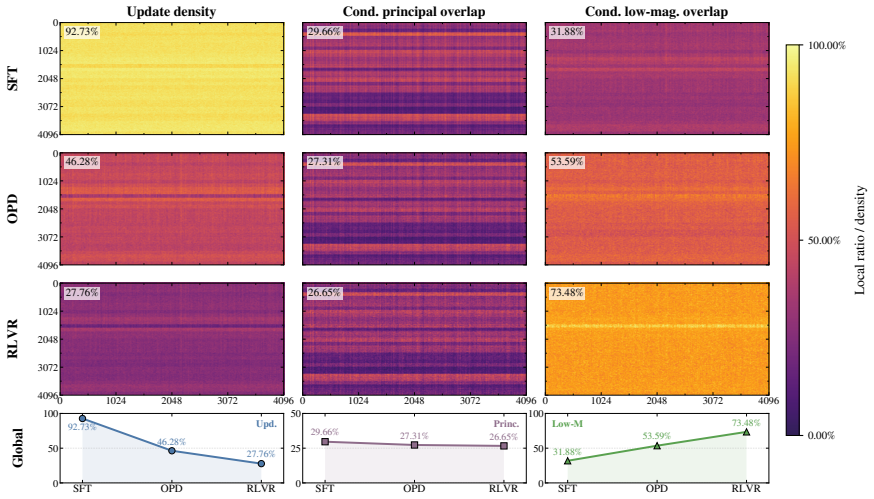
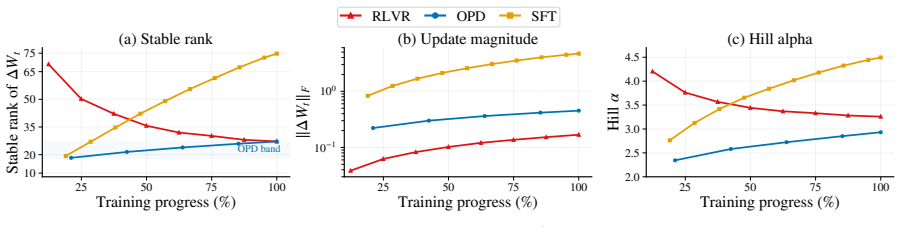
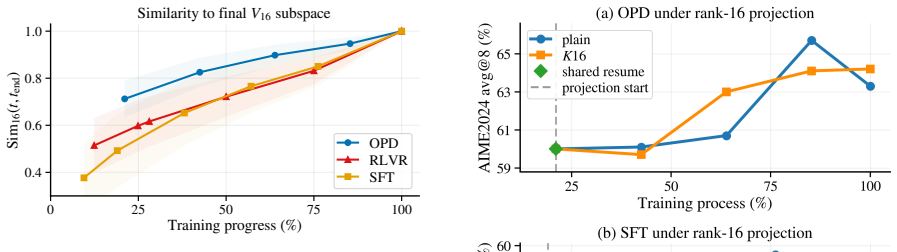
OPD induces its own update geometry in parameter space: its updates affect fewer weights and avoid principal directions more strongly than SFT while remaining less tightly constrained than RLVR, and they rapidly lock into a narrow low-dimensional subspace that is functionally sufficient for OPD performance.
What carries the argument
Subspace locking, in which cumulative OPD updates enter and remain inside a narrow low-dimensional channel early in training, as diagnosed by the number of affected weights, avoidance of principal directions, and subspace rank dynamics.
If this is right
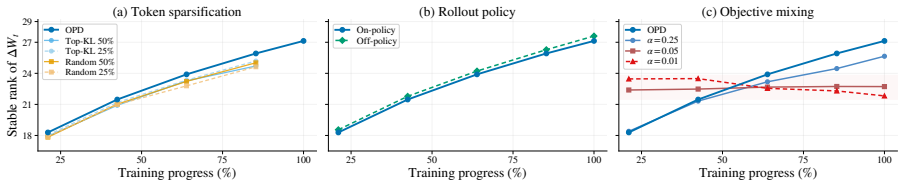
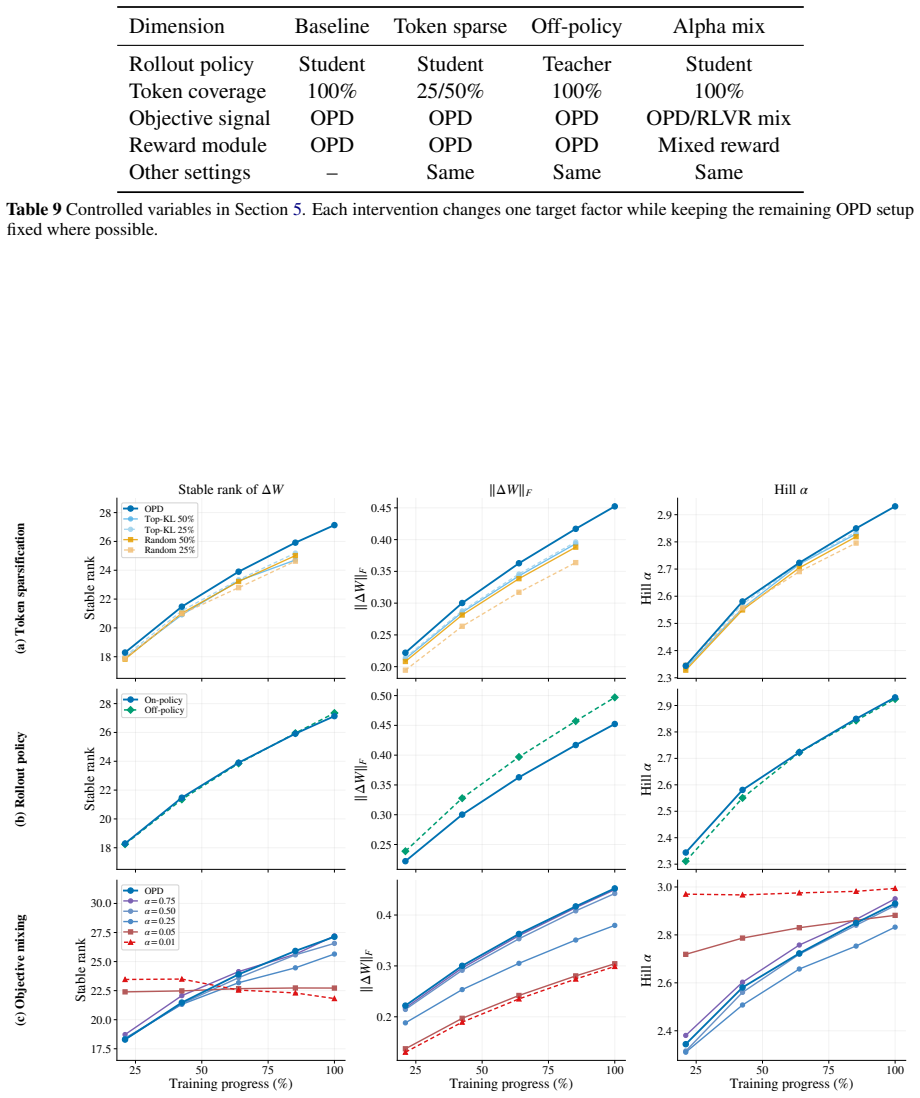
- Restricting updates to the early subspace leaves OPD performance intact but substantially lowers SFT performance.
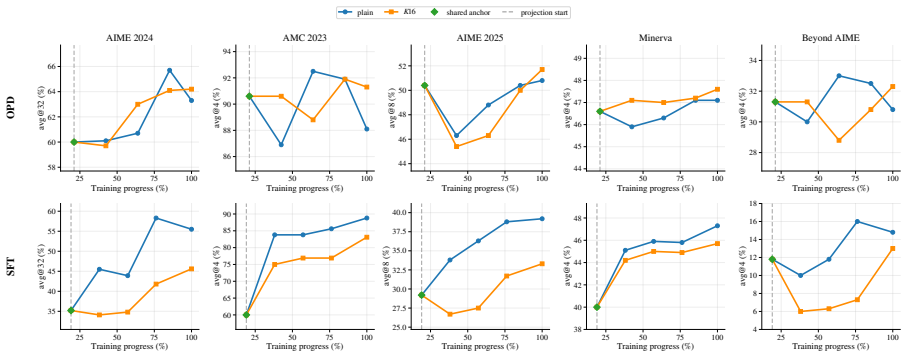
- Sparsifying the tokens used for updates or moving rollout generation off-policy leaves the rank dynamics of OPD unchanged.
- Mixing the OPD objective with RLVR alters the observed rank dynamics.
- OPD updates stay less tightly constrained than those produced by RLVR.
Where Pith is reading between the lines
- The locked subspace could be pre-computed once and reused to reduce the cost of later OPD runs on similar tasks.
- Different objectives may claim different low-dimensional channels, opening the possibility of running multiple fine-tuning styles without mutual interference.
- If the channel is narrow enough, it may become feasible to monitor or regularize only those dimensions during deployment-time adaptation.
Load-bearing premise
The chosen diagnostics of affected weights, principal-direction avoidance, and subspace rank correctly identify the directions that matter for keeping OPD performance.
What would settle it
Training restricted to the early OPD subspace would no longer preserve OPD performance while still degrading SFT performance.
Figures

read the original abstract
On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly understood. We characterize the trajectory of OPD updates in parameter space and compare it with supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). A suite of parameter-space diagnostics consistently places OPD in a relaxed off-principal regime: compared with SFT, its updates affect fewer weights and avoid principal directions more strongly, while compared with RLVR, they remain less tightly constrained. Beyond this static localization, OPD exhibits subspace locking: its cumulative updates rapidly enter a narrow low-dimensional channel. Constraining training to the update subspace formed early in training preserves OPD performance but substantially degrades SFT, indicating that the locked subspace is functionally sufficient for OPD. Control experiments further show that sparsifying the update tokens and shifting rollout generation off-policy preserve the rank dynamics, whereas mixing the OPD objective with RLVR changes them. Overall, these results suggest that OPD is not merely an intermediate point between SFT and RLVR, but induces its own update geometry in parameter space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy distillation (OPD) induces a distinct update geometry in parameter space for large language models, distinct from both supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). Static diagnostics show OPD updates affect fewer weights and avoid principal directions more strongly than SFT while remaining less tightly constrained than RLVR. Dynamically, OPD exhibits subspace locking, with cumulative updates rapidly entering a narrow low-dimensional channel; constraining training to the early-OPD subspace preserves OPD performance but degrades SFT. Control experiments indicate that sparsifying update tokens and off-policy rollouts preserve rank dynamics, while mixing with RLVR alters them.
Significance. If the geometric characterization and subspace-locking results hold after addressing controls, the work would establish that OPD is not an interpolation between SFT and RLVR but follows its own parameter-space trajectory. This could inform the design of distillation objectives and provide a new lens on why OPD improves reasoning performance. The empirical focus on direct trajectory measurements rather than derived quantities is a strength.
major comments (2)
- [Subspace locking / constraining experiment] Subspace-constraining experiment (described in the dynamic claim section): the performance preservation when training is constrained to the early-OPD update subspace is presented as evidence that the subspace is functionally sufficient and specific to OPD. However, the experiment lacks controls for random subspaces of identical dimension drawn from the same initialization, or verification that the projection does not implicitly change effective gradient magnitudes or token statistics. Without these, the preservation could arise from reduced capacity or regularization rather than OPD-specific geometry. This is load-bearing for the central claim that OPD induces its own update geometry.
- [Static diagnostics] Static diagnostics section: the metrics for 'number of affected weights' and 'avoidance of principal directions' are used to localize OPD in a relaxed off-principal regime, but the manuscript does not specify the exact thresholds or sensitivity analyses for these quantities. If the thresholds are post-hoc, they could affect the comparative placement versus SFT and RLVR.
minor comments (2)
- [Abstract / Methods] The abstract and main text should explicitly state the model sizes, datasets, and exact hyperparameter settings used for the reported trajectories to allow reproduction of the rank dynamics.
- [Figures] Figure captions for the subspace rank plots should clarify whether the plotted quantities are cumulative or per-step and how the principal directions are computed (e.g., from which covariance matrix).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The two major comments identify areas where additional controls and clarifications will strengthen the presentation of the subspace-locking results and static diagnostics. We address each point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Subspace locking / constraining experiment] Subspace-constraining experiment (described in the dynamic claim section): the performance preservation when training is constrained to the early-OPD update subspace is presented as evidence that the subspace is functionally sufficient and specific to OPD. However, the experiment lacks controls for random subspaces of identical dimension drawn from the same initialization, or verification that the projection does not implicitly change effective gradient magnitudes or token statistics. Without these, the preservation could arise from reduced capacity or regularization rather than OPD-specific geometry. This is load-bearing for the central claim that OPD induces its own update geometry.
Authors: We agree that the current controls leave open the possibility that performance preservation arises from generic effects of reduced capacity rather than OPD-specific geometry. In the revised manuscript we will add (i) training runs constrained to random subspaces of matching dimension sampled from the same initialization and (ii) explicit verification that the projection operator preserves effective gradient magnitudes and token statistics. These additions directly address the concern and will be reported alongside the existing SFT degradation result. revision: yes
-
Referee: [Static diagnostics] Static diagnostics section: the metrics for 'number of affected weights' and 'avoidance of principal directions' are used to localize OPD in a relaxed off-principal regime, but the manuscript does not specify the exact thresholds or sensitivity analyses for these quantities. If the thresholds are post-hoc, they could affect the comparative placement versus SFT and RLVR.
Authors: We will revise the static diagnostics section to state the precise numerical thresholds employed for both metrics, describe how they were selected (including any pre-specified criteria), and include sensitivity plots showing how the relative placement of OPD, SFT, and RLVR changes under modest variations of those thresholds. This will eliminate ambiguity about post-hoc selection. revision: yes
Circularity Check
No circularity: empirical diagnostics and subspace experiments are direct measurements, not reductions to fitted inputs or self-citations.
full rationale
The paper presents no derivation chain, equations, or first-principles predictions. All central claims rest on direct empirical measurements of update trajectories, affected weights, principal directions, rank dynamics, and controlled subspace-constraint experiments. These are falsifiable observations from training runs rather than quantities defined in terms of themselves or extracted via self-citation. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing uniqueness theorems appear. The skeptic concern about whether the subspace is functionally special is a question of experimental controls, not circularity in the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of lan- guage models: Learning from self-generated mis- takes.Preprint, arXiv:2306.13649. Yuchen Cai, Ding Cao, Liang Lin, Chunxi Luo, Xin Xu, Kai Yang, Weijie Liu, Saiyong Yang, Tianxiang Zhao, Guangzhong Sun, Guiquan Liu, and Junfeng Fang
-
[2]
Learning to foresee: Unveiling the un- locking efficiency of on-policy distillation.Preprint, arXiv:2605.11739. DeepSeek-AI
-
[3]
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao
Fine-tuning pretrained language models: Weight ini- tializations, data orders, and early stopping.Preprint, arXiv:2002.06305. Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao
arXiv 2002
-
[4]
Revisiting on-policy distillation: Empirical failure modes and simple fixes.Preprint, arXiv:2603.25562. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others
-
[5]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Bruce M. Hill
-
[6]
Universal language model fine-tuning for text classification. Preprint, arXiv:1801.06146. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica
-
[7]
Live- codebench: Holistic and contamination free evalu- ation of large language models for code.Preprint, arXiv:2403.07974. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding
-
[8]
Rethinking on-policy distillation of large lan- guage models: Phenomenology, mechanism, and recipe.Preprint, arXiv:2604.13016. Zihang Liu, Tianyu Pang, Oleg Balabanov, Chao- qun Yang, Tianjin Huang, Lu Yin, Yaoqing Yang, and Shiwei Liu
-
[9]
Kevin Lu and Thinking Machines Lab
Lift the veil for the truth: Principal weights emerge after rank reduction for reasoning-focused supervised fine-tuning.Preprint, arXiv:2506.00772. Kevin Lu and Thinking Machines Lab
-
[10]
Reinforcement learning fine- tunes small subnetworks in large language models. Preprint, arXiv:2505.11711. Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groen- eveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukho...
-
[11]
Olmo 3.Preprint, arXiv:2512.13961. OpenAI
-
[12]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L
Openai o1 system card.Preprint, arXiv:2412.16720. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe
-
[13]
Training language models to follow instructions with human feedback.Preprint, arXiv:2203.02155. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo
-
[14]
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal
Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.03300. Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal
-
[15]
Rl’s razor: Why online reinforcement learning for- gets less.Preprint, arXiv:2509.04259. Mingyang Song and Mao Zheng
-
[16]
A survey of on-policy distillation for large language models. Preprint, arXiv:2604.00626. Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, An- drew M. Dai, and Quoc V . Le
-
[17]
9 Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi
Finetuned language models are zero-shot learners.Preprint, arXiv:2109.01652. 9 Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi
-
[18]
The invisible leash: Why rlvr may or may not escape its origin.Preprint, arXiv:2507.14843. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others
-
[19]
Qwen3 technical report.Preprint, arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, and 16 others
-
[20]
Dapo: An open-source llm re- inforcement learning system at scale.Preprint, arXiv:2503.14476. Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Zhizhou Sha, Jinwon Lee, David Z. Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai
- [21]
-
[22]
Fine-tuning lan- guage models from human preferences.Preprint, arXiv:1909.08593. A AI Usage We used ChatGPT for writing assistance, including language polishing, LaTeX formatting, organiza- tion suggestions, and refinement of presentation. We also used it to assist with drafting plotting and analysis scripts. All scientific claims, experimen- tal designs,...
Pith/arXiv arXiv 1909
-
[23]
C.3 Parameter-Space Diagnostic Implementation All diagnostics are computed offline on saved checkpoints
The code-domain variant uses DeepCoder data (Luo et al., 2025); evaluation is conducted on Live- CodeBench v5 (Jain et al., 2024). C.3 Parameter-Space Diagnostic Implementation All diagnostics are computed offline on saved checkpoints. Each analysis loads a pair of check- points (W0, W+) and computes ∆W=W + −W
2025
-
[24]
Gate I: KL anchor .RLVR updates are locally constrained in policy space
explains visi- ble update sparsity as the outcome of a constrained, geometry-steered, and precision-filtered optimiza- tion process. Gate I: KL anchor .RLVR updates are locally constrained in policy space. In a KL-regularized or trust-region view, the post-update policy remains close to the current or reference policy: DKL(πθ+ ∥π θ)≤K.(15) This policy-spa...
1975
-
[25]
whereas SFT is substantially more sensitive to the same bottleneck
OPD remains broadly robust under the early rank-16 subspace constraint, Item Setting Student model Qwen3-8B Teacher model Qwen3-32B Student initialization Qwen3-8B SFT anchor, iter_0005375 Training data dapo-math-17k Training length 300 steps Checkpoint steps 63, 127, 191, 255, 299 Baseline rollout Student-generated, 8 sam- ples per prompt Analyzed matric...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.