SABLE: GPU-Based Power Flow Accelerator for Sparsity-Aware Batched Learning
Pith reviewed 2026-06-27 21:24 UTC · model grok-4.3
The pith
SABLE reformulates batched power flow Jacobians into a shared 2D sparse template for GPU-accelerated differentiable learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
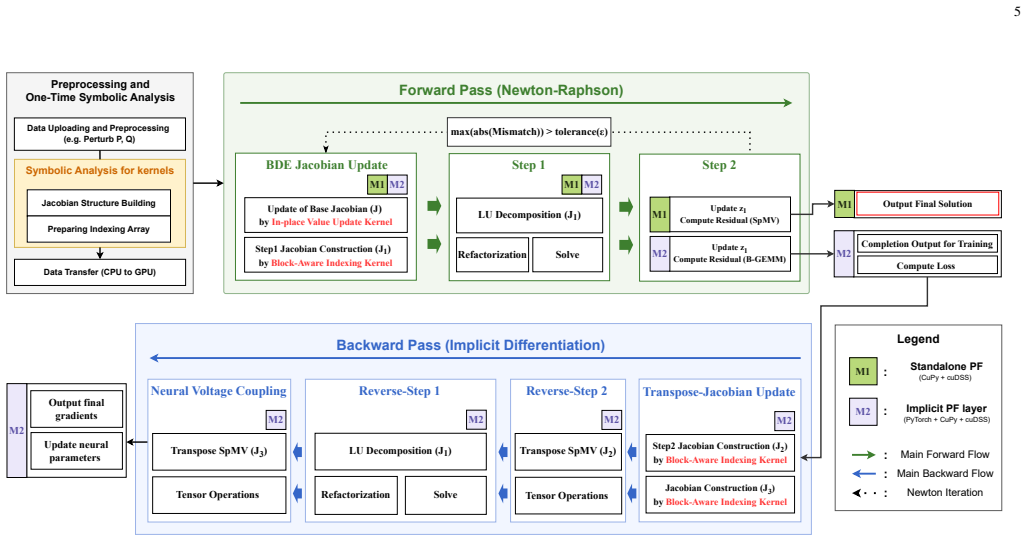
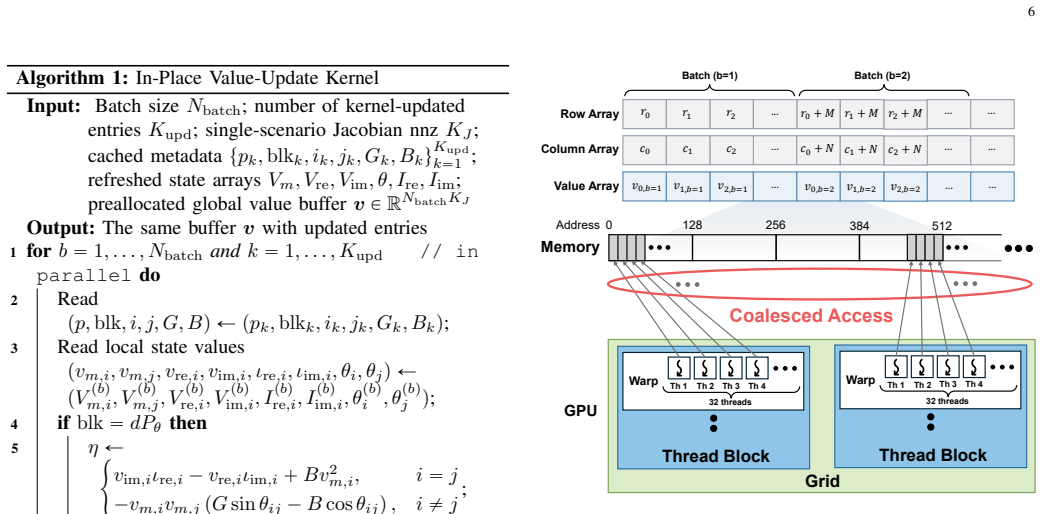
SABLE uses a block-diagonal embedding to convert batched three-dimensional Jacobians into a single fixed-pattern two-dimensional sparse template. This template is shared across libraries for zero-copy interoperability and enables memory-efficient reuse of sparsity patterns during repeated power flow computations inside implicit layers.
What carries the argument
The block-diagonal embedding that reformulates batched three-dimensional Jacobians as a fixed-pattern two-dimensional sparse template shared across PyTorch, CuPy, and cuDSS.
If this is right
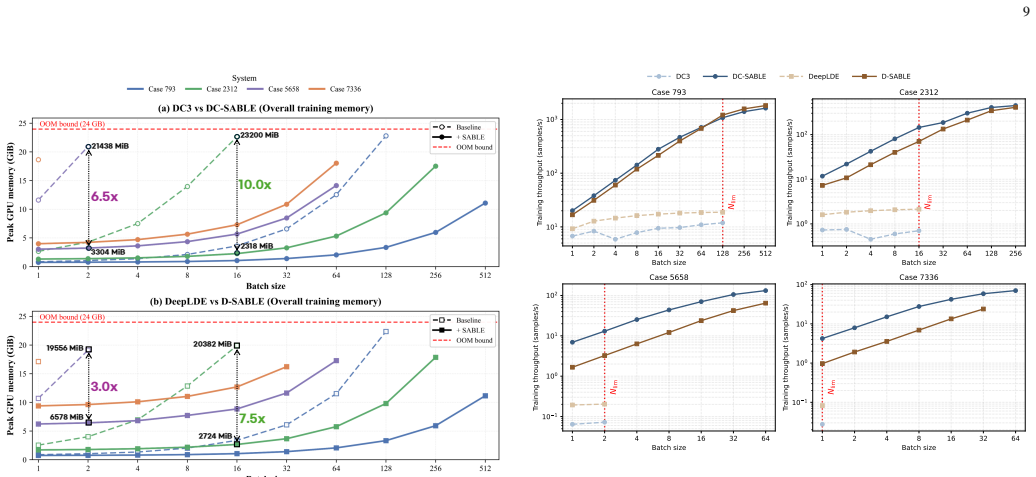
- Standalone power flow throughput reaches up to 253.4 times that of pandapower and 5.7 times that of ExaPF.
- Feasible training batch sizes for DC3- and DeepLDE-based AC optimal power flow models grow up to 64 times larger.
- End-to-end training throughput improves up to 206.7 times over the corresponding baseline.
- Repeated power flow calls inside training loops benefit from reusable sparse templates and mixed-precision arithmetic.
Where Pith is reading between the lines
- The same embedding pattern could be applied to other batched sparse linear systems that appear in differentiable optimization.
- Power system operators could train larger-scale learned controllers that were previously limited by batch size.
- Real-time grid applications might incorporate end-to-end learned power flow corrections at higher update rates.
Load-bearing premise
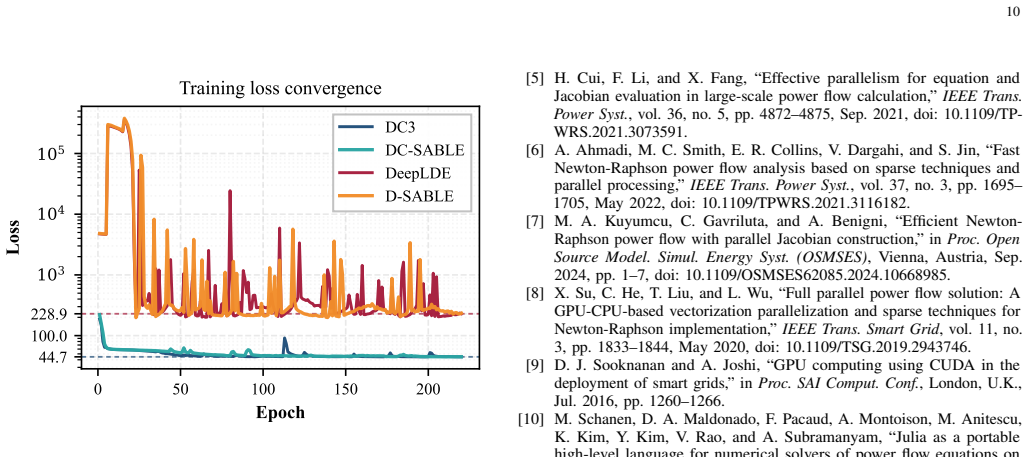
The embedding keeps numerical stability, sparsity benefits, and end-to-end differentiability intact when the sparse template is used inside learning frameworks.
What would settle it
Run a batched AC power flow solve and its gradient computation both with and without the embedding on the same network; divergence in voltage solutions or incorrect loss gradients would falsify the claim.
Figures

read the original abstract
Recent studies have developed GPU-based approaches for solving AC power flow and successfully applied them to standalone power flow problems. However, integrating these approaches into modern differentiable learning frameworks while preserving sparsity remains challenging. To this end, we present SABLE, a GPU-based sparse batched power flow accelerator for differentiable learning via an implicit power flow layer. SABLE leverages a block-diagonal embedding that reformulates batched three-dimensional Jacobians as a fixed-pattern two-dimensional sparse template that is shared across PyTorch, CuPy, and cuDSS. This common template enables zero-copy interoperability and memory-efficient sparse reuse across the software stack. On top of this representation, SABLE accelerates repeated power flow computations through reusable sparse templates, custom GPU kernels, a cuDSS-based sparse-direct LU solver, and mixed-precision techniques. Extensive experiments show that SABLE improves standalone power flow solving throughput by up to 253.4$\times$ over pandapower and 5.7$\times$ over ExaPF. In end-to-end training, evaluated on AC optimal power flow learning models based on DC3 and DeepLDE, SABLE expands the feasible training batch range by up to 64$\times$ and improves training throughput by up to 206.7$\times$ over the corresponding baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SABLE, a GPU-based sparse batched power flow accelerator for use inside differentiable learning frameworks via an implicit power flow layer. It introduces a block-diagonal embedding that reformulates batched 3D Jacobians as a fixed-pattern 2D sparse template shared across PyTorch, CuPy, and cuDSS, enabling reusable sparse templates, custom kernels, cuDSS LU solves, and mixed precision. Experiments report up to 253.4× standalone throughput improvement over pandapower and 5.7× over ExaPF, plus up to 64× batch expansion and 206.7× training throughput gains on DC3- and DeepLDE-based AC OPF learning models.
Significance. If the performance and accuracy claims hold, the work supplies a practical sparsity-preserving GPU primitive that directly addresses the repeated-solve bottleneck in end-to-end training of AC optimal power flow models. The cross-library zero-copy interoperability and fixed-pattern reuse are concrete engineering contributions that could enable larger-scale learning experiments in power systems. The stress-test concern on the block-diagonal embedding does not appear to introduce load-bearing inconsistencies; the reported experiments show no evident contradictions in numerical stability, sparsity handling, or differentiability.
minor comments (2)
- [Abstract] Abstract: the concrete speedup numbers are stated without any mention of test-system sizes, hardware platform, or accuracy metrics; adding one sentence on the experimental protocol would allow readers to assess the claims at a glance.
- [§3] The manuscript would benefit from an explicit statement (perhaps in §3 or the experimental section) confirming that the block-diagonal embedding preserves the same LU factorization pattern across batches, as this is central to the claimed memory-efficient reuse.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SABLE and the recommendation for minor revision. We are pleased that the work's practical contributions to sparsity-preserving GPU primitives for AC OPF learning are recognized, along with the confirmation that the block-diagonal embedding introduces no evident inconsistencies in stability or differentiability.
Circularity Check
No significant circularity identified
full rationale
The paper's central contributions consist of a block-diagonal embedding reformulation for batched Jacobians and associated GPU kernels for power flow acceleration. All reported performance metrics (throughput gains versus pandapower and ExaPF, batch-size expansion in DC3/DeepLDE training) are obtained by direct experimental comparison against externally maintained, independently implemented baselines rather than any internally fitted parameters, self-citations, or quantities defined in terms of the claimed outputs. No equations or uniqueness theorems are invoked that reduce to self-referential definitions or prior author work; the representation is presented as an engineering choice enabling interoperability, with numerical stability and differentiability asserted as preserved properties verified by experiment. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption cuDSS sparse-direct LU solver is numerically stable and efficient for the Jacobians arising in AC power flow
- domain assumption Mixed-precision arithmetic preserves sufficient accuracy for both power flow solutions and gradient computation in learning
Reference graph
Works this paper leans on
-
[1]
A critical review on probabilistic load flow studies in power systems with intermittent renewable energy generation,
B. R. Prusty and D. Jena, “A critical review on probabilistic load flow studies in power systems with intermittent renewable energy generation,” Renew. Sustain. Energy Rev., vol. 78, pp. 100–111, 2017
2017
-
[2]
DC3: A learning method for optimization with hard constraints,
P. L. Donti, D. Rolnick, and J. Z. Kolter, “DC3: A learning method for optimization with hard constraints,” inProc. Int. Conf. Learn. Representations (ICLR), 2021
2021
-
[3]
Unsupervised Deep Lagrange Dual with equation embedding for AC optimal power flow,
M. Kim and H. Kim, “Unsupervised Deep Lagrange Dual with equation embedding for AC optimal power flow,”IEEE Trans. Power Syst., vol. 40, no. 1, pp. 1078–1090, Jan. 2025, doi: 10.1109/TPWRS.2024.3406437
-
[4]
F. Sch ¨afer and M. Braun, “An efficient open-source implementation to compute the Jacobian matrix for the Newton-Raphson power flow algorithm,” inProc. IEEE PES Innov. Smart Grid Technol. Eur . (ISGT- Europe), Sarajevo, Bosnia and Herzegovina, Oct. 2018, doi: 10.1109/IS- GTEurope.2018.8571471
work page doi:10.1109/is- 2018
-
[5]
A Task-Based Day-Ahead Load Forecasting ModelforStochasticEconomicDispatch,
H. Cui, F. Li, and X. Fang, “Effective parallelism for equation and Jacobian evaluation in large-scale power flow calculation,”IEEE Trans. Power Syst., vol. 36, no. 5, pp. 4872–4875, Sep. 2021, doi: 10.1109/TP- WRS.2021.3073591
work page doi:10.1109/tp- 2021
-
[6]
Fast Newton-Raphson power flow analysis based on sparse techniques and parallel processing,
A. Ahmadi, M. C. Smith, E. R. Collins, V . Dargahi, and S. Jin, “Fast Newton-Raphson power flow analysis based on sparse techniques and parallel processing,”IEEE Trans. Power Syst., vol. 37, no. 3, pp. 1695– 1705, May 2022, doi: 10.1109/TPWRS.2021.3116182
-
[7]
Efficient Newton- Raphson power flow with parallel Jacobian construction,
M. A. Kuyumcu, C. Gavriluta, and A. Benigni, “Efficient Newton- Raphson power flow with parallel Jacobian construction,” inProc. Open Source Model. Simul. Energy Syst. (OSMSES), Vienna, Austria, Sep. 2024, pp. 1–7, doi: 10.1109/OSMSES62085.2024.10668985
-
[8]
X. Su, C. He, T. Liu, and L. Wu, “Full parallel power flow solution: A GPU-CPU-based vectorization parallelization and sparse techniques for Newton-Raphson implementation,”IEEE Trans. Smart Grid, vol. 11, no. 3, pp. 1833–1844, May 2020, doi: 10.1109/TSG.2019.2943746
-
[9]
GPU computing using CUDA in the deployment of smart grids,
D. J. Sooknanan and A. Joshi, “GPU computing using CUDA in the deployment of smart grids,” inProc. SAI Comput. Conf., London, U.K., Jul. 2016, pp. 1260–1266
2016
-
[10]
Julia as a portable high-level language for numerical solvers of power flow equations on GPU architectures,
M. Schanen, D. A. Maldonado, F. Pacaud, A. Montoison, M. Anitescu, K. Kim, Y . Kim, V . Rao, and A. Subramanyam, “Julia as a portable high-level language for numerical solvers of power flow equations on GPU architectures,”Les Cahiers du GERAD, G-2020-74, Dec. 2020
2020
-
[11]
N. Garcia, “Parallel power flow solutions using a biconjugate gradient algorithm and a Newton method: A GPU-based approach,” inProc. IEEE Power Energy Soc. Gen. Meeting, Providence, RI, USA, Jul. 2010, pp. 1–4, doi: 10.1109/PES.2010.5589682
-
[12]
GPU-based power flow analysis with Chebyshev preconditioner and conjugate gradient method,
X. Li and F. Li, “GPU-based power flow analysis with Chebyshev preconditioner and conjugate gradient method,”Electr . Power Syst. Res., vol. 116, pp. 87–93, Nov. 2014
2014
-
[13]
GPU- accelerated batch-ACPF solution for N´1 static security analysis,
G. Zhou, R. Bo, C.-N. Yu, A. J. Flueck, and L. Liao, “GPU- accelerated batch-ACPF solution for N´1 static security analysis,” IEEE Trans. Smart Grid, vol. 8, no. 3, pp. 1406–1416, May 2017, doi: 10.1109/TSG.2016.2518635
-
[14]
GPU- based batch LU-factorization solver for concurrent analysis of massive power flows,
G. Zhou, R. Bo, L. Chien, X. Zhang, F. Shi, C. Xu, and Y . Feng, “GPU- based batch LU-factorization solver for concurrent analysis of massive power flows,”IEEE Trans. Power Syst., vol. 32, no. 6, pp. 4975–4977, Nov. 2017, doi: 10.1109/TPWRS.2017.2662322
-
[15]
Fast parallel Newton- Raphson power flow solver for large number of system calculations with CPU and GPU,
Z. Wang, S. Wende-von Berg, and M. Braun, “Fast parallel Newton- Raphson power flow solver for large number of system calculations with CPU and GPU,”Sustain. Energy Grids Netw., vol. 27, p. 100483, Sep. 2021
2021
-
[16]
Sparse tensors documentation,
PyTorch, “Sparse tensors documentation,” [Online]. Available: https: //pytorch.org/docs/stable/sparse.html#construction. Accessed: Jun. 4, 2026
2026
-
[17]
torch.utils.dlpack,
PyTorch Foundation, “torch.utils.dlpack,”PyTorch Documentation, last updated Jun. 13, 2025. [Online]. Available: https://docs.pytorch.org/docs/ stable/dlpack.html. Accessed: Jun. 4, 2026
2025
-
[18]
nvmath-python: NVIDIA Math Libraries for the Python Ecosystem,
NVIDIA, “nvmath-python: NVIDIA Math Libraries for the Python Ecosystem,” [Online]. Available: https : / / github . com / NVIDIA / nvmath-python. Accessed: Jun. 4, 2026
2026
-
[19]
NVIDIA cuDSS: A high-performance CUDA library for direct sparse solvers,
NVIDIA, “NVIDIA cuDSS: A high-performance CUDA library for direct sparse solvers,” [Online]. Available: https://docs.nvidia.com/cuda/cudss/ index.html. Accessed: Jun. 4, 2026
2026
-
[20]
CuPy: A NumPy-compatible library for NVIDIA GPU calculations,
R. Okuta, Y . Unno, D. Nishino, S. Hido, and C. Loomis, “CuPy: A NumPy-compatible library for NVIDIA GPU calculations,” inProc. Workshop Mach. Learn. Syst. (LearningSys), NeurIPS, 2017
2017
-
[21]
L. Thurner, A. Scheidler, F. Sch ¨afer, J.-H. Menke, J. Dollichon, F. Meier, S. Meinecke, and M. Braun, “Pandapower—An open-source Python tool for convenient modeling, analysis, and optimization of electric power systems,”IEEE Trans. Power Syst., vol. 33, no. 6, pp. 6510–6521, Nov. 2018, doi: 10.1109/TPWRS.2018.2829021
-
[22]
ExaPF.jl documentation,
ExaPF Developers, “ExaPF.jl documentation,” [Online]. Available: https: //exanauts.github.io/ExaPF.jl/stable/. Accessed: Jun. 4, 2026
2026
-
[23]
NVIDIA A100 Tensor Core GPU,
NVIDIA, “NVIDIA A100 Tensor Core GPU,” [Online]. Available: https: //www.nvidia.com/en-us/data-center/a100/. Accessed: Jun. 4, 2026
2026
-
[24]
NVIDIA H100 Tensor Core GPU,
NVIDIA, “NVIDIA H100 Tensor Core GPU,” [Online]. Available: https: //www.nvidia.com/en-us/data-center/h100/. Accessed: Jun. 4, 2026
2026
-
[25]
Mixed precision algorithms in numerical linear algebra,
N. J. Higham and T. Mary, “Mixed precision algorithms in numerical linear algebra,”SIAM Rev., vol. 64, no. 1, pp. 31–77, Feb. 2022
2022
-
[26]
Newton’s method in mixed precision,
C. T. Kelley, “Newton’s method in mixed precision,”SIAM Rev., vol. 64, no. 1, pp. 191–211, Feb. 2022, doi: 10.1137/20M1342902
-
[27]
Power flow solution by Newton’s method,
W. F. Tinney and C. E. Hart, “Power flow solution by Newton’s method,” IEEE Trans. Power Appar . Syst., vol. PAS-86, no. 11, pp. 1449–1460, Nov. 1967
1967
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.