CANote: Empowering Fact-checking Note Writing Through Scaffolded and Provenance-based Human-AI Collaboration
Pith reviewed 2026-06-27 21:02 UTC · model grok-4.3
The pith
CANote's AI scaffolding with subclaim extraction and provenance links lets lay users produce fact-check notes matching expert quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CANote improves note quality through evidence correlation and structured co-drafting by breaking posts into subclaims, supplying explicit provenance links to supporting evidence, and generating neutral structural drafts that support rather than replace human reasoning; in a controlled evaluation on a simulated X platform, both expert and lay users produced higher-quality notes with the system than without it, with lay users reaching quality levels comparable to unaided experts.
What carries the argument
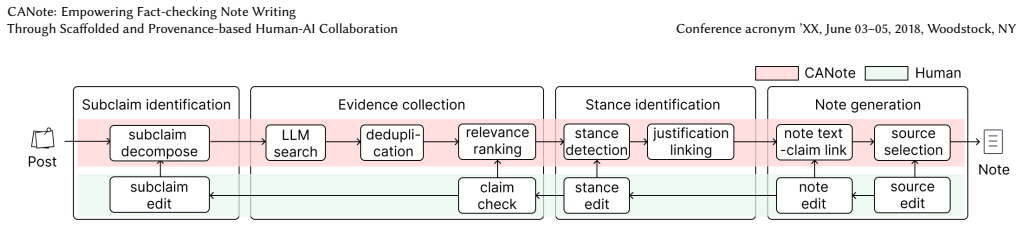
Scaffolded workflow that extracts subclaims, provides explicit provenance links between subclaims and evidence, and generates neutral structural drafts for human co-drafting.
If this is right
- Lay users become viable contributors of high-quality debunking notes.
- Overall quality of crowdsourced notes on platforms like X rises.
- Task completion time and cognitive load stay the same as manual writing.
- User satisfaction with the writing process increases.
- Contributors report a lower sense of ownership and control over the finished note.
Where Pith is reading between the lines
- The same scaffolding pattern could be adapted to other social platforms that rely on user-generated corrections.
- Lower ownership might reduce long-term contributor retention even if short-term quality improves.
- The provenance links could serve as training data for fully automated fact-checking systems.
- Real-world rollout would need to test whether the quality gains persist when users know the audience is live rather than simulated.
Load-bearing premise
The controlled simulation of the X platform with 52 participants per group accurately captures real-world note quality and generalizes to actual deployment.
What would settle it
In a live X deployment, notes written with CANote receive no higher quality ratings from platform users or independent raters than notes written without the system.
Figures







read the original abstract
Crowdsourced fact-checking mechanisms, such as X's Community Notes, play a critical role in mitigating the spread of misinformation. However, drafting high-quality, evidence-based debunking notes imposes a substantial burden on contributors. We present CANote, an AI-assisted debunking note writing system featuring evidence correlation and structured co-drafting. CANote scaffolds the workflow by extracting subclaims from social media posts, providing provenance through explicit links between subclaims and retrieved evidence, and generating neutral, structural drafts to support human reasoning. We evaluated CANote against manual writing (N=52 fact-checkers, N=52 lay users) on simulated X platform, where we found CANote significantly improves note quality. Notably, CANote enables lay users to write notes that have comparable quality to those written by experts. While the task completion time and perceived cognitive load remain comparable to manual drafting, CANote significantly increases user satisfaction. However, this assistance introduces a trade-off, resulting in a reduced sense of user ownership and control over the debunking note.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CANote, an AI-assisted system for drafting evidence-based fact-checking notes on platforms like X's Community Notes. The system extracts subclaims from posts, links them explicitly to retrieved evidence for provenance, and generates neutral structural drafts to scaffold human reasoning. A controlled user study on a simulated X platform (N=52 fact-checkers and N=52 lay users) is reported to show that CANote significantly improves note quality over manual writing, enables lay users to reach expert-comparable quality, increases satisfaction, keeps task time and cognitive load similar, but reduces perceived ownership and control.
Significance. If the evaluation holds under scrutiny, the work could meaningfully advance human-AI collaboration tools for crowdsourced fact-checking by lowering barriers for non-experts while preserving evidence linkage. The provenance and scaffolding features directly target documented burdens in Community Notes-style systems, and the lay-expert parity result, if substantiated, would be a notable finding for participatory misinformation mitigation.
major comments (2)
- [Abstract / Evaluation] Abstract and user-study description: the claims of 'significantly improves note quality' and 'lay users to write notes that have comparable quality to those written by experts' are presented without any information on the quality rubric (dimensions scored, scoring scale), statistical tests used, blinding of raters to condition or author expertise level, or inter-rater reliability metrics. These omissions make it impossible to evaluate whether the reported significance and parity are interpretable or robust.
- [Abstract / Evaluation] Abstract and simulated-platform evaluation: the headline lay-expert comparability result rests entirely on the N=52/group controlled simulation, yet no details are supplied on how note visibility, feedback loops, or platform dynamics in the simulation map to real Community Notes mechanics, nor on any controls for content domain or post difficulty. This leaves the generalizability of the central claim unassessable.
minor comments (1)
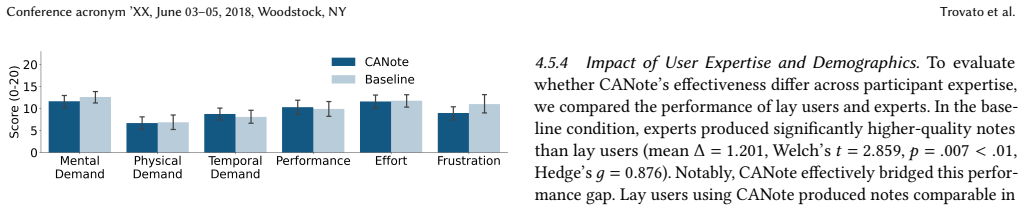
- [Abstract] The abstract states that task completion time and cognitive load 'remain comparable' while satisfaction increases; a table or figure reporting the exact means, standard deviations, and p-values for these measures would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting critical gaps in the reporting of our evaluation. We agree that the current manuscript version lacks sufficient detail on the quality assessment protocol and simulation design. We will revise the paper to include these elements, which will strengthen the interpretability of our results.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and user-study description: the claims of 'significantly improves note quality' and 'lay users to write notes that have comparable quality to those written by experts' are presented without any information on the quality rubric (dimensions scored, scoring scale), statistical tests used, blinding of raters to condition or author expertise level, or inter-rater reliability metrics. These omissions make it impossible to evaluate whether the reported significance and parity are interpretable or robust.
Authors: We agree that the abstract and user-study description omit essential methodological details required to assess the robustness of the quality and parity claims. In the revised manuscript we will expand the Evaluation section to specify: (1) the full quality rubric with all scored dimensions and the 1-5 Likert scale; (2) the exact statistical tests (including effect sizes and corrections for multiple comparisons); (3) that raters were blinded to both experimental condition and whether the note author was a fact-checker or lay user; and (4) inter-rater reliability statistics (e.g., Krippendorff’s alpha or ICC). These additions will be placed in both the main text and a new supplementary table. revision: yes
-
Referee: [Abstract / Evaluation] Abstract and simulated-platform evaluation: the headline lay-expert comparability result rests entirely on the N=52/group controlled simulation, yet no details are supplied on how note visibility, feedback loops, or platform dynamics in the simulation map to real Community Notes mechanics, nor on any controls for content domain or post difficulty. This leaves the generalizability of the central claim unassessable.
Authors: We concur that the current description of the simulated platform is insufficient to evaluate ecological validity. In revision we will add a dedicated subsection detailing: (a) how note visibility and rating mechanics were approximated (including the absence of real-time community feedback loops, which we will explicitly flag as a limitation); (b) the procedure used to select and balance posts across content domains and difficulty levels; and (c) any pilot testing performed to calibrate the simulation. We will also add a limitations paragraph acknowledging that controlled simulations cannot fully replicate emergent platform dynamics such as iterative note editing by multiple contributors. revision: yes
Circularity Check
No circularity: empirical user study with no derivations or fitted predictions
full rationale
The paper presents a system description and controlled user study (N=52 per group) comparing CANote-assisted note writing to manual drafting on a simulated platform. No equations, first-principles derivations, parameter fitting, or predictions appear in the abstract or described content. Claims of quality improvement and lay-expert parity rest on direct empirical measurement rather than any self-referential reduction or self-citation chain. The evaluation is self-contained against its own rubric and participant data; no load-bearing step reduces to an input by construction. This is the expected outcome for an HCI system paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Crowdsourced fact-checking mechanisms play a critical role in mitigating the spread of misinformation.
invented entities (1)
-
CANote system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity checks for saliency maps.Advances in neural information processing systems31 (2018)
2018
-
[2]
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. 2024. Geo: Generative engine optimization. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 5–16
2024
-
[3]
Mubashara Akhtar, Michael Schlichtkrull, Zhijiang Guo, Oana Cocarascu, Elena Simperl, and Andreas Vlachos. 2023. Multimodal automated fact-checking: A survey. InFindings of the Association for Computational Linguistics: EMNLP 2023. 5430–5448
2023
-
[4]
Mubashara Akhtar, Michael Schlichtkrull, and Andreas Vlachos. 2024. Ev2r: Evaluating evidence retrieval in automated fact-checking.arXiv preprint arXiv:2411.05375(2024)
arXiv 2024
-
[5]
Maryam Ashoori and Justin D Weisz. 2019. In AI we trust? Factors that influ- ence trustworthiness of AI-infused decision-making processes.arXiv preprint arXiv:1912.02675(2019)
arXiv 2019
-
[6]
Pepa Atanasova. 2024. Multi-hop fact checking of political claims. InAccountable and Explainable Methods for Complex Reasoning over Text. Springer, 131–151
2024
-
[7]
Pepa Atanasova, Jakob Grue Simonsen, Christina Lioma, and Isabelle Augenstein
-
[8]
InProceedings of the 58th annual meeting of the association for computational linguistics
Generating fact checking explanations. InProceedings of the 58th annual meeting of the association for computational linguistics. 7352–7364
-
[9]
Michael Bailey, David Dittrich, Erin Kenneally, and Doug Maughan. 2012. The menlo report.IEEE Security & Privacy10, 2 (2012), 71–75
2012
-
[10]
Eivind Morris Bakke and Nora Winger Heggelund. 2025. (Fact) Check Your Bias. InProceedings of the Eighth Fact Extraction and VERification Workshop (FEVER). 162–178
2025
-
[11]
Ramy Baly, Georgi Karadzhov, Dimitar Alexandrov, James Glass, and Preslav Nakov. 2018. Predicting factuality of reporting and bias of news media sources. InProceedings of the 2018 conference on empirical methods in natural language processing. 3528–3539
2018
-
[12]
Mariano Barone, Antonio Romano, Giuseppe Riccio, Marco Postiglione, and Vincenzo Moscato. 2025. Combining Evidence and Reasoning for Biomedical Fact-Checking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1087–1097
2025
-
[13]
Azadeh Bayani, Alexandre Ayotte, Jean Noel Nikiema, et al. 2025. Transformer- based tool for automated fact-checking of online health information: Develop- ment study.JMIR infodemiology5, 1 (2025), e56831
2025
-
[14]
Tom L Beauchamp et al. 2008. The belmont report.The Oxford textbook of clinical research ethics(2008), 149–155
2008
-
[15]
Adrien Bibal, Rémi Cardon, David Alfter, Rodrigo Wilkens, Xiaoou Wang, Thomas François, and Patrick Watrin. 2022. Is attention explanation? an introduction to the debate. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (volume 1: long papers). 3889–3900
2022
-
[16]
Tobias Braun, Mark Rothermel, Marcus Rohrbach, and Anna Rohrbach. 2025. DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts. In International Conference on Machine Learning. PMLR, 5383–5417
2025
-
[17]
Alexander S Choi, Syeda Sabrina Akter, JP Singh, and Antonios Anastasopoulos
-
[18]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
The LLM effect: Are humans truly using LLMs, or are they being influenced by them instead?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 22032–22054
2024
-
[19]
Yuwei Chuai, Moritz Pilarski, Gabriele Lenzini, and Nicolas Pröllochs. 2024. Community notes reduce the spread of misleading posts on X. (2024)
2024
-
[20]
Yuwei Chuai, Haoye Tian, Nicolas Pröllochs, and Gabriele Lenzini. 2024. Did the roll-out of community notes reduce engagement with misinformation on X/Twitter?Proceedings of the ACM on human-computer interaction8, CSCW2 (2024), 1–52
2024
-
[21]
Yuwei Chuai, Shuning Zhang, Ziming Wang, Xin Yi, Mohsen Mosleh, and Gabriele Lenzini. 2025. Request a Note: How the Request Function Shapes X’s Community Notes System.arXiv preprint arXiv:2509.09956(2025)
arXiv 2025
-
[22]
Sunhao Dai, Yuqi Zhou, Liang Pang, Weihao Liu, Xiaolin Hu, Yong Liu, Xiao Zhang, Gang Wang, and Jun Xu. 2024. Neural retrievers are biased towards llm-generated content. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 526–537
2024
-
[23]
Laurence Dierickx and Carl-Gustav Lindén. 2023. Journalism and fact-checking technologies: Understanding user needs.communication+ 110, 1 (2023)
2023
-
[24]
Tim Draws, David La Barbera, Michael Soprano, Kevin Roitero, Davide Ceolin, Alessandro Checco, and Stefano Mizzaro. 2022. The effects of crowd worker biases in fact-checking tasks. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 2114–2124
2022
-
[25]
Fiona Draxler, Anna Werner, Florian Lehmann, Matthias Hoppe, Albrecht Schmidt, Daniel Buschek, and Robin Welsch. 2024. The AI ghostwriter effect: When users do not perceive ownership of AI-generated text but self-declare as authors.ACM Transactions on Computer-Human Interaction31, 2 (2024), 1–40
2024
-
[26]
Ziv Epstein, Nicolo Foppiani, Sophie Hilgard, Sanjana Sharma, Elena Glassman, and David Rand. 2022. Do explanations increase the effectiveness of AI-crowd generated fake news warnings?. InProceedings of the International AAAI Confer- ence on Web and Social Media, Vol. 16. 183–193
2022
-
[27]
Jonathan L Freedman and David O Sears. 1965. Selective exposure. InAdvances in experimental social psychology. Vol. 2. Elsevier, 57–97
1965
-
[28]
Liye Fu, Benjamin Newman, Maurice Jakesch, and Sarah Kreps. 2023. Com- paring sentence-level suggestions to message-level suggestions in AI-mediated communication. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–13
2023
-
[29]
The Data Says Otherwise
Yu Fu, Shunan Guo, Jane Hoffswell, Victor S. Bursztyn, Ryan Rossi, and John Stasko. 2024. " The Data Says Otherwise"—Towards Automated Fact-checking and Communication of Data Claims. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–20
2024
-
[30]
Daniel Fürst, Mennatallah El-Assady, Daniel A Keim, and Maximilian T Fis- cher. 2025. Challenges and Opportunities for Visual Analytics in Jurisprudence. Artificial Intelligence and Law(2025), 1–32
2025
-
[31]
William Godel, Zeve Sanderson, Kevin Aslett, Jonathan Nagler, Richard Bonneau, Nathaniel Persily, and Joshua A Tucker. 2021. Moderating with the mob: Eval- uating the efficacy of real-time crowdsourced fact-checking.Journal of Online Trust and Safety1, 1 (2021)
2021
-
[32]
Lucas Graves and Michelle Amazeen. 2019. Fact-checking as idea and practice in journalism. (2019)
2019
-
[33]
2025.Towards Automating Citation Worthiness Detection for Sen- tences in Low-Resource Languages
Aida Halitaj. 2025.Towards Automating Citation Worthiness Detection for Sen- tences in Low-Resource Languages. Ph. D. Dissertation. Queen Mary University of Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. London
2025
-
[34]
Sandra G Hart and Lowell E Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. InAdvances in psy- chology. Vol. 52. Elsevier, 139–183
1988
-
[35]
Naeemul Hassan, Fatma Arslan, Chengkai Li, and Mark Tremayne. 2017. Toward automated fact-checking: Detecting check-worthy factual claims by claimbuster. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 1803–1812
2017
-
[36]
Gaole He, Stefan Buijsman, and Ujwal Gadiraju. 2023. How stated accuracy of an AI system and analogies to explain accuracy affect human reliance on the system. Proceedings of the ACM on Human-Computer Interaction7, CSCW2 (2023), 1–29
2023
-
[37]
Gaole He, Lucie Kuiper, and Ujwal Gadiraju. 2023. Knowing about knowing: An illusion of human competence can hinder appropriate reliance on AI systems. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–18
2023
-
[38]
Andreas Hinderks. 2017. Design and evaluation of a short version of the user experience questionnaire (UEQ-S).International Journal of Interactive Multimedia and Artificial Intelligence(2017)
2017
-
[39]
Qisheng Hu, Quanyu Long, and Wenya Wang. 2025. Decomposition Dilemmas: Does Claim Decomposition Boost or Burden Fact-Checking Performance?. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 6313–6336
2025
-
[40]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
-
[41]
Alon Jacovi and Yoav Goldberg. 2020. Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?. InProceedings of the 58th annual meeting of the association for computational linguistics. 4198–4205
2020
-
[42]
Farnaz Jahanbakhsh, Yannis Katsis, Dakuo Wang, Lucian Popa, and Michael Muller. 2023. Exploring the use of personalized AI for identifying misinformation on social media. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–27
2023
-
[43]
Eunchae Jang, Hui Min Lee, Sangwook Lee, Yongnam Jung, and S Shyam Sundar
-
[44]
InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems
Too good to be false: How photorealism promotes susceptibility to mis- information. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–8
-
[45]
Jiun-Yin Jian, Ann M Bisantz, and Colin G Drury. 2000. Foundations for an empirically determined scale of trust in automated systems.International journal of cognitive ergonomics4, 1 (2000), 53–71
2000
-
[46]
Junqi Jiang, Tom Bewley, Salim I Amoukou, Francesco Leofante, Antonio Rago, Saumitra Mishra, and Francesca Toni. 2025. Representation Consistency for Accurate and Coherent LLM Answer Aggregation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[47]
Yifan Jiang, Cong Zhang, Bofei Zhang, Yifan Yang, Bingzhang Wang, and Yew- Soon Ong. 2026. From Pixels to Facts (Pix2Fact): Benchmarking Multi-Hop Reasoning for Fine-Grained Visual Fact Checking.arXiv preprint arXiv:2602.00593 (2026)
Pith/arXiv arXiv 2026
-
[48]
Prerna Juneja and Tanushree Mitra. 2022. Human and technological infrastruc- tures of fact-checking.Proceedings of the ACM on Human-Computer Interaction6, CSCW2 (2022), 1–36
2022
-
[49]
Jiho Kim, Sungjin Park, Yeonsu Kwon, Yohan Jo, James Thorne, and Edward Choi
-
[50]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
FactKG: Fact verification via reasoning on knowledge graphs. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16190–16206
-
[51]
Mio Kobayashi, Ai Ishii, Chikara Hoshino, Hiroshi Miyashita, and Takuya Mat- suzaki. 2017. Automated historical fact-checking by passage retrieval, word statistics, and virtual question-answering. InProceedings of the Eighth Interna- tional Joint Conference on Natural Language Processing (Volume 1: Long Papers). 967–975
2017
-
[52]
Allison Koenecke, Jed Stiglitz, David Mimno, and Matthew Wilkens. 2025. Tasks and roles in legal ai: Data curation, annotation, and verification.arXiv preprint arXiv:2504.01349(2025)
arXiv 2025
-
[53]
Neema Kotonya and Francesca Toni. 2020. Explainable automated fact-checking for public health claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 7740–7754
2020
-
[54]
David La Barbera, Kevin Roitero, Stefano Mizzaro, et al. 2022. A Hybrid Human- In-The-Loop Framework for Fact Checking.. InNL4AI@ AI* IA. 13–23
2022
-
[55]
Duo Lan, Yicheng Zhu, Meiyu Liu, and Chuge He. 2025. AI Agency in Fact- Checking: Role-Based Machine Heuristics and Publics’ Conspiratorial Orienta- tion.Media and Communication13 (2025)
2025
-
[56]
Hao-Ping Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, and Nicholas Wilson. 2025. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. InProceedings of the 2025 CHI conference on human factors in computing systems. 1–22
2025
-
[57]
Haiwen Li, Soham De, Manon Revel, Andreas Haupt, Brad Miller, Keith Coleman, Jay Baxter, Martin Saveski, and Michiel Bakker. 2025. Scaling Human Judgment in Community Notes with LLMs.Journal of Online Trust and Safety3, 1 (2025)
2025
-
[58]
Q Vera Liao and Kush R Varshney. 2021. Human-centered explainable ai (xai): From algorithms to user experiences.arXiv preprint arXiv:2110.10790(2021)
arXiv 2021
-
[59]
Gionnieve Lim and Simon T Perrault. 2023. XAI in Automated Fact-Checking? The Benefits Are Modest and There’s No One-Explanation-Fits-All. InProceedings of the 35th Australian Computer-Human Interaction Conference. 624–638
2023
-
[60]
Houjiang Liu, Anubrata Das, Alexander Boltz, Didi Zhou, Daisy Pinaroc, Matthew Lease, and Min Kyung Lee. 2024. Human-centered NLP Fact-checking: Co- Designing with Fact-checkers using Matchmaking for AI.Proceedings of the ACM on Human-Computer Interaction8, CSCW2 (2024), 1–44
2024
-
[61]
Houjiang Liu, Jacek Gwizdka, and Matthew Lease. 2025. Exploring Multidimen- sional Checkworthiness: Designing AI-assisted Claim Prioritization for Human Fact-checkers.Proceedings of the ACM on Human-Computer Interaction9, 7 (2025), 1–49
2025
-
[62]
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D Man- ning, and Daniel E Ho. 2025. Hallucination-free? Assessing the reliability of leading AI legal research tools.Journal of empirical legal studies22, 2 (2025), 216–242
2025
-
[63]
David M Markowitz, Timothy R Levine, Kim B Serota, and Alivia D Moore. 2023. Cross-checking journalistic fact-checkers: The role of sampling and scaling in interpreting false and misleading statements.Plos one18, 7 (2023), e0289004
2023
-
[64]
Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and inter-rater reliability in qualitative research: Norms and guidelines for CSCW and HCI practice.Proceedings of the ACM on human-computer interaction3, CSCW (2019), 1–23
2019
-
[65]
Nicholas Micallef, Vivienne Armacost, Nasir Memon, and Sameer Patil. 2022. True or false: Studying the work practices of professional fact-checkers.Proceedings of the ACM on Human-Computer Interaction6, CSCW1 (2022), 1–44
2022
-
[66]
Serge Moscovici and Claude Faucheux. 1972. Social influence, conformity bias, and the study of active minorities. InAdvances in experimental social psychology. Vol. 6. Elsevier, 149–202
1972
-
[67]
2025.Multi-Stage LLM Reasoning for Automated Detection and Classification of High-Impact Misinformation
Anushka Manchanda Nair. 2025.Multi-Stage LLM Reasoning for Automated Detection and Classification of High-Impact Misinformation. Ph. D. Dissertation. Massachusetts Institute of Technology
2025
-
[68]
P Nakov, D Corney, M Hasanain, F Alam, T Elsayed, A Barron-Cedeno, P Papotti, S Shaar, G Da San Martino, et al. 2021. Automated Fact-Checking for Assisting Human Fact-Checkers. InIJCAI. International Joint Conferences on Artificial Intelligence, 4551–4558
2021
-
[69]
An T Nguyen, Aditya Kharosekar, Saumyaa Krishnan, Siddhesh Krishnan, Eliza- beth Tate, Byron C Wallace, and Matthew Lease. 2018. Believe it or not: designing a human-ai partnership for mixed-initiative fact-checking. InProceedings of the 31st annual ACM symposium on user interface software and technology. 189–199
2018
-
[70]
Margit E Oswald and Stefan Grosjean. 2004. Confirmation bias.Cognitive illusions: A handbook on fallacies and biases in thinking, judgement and memory79 (2004), 83
2004
-
[71]
Liangming Pan, Xiaobao Wu, Xinyuan Lu, Luu Anh Tuan, William Yang Wang, Min-Yen Kan, and Preslav Nakov. 2023. Fact-checking complex claims with program-guided reasoning. InProceedings of the 61st annual meeting of the asso- ciation for computational linguistics (volume 1: Long papers). 6981–7004
2023
-
[72]
Is this professionally correct?
Brandon Patterson, Anne R Diekema, Elizabeth Betsy S Hopkins, Duane Wilson, and Nena Schvaneveldt. 2025. “Is this professionally correct?”: understanding the criteria nurses use to evaluate information.Journal of the Medical Library Association: JMLA113, 4 (2025), 298
2025
-
[73]
Vitali Petsiuk, Rajiv Jain, Varun Manjunatha, Vlad I Morariu, Ashutosh Mehra, Vicente Ordonez, and Kate Saenko. 2021. Black-box explanation of object detec- tors via saliency maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11443–11452
2021
-
[74]
Kashyap Popat, Subhabrata Mukherjee, Andrew Yates, and Gerhard Weikum
-
[75]
InProceedings of the 2018 conference on empirical methods in natural language processing
Declare: Debunking fake news and false claims using evidence-aware deep learning. InProceedings of the 2018 conference on empirical methods in natural language processing. 22–32
2018
-
[76]
Subhey Sadi Rahman, Md Adnanul Islam, Md Mahbub Alam, Musarrat Zeba, Md Abdur Rahman, Sadia Sultana Chowa, Mohaimenul Azam Khan Raiaan, and Sami Azam. 2026. Hallucination to truth: a review of fact-checking and factuality evaluation in large language models.Artificial Intelligence Review(2026)
2026
-
[77]
Why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should i trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144
2016
-
[78]
Giuseppe Romeo and Daniela Conti. 2026. Exploring automation bias in human– AI collaboration: a review and implications for explainable AI.AI & SOCIETY41, 1 (2026), 259–278
2026
-
[79]
Mohammed Saeed, Nicolas Traub, Maelle Nicolas, Gianluca Demartini, and Paolo Papotti. 2022. Crowdsourced fact-checking at Twitter: How does the crowd compare with experts?. InProceedings of the 31st ACM international conference on information & knowledge management. 1736–1746. CANote: Empowering Fact-checking Note Writing Through Scaffolded and Provenance...
2022
-
[80]
Max Schemmer, Niklas Kühl, Carina Benz, and Gerhard Satzger. 2022. On the In- fluence of Explainable AI on Automation Bias. InProceedings of the 30th European Conference on Information Systems (ECIS), Timis,oara, RO, June 18-24, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.