REMEDI: A Benchmark for Retention and Unlearning Evaluation in Multi-label Clinical Disease Inference
Pith reviewed 2026-06-27 22:17 UTC · model grok-4.3
The pith
Existing machine unlearning methods show a clear trade-off between retained model utility and successful removal of specific patient data in multi-label clinical disease inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
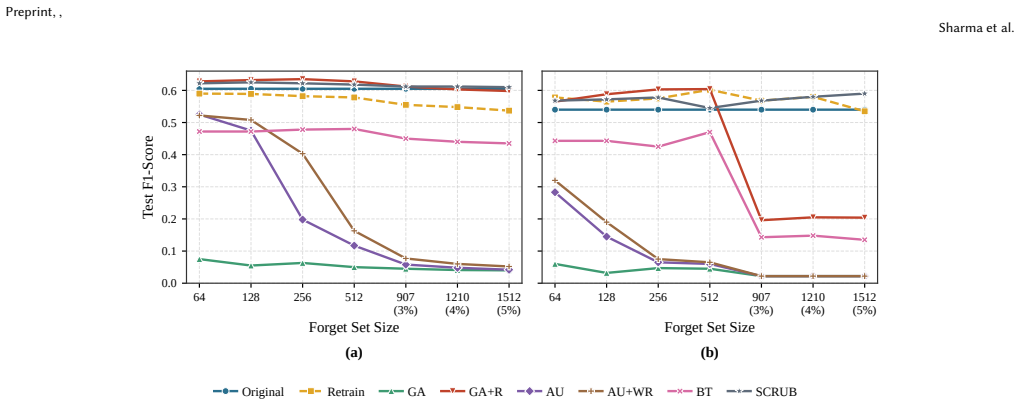
REMEDI supplies a standardized evaluation suite for retention and unlearning on real clinical records, where experiments with prior unlearning algorithms reveal an inherent utility-unlearning trade-off and show that those algorithms remain largely unsuitable for multi-label classification tasks.
What carries the argument
The REMEDI benchmark, which defines diverse forget-instance sets, multi-label and multi-class tasks, and joint metrics for utility retention and unlearning success on longitudinal MIMIC-III data.
If this is right
- New unlearning algorithms will need to handle label correlations explicitly to succeed in medical settings.
- Practical deployment of clinical inference models may require hybrid retention-unlearning pipelines rather than pure removal techniques.
- Regulatory or patient-driven data-deletion requests will likely force accuracy losses unless the trade-off is resolved.
- Benchmarking on real longitudinal records, rather than synthetic data, exposes limitations hidden by simpler testbeds.
Where Pith is reading between the lines
- If the observed trade-off holds across larger models, hospitals may need to maintain separate models for different patient cohorts rather than a single shared model.
- The longitudinal structure noted in the benchmark suggests that time-aware forgetting mechanisms could become a useful research direction.
- Success on REMEDI could serve as a minimum viability test before any clinical unlearning method is considered for regulatory review.
Load-bearing premise
That the chosen forget instances and metrics capture the real privacy-removal requests that would arise in clinical practice without introducing selection bias.
What would settle it
An experiment in which at least one existing unlearning method achieves both high unlearning scores and undiminished multi-label accuracy on the REMEDI test splits would falsify the reported trade-off.
Figures

read the original abstract
Language models trained for clinical disease inference are trained on patient data, which may include sensitive and private information, and data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning patient-specific data is intractable, and retraining with minor data removal is resource-intensive. While there exists several machine unlearning methods that can be used, their utility is generally restricted to non-medical domains. Moreover, the existing benchmarks for evaluating such unlearning methods primarily utilize synthetically curated datasets, which are not truly representative of real-world systems. Hence, the effectiveness of these unlearning methods in the medical domain is largely unclear. To this end, we introduce REMEDI, an extensive benchmark for machine unlearning tailored to multi-label and multiclass clinical disease inference, where label correlations, longitudinal structure, and safety constraints make unlearning particularly challenging. Unlike the existing benchmarks, REMEDI considers: (1) a relevant application domain (medical), (2) comprehensive unlearning setups involving diverse sets of forget instances, (3) challenging unlearning scenarios including multi-label and multi-class classification tasks, and (4) evaluation metrics involving performance both in terms of utility and extent of unlearning achieved. REMEDI is developed using the MIMIC-III clinical database that contains comprehensive clinical data of patients. Experiments with existing unlearning methods indicate that there exists a trade-off between utility and unlearning performance. They are also largely unsuited to multi-label classification tasks. To facilitate reproducibility, we make our benchmark publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REMEDI, a benchmark for machine unlearning in multi-label and multiclass clinical disease inference built on the MIMIC-III database. It claims that label correlations, longitudinal structure, and safety constraints make unlearning particularly challenging in this domain; that existing unlearning methods exhibit a utility-unlearning trade-off; and that these methods are largely unsuited to multi-label tasks. The benchmark incorporates diverse forget-instance sets, utility and unlearning metrics, and is released publicly to support reproducibility.
Significance. If the forget sets and metrics prove representative of real clinical privacy requests, REMEDI would supply a needed domain-specific evaluation resource for privacy-preserving ML in medicine, where data removal requests are increasingly common. The use of real longitudinal clinical records rather than synthetic data and the public release of the benchmark are concrete strengths that would aid future method development.
major comments (1)
- [Abstract (REMEDI design paragraph)] Abstract (REMEDI design paragraph): the claim that 'the chosen forget instances and metrics in REMEDI accurately capture real-world privacy requests' is load-bearing for the central finding of a utility-unlearning trade-off and unsuitability for multi-label tasks, yet the text supplies no explicit selection criteria for forget patients from MIMIC-III (random sampling, disease-specific, longitudinal span, or full-record deletion). Without such criteria or a matching argument to typical clinical removal requests, the observed trade-off could be an artifact of the benchmark construction rather than a general property.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on the abstract's description of forget-instance selection below.
read point-by-point responses
-
Referee: Abstract (REMEDI design paragraph): the claim that 'the chosen forget instances and metrics in REMEDI accurately capture real-world privacy requests' is load-bearing for the central finding of a utility-unlearning trade-off and unsuitability for multi-label tasks, yet the text supplies no explicit selection criteria for forget patients from MIMIC-III (random sampling, disease-specific, longitudinal span, or full-record deletion). Without such criteria or a matching argument to typical clinical removal requests, the observed trade-off could be an artifact of the benchmark construction rather than a general property.
Authors: We agree that the abstract would benefit from greater precision on this point. The full manuscript (Section 3.2) constructs the forget sets via a combination of random sampling stratified by disease prevalence and record length, plus targeted selection of patients with multi-visit longitudinal data to simulate full-record deletion requests. We will revise the abstract to briefly state these criteria and add a short paragraph in the introduction linking them to common clinical privacy scenarios (e.g., GDPR Article 17 or HIPAA patient-requested record removal). This revision will make explicit that the benchmark aims to reflect representative rather than exhaustive real-world conditions. revision: yes
Circularity Check
No circularity: benchmark construction with empirical reporting only
full rationale
The paper introduces REMEDI as a new benchmark dataset and reports experimental results on existing unlearning methods. No derivation chain, first-principles predictions, fitted parameters renamed as predictions, or self-referential equations exist. Claims about trade-offs are direct empirical observations from running methods on the benchmark, not reductions to inputs by construction. The design choices (forget sets, metrics) are presented as deliberate but are not shown to be equivalent to the reported outcomes via any definitional loop. Self-citations, if present, are not load-bearing for any central result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MIMIC-III clinical database contains comprehensive clinical data of patients suitable for multi-label disease inference benchmarks.
Reference graph
Works this paper leans on
-
[1]
Health Care Financing Administration
United States. Health Care Financing Administration. 1991.ICD-9-CM Official Guidelines for Coding and Reporting. US Department of Health and Human Services
1991
-
[2]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hen- grui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. In2021 IEEE symposium on security and privacy (SP). IEEE, 141–159
2021
-
[3]
Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In2015 IEEE symposium on security and privacy. IEEE, 463–480
2015
-
[4]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. 2022. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP). IEEE, 1897–1914
2022
-
[5]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
2021
-
[6]
Sungmin Cha, Sungjun Cho, Dasol Hwang, Honglak Lee, Taesup Moon, and Moontae Lee. 2024. Learning to unlearn: Instance-wise unlearning for pre- trained classifiers. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 11186–11194
2024
-
[7]
Jiali Cheng and Hadi Amiri. 2024. Mu-bench: A multitask multimodal benchmark for machine unlearning.arXiv preprint arXiv:2406.14796(2024)
arXiv 2024
-
[8]
Dasol Choi and Dongbin Na. 2023. Towards machine unlearning benchmarks: Forgetting the personal identities in facial recognition systems.arXiv preprint arXiv:2311.02240(2023)
arXiv 2023
-
[9]
Stewart, and Jimeng Sun
Edward Choi, Siddharth Biswal, Bradley Malin, Jon Duke, Walter F. Stewart, and Jimeng Sun. 2017. Generating Multi-label Discrete Patient Records using Generative Adversarial Networks. InProceedings of the 2nd Machine Learning for Healthcare Conference (Proceedings of Machine Learning Research, Vol. 68), Finale Doshi-Velez, Jim Fackler, David Kale, Rajesh ...
2017
-
[10]
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan Kankanhalli
-
[11]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Can bad teaching induce forgetting? unlearning in deep networks us- ing an incompetent teacher. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 7210–7217
-
[12]
Ronen Eldan and Mark Russinovich. [n. d.]. Who’s harry potter? approximate unlearning in llms, 2023.URL https://arxiv. org/abs/2310.022381, 2 ([n. d.]), 8
arXiv 2023
-
[13]
União Europeia. 2006. European Parliament and Council of the European Union. Recommendation of the European Parliament and of the Council of18 (2006)
2006
-
[14]
Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. 2019. Making ai forget you: Data deletion in machine learning.Advances in neural information processing systems32 (2019)
2019
-
[15]
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. 2020. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9304–9312
2020
-
[16]
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. 2020. Forgetting outside the box: Scrubbing deep networks of information accessible from input-output observations. InEuropean Conference on Computer Vision. Springer, 383–398
2020
-
[17]
Lawrence O Gostin, Laura A Levit, and Sharyl J Nass. 2009. Beyond the HIPAA privacy rule: enhancing privacy, improving health through research.National Academies Press(2009)
2009
-
[18]
Varun Gupta, Christopher Jung, Seth Neel, Aaron Roth, Saeed Sharifi-Malvajerdi, and Chris Waites. 2021. Adaptive machine unlearning.Advances in Neural Information Processing Systems34 (2021), 16319–16330
2021
-
[19]
Esraa Hassan, Tarek Abd El-Hafeez, and Mahmoud Y Shams. 2024. Optimizing classification of diseases through language model analysis of symptoms.Scientific reports14, 1 (2024), 1507
2024
-
[20]
Shengyuan Hu, Neil Kale, Pratiksha Thaker, Yiwei Fu, Steven Wu, and Virginia Smith. 2025. BLUR: A Benchmark for LLM Unlearning Robust to Forget-Retain Overlap.arXiv preprint arXiv:2506.15699(2025)
arXiv 2025
-
[21]
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. 2024. Rwku: Benchmarking real-world knowledge unlearning for large language models.Advances in Neural Information Processing Systems37 (2024), 98213–98263
2024
-
[22]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database.Scientific data3, 1 (2016), 1–9
2016
-
[23]
Jitendra Jonnagaddala and Zoie Shui-Yee Wong. 2025. Privacy preserving strate- gies for electronic health records in the era of large language models.npj Digital Medicine8, 1 (2025), 34
2025
-
[24]
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou
-
[25]
Towards unbounded machine unlearning.Advances in neural information processing systems36 (2023), 1957–1987
2023
-
[26]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics36, 4 (2020), 1234–1240
2020
-
[27]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, et al
-
[28]
InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol
The WMDP Benchmark: Measuring and Reducing Malicious Use with Un- learning. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (Eds.). PMLR, 28525–28550. https:/...
-
[29]
Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. 2020. Federated unlearning.arXiv preprint arXiv:2012.13891(2020)
arXiv 2020
-
[30]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. 2024. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121(2024)
Pith/arXiv arXiv 2024
-
[31]
Zabir Al Nazi and Wei Peng. 2024. Large language models in healthcare and medical domain: A review. InInformatics, Vol. 11. MDPI, 57
2024
-
[32]
CA OAG. 2021. Ccpa regulations: Final regulation text.Office of the Attorney General, California Department of Justice(2021), 1
2021
-
[33]
Jasmine Chiat Ling Ong, Shelley Yin-Hsi Chang, Wasswa William, Atul J Butte, Nigam H Shah, Lita Sui Tjien Chew, Nan Liu, Finale Doshi-Velez, Wei Lu, Julian Savulescu, et al. 2024. Ethical and regulatory challenges of large language models in medicine.The Lancet Digital Health6, 6 (2024), e428–e432
2024
-
[34]
Ayush Sekhari, Jayadev Acharya, Gautam Kamath, and Ananda Theertha Suresh
-
[35]
Advances in Neural Information Processing Systems34 (2021), 18075–18086
Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems34 (2021), 18075–18086
2021
-
[36]
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A Smith, and Chiyuan Zhang
-
[37]
Muse: Machine unlearning six-way evaluation for language models.arXiv preprint arXiv:2407.06460(2024)
arXiv 2024
-
[38]
Betty van Aken, Jens-Michalis Papaioannou, Manuel Mayrdorfer, Klemens Budde, Felix Gers, and Alexander Loeser. 2021. Clinical Outcome Prediction from Ad- mission Notes using Self-Supervised Knowledge Integration. InProceedings of the 16th Conference of the European Chapter of the Association for Com- putational Linguistics: Main Volume, Paola Merlo, Jorg ...
-
[39]
Leon Wichert and Sandipan Sikdar. 2024. Rethinking Evaluation Methods for Machine Unlearning. InFindings of the Association for Computational Linguis- tics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 4727–4739. doi:10.18653/v1/2024.findings-emnlp.271
-
[40]
Jin Yao, Eli Chien, Minxin Du, Xinyao Niu, Tianhao Wang, Zezhou Cheng, and Xiang Yue. 2024. Machine unlearning of pre-trained large language models.arXiv preprint arXiv:2402.15159(2024)
arXiv 2024
-
[41]
Michihiro Yasunaga, Jure Leskovec, and Percy Liang. 2022. LinkBERT: Pretrain- ing Language Models with Document Links. InAssociation for Computational Linguistics (ACL)
2022
-
[42]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF). IEEE, 268–282
2018
-
[43]
Ziyang Zhang. 2025. MMDU-Bench: Multi-modal Deep Unlearning Benchmark. InThe First Workshop on Multimodal Knowledge and Language Modeling
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.