Consistent-Inversion: Reverse Consistency Guidance for Structure-Preserving Visual Editing
Pith reviewed 2026-06-27 22:13 UTC · model grok-4.3
The pith
Consistent-Inversion corrects target denoising paths by reversing them toward the source trajectory under the original prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
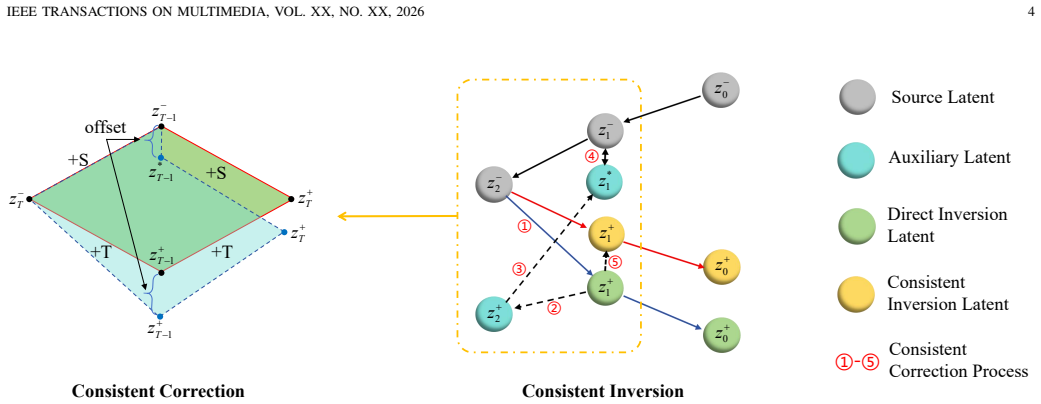
Instead of reusing the inverted source latent directly, Consistent-Inversion checks whether an intermediate point on the target trajectory can be reversed back toward the source inversion trajectory when conditioned on the source prompt; the measured discrepancy supplies a guidance signal that adjusts selected early denoising steps of the target process, thereby reducing trajectory mismatch without updating model weights.
What carries the argument
Reverse consistency guidance: an auxiliary target-side noise representation plus source-guided reverse denoising that yields a discrepancy signal used to correct early target denoising steps.
If this is right
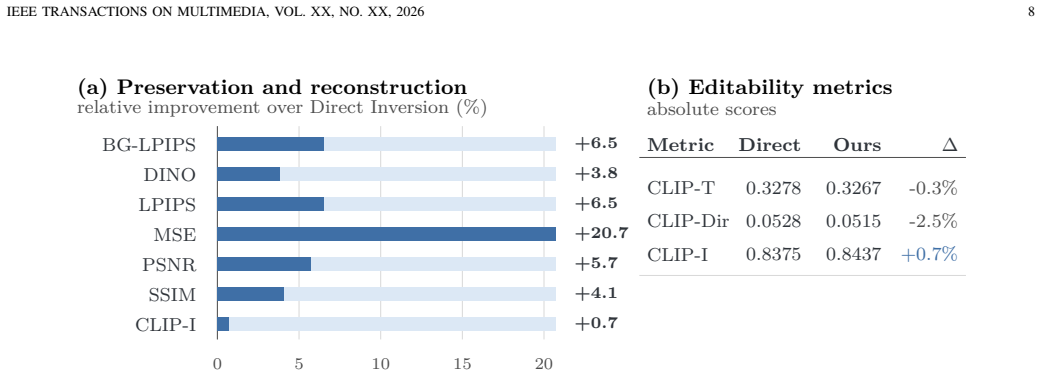
- Background and structural fidelity improve on PIE-Bench under a unified SD3.5 protocol.
- Target-prompt alignment is maintained at the same level as the uncorrected baseline.
- The same correction principle applies to classical Stable-Diffusion inversion pipelines without retraining.
- Only sparse application is needed, keeping added inference cost small.
- No model parameters are updated, preserving compatibility with any inversion-based editor.
Where Pith is reading between the lines
- The same reverse-consistency check could be applied to other diffusion editing tasks such as inpainting where source structure must survive.
- Sparser or denser application schedules might trade edit strength against fidelity in a controllable way.
- The auxiliary noise construction might extend to multi-step consistency checks beyond the early denoising window described.
Load-bearing premise
The discrepancy obtained from reversing a target intermediate latent under the source prompt actually measures and corrects harmful trajectory mismatch rather than introducing unrelated artifacts or blocking the intended edit.
What would settle it
Run the method on PIE-Bench with the SD3.5 protocol and observe whether structural similarity scores rise, fall, or stay flat compared with the baseline while target-prompt alignment remains unchanged.
Figures


read the original abstract
Text-guided diffusion models have become effective tools for real-image visual editing, where the edited image must follow a target instruction while preserving editing-irrelevant structure. Most training-free editors rely on inversion: a source image is mapped to a noisy latent trajectory and the terminal latent is reused for target-prompt denoising. This reuse is useful for preservation, but it also couples source reconstruction and target editing. The resulting trajectory mismatch may either damage background/layout details or over-constrain the intended edit. This paper presents Consistent-Inversion, a training-free reverse consistency guidance framework for structure-preserving visual editing. Instead of treating the inverted source latent as a fixed initialization, Consistent-Inversion checks whether an intermediate target trajectory can be reversed toward the source inversion trajectory under the source prompt. To make this check well-defined, we construct an auxiliary target-side noise representation, perform source-guided reverse denoising, and use the resulting reverse consistency discrepancy as a correction signal for selected early target denoising steps. The method does not update model parameters, is compatible with inversion-based editors, and introduces only a small inference overhead when applied sparsely. Experiments on PIE-Bench show that Consistent-Inversion improves background and structural fidelity under a unified SD3.5 protocol while maintaining target-prompt alignment, and compatibility experiments further verify the same correction principle on classical Stable-Diffusion inversion pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Consistent-Inversion, a training-free framework for structure-preserving visual editing with text-guided diffusion models. It identifies trajectory mismatch between source inversion and target editing as a source of fidelity loss or over-constraint, then introduces reverse consistency guidance: an auxiliary target-side noise representation is constructed, source-guided reverse denoising is performed, and the resulting discrepancy is applied as a correction signal to selected early steps of the target trajectory. The method is compatible with existing inversion-based editors, adds only sparse inference overhead, and is evaluated on PIE-Bench under a unified SD3.5 protocol plus compatibility tests on classical Stable Diffusion pipelines, claiming improved background/structural fidelity while preserving target-prompt alignment.
Significance. If the central mechanism is shown to work reliably, the approach supplies a lightweight, training-free correction principle that can be grafted onto many existing inversion editors. The emphasis on reverse consistency (rather than forward regularization) and the reported compatibility across pipelines are potentially useful contributions to the editing literature.
major comments (3)
- [Abstract, §3] Abstract and §3 (method description): the auxiliary target-side noise representation and the precise rule for injecting the reverse consistency discrepancy (additive guidance, scaling factor, masking, or selection of early steps) are described only at a high level with no equations or pseudocode. This construction is load-bearing for the fidelity claim; without it the reader cannot verify whether the discrepancy reliably corrects structure without injecting source artifacts or over-constraining the edit.
- [§4] §4 (experiments): the PIE-Bench results are summarized as improved background and structural fidelity, yet no quantitative tables, error bars, ablation on the sparsity parameter, or direct measurement of the discrepancy signal’s contribution appear in the provided description. The central claim that the correction improves fidelity without harming prompt alignment therefore rests on unshown evidence.
- [§3.3] §3.3 (compatibility experiments): the claim that the same correction principle transfers to classical Stable Diffusion inversion pipelines is asserted, but no implementation equations, hyper-parameter settings, or failure-case analysis are supplied, leaving open whether the auxiliary-noise construction generalizes or requires pipeline-specific tuning.
minor comments (2)
- [§3] Notation for the auxiliary noise and discrepancy signal should be introduced with explicit symbols and a short algorithm box to aid reproducibility.
- [Abstract, §4] The abstract states “small inference overhead when applied sparsely”; a brief complexity or timing table would make this concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarity of the method and strength of the experimental evidence. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the auxiliary target-side noise representation and the precise rule for injecting the reverse consistency discrepancy (additive guidance, scaling factor, masking, or selection of early steps) are described only at a high level with no equations or pseudocode. This construction is load-bearing for the fidelity claim; without it the reader cannot verify whether the discrepancy reliably corrects structure without injecting source artifacts or over-constraining the edit.
Authors: We agree that the current description is high-level. In the revised manuscript we will add the explicit equations defining the auxiliary target-side noise representation, the source-guided reverse denoising step, and the precise injection rule (including scaling, masking, and early-step selection criteria) in §3. This will make the correction mechanism fully verifiable. revision: yes
-
Referee: [§4] §4 (experiments): the PIE-Bench results are summarized as improved background and structural fidelity, yet no quantitative tables, error bars, ablation on the sparsity parameter, or direct measurement of the discrepancy signal’s contribution appear in the provided description. The central claim that the correction improves fidelity without harming prompt alignment therefore rests on unshown evidence.
Authors: The full experimental section contains quantitative tables comparing background/structural fidelity and prompt alignment on PIE-Bench under the unified SD3.5 protocol. We will ensure these tables, associated error bars, an ablation on the sparsity parameter, and a direct measurement of the discrepancy signal’s contribution are clearly presented and highlighted in the revision. revision: yes
-
Referee: [§3.3] §3.3 (compatibility experiments): the claim that the same correction principle transfers to classical Stable Diffusion inversion pipelines is asserted, but no implementation equations, hyper-parameter settings, or failure-case analysis are supplied, leaving open whether the auxiliary-noise construction generalizes or requires pipeline-specific tuning.
Authors: We will expand §3.3 with the implementation equations for the auxiliary-noise construction on classical Stable Diffusion pipelines, list the exact hyper-parameter settings used in the compatibility tests, and include a brief failure-case analysis discussing when the correction transfers without additional tuning. revision: yes
Circularity Check
No circularity; method introduces independent reverse-consistency correction
full rationale
The abstract and description present Consistent-Inversion as a new training-free guidance technique that constructs an auxiliary target-side noise representation, runs source-guided reverse denoising, and applies the resulting discrepancy as a correction signal. No quoted equations, fitted parameters, or self-citations reduce the claimed fidelity improvement to a self-definition, renamed input, or load-bearing prior result from the same authors. The central premise is an external trajectory check rather than a construction that forces the output by definition. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[2]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 392–18 402
2023
-
[4]
Prompt-to-Prompt Image Editing with Cross Attention Control
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross attention control.(2022),”URL https://arxiv. org/abs/2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng, “Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 560–22 570
2023
-
[6]
Zero- shot image-to-image translation,
G. Parmar, K. Kumar Singh, R. Zhang, Y . Li, J. Lu, and J.-Y . Zhu, “Zero- shot image-to-image translation,” inACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–11
2023
-
[7]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differential equations,”arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Blended diffusion for text- driven editing of natural images,
O. Avrahami, D. Lischinski, and O. Fried, “Blended diffusion for text- driven editing of natural images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 208–18 218
2022
-
[9]
Diffedit: Diffusion- based semantic image editing with mask guidance,
G. Couairon, J. Verbeek, H. Schwenk, and M. Cord, “Diffedit: Diffusion- based semantic image editing with mask guidance,”arXiv preprint arXiv:2210.11427, 2022
-
[10]
Null- text inversion for editing real images using guided diffusion models,
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, and D. Cohen-Or, “Null- text inversion for editing real images using guided diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6038–6047
2023
-
[11]
Prompt tuning inversion for text-driven image editing using diffusion models,
W. Dong, S. Xue, X. Duan, and S. Han, “Prompt tuning inversion for text-driven image editing using diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7430–7440
2023
-
[12]
Edict: Exact diffusion inversion via coupled transformations,
B. Wallace, A. Gokul, and N. Naik, “Edict: Exact diffusion inversion via coupled transformations,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 532–22 541
2023
-
[13]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[14]
Smartedit: Exploring complex instruction- based image editing with multimodal large language models,
Y . Huang, L. Xie, X. Wang, Z. Yuan, X. Cun, Y . Ge, J. Zhou, C. Dong, R. Huang, R. Zhanget al., “Smartedit: Exploring complex instruction- based image editing with multimodal large language models,”arXiv preprint arXiv:2312.06739, 2023
-
[15]
Diffusionclip: Text-guided diffusion models for robust image manipulation,
G. Kim, T. Kwon, and J. C. Ye, “Diffusionclip: Text-guided diffusion models for robust image manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2426–2435
2022
-
[16]
Stylediffusion: Controllable dis- entangled style transfer via diffusion models,
Z. Wang, L. Zhao, and W. Xing, “Stylediffusion: Controllable dis- entangled style transfer via diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7677–7689
2023
-
[17]
Imagic: Text-based real image editing with diffusion models,
B. Kawar, S. Zada, O. Lang, O. Tov, H. Chang, T. Dekel, I. Mosseri, and M. Irani, “Imagic: Text-based real image editing with diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6007–6017
2023
-
[18]
Dragdiffusion: Harnessing diffusion models for interactive point-based image editing,
Y . Shi, C. Xue, J. Pan, W. Zhang, V . Y . Tan, and S. Bai, “Dragdiffusion: Harnessing diffusion models for interactive point-based image editing,” arXiv preprint arXiv:2306.14435, 2023
-
[19]
Plug-and-play diffusion features for text-driven image-to-image translation,
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel, “Plug-and-play diffusion features for text-driven image-to-image translation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1921–1930
2023
-
[20]
Proxedit: Improving tuning- free real image editing with proximal guidance,
L. Han, S. Wen, Q. Chen, Z. Zhang, K. Song, M. Ren, R. Gao, A. Stathopoulos, X. He, Y . Chenet al., “Proxedit: Improving tuning- free real image editing with proximal guidance,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 4291–4301
2024
-
[21]
Ledits++: Limitless image editing using text-to-image models,
M. Brack, F. Friedrich, K. Kornmeier, L. Tsaban, P. Schramowski, K. Kersting, and A. Passos, “Ledits++: Limitless image editing using text-to-image models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[22]
Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models,
D. Miyake, A. Iohara, Y . Saito, and T. Tanaka, “Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models,”arXiv preprint arXiv:2305.16807, 2023
-
[23]
Direct inversion: Boosting diffusion-based editing with 3 lines of code,
X. Ju, A. Zeng, Y . Bian, S. Liu, and Q. Xu, “Direct inversion: Boosting diffusion-based editing with 3 lines of code,”arXiv preprint arXiv:2310.01506, 2023
-
[24]
Renoise: Real image inversion through iterative noising,
D. Garibi, O. Patashnik, A. V oynov, H. Averbuch-Elor, and D. Cohen- Or, “Renoise: Real image inversion through iterative noising,”arXiv preprint arXiv:2403.14602, 2024
-
[25]
Eta inversion: Designing an optimal eta function for diffusion-based real image editing,
W. Kang, K. Galim, and H. I. Koo, “Eta inversion: Designing an optimal eta function for diffusion-based real image editing,” inEuropean Conference on Computer Vision, 2024
2024
-
[26]
Tight inversion: Image-conditioned inversion for real image editing,
E. Kadosh, N. Goren, O. Patashnik, D. Garibi, and D. Cohen-Or, “Tight inversion: Image-conditioned inversion for real image editing,”arXiv preprint arXiv:2502.20376, 2025
-
[27]
Dci: Dual- conditional inversion for boosting diffusion-based image editing,
Z. Li, H. Wang, W. Wang, C. Tan, Y . Wei, and Y . Zhao, “Dci: Dual- conditional inversion for boosting diffusion-based image editing,”arXiv preprint arXiv:2506.02560, 2025
-
[28]
L. Rout, Y . Chen, N. Ruiz, C. Caramanis, S. Shakkottai, and W.-S. Chu, “Semantic image inversion and editing using rectified stochastic differential equations,”arXiv preprint arXiv:2410.10792, 2024
-
[29]
FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
J. Wu, Z. Li, H. Qin, X. Liu, L. Kong, Y . Zhang, and X. Yang, “Flashedit: Decoupling speed, structure, and semantics for precise image editing,” arXiv preprint arXiv:2509.22244, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Steerflow: Steering rectified flows for faithful inversion-based image editing,
T. Dao, Z. Wang, K. T. Pham, and L. Chen, “Steerflow: Steering rectified flows for faithful inversion-based image editing,”arXiv preprint arXiv:2604.01715, 2026
-
[31]
Training-free image inversion for one-step diffusion models,
T. Wu, S. Li, Y . Wang, S. Yang, K. Wang, and J. van de Weijer, “Training-free image inversion for one-step diffusion models,”Pattern Recognition, 2026
2026
-
[32]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[33]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.