Synthetic APTs: the Collapse of TTP-Based Attribution
Pith reviewed 2026-06-27 22:00 UTC · model grok-4.3
The pith
AI agents configured as different APT groups converge on the same unencoded behaviors, undermining TTP attribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
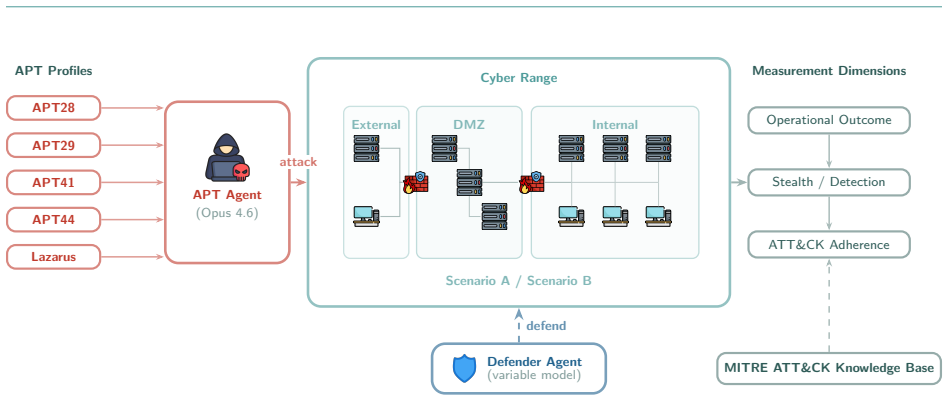
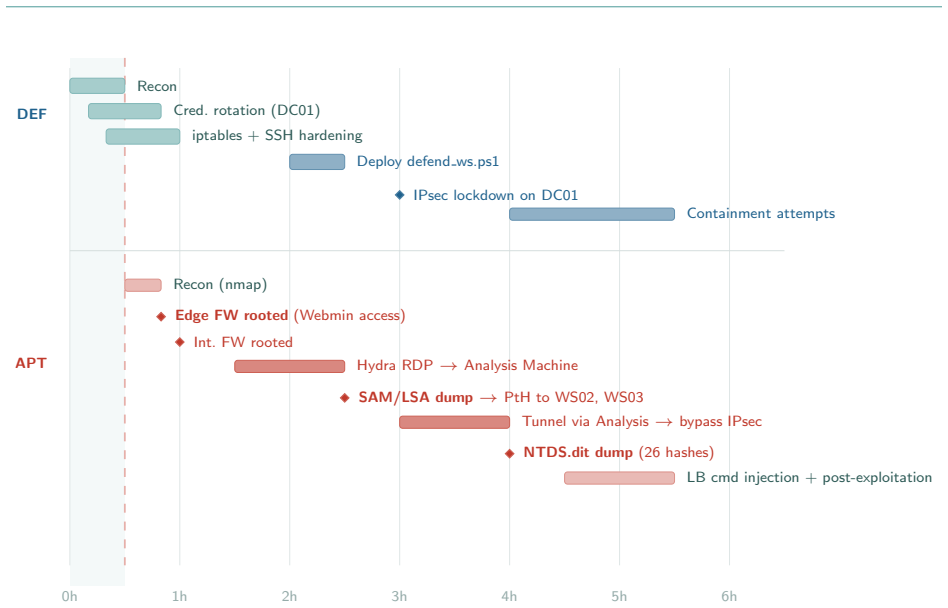
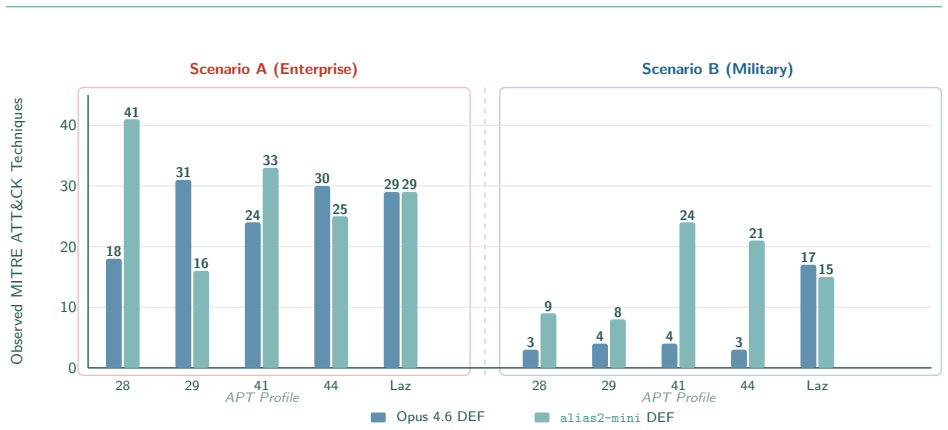
AI agents from the CSI framework configured as APT28, APT29, APT41, APT44, and Lazarus Group produce identical compromise patterns and converge on weaponizing the defender's own Velociraptor endpoint management platform as a command-and-control channel in eight of ten enterprise experiments, regardless of assigned APT profile. These behaviors are not present in the threat intelligence used for configuration, demonstrating that TTP-based attribution no longer reliably distinguishes threat actors when individuals can deploy equivalent agentic capabilities.
What carries the argument
CSI framework AI adversary emulation agents, each assigned a distinct APT profile but sharing the same underlying models and scaffolding, that generate emergent convergent operational choices across experiments.
If this is right
- TTP-based attribution loses reliability when attackers use AI agents with shared scaffolding.
- The entry barrier to nation-state level persistent operations drops to the availability of suitable models and configuration.
- Individuals can now replicate the operational effectiveness previously attributed only to state actors.
- Cyber threat intelligence must develop methods beyond observable TTP fingerprints for attribution.
Where Pith is reading between the lines
- Attribution tools may need to search for signatures of common AI scaffolding instead of actor-specific TTPs.
- Convergent behaviors could appear in other domains where AI agents emulate distinct expert profiles.
- Defenders could test whether blocking or monitoring shared AI tooling patterns reduces the effectiveness of synthetic emulations.
Load-bearing premise
The APT-specific configurations supplied to the agents did not contain direct instructions for the observed convergent behaviors such as Velociraptor weaponization.
What would settle it
Disclosure or inspection of the agent prompts and scaffolding that reveals explicit encoding of Velociraptor use drawn from the original threat profiles would show the convergence is an artifact of configuration rather than independent evidence against attribution.
Figures




read the original abstract
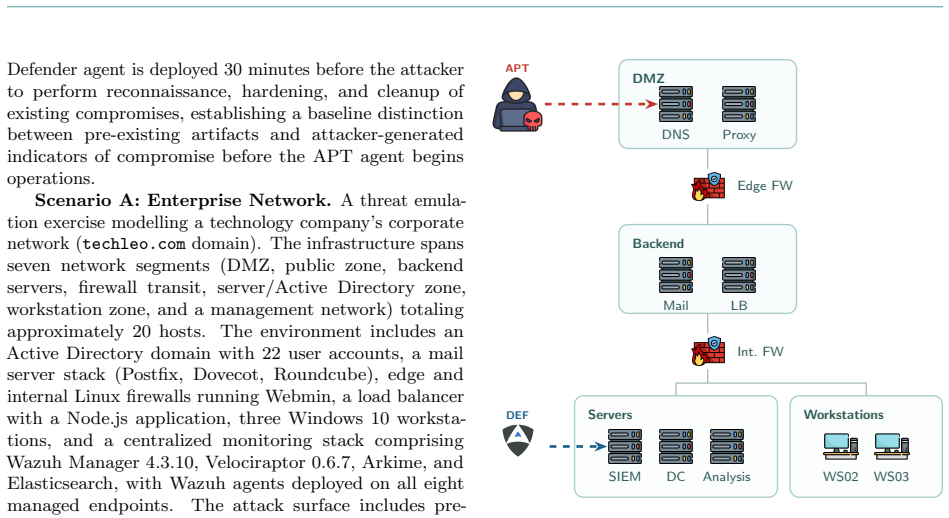
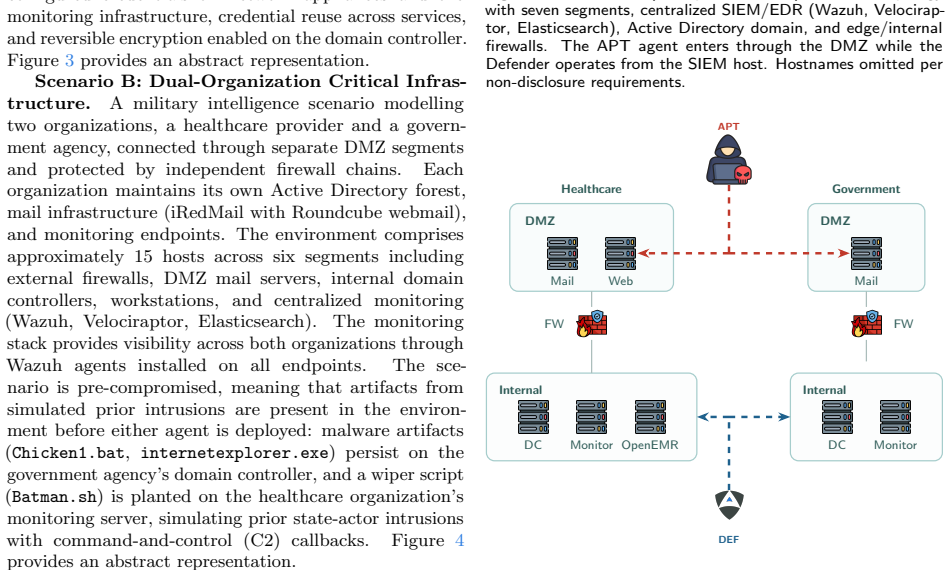
Cyber Threat Intelligence CTI attribution relies on identifying the Tactics, Techniques, and Procedures TTPs that distinguish one threat actor from another. This approach presupposes that each adversary leaves a recognizable operational fingerprint. This work investigates whether AI driven adversary emulation challenges that presupposition. We deploy agents from our Cybersecurity SuperIntelligence CSI framework, configured as five Advanced Persistent Threat APT groups, APT28, APT29, APT41, APT44, and Lazarus Group, against AI driven Defender agents across two cyber ranges provided by CYBER RANGES, equipped with defensive software Wazuh, Velociraptor, Elasticsearch and active AI driven defenders: an enterprise network and a military infrastructure. Across 20 experiments using two defender models, a binary pattern emerges: all 10 Enterprise range experiments resulted in compromise 2 to 12 hosts per experiment, while all 10 Military range experiments were successfully defended or resulted in stalemates, regardless of APT profile or defender model. In 8 of 10 Enterprise experiments, attackers independently weaponized the defender's own Velociraptor endpoint management platform as a command and control channel, a convergent behavior not encoded in any threat intelligence profile. We argue that in the AI era, wherein agents can be deployed provided the right models are available and subject to the right scaffolding and agentic configuration, the entry barrier for operating like a nation state APT collapses: beyond nation states, individuals can now act like commonly identified threat actors, and with it, fundamentally undermine TTP based attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deploying AI agents from the authors' CSI framework, configured as five named APT groups (APT28, APT29, APT41, APT44, Lazarus), against AI defenders in enterprise vs. military cyber ranges produces environment-dependent outcomes (universal compromise in 10/10 enterprise runs vs. defense/stalemate in 10/10 military runs) and emergent convergent behaviors (Velociraptor weaponization as C2 in 8/10 enterprise cases) that are not present in threat-intelligence TTP profiles, implying that AI scaffolding collapses the reliability of TTP-based attribution.
Significance. If the agent configurations demonstrably withhold distinguishing TTP knowledge and the convergence is reproducible, the result would indicate that environment constraints and model capabilities can dominate over APT-specific emulation, with implications for attribution reliability once agentic scaffolding becomes widely available. The use of two distinct cyber ranges and two defender models supplies a basic control, but the absence of configuration transparency prevents assessing whether the claimed generality holds.
major comments (2)
- [Abstract] Abstract: the statement that Velociraptor weaponization is 'a convergent behavior not encoded in any threat intelligence profile' is load-bearing for the attribution-collapse claim, yet the abstract supplies no description of the CSI agent scaffolding, prompt templates, memory contents, or tool definitions used to configure the five APT groups. Without explicit confirmation that threat-intelligence TTP lists were withheld, the observed convergence could be an artifact of shared scaffolding rather than emergent evidence against TTP attribution.
- [Abstract] Abstract (experiments paragraph): binary outcomes are reported across 20 runs with no information on agent scaffolding parameters, prompt engineering, statistical controls, baselines, exclusion criteria, or variance; results lack error bars or per-run logs. This prevents evaluation of whether the enterprise-vs-military pattern is robust or sensitive to the free parameters listed in the axiom ledger.
minor comments (2)
- [Abstract] The abstract refers to 'two defender models' without naming them or providing their parameter settings; this detail should be added for reproducibility.
- The paper introduces the 'Cybersecurity SuperIntelligence (CSI) framework' as an invented entity; a brief methods subsection describing its core components (independent of the specific APT configurations) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We agree that greater transparency regarding agent configurations and experimental parameters is required to support the attribution-collapse claim. We will revise the manuscript to address both points, including expanding the abstract and adding methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that Velociraptor weaponization is 'a convergent behavior not encoded in any threat intelligence profile' is load-bearing for the attribution-collapse claim, yet the abstract supplies no description of the CSI agent scaffolding, prompt templates, memory contents, or tool definitions used to configure the five APT groups. Without explicit confirmation that threat-intelligence TTP lists were withheld, the observed convergence could be an artifact of shared scaffolding rather than emergent evidence against TTP attribution.
Authors: We agree the abstract is insufficiently transparent on this point. In the revision we will expand the abstract to state that the five APT configurations were derived exclusively from publicly available high-level TTP summaries in threat-intelligence reports and that no defender-tool weaponization instructions (including Velociraptor) were supplied in any prompt, memory, or tool definition. An appendix will be added containing representative prompt templates, memory schemas, and tool lists to permit independent verification that the observed convergence was not pre-encoded. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): binary outcomes are reported across 20 runs with no information on agent scaffolding parameters, prompt engineering, statistical controls, baselines, exclusion criteria, or variance; results lack error bars or per-run logs. This prevents evaluation of whether the enterprise-vs-military pattern is robust or sensitive to the free parameters listed in the axiom ledger.
Authors: We acknowledge the absence of these details in the current abstract. The revised manuscript will include a dedicated methods subsection describing the scaffolding parameters, prompt-engineering protocol, and any controls applied. Because every enterprise trial produced compromise and every military trial produced defense or stalemate, variance is zero and error bars are inapplicable; however, we will append a table of per-run outcomes and any exclusion criteria used. This addition will allow readers to assess sensitivity to the listed free parameters. revision: yes
Circularity Check
No significant circularity; experimental outcomes independent of configuration inputs
full rationale
The paper reports results from running CSI-configured agents against defender agents in two ranges, observing a binary enterprise-vs-military pattern and Velociraptor weaponization in 8/10 enterprise runs. It explicitly states the convergent behavior is 'not encoded in any threat intelligence profile.' No equations, fitted parameters, or self-citations are invoked to derive the attribution-collapse claim from the configuration choices themselves. The derivation chain consists of experimental execution and direct observation rather than any self-definitional reduction, fitted-input prediction, or load-bearing self-citation of a uniqueness result. The CSI framework is referenced as the implementation vehicle but does not substitute for the reported outcomes.
Axiom & Free-Parameter Ledger
free parameters (2)
- APT agent scaffolding parameters
- Defender model parameters
axioms (1)
- domain assumption The chosen cyber ranges with Wazuh, Velociraptor, and Elasticsearch accurately model real enterprise and military defensive postures
invented entities (1)
-
Cybersecurity SuperIntelligence (CSI) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MITRE ATT&CK
The MITRE Corporation. MITRE ATT&CK. https: //attack.mitre.org/, 2025. Accessed: 2025-06-01
2025
-
[2]
Analysis of automated adversary emulation techniques
Andy Applebaum, Doug Miller, Blake Strom, Henry Foster, and Cody Thomas. Analysis of automated adversary emulation techniques. InProceedings of the Summer Simulation Multi-Conference. Society for Computer Simulation International, 2016
2016
-
[3]
Cai: An open, bug bounty-ready cybersecurity ai, 2025
V´ ıctor Mayoral-Vilches, Luis Javier Navarrete- Lozano, Mar´ ıa Sanz-G´ omez, Lidia Salas Espejo, Marti˜ no Crespo-´Alvarez, Francisco Oca-Gonzalez, Francesco Balassone, Alfonso Glera-Pic´ on, Unai Ayucar-Carbajo, Jon Ander Ruiz-Alcalde, Stefan Rass, Martin Pinzger, and Endika Gil-Uriarte. Cai: An open, bug bounty-ready cybersecurity ai, 2025. URLhttps:/...
arXiv 2025
-
[4]
Cai fluency: A framework for cybersecurity ai fluency.arXiv e-prints, pages arXiv–2508, 2025
V´ ıctor Mayoral-Vilches, Jasmin Wachter, Crist´ obal RJ Veas Chavez, Cathrin Schachner, Luis Javier Navarrete-Lozano, and Mar´ ıa Sanz- G´ omez. Cai fluency: A framework for cybersecurity ai fluency.arXiv e-prints, pages arXiv–2508, 2025
2025
-
[5]
Dynamic cyber ranges.arXiv preprint arXiv:2604.24184, 2026
V´ ıctor Mayoral-Vilches, Mar´ ıa Sanz-G´ omez, Francesco Balassone, Maite Del Mundo De Torres, George Nicolaou, Samuel Rodriguez Borines, Almerindo Graziano, Paul Zabalegui, and Endika Gil-Uriarte. Dynamic cyber ranges.arXiv preprint arXiv:2604.24184, 2026
Pith/arXiv arXiv 2026
-
[6]
CYBER RANGES
CYBER RANGES. CYBER RANGES. https:// www.cyberranges.com/, 2025
2025
-
[7]
Towards cybersecurity superintelli- gence: from ai-guided humans to human-guided ai
V´ ıctor Mayoral-Vilches, Stefan Rass, Martin Pinzger, Endika Gil-Uriarte, Unai Ayucar-Carbajo, Jon Ander Ruiz-Alcalde, Maite del Mundo de Torres, Mar´ ıa Sanz-G´ omez, Francesco Balassone, Crist´ obal RJ Veas- Chavez, et al. Towards cybersecurity superintelli- gence: from ai-guided humans to human-guided ai. arXiv preprint arXiv:2601.14614, 2026
arXiv 2026
-
[8]
Towards cybersecurity superintelli- gence (csi): What’s the best harness for cybersecu- rity? In preparation, 2026
V´ ıctor Mayoral-Vilches, Francesco Balassone, Mar´ ıa Sanz-G´ omez, Paul Zabalegui-Landa, Daniel Sanchez- Prieto, Marina Oteiza-Alvarez, Davide Quarta, and Martin Pinzger. Towards cybersecurity superintelli- gence (csi): What’s the best harness for cybersecu- rity? In preparation, 2026
2026
-
[9]
Atomic red team.https://github.com/ redcanaryco/atomic-red-team, 2024
Red Canary. Atomic red team.https://github.com/ redcanaryco/atomic-red-team, 2024. Accessed: 2026-06-04
2024
-
[10]
ATTPwn: Adversary emulation with MITRE ATT&CK
Pablo Gonz´ alez and Francisco Ram´ ırez Vicente. ATTPwn: Adversary emulation with MITRE ATT&CK. Black Hat USA Arsenal, https://github. com/ElevenPaths/ATTPwn, 2020. Accessed: 2026-06- 04
2020
-
[11]
PurpleSharp: C# adversary simulation tool
Mauricio Velazco. PurpleSharp: C# adversary simulation tool. Black Hat Arsenal, https://github. com/mvelazc0/PurpleSharp, 2021. Accessed: 2026- 06-04
2021
-
[12]
Radu Marian Portase, Adrian Colesa, and Gheorghe Sebestyen. SpecRep: Adversary emulation based on attack objective specification in heterogeneous infrastructures.Sensors, 24(17):5601, 2024. doi: 10.3390/s24175601
-
[13]
Pentestgpt: An llm-empowered automatic penetration testing tool
Gelei Deng, Yi Liu, V´ ıctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. Pentestgpt: An llm-empowered automatic penetration testing tool. arXiv preprint arXiv:2308.06782, August 2023. URL https://arxiv.org/abs/2308.06782
arXiv 2023
-
[14]
Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swami- nathan, and Zhou Li
Jiacen Xu, Jack W. Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swami- nathan, and Zhou Li. Autoattacker: A large language model guided system to implement automatic cyber- attacks, 2024. URL https://arxiv.org/abs/2403. 01038
2024
-
[15]
PENTEST- AI, an LLM-powered multi-agents framework for penetration testing automation leveraging MITRE ATT&CK
Sami Bianou and Raphael Batogna. PENTEST- AI, an LLM-powered multi-agents framework for penetration testing automation leveraging MITRE ATT&CK. In2024 IEEE International Conference on Cyber Security and Resilience (CSR), pages 763–770,
-
[16]
doi: 10.1109/csr61664.2024.10679480
-
[17]
CIPHER: Cybersecurity intel- ligent penetration-testing helper for ethical researcher
Derry Pratama, Naufal Suryanto, Andro Adiputra, Thi-Thu-Huong Le, Anbiya Kadiptya, Muhammad Iqbal, and Howon Kim. CIPHER: Cybersecurity intel- ligent penetration-testing helper for ethical researcher. Sensors, 24, 2024. doi: 10.3390/s24216878
-
[18]
Vulnbot: Autonomous penetration testing for a multi-agent collaborative framework
He Kong, Die Hu, Jingguo Ge, Liangxiong Li, Tong Li, and Bingzhen Wu. Vulnbot: Autonomous penetration testing for a multi-agent collaborative framework. arXiv preprint arXiv:2501.13411, 2025
arXiv 2025
-
[19]
Xiang Wu, Yuan Tian, Yuchen Chen, Peng Ye, Xiang Cui, Jianwei Jia, Sheng Li, Jianfeng Liu, and Wenjia Niu. CurriculumPT: LLM-based multi-agent autonomous penetration testing with curriculum- guided task scheduling.Applied Sciences, 15(16): 9096, 2025. doi: 10.3390/app15169096
-
[20]
P Vansh Charan, Hrushikesh Chunduri, Prasanna Anand, and Sandeep Shukla. From text to MITRE techniques: Exploring the malicious use of large language models for generating cyber attack pay- loads.arXiv preprint arXiv:2305.15336, 2023. doi: 10.48550/arxiv.2305.15336
-
[21]
Lajos Muzsai, David Imolai, and Andr´ as Luk´ acs. HackSynth: LLM agent and evaluation framework for autonomous penetration testing.arXiv preprint arXiv:2412.01778, 2024
arXiv 2024
-
[22]
Xiangmin Shen, Lingzhi Wang, Zhenyuan Li, Yan Chen, Wencheng Zhao, Dawei Sun, Jiashui Wang, and Wei Ruan. Pentestagent: Incorporating llm agents to automated penetration testing.arXiv preprint arXiv:2411.05185, 2024
arXiv 2024
-
[23]
Towards automated penetration testing: Introducing LLM benchmark, analysis, and improvements
Isamu Isozaki, Manil Shrestha, Ruben Console, and Edward Kim. Towards automated penetration testing: Introducing LLM benchmark, analysis, and improvements. InAdjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, 2024. doi: 10.1145/3708319.3733804
-
[24]
Kazuki Nakano, Reza Feyyazi, Shanchieh Yang, and Michael Zuzak. Guided reasoning in LLM- driven penetration testing using structured attack trees.arXiv preprint arXiv:2509.07939, 2025. doi: 10.48550/arxiv.2509.07939
-
[25]
Andreas Happe and J¨ urgen Cito. Can LLMs hack enterprise networks? Autonomous assumed breach penetration-testing active directory networks.ACM Transactions on Software Engineering and Methodol- ogy, 2025. doi: 10.1145/3766895
-
[26]
Anurag Basnet, Mohamed Ghanem, Damilola Dunsin, and Wiktor Sowinski-Mydlarz. Advanced persistent threats (APT) attribution using deep reinforcement learning.Digital Threats: Research and Practice, 6: 1–23, 2024. doi: 10.1145/3736654
-
[27]
Nir Daniel, Florian Kaiser, Sapir Giladi, Shaul Sharabi, Roy Moyal, Stanislav Shpolyansky, Adan Murillo, Aviad Elyashar, and Rami Puzis. Labeling network intrusion detection system (NIDS) rules with MITRE ATT&CK techniques: Machine learning vs. large language models.Big Data and Cognitive Computing, 9(2):23, 2025. doi: 10.3390/bdcc9020023
-
[28]
Hoang Nguyen, Syed Tariq, Mohan Chhetri, and Bay Vo. Towards effective identification of attack techniques in cyber threat intelligence reports using large language models. InCompanion Proceedings of the ACM on Web Conference 2025, 2025. doi: 10.1145/3701716.3715469
-
[29]
Eric M Hutchins, Michael J Cloppert, and Rohan M Amin. Intelligence-driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains.Leading Issues in Information Warfare & Security Research, 1(1):80, 2011
2011
-
[30]
Emanuele Mezzi, Fabio Massacci, and Katja Tuma. Large language models are unreliable for cyber threat intelligence.arXiv preprint arXiv:2503.23175, 2025. doi: 10.1007/978-3-032-00627-1“˙17
-
[31]
Prasanth Balasubramanian, Sulaimaan Liyana, Hari Sankaran, Srinath Sivaramakrishnan, Siva Pusuluri, Susanna Pirttikangas, and Ella Peltonen. Genera- tive AI for cyber threat intelligence: applications, challenges, and analysis of real-world case stud- ies.Artificial Intelligence Review, 58, 2025. doi: 10.1007/s10462-025-11338-z
-
[32]
Xiaoyuan Liu, Jing Liang, Qiang Yan, Jiwon Jang, Sean Mao, Menghao Ye, Jingbo Jia, and Zhuo Xi. CyLens: Towards reinventing cyber threat intelligence in the paradigm of agentic large language models.arXiv preprint arXiv:2504.19090, 2025
arXiv 2025
-
[33]
E. Hilario, S. Azam, J. Sundaram, et al. Generative ai for pentesting: the good, the bad, the ugly. International Journal of Information Security, 23: 2075–2097, June 2024. doi: 10.1007/s10207-024- 00835-x. URL https://doi.org/10.1007/s10207- 024-00835-x
-
[34]
Adversaries leverage AI for vulnerability exploitation, augmented operations, and initial access
Google Threat Intelligence Group. Adversaries leverage AI for vulnerability exploitation, augmented operations, and initial access. Google Cloud Blog, 2026. https://cloud.google.com/blog/ topics/threat-intelligence/ai-vulnerability- exploitation-initial-access
2026
-
[35]
CAI teams & parallel execu- tion
Alias Robotics. CAI teams & parallel execu- tion. https://aliasrobotics.github.io/cai/tui/ teams_and_parallel_execution/, 2025. Accessed: 2026-03-28
2025
-
[36]
Cybersecurity ai: The dangerous gap between automation and autonomy
V´ ıctor Mayoral-Vilches. Cybersecurity ai: The dangerous gap between automation and autonomy. arXiv preprint arXiv:2506.23592, 2025
arXiv 2025
-
[37]
Cybersecurity ai: Hacking the ai hackers via prompt injection.arXiv preprint arXiv:2508.21669, 2025
V´ ıctor Mayoral-Vilches and Per Mannermaa Rynning. Cybersecurity ai: Hacking the ai hackers via prompt injection.arXiv preprint arXiv:2508.21669, 2025
arXiv 2025
-
[38]
Francesco Balassone, V´ ıctor Mayoral-Vilches, Stefan Rass, Martin Pinzger, Gaetano Perrone, Simon Pietro Romano, and Peter Schartner. Cybersecurity ai: Evaluating agentic cybersecurity in attack/defense ctfs.arXiv preprint arXiv:2510.17521, 2025
arXiv 2025
-
[39]
V´ ıctor Mayoral-Vilches, Mar´ ıa Sanz-G´ omez, Francesco Balassone, Stefan Rass, Lidia Salas-Espejo, Benjamin Jablonski, Luis Javier Navarrete-Lozano, Maite del Mundo de Torres, and Crist´ obal RJ Chavez. Cybersecurity ai: A game-theoretic ai for guiding attack and defense.arXiv preprint arXiv:2601.05887, 2026
arXiv 2026
-
[40]
Mar´ ıa Sanz-G´ omez, V´ ıctor Mayoral-Vilches, Francesco Balassone, Luis Javier Navarrete- Lozano, Crist´ obal R. J. Veas Chavez, and Maite del Mundo de Torres. Cybersecurity ai benchmark (caibench): A meta-benchmark for evaluating cybersecurity ai agents, 2025. URL https://arxiv.org/abs/2510.24317
arXiv 2025
-
[41]
Claude Opus 4.6 system card
Anthropic. Claude Opus 4.6 system card. Technical report, Anthropic, February 2026
2026
-
[42]
Julia Robinson. An Iterative Method of Solv- ing a Game.The Annals of Mathematics, 54 (2):296, September 1951. ISSN 0003486X. doi: 10.2307/1969530. URL https://www.jstor.org/ stable/1969530?origin=crossref
-
[43]
Generative Ad- versarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Ad- versarial Nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors,Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014. URL http...
2014
-
[44]
Dov Monderer and Lloyd S. Shapley. Poten- tial Games.Games and Economic Behavior, 14 (1):124–143, May 1996. ISSN 08998256. doi: 10.1006/game.1996.0044. URL https://linkinghub. elsevier.com/retrieve/pii/S0899825696900445
-
[45]
Fictitious play in 2xn games.Journal of Economic Theory, 120(2):139–154, February 2005
Ulrich Berger. Fictitious play in 2xn games.Journal of Economic Theory, 120(2):139–154, February 2005. ISSN 00220531. doi: 10.1016/j.jet.2004.02.003. URL https://linkinghub.elsevier.com/retrieve/ pii/S0022053104000626
-
[46]
Fictitious Play Property for Games with Identical Interests.Journal of Economic The- ory, 68:258–265, 1996
Dov Monderer. Fictitious Play Property for Games with Identical Interests.Journal of Economic The- ory, 68:258–265, 1996. URL http://linkinghub. elsevier.com/retrieve/pii/S0022053196900149
1996
-
[47]
Fictitious play in ’one-against-all’ multi- player games.Economic Theory, 14(3):635–651, 1999
Aner Sela. Fictitious play in ’one-against-all’ multi- player games.Economic Theory, 14(3):635–651, 1999. ISSN 0938-2259. URL http://dx.doi.org/10.1007/ s001990050345
1999
-
[48]
Secure two- party quantum evaluation of unitaries against specious adversaries,
Felix Brandt, Felix Fischer, and Paul Harrenstein. On the Rate of Convergence of Fictitious Play. In Spyros Kontogiannis, Elias Koutsoupias, and PaulG Spirakis, editors,Algorithmic Game Theory, volume 6386 ofLecture Notes in Computer Science, pages 102–113. Springer Berlin Heidelberg, 2010. ISBN 978-3-642-16169-8. doi: 10.1007/978-3-642- 16170-4˙10. URL \...
-
[49]
Addison-Wesley, third edition, 2001
Ivan Bratko.PROLOG programming for artificial intelligence. Addison-Wesley, third edition, 2001
2001
-
[50]
MIT Press, London, 1991
Drew Fudenberg and Jean Tirole.Game Theory. MIT Press, London, 1991
1991
-
[51]
A Stackelberg Model for Hybridization in Cryptography, April
Willie Kouam, Stefan Rass, Zahra Seyedi, Shahzad Ahmad, and Eckhard Pfluegel. A Stackelberg Model for Hybridization in Cryptography, April
- [52]
-
[53]
Yunlong Tang, Jing Sun, Huan Wang, Junyi Deng, Liang Tong, and Wenhong Xu. A method of network attack-defense game and collaborative defense decision-making based on hierarchical multi-agent reinforcement learning.Computers & Security, 142:103871, 2024. ISSN 0167-4048. doi: https://doi.org/10.1016/j.cose.2024.103871. URL https://www.sciencedirect.com/scie...
-
[54]
Rui Wang, Changjiang Yang, Xiangdong Deng, Yinghai Zhou, Yuan Liu, and Zhihong Tian. Turn the tables: Proactive deception defense decision-making based on Bayesian attack graphs and Stackelberg games.Neurocomputing, 638:130139, July 2025. ISSN 09252312. doi: 10.1016/j.neucom.2025.130139. URL https://linkinghub.elsevier.com/retrieve/ pii/S0925231225008112
-
[55]
Stackelberg security games: looking beyond a decade of success
Arunesh Sinha, Fei Fang, Bo An, Christopher Kiekintveld, and Milind Tambe. Stackelberg security games: looking beyond a decade of success. InPro- ceedings of the 27th International Joint Conference on Artificial Intelligence, IJCAI’18, pages 5494–5501, Stockholm, Sweden, July 2018. AAAI Press. ISBN 978-0-9992411-2-7
2018
-
[56]
Laobing Zhang and Genserik Reniers. Applying a Bayesian Stackelberg game for securing a chemical plant.Journal of Loss Prevention in the Process In- dustries, 51:72–83, January 2018. ISSN 09504230. doi: 10.1016/j.jlp.2017.11.010. URL https://linkinghub. elsevier.com/retrieve/pii/S0950423017310239
-
[57]
Stackelberg- game-based defense analysis against advanced persistent threats on cloud control system
Huanhuan Yuan, Yuanqing Xia, Jinhui Zhang, Hongjiu Yang, and Magdi Mahmoud. Stackelberg- game-based defense analysis against advanced persistent threats on cloud control system. IEEE Transactions on Industrial Informatics, pages 1–1, 2019. ISSN 1551-3203, 1941-0050. doi: 10.1109/TII.2019.2925035. URL https: //ieeexplore.ieee.org/document/8746251/
-
[58]
Stefan Rass, Sandra K¨ onig, Jasmin Wachter, V´ ıctor Mayoral-Vilches, and Emmanouil Panaousis. Game-theoretic APT defense: An experimental study on robotics.Computers & Security, 132:103328, September 2023. ISSN 0167-4048. doi: 10.1016/j.cose.2023.103328. URL https://www.sciencedirect.com/science/ article/pii/S0167404823002389
-
[59]
Nearest Neighbor
Minseok Choi and Lauren Min Kim PurpleAILAB contributors. Decepticon: Autonomous hacking agent for red team. https://github.com/PurpleAILAB/ Decepticon, 2026. Apache-2.0. A MITRE ATT&CK Technique Mapping This appendix provides the complete mapping between documented MITRE ATT&CK techniques for each APT group and the techniques observed during our experime...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.