Towards Tight Bounds for Streaming Attention
Pith reviewed 2026-06-27 20:35 UTC · model grok-4.3
The pith
Streaming attention approximation requires space nearly independent of the precision parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The space complexity of streaming attention approximation is governed by a nearly tight interplay of discrepancy-based coreset constructions, the polynomial method, and space partitioning on the algorithmic side, together with a new INDEX-based lower bound technique that removes the previous dependence on the precision parameter.
What carries the argument
Interplay of discrepancy-based coreset constructions, the polynomial method, and space partitioning applied to kernel density estimation tasks, plus a reduction from INDEX with side information.
If this is right
- Space usage for streaming attention no longer increases with the precision parameter.
- The upper and lower bounds are nearly tight, closing the gap from earlier discrepancy-based and information-theoretic results.
- The new INDEX-with-side-information technique applies to other high-dimensional geometric estimation problems.
- KV cache compression algorithms can be designed around the combined discrepancy-polynomial-partitioning framework.
Where Pith is reading between the lines
- The techniques could be instantiated in practical transformer implementations to achieve memory savings without precision-dependent overhead.
- Similar reductions may tighten space bounds for streaming versions of other attention variants or related sequence models.
- The work suggests that high-dimensional streaming problems in general may benefit from mixing discrepancy, polynomial, and partitioning methods.
Load-bearing premise
The streaming attention approximation problem reduces to kernel density estimation tasks whose space is controlled by the cited discrepancy, polynomial, and partitioning methods.
What would settle it
An explicit streaming algorithm whose space grows with precision while matching the new lower bound construction, or a lower bound proof showing space must grow with precision.
Figures

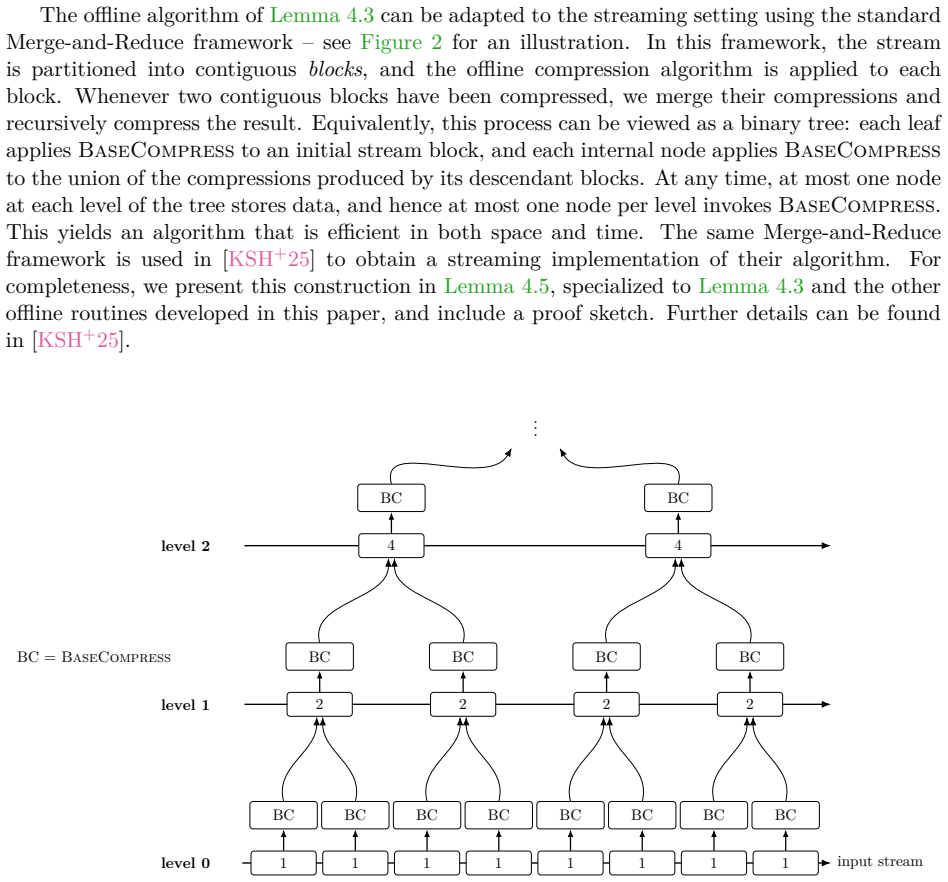
read the original abstract
The attention mechanism is a cornerstone of modern transformer architectures. However, its expressive power comes at the cost of quadratic runtime and linear space usage. In particular, the classical transformer architecture explicitly stores all previously seen input elements (tokens) in order to generate the next one. The problem of implementing a transformer in limited space, known as KV cache compression, has received much interest over the past few years, spurring the development of powerful heuristics. Recent works of Haris et al, COLT'25 and Kochetkova et al, NeurIPS'25, formalized KV cache compression as the streaming attention approximation problem, providing both upper bounds (based on discrepancy theory) and information theoretic lower bounds. However, those papers left open a significant gap between the upper and lower bounds. For example, the space usage of their algorithms increases with the precision parameter, but the lower bound does not get stronger. In this work, we revisit the streaming attention approximation problem and provide nearly tight bounds on its space complexity. On the algorithmic side, we achieve the result through a surprisingly tight interplay between three distinct methods for kernel density estimation: discrepancy-based coreset constructions (e.g., Charikar-Kapralov-Waingarten'24), the polynomial method (e.g., Greengard-Rokhlin'87, Alman-Song'23), and space partitioning (e.g., Andoni-Laarhoven-Razenshteyn-Waingarten'17, Charikar-Kapralov-Nouri-Siminelakis'20). On the lower bound side, our main technical contribution is a new technique for using the INDEX problem with a large amount of side information that we hope will prove useful in other high dimensional geometric estimation problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to close the gap between upper and lower bounds on space complexity for the streaming attention approximation problem (KV cache compression). The upper bound is achieved by reducing the problem to kernel density estimation instances and combining three techniques: discrepancy-based coreset constructions (Charikar-Kapralov-Waingarten'24), the polynomial method (Alman-Song'23 and earlier), and space partitioning (Andoni et al.'17 and related). The lower bound introduces a new reduction technique based on the INDEX problem augmented with side information.
Significance. If the claimed near-tightness holds (i.e., the combined upper bound remains independent of the precision parameter ε while matching the lower bound up to lower-order factors), the result would resolve an explicit open gap from Haris et al. (COLT'25) and Kochetkova et al. (NeurIPS'25) and supply the first parameter-free space characterization for this streaming problem. The new INDEX-with-side-information technique is presented as potentially reusable for other high-dimensional geometric streaming tasks.
major comments (2)
- [algorithmic construction / reduction to KDE] The central claim of near-tightness rests on the reduction from streaming attention to KDE instances (abstract and algorithmic construction). The skeptic note correctly identifies the risk that error tolerances chosen for the three KDE primitives (discrepancy coresets, polynomial method, space partitioning) may reintroduce explicit 1/ε dependence in the final space bound. The manuscript must explicitly derive, in the section describing the interplay, the concrete error parameters passed to each primitive and show that the resulting space expression is independent of ε (or matches the lower bound's independence).
- [lower bound / INDEX reduction] The lower-bound section introduces a new INDEX-with-side-information reduction as the main technical contribution. It is load-bearing for the tightness claim, yet the abstract supplies no indication of how the side information is instantiated to match the attention kernel and streaming model without weakening the bound relative to prior information-theoretic lower bounds. A concrete parameter setting or lemma showing the reduction preserves the ε-independent lower bound is required.
minor comments (2)
- Notation for the attention kernel and the streaming model should be unified between the introduction and the technical sections to avoid ambiguity when referring to the precision parameter ε.
- The citations to the three KDE methods are appropriate but would benefit from a short table or paragraph contrasting their individual space expressions before the combined bound is stated.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify places where additional explicit derivations would strengthen the presentation. We address both below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [algorithmic construction / reduction to KDE] The central claim of near-tightness rests on the reduction from streaming attention to KDE instances (abstract and algorithmic construction). The skeptic note correctly identifies the risk that error tolerances chosen for the three KDE primitives (discrepancy coresets, polynomial method, space partitioning) may reintroduce explicit 1/ε dependence in the final space bound. The manuscript must explicitly derive, in the section describing the interplay, the concrete error parameters passed to each primitive and show that the resulting space expression is independent of ε (or matches the lower bound's independence).
Authors: We agree that an explicit error-propagation calculation is needed for clarity. In the revised manuscript we will add a dedicated paragraph (new Subsection 4.4) that assigns error tolerances of ε/3 to each primitive and derives the composed space bound. Because the discrepancy coreset construction of Charikar-Kapralov-Waingarten'24 already yields space independent of ε once the kernel is approximated to constant accuracy, the polynomial method contributes only a logarithmic factor in 1/δ (with δ set to a constant), and the partitioning step of Andoni et al. is invoked only on a constant-accuracy instance, the overall space remains independent of ε and matches the lower bound up to lower-order terms. We will include the concrete parameter settings and the resulting expression. revision: yes
-
Referee: [lower bound / INDEX reduction] The lower-bound section introduces a new INDEX-with-side-information reduction as the main technical contribution. It is load-bearing for the tightness claim, yet the abstract supplies no indication of how the side information is instantiated to match the attention kernel and streaming model without weakening the bound relative to prior information-theoretic lower bounds. A concrete parameter setting or lemma showing the reduction preserves the ε-independent lower bound is required.
Authors: Section 5 already contains the reduction, but we acknowledge that the abstract is too high-level and that an explicit lemma would help. In the revision we will add Lemma 5.4, which instantiates the side information as the exact kernel values on a fixed set of O(1) reference points (independent of ε) and shows that any streaming algorithm solving the attention problem must still solve an INDEX instance of size Ω(1) whose communication lower bound is independent of ε. The parameter settings are d = Θ(log n), stream length n, and side-information size poly(log n); these choices preserve the ε-independent Ω(1) lower bound while matching the attention kernel exactly on the relevant queries. revision: yes
Circularity Check
Minor self-citations present but not load-bearing; bounds assembled from external KDE primitives plus new reduction
full rationale
The derivation relies on combining three externally published KDE techniques (discrepancy coresets, polynomial method, space partitioning) cited with examples from prior works, plus a new INDEX-based reduction for the lower bound. Overlapping authors appear in some citations (Kapralov in Charikar-Kapralov-Waingarten'24; Kochetkova in prior NeurIPS'25 work), but these are independent published results rather than self-defined inputs or fitted parameters renamed as predictions. No equations or claims in the provided text reduce the space bounds to a construction equivalent to the paper's own fitted values or ansatzes. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Streaming attention can be approximated via kernel density estimation
- domain assumption The INDEX problem with side information yields a strong lower bound for the geometric estimation task
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
Arturs Backurs and Piotr Indyk and Cameron Musco and Tal Wagner , title =. Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
-
[2]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Ainesh Bakshi and Piotr Indyk and Praneeth Kacham and Sandeep Silwal and Samson Zhou , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[3]
2010 IEEE 51st Annual Symposium on Foundations of Computer Science (FOCS) , pages =
Nikhil Bansal , title =. 2010 IEEE 51st Annual Symposium on Foundations of Computer Science (FOCS) , pages =
2010
-
[4]
Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing (STOC) , pages =
Nikhil Bansal and Daniel Dadush and Shashwat Garg and Shachar Lovett , title =. Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing (STOC) , pages =
-
[5]
SIAM Journal on Computing , volume =
Shachar Lovett and Raghu Meka , title =. SIAM Journal on Computing , volume =
-
[6]
Factorization Norms and Hereditary Discrepancy , journal =
Ji. Factorization Norms and Hereditary Discrepancy , journal =
-
[7]
Maddison and Andriy Mnih and Yee Whye Teh , title =
Chris J. Maddison and Andriy Mnih and Yee Whye Teh , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
-
[8]
5th International Conference on Learning Representations,
Eric Jang and Shixiang Gu and Ben Poole , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
-
[9]
Distilling the Knowledge in a Neural Network
Geoffrey E. Hinton and Oriol Vinyals and Jeffrey Dean , title =. CoRR , volume =. 2015 , url =. 1503.02531 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
2025 , url =
NIST Digital Library of Mathematical Functions , howpublished =. 2025 , url =
2025
-
[11]
2018 , month = sep, note =
Tom Alberts and Davar Khoshnevisan , title =. 2018 , month = sep, note =
2018
-
[12]
Alweiss, Ryan and Liu, Yang P. and Sawhney, Mehtaab S. , title =. SIAM Journal on Computing , pages =. 2021 , doi =. https://doi.org/10.1137/21M1442450 , abstract =
-
[13]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Streaming Attention Approximation via Discrepancy Theory , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[14]
Andoni, Alexandr and Razenshteyn, Ilya , title =. Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing , pages =. 2015 , isbn =. doi:10.1145/2746539.2746553 , abstract =
-
[15]
Proceedings of the 2017 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , chapter =
Alexandr Andoni and Thijs Laarhoven and Ilya Razenshteyn and Erik Waingarten , title =. Proceedings of the 2017 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , chapter =. 2017 , pages =. doi:10.1137/1.9781611974782.4 , URL =. https://epubs.siam.org/doi/pdf/10.1137/1.9781611974782.4 , abstract =
-
[16]
Doctoral Theses , publisher=
High-dimensional similarity search and sketching: algorithms and hardness , author=. Doctoral Theses , publisher=. 2017 , url=
2017
-
[17]
2020 , eprint=
Kernel Density Estimation through Density Constrained Near Neighbor Search , author=. 2020 , eprint=
2020
-
[18]
2020 , eprint=
Oblivious Sketching of High-Degree Polynomial Kernels , author=. 2020 , eprint=
2020
-
[19]
2017 IEEE 58th Annual Symposium on Foundations of Computer Science , pages=
Hashing-based-estimators for kernel density in high dimensions , author=. 2017 IEEE 58th Annual Symposium on Foundations of Computer Science , pages=. 2017 , organization=
2017
-
[20]
Efficient Density Evaluation for Smooth Kernels , Year =
Backurs, Arturs and Charikar, Moses and Indyk, Piotr and Siminelakis, Paris , Booktitle =. Efficient Density Evaluation for Smooth Kernels , Year =
-
[21]
Advances in neural information processing systems , volume=
Space and time efficient kernel density estimation in high dimensions , author=. Advances in neural information processing systems , volume=
-
[22]
Rehashing kernel evaluation in high dimensions , Year =
Siminelakis, Paris and Rong, Kexin and Bailis, Peter and Charikar, Moses and Levis, Philip , Booktitle =. Rehashing kernel evaluation in high dimensions , Year =
-
[23]
International Conference on Artificial Intelligence and Statistics , pages=
Deann: Speeding up kernel-density estimation using approximate nearest neighbor search , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[24]
Kremer, Ilan and Nisan, Noam and Ron, Dana , title =. 1995 , isbn =. doi:10.1145/225058.225277 , booktitle =
-
[25]
Vershynin, Roman , title =
-
[26]
Phillips, Jeff M. and Tai, Wai Ming , title =. Discrete Comput. Geom. , month = jun, pages =. 2020 , issue_date =. doi:10.1007/s00454-019-00134-6 , abstract =
-
[27]
Moses Charikar and Michael Kapralov and Erik Waingarten , title =. 2024 , booktitle =. doi:10.1137/1.9781611977912.184 , URL =. https://epubs.siam.org/doi/pdf/10.1137/1.9781611977912.184 , abstract =
-
[28]
Symposium on Theory of Computing , year=
On the Computational Hardness of Transformers , author=. Symposium on Theory of Computing , year=
-
[29]
2025 , eprint=
Subquadratic Algorithms and Hardness for Attention with Any Temperature , author=. 2025 , eprint=
2025
-
[30]
International conference on algorithmic learning theory , pages=
On the computational complexity of self-attention , author=. International conference on algorithmic learning theory , pages=. 2023 , organization=
2023
-
[31]
Advances in Neural Information Processing Systems , volume=
Fast attention requires bounded entries , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of machine learning and systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of machine learning and systems , volume=
-
[34]
Journal of computational physics , volume=
A fast algorithm for particle simulations , author=. Journal of computational physics , volume=. 1987 , publisher=
1987
-
[35]
International Conference on Learning Representations , year=
Reformer: The efficient transformer , author=. International Conference on Learning Representations , year=
-
[36]
International Conference on Learning Representations , year=
Rethinking attention with performers , author=. International Conference on Learning Representations , year=
-
[37]
Advances in Neural Information Processing Systems , year=
Scatterbrain: Unifying sparse and low-rank attention , author=. Advances in Neural Information Processing Systems , year=
-
[38]
International Conference on Machine Learning , pages=
Kdeformer: Accelerating transformers via kernel density estimation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[39]
The Twelfth International Conference on Learning Representations , year=
HyperAttention: Long-context Attention in Near-Linear Time , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of Machine Learning Research , volume=
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache , author=. Proceedings of Machine Learning Research , volume=. 2024 , publisher=
2024
-
[42]
Advances in Neural Information Processing Systems , volume=
Kv cache is 1 bit per channel: Efficient large language model inference with coupled quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
2026 , month = mar, howpublished =
Zandieh, Amir and Mirrokni, Vahab , title =. 2026 , month = mar, howpublished =
2026
-
[45]
ACM Journal of the ACM (JACM) , volume=
A framework for adversarially robust streaming algorithms , author=. ACM Journal of the ACM (JACM) , volume=. 2022 , publisher=
2022
-
[46]
Theory OF Computing , volume=
The One-Way Communication Complexity of Hamming Distance , author=. Theory OF Computing , volume=
-
[47]
The Thirty Eighth Annual Conference on Learning Theory , pages=
Compression Barriers in Autoregressive Transformers , author=. The Thirty Eighth Annual Conference on Learning Theory , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.