Clairvoyant: Predictive SJF Scheduling to Mitigate Head-of-Line Blocking in Serial LLM Backends
Pith reviewed 2026-06-27 20:57 UTC · model grok-4.3
The pith
Clairvoyant predicts LLM response lengths from 19 lexical features to enable shortest-job-first admission ordering in serial backends.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
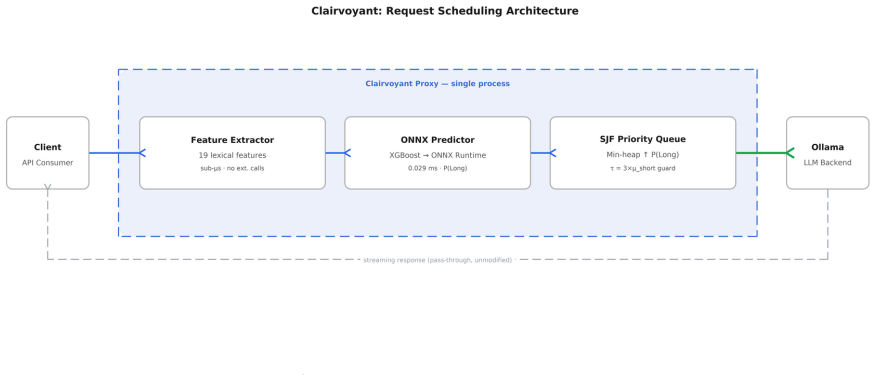
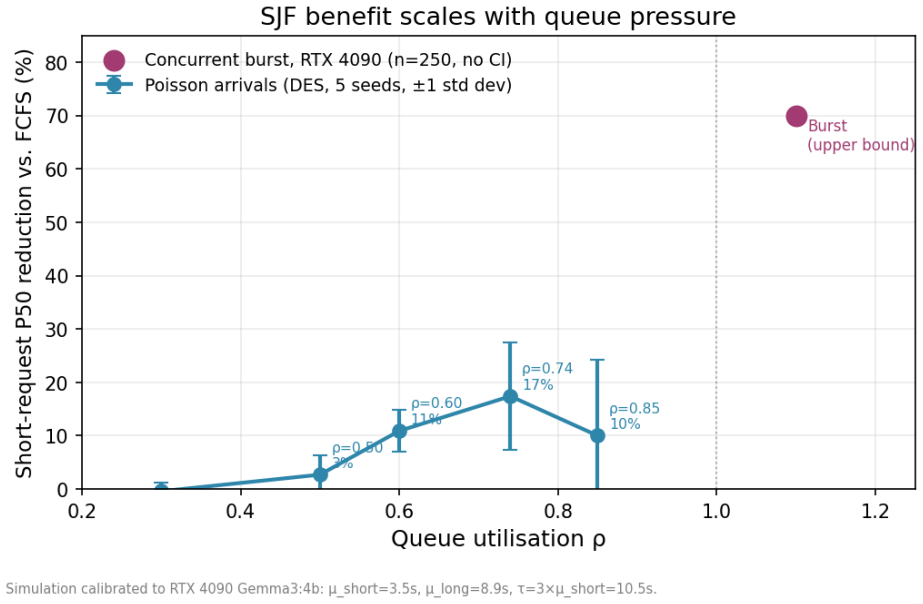
The paper claims that an ONNX-exported XGBoost classifier trained on 19 lexical features can predict relative response lengths with 62-96% in-distribution ranking fidelity, which is sufficient to implement predictive shortest-job-first admission control. This ordering mitigates head-of-line blocking in serial LLM backends without the high VRAM cost of continuous batching, producing measured end-to-end P50 latency reductions of 70-76% for short requests under maximum queue pressure of 100 concurrent requests and 17% under steady-state Poisson arrivals at load factor 0.74.
What carries the argument
The ONNX-exported XGBoost classifier on 19 lightweight lexical features, which supplies fast per-request length-class predictions used only for relative admission ordering.
If this is right
- Short requests experience 70-76% lower P50 latency under 100 concurrent requests.
- Short requests experience 17% lower P50 latency under steady-state Poisson arrivals at ρ=0.74.
- The proxy adds 0.029 ms overhead per request and needs no backend changes.
- Natural conversation logs, not curated instruction datasets, are required for effective training because instruction data under-represents long responses.
- The system applies to any serial OpenAI-compatible backend such as Ollama or llama.cpp.
Where Pith is reading between the lines
- Edge and local deployments with tight VRAM can now mix short and long requests without hardware upgrades.
- Ranking-focused prediction may allow similar lightweight proxies for other ordering policies such as priority or deadline scheduling.
- Periodic retraining on fresh conversation logs will likely be needed when workload domains shift.
Load-bearing premise
The reported 62-96% ranking fidelity of the lexical XGBoost model is high enough to produce the claimed end-to-end latency reductions when used to order admissions.
What would settle it
Deploy the proxy on a serial backend with a recorded mixed workload, measure actual response lengths and queue latencies, and check whether short-request P50 latency falls by 70-76% under the same 100-request queue pressure.
Figures

read the original abstract
Serial LLM inference backends -- such as Ollama -- process requests one at a time under FCFS admission, causing Head-of-Line Blocking (HOLB) under mixed workloads at high utilisation: short factual queries can be delayed by minutes behind long generation jobs. While cloud-scale deployments mitigate HOLB via continuous batching (vLLM, Orca), these solutions require tens of GB of VRAM for concurrent KV-caches -- infeasible for memory-constrained edge and local deployments that rely on serial request dispatch. We present \clairvoyant, a drop-in sidecar proxy for any serial OpenAI-compatible backend (e.g., Ollama, llama.cpp). \clairvoyant predicts response length from 19 lightweight lexical features via an ONNX-exported XGBoost classifier, achieving 0.029\,ms per-request latency (four orders of magnitude below typical generation time). Because admission scheduling depends on relative ordering rather than exact prediction, the system optimises ranking fidelity, achieving 62--96\% in-distribution and 52--66\% cross-distribution accuracy across natural conversation datasets. We find that curated instruction datasets are degenerate training sources for length prediction: GPT-imposed brevity constraints reduce Long-class representation to under 0.02\% of examples, making natural conversation logs the only viable training source. End-to-end GPU benchmarks on an RTX~4090 show 70--76\% P50 latency reduction for short requests under maximum queue pressure (100 concurrent requests) and 17\% under steady-state Poisson arrivals ($\rho=0.74$). \clairvoyant is open-source and requires no modifications to the inference backend.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Clairvoyant, a drop-in sidecar proxy for serial OpenAI-compatible LLM backends (e.g., Ollama) that uses an ONNX-exported XGBoost classifier on 19 lightweight lexical features to predict response lengths and enable SJF-style admission ordering. This aims to mitigate head-of-line blocking for short requests under mixed workloads. Key claims include 0.029 ms per-request prediction latency, 62--96% in-distribution and 52--66% cross-distribution ranking accuracy, and end-to-end GPU benchmark results on an RTX 4090 showing 70--76% P50 latency reduction for short requests at maximum queue pressure (100 concurrent) and 17% under steady-state Poisson arrivals (ρ=0.74). Natural conversation logs are identified as the only viable training source due to degeneracy in curated instruction datasets.
Significance. If the empirical results hold under scrutiny, this work provides a practical, low-overhead approach to improving responsiveness in memory-constrained local/edge LLM deployments where continuous batching is infeasible. The emphasis on ranking fidelity (rather than exact length prediction) and the open-source release are notable strengths. The identification of training data issues with instruction datasets is a useful observation for the community.
major comments (2)
- [Abstract and §5 (benchmarks)] The central end-to-end latency claims (70--76% P50 reduction under queue pressure and 17% under Poisson) rest on benchmarks whose experimental setup, number of runs, statistical significance, error bars, and data exclusion rules are not detailed in the reported results. This directly affects verifiability of the claim that the reported ranking fidelity produces the observed gains.
- [§4 (model evaluation) and §5 (end-to-end)] No ablation or sensitivity analysis is provided to demonstrate that the 62--96% in-distribution ranking fidelity is sufficient to deliver the claimed latency reductions when used for admission ordering, nor how performance degrades with lower fidelity (e.g., the 52--66% cross-distribution case).
minor comments (1)
- [Abstract] The abstract states concrete numerical results but does not reference the specific tables or figures containing the underlying data; cross-references would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve verifiability and analysis of the results.
read point-by-point responses
-
Referee: [Abstract and §5 (benchmarks)] The central end-to-end latency claims (70--76% P50 reduction under queue pressure and 17% under Poisson) rest on benchmarks whose experimental setup, number of runs, statistical significance, error bars, and data exclusion rules are not detailed in the reported results. This directly affects verifiability of the claim that the reported ranking fidelity produces the observed gains.
Authors: We agree that the experimental details require expansion for verifiability. The revised §5 will explicitly state the number of independent runs (with random seeds), the method for assessing statistical significance (e.g., confidence intervals or paired tests), inclusion of error bars on all latency figures, and confirmation that no data were excluded beyond standard queue-completion filtering. These additions will directly support the latency claims. revision: yes
-
Referee: [§4 (model evaluation) and §5 (end-to-end)] No ablation or sensitivity analysis is provided to demonstrate that the 62--96% in-distribution ranking fidelity is sufficient to deliver the claimed latency reductions when used for admission ordering, nor how performance degrades with lower fidelity (e.g., the 52--66% cross-distribution case).
Authors: We acknowledge the absence of a dedicated sensitivity analysis. While the reported cross-distribution results provide partial evidence of behavior under lower fidelity, we will add a new analysis in §5 that simulates admission ordering with controlled prediction noise at fidelity levels matching the observed range (52--96%). This will quantify how latency reductions vary with ranking accuracy and confirm sufficiency of the achieved fidelity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical system: an XGBoost classifier trained on 19 lexical features to predict response length for SJF-style admission ordering, with measured ranking fidelity on held-out data and direct end-to-end latency benchmarks on RTX 4090 hardware under controlled workloads. No equations or derivations are claimed; the central results (latency reductions, prediction latency, fidelity ranges) are obtained from independent measurements rather than reducing to the training fit by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The argument that relative ordering suffices is supported by explicit cross-distribution accuracy numbers and is not tautological with the model training.
Axiom & Free-Parameter Ledger
free parameters (2)
- XGBoost model parameters
- 19 lexical feature definitions and selection
axioms (1)
- domain assumption Lexical features extracted from prompts correlate sufficiently with eventual response length to support useful ranking for scheduling
Reference graph
Works this paper leans on
-
[1]
Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve
Amey Agrawal, Niket Kedia, Ashish Panwar, Jayashree Mohan, Jinwoo Kwak, Gregory R Ganger, Anton Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, 2024
2024
-
[2]
CodeAlpaca: An instruction-following LLaMA model for code generation.https: //github.com/sahil280114/codealpaca, 2023
Sahil Chaudhary. CodeAlpaca: An instruction-following LLaMA model for code generation.https: //github.com/sahil280114/codealpaca, 2023. Accessed: 2026-06-02
2023
-
[3]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. ACM, 2016
2016
-
[4]
Databricks Dolly 15K: An open-source dataset for instruction-following large language models.https://github.com/databrickslabs/dolly, 2023
Databricks. Databricks Dolly 15K: An open-source dataset for instruction-following large language models.https://github.com/databrickslabs/dolly, 2023. Accessed: 2026-06-02
2023
-
[5]
Efficient LLM scheduling by learning to rank
Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Stoica, and Hao Zhang. Efficient LLM scheduling by learning to rank. InAdvances in Neural Information Processing Systems (NeurIPS 37), 2024
2024
-
[6]
Cambridge University Press, 1st edition, 2013
Mor Harchol-Balter.Performance Modeling and Design of Computer Systems: Queueing Theory in Action. Cambridge University Press, 1st edition, 2013
2013
-
[7]
S3: Increasing GPU utilization during generative inference for higher throughput
Yunho Jin, Xiaoxuan Pan, Alvin Wang, Guohao Yu, Zhihao Zhu, Ion Stoica, and Hao Zhang. S3: Increasing GPU utilization during generative inference for higher throughput. InAdvances in Neural Information Processing Systems (NeurIPS 36), 2023
2023
-
[8]
Volume 1: Theory
Leonard Kleinrock.Queueing Systems. Volume 1: Theory. Wiley-Interscience, 1975
1975
-
[9]
OpenAssistant conversations: Democratizing large language model alignment
Andreas Köpf et al. OpenAssistant conversations: Democratizing large language model alignment. https://huggingface.co/datasets/OpenAssistant/oasst1, 2023. Accessed: 2026-06-02
2023
-
[10]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP ’23), pages 611–626. ACM, 2023
2023
-
[11]
LMSYS-Chat-1M: A large-scale real-world LLM conversation dataset
LMSYS Org. LMSYS-Chat-1M: A large-scale real-world LLM conversation dataset. https:// huggingface.co/datasets/lmsys/lmsys-chat-1m, 2023. Accessed: 2026-06-02
2023
-
[12]
ONNX Runtime.https://onnxruntime.ai, 2021
ONNX Runtime Developers. ONNX Runtime.https://onnxruntime.ai, 2021. Accessed: 2026-06-02
2021
-
[13]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Nedeljko Vujic, Zhenhua Liu, Chenyang Wang, Ioannis Stavrakakis, Stratis Ioannidis, and David A. Wood. Efficient interactive LLM serving with proxy model-based sequence length prediction.arXiv preprint arXiv:2404.08509, 2024
-
[14]
Linus E. Schrage. A proof of the optimality of the shortest remaining processing time discipline. Operations Research, 16(3):687–690, 1968. 16
1968
-
[15]
Liu, and Christopher D
Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer- generator networks. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1073–1083. Association for Computational Linguistics, 2017
2017
-
[16]
ShareGPT dataset.https://sharegpt.com, 2023
ShareGPT. ShareGPT dataset.https://sharegpt.com, 2023. Accessed: 2026-06-02
2023
-
[17]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford Alpaca: An instruction-following LLaMA model.https: //github.com/tatsu-lab/stanford_alpaca, 2023. Accessed: 2026-06-02
2023
-
[18]
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Predicting LLM output length via entropy-guided representations
Huanyi Xie, Yubin Chen, Liangyu Wang, Lijie Hu, and Di Wang. Predicting LLM output length via entropy-guided representations. InThe Fourteenth International Conference on Learning Representations (ICLR 2026), 2026
2026
-
[20]
Orca: A distributed serving system for transformer-based generative models
Gyeong-In Yu, Jeongmin Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538. USENIX Association, 2022. 17
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.