AnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
Pith reviewed 2026-06-27 22:23 UTC · model grok-4.3
The pith
AnchorWorld advances egocentric world simulation by using exogenous viewpoints for full-body grounding and anchor views for evolutionary customization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
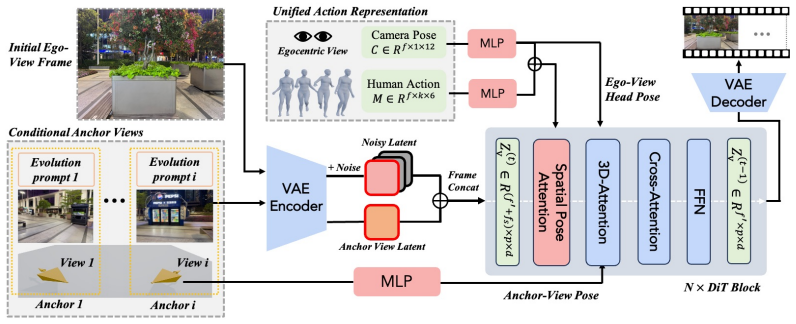
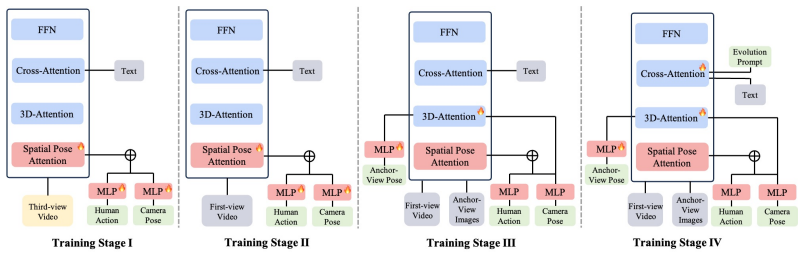
AnchorWorld advances egocentric simulation through enhanced interaction integrity and a flexible mechanism for world customization. It utilizes 3D human motion as the primary interaction modality and introduces an auxiliary training supervision that incorporates exogenous viewpoints decoupled from the agent's first-person sensorium, allowing observation of full-body positioning relative to the environment. It also proposes a simple yet effective mechanism for customizing self-evolving worlds by defining anchor views within a unified world coordinate system coupled with textual descriptions dictating the dynamic evolution of local scenes.
What carries the argument
Auxiliary exogenous viewpoint supervision for full-body positioning combined with anchor-view customization in a unified coordinate system driven by textual evolutionary descriptions.
If this is right
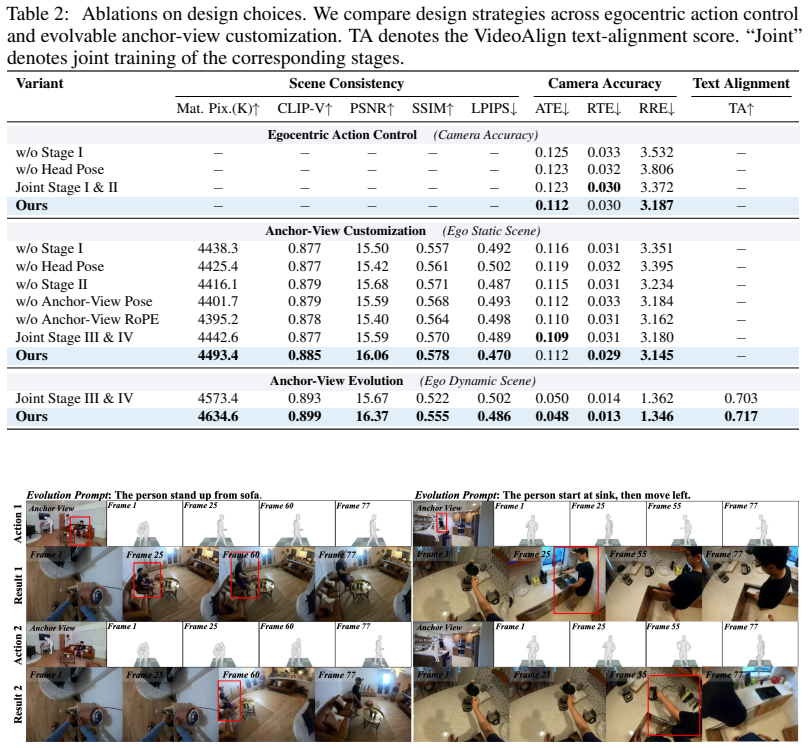
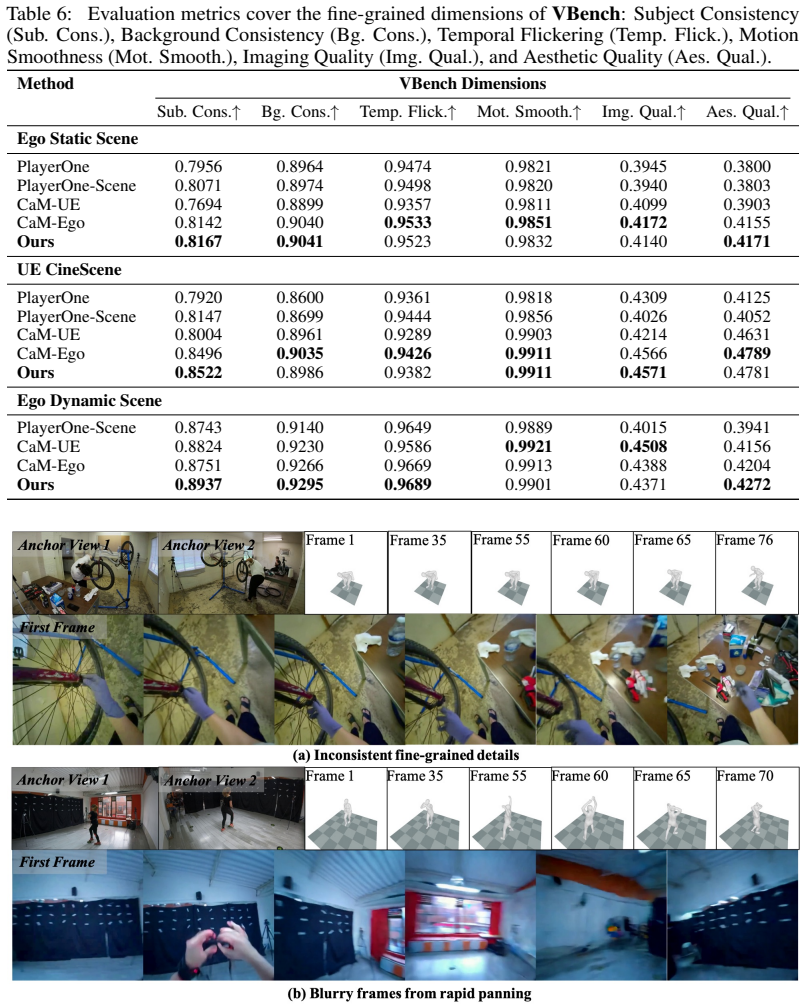
- The model significantly outperforms state-of-the-art baselines on relevant metrics.
- Ablation studies confirm the contribution of the auxiliary supervision and the customization scheme.
- The customization approach produces spatio-temporal geometric consistency while strictly following the prescribed evolutionary dynamics dictated by text.
Where Pith is reading between the lines
- The decoupled-view supervision pattern could be tested in other embodied settings where primary sensors provide incomplete observations of the agent.
- Text-driven anchor control suggests a route for language-based scenario editing that preserves geometric coherence across time steps.
- The unified coordinate system for anchors may simplify transfer between different simulation environments or real-world capture setups.
Load-bearing premise
The auxiliary training supervision that incorporates exogenous viewpoints decoupled from the agent's first-person sensorium allows the model to observe the agent's full-body positioning relative to the environment and thereby facilitates more robust spatial grounding of human-world interactions.
What would settle it
Training the same architecture without the exogenous viewpoint supervision and measuring whether full-body spatial grounding accuracy or interaction consistency drops significantly in egocentric test sequences.
Figures










read the original abstract
Despite being a pivotal frontier, interactive world modeling remains underexplored in terms of the versatile controllability required by practical scenarios. To bridge this gap, we present AnchorWorld, a framework that advances egocentric simulation through enhanced interaction integrity and a flexible mechanism for world customization. First, we utilize 3D human motion as the primary interaction modality. To complement the out-of-view or truncated body parts in egocentric views, we introduce an auxiliary training supervision that incorporates exogenous viewpoints decoupled from the agent's first-person sensorium. It allows the model to observe the agent's full-body positioning relative to the environment, facilitating a more robust spatial grounding of human-world interactions. Furthermore, we propose a simple yet effective mechanism for customizing self-evolving worlds. This is achieved by defining anchor views within a unified world coordinate system, coupled with textual descriptions dictating the dynamic evolution of local scenes. Experimental results show that AnchorWorld significantly outperforms state-of-the-art baselines, while ablation studies validate the effectiveness of our key designs. Notably, our customization scheme exhibits promising spatio-temporal geometric consistency and adheres strictly to the prescribed evolutionary dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AnchorWorld, a framework for egocentric interactive world simulation. It uses 3D human motion as the primary interaction modality, introduces auxiliary exogenous viewpoints as training supervision to complement truncated egocentric views and improve spatial grounding of full-body interactions, and proposes a customization mechanism based on anchor views in a unified world coordinate system paired with textual descriptions to control self-evolving local scenes. The authors claim that AnchorWorld significantly outperforms state-of-the-art baselines, with ablations confirming the key designs and the customization scheme showing strong spatio-temporal geometric consistency while following prescribed evolutionary dynamics.
Significance. If the quantitative results and ablations hold under standard single-view inference, the work could advance controllable embodied world models by addressing spatial grounding limitations in egocentric settings and enabling flexible, text-driven customization of dynamic environments.
major comments (2)
- [Abstract] Abstract: The central claim of significantly outperforming baselines via improved spatial grounding rests on the auxiliary exogenous-view supervision. The manuscript does not explicitly state whether these decoupled viewpoints are available only during training or whether the model requires them at inference time. If the latter, the reported gains would not apply to standard first-person deployment and the headline performance numbers would be dependent on privileged multi-view information.
- [Abstract] Abstract: No quantitative results, error bars, dataset details, baseline implementations, or evaluation metrics are supplied to support the outperformance and ablation claims, making it impossible to assess whether the gains are statistically meaningful or attributable to the proposed designs rather than implementation differences.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below, providing clarifications based on the manuscript content.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of significantly outperforming baselines via improved spatial grounding rests on the auxiliary exogenous-view supervision. The manuscript does not explicitly state whether these decoupled viewpoints are available only during training or whether the model requires them at inference time. If the latter, the reported gains would not apply to standard first-person deployment and the headline performance numbers would be dependent on privileged multi-view information.
Authors: The manuscript states that exogenous viewpoints are introduced as 'an auxiliary training supervision' (abstract and Section 3.2), making clear that they serve only as training-time signals to enhance spatial grounding from truncated egocentric observations. At inference the model uses only first-person views, consistent with standard deployment. To eliminate any residual ambiguity we will revise the abstract to explicitly note that the supervision is training-only and unavailable at test time. revision: yes
-
Referee: [Abstract] Abstract: No quantitative results, error bars, dataset details, baseline implementations, or evaluation metrics are supplied to support the outperformance and ablation claims, making it impossible to assess whether the gains are statistically meaningful or attributable to the proposed designs rather than implementation differences.
Authors: Abstracts conventionally provide high-level summaries. All requested details—quantitative results with error bars, dataset specifications, baseline implementations, evaluation metrics, and ablation analyses—are reported in Sections 4 and 5, together with implementation details that allow reproduction and statistical assessment of the claims. revision: no
Circularity Check
No circularity: framework description contains no equations or load-bearing derivations
full rationale
The provided abstract and description present AnchorWorld as an empirical framework relying on 3D motion input, auxiliary exogenous-view supervision during training, and anchor-view customization. No mathematical derivations, parameter-fitting steps, predictions derived from fits, or self-citation chains appear. Claims of outperformance rest on experimental results and ablations rather than any definitional reduction. The auxiliary supervision is an explicit training design choice, not a hidden circularity. This matches the default expectation of no circularity when no derivation chain exists to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[2]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14834–14844, 2025
2025
-
[3]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[4]
Whole- body conditioned egocentric video prediction.arXiv preprint arXiv:2506.21552, 2025
Yutong Bai, Danny Tran, Amir Bar, Yann LeCun, Trevor Darrell, and Jitendra Malik. Whole- body conditioned egocentric video prediction.arXiv preprint arXiv:2506.21552, 2025
arXiv 2025
-
[5]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[6]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[7]
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025
arXiv 2025
-
[8]
Unreal engine 5
Epic Games. Unreal engine 5. https://www.unrealengine.com/en-US/ unreal-engine-5, 2022. Accessed: 2025-09-25
2022
-
[9]
Vidarc: Embodied video diffusion model for closed-loop control.arXiv preprint arXiv:2512.17661, 2025
Yao Feng, Chendong Xiang, Xinyi Mao, Hengkai Tan, Zuyue Zhang, Shuhe Huang, Kaiwen Zheng, Haitian Liu, Hang Su, and Jun Zhu. Vidarc: Embodied video diffusion model for closed-loop control.arXiv preprint arXiv:2512.17661, 2025
arXiv 2025
-
[10]
Scenescape: Text-driven consistent scene generation.Advances in Neural Information Processing Systems, 36:39897–39914, 2023
Rafail Fridman, Amit Abecasis, Yoni Kasten, and Tali Dekel. Scenescape: Text-driven consistent scene generation.Advances in Neural Information Processing Systems, 36:39897–39914, 2023
2023
-
[11]
Gigahands: A massive annotated dataset of bimanual hand activities
Rao Fu, Dingxi Zhang, Alex Jiang, Wanjia Fu, Austin Funk, Daniel Ritchie, and Srinath Sridhar. Gigahands: A massive annotated dataset of bimanual hand activities. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17461–17474, 2025
2025
-
[12]
Xiao Fu, Xian Liu, Xintao Wang, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, and Dahua Lin. 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation.arXiv preprint arXiv:2412.07759, 2024
arXiv 2024
-
[13]
Quankai Gao, Jiawei Yang, Qiangeng Xu, Le Chen, and Yue Wang. Lome: Learning human-object manipulation with action-conditioned egocentric world model.arXiv preprint arXiv:2603.27449, 2026
arXiv 2026
-
[14]
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[15]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyl- los Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1...
2024
-
[16]
Jinkun Hao, Mingda Jia, Ruiyan Wang, Xihui Liu, Ran Yi, Lizhuang Ma, Jiangmiao Pang, and Xudong Xu. Egosim: Egocentric world simulator for embodied interaction generation.arXiv preprint arXiv:2604.01001, 2026. 11
arXiv 2026
-
[17]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
arXiv 2025
-
[18]
Gen3r: 3d scene generation meets feed-forward reconstruction.arXiv preprint arXiv:2601.04090, 2026
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, and Yiyi Liao. Gen3r: 3d scene generation meets feed-forward reconstruction.arXiv preprint arXiv:2601.04090, 2026
arXiv 2026
-
[19]
Kaiyi Huang, Yukun Huang, Yu Li, Jianhong Bai, Xintao Wang, Zinan Lin, Xuefei Ning, Jiwen Yu, Pengfei Wan, Yu Wang, et al. Cinescene: Implicit 3d as effective scene representation for cinematic video generation.arXiv preprint arXiv:2602.06959, 2026
arXiv 2026
-
[20]
V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Rynson Lau, Wangmeng Zuo, et al. V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
2025
-
[21]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[22]
Lemma: A multi- view dataset for le arning m ulti-agent m ulti-task a ctivities
Baoxiong Jia, Yixin Chen, Siyuan Huang, Yixin Zhu, and Song-Chun Zhu. Lemma: A multi- view dataset for le arning m ulti-agent m ulti-task a ctivities. InEuropean Conference on Computer Vision, pages 767–786. Springer, 2020
2020
-
[23]
Fulldit: Multi-task video generative foundation model with full attention
Xuan Ju, Weicai Ye, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, and Qiang Xu. Fulldit: Multi-task video generative foundation model with full attention. arXiv preprint arXiv:2503.19907, 2025
arXiv 2025
-
[24]
Dexterous world models.arXiv preprint arXiv:2512.17907, 2025
Byungjun Kim, Taeksoo Kim, Junyoung Lee, and Hanbyul Joo. Dexterous world models.arXiv preprint arXiv:2512.17907, 2025
arXiv 2025
-
[25]
Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[26]
Egocentric world model for photorealistic hand-object interaction synthesis
Dayou Li, Lulin Liu, Bangya Liu, Shijie Zhou, Jiu Feng, Ziqi Lu, Minghui Zheng, Chenyu You, and Zhiwen Fan. Egocentric world model for photorealistic hand-object interaction synthesis. arXiv preprint arXiv:2603.13615, 2026
arXiv 2026
-
[27]
Yu Li, Menghan Xia, Gongye Liu, Jianhong Bai, Xintao Wang, Conglang Zhang, Yuxuan Lin, Ruihang Chu, Pengfei Wan, and Yujiu Yang. Adaviewplanner: Adapting video diffusion models for viewpoint planning in 4d scenes.arXiv preprint arXiv:2510.10670, 2025
arXiv 2025
-
[28]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
2025
-
[29]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[30]
Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
Pith/arXiv arXiv 2025
-
[31]
Yume-1.5: A text-controlled interactive world generation model
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, Tong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model. arXiv preprint arXiv:2512.22096, 2025
arXiv 2025
-
[32]
Recondreamer: Crafting world models for driving scene reconstruction via online restoration
Chaojun Ni, Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Wenkang Qin, Guan Huang, Chen Liu, Yuyin Chen, Yida Wang, Xueyang Zhang, et al. Recondreamer: Crafting world models for driving scene reconstruction via online restoration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1559–1569, 2025. 12
2025
-
[33]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
2019
-
[34]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[36]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6121–6132, 2025
2025
-
[37]
Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
Junyoung Seo, Hyunwook Choi, Minkyung Kwon, Jinhyeok Choi, Siyoon Jin, Gayoung Lee, Junho Kim, JoungBin Lee, Geonmo Gu, Dongyoon Han, et al. Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
arXiv 2026
-
[38]
Gim: Learning generalizable image matcher from internet videos.arXiv preprint arXiv:2402.11095, 2024
Xuelun Shen, Zhipeng Cai, Wei Yin, Matthias Müller, Zijun Li, Kaixuan Wang, Xiaozhi Chen, and Cheng Wang. Gim: Learning generalizable image matcher from internet videos.arXiv preprint arXiv:2402.11095, 2024
arXiv 2024
-
[39]
Egoforge: Goal-directed egocentric world simulator.arXiv preprint arXiv:2603.20169, 2026
Yifan Shen, Jiateng Liu, Xinzhuo Li, Yuanzhe Liu, Bingxuan Li, Houze Yang, Wenqi Jia, Yijiang Li, Tianjiao Yu, James Matthew Rehg, et al. Egoforge: Goal-directed egocentric world simulator.arXiv preprint arXiv:2603.20169, 2026
arXiv 2026
-
[40]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[41]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[42]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[43]
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, Linfeng Zhang, et al. Hunyuan-gamecraft-2: Instruction-following interactive game world model.arXiv preprint arXiv:2511.23429, 2025
arXiv 2025
-
[44]
Advancing open-source world models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models. arXiv preprint arXiv:2601.20540, 2026
Pith/arXiv arXiv 2026
-
[45]
Playerone: Egocentric world simulator.arXiv preprint arXiv:2506.09995, 2025
Yuanpeng Tu, Hao Luo, Xi Chen, Xiang Bai, Fan Wang, and Hengshuang Zhao. Playerone: Egocentric world simulator.arXiv preprint arXiv:2506.09995, 2025
arXiv 2025
-
[46]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[47]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[48]
Yuxi Wang, Wenqi Ouyang, Tianyi Wei, Yi Dong, Zhiqi Shen, and Xingang Pan. Hand2world: Autoregressive egocentric interaction generation via free-space hand gestures.arXiv preprint arXiv:2602.09600, 2026. 13
arXiv 2026
-
[49]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
2004
-
[50]
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
Pith/arXiv arXiv 2026
-
[51]
Jiannan Xiang, Yi Gu, Zihan Liu, Zeyu Feng, Qiyue Gao, Yiyan Hu, Benhao Huang, Guangyi Liu, Yichi Yang, Kun Zhou, et al. Pan: A world model for general, interactable, and long-horizon world simulation.arXiv preprint arXiv:2511.09057, 2025
arXiv 2025
-
[52]
Linxi Xie, Lisong C Sun, Ashley Neall, Tong Wu, Shengqu Cai, and Gordon Wetzstein. Generated reality: Human-centric world simulation using interactive video generation with hand and camera control.arXiv preprint arXiv:2602.18422, 2026
arXiv 2026
-
[53]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Pith/arXiv arXiv 2025
-
[54]
Yan: Foundational interactive video generation.arXiv preprint arXiv:2508.08601, 2025
Deheng Ye, Fangyun Zhou, Jiacheng Lv, Jianqi Ma, Jun Zhang, Junyan Lv, Junyou Li, Minwen Deng, Mingyu Yang, Qiang Fu, et al. Yan: Foundational interactive video generation.arXiv preprint arXiv:2508.08601, 2025
arXiv 2025
-
[55]
Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025
Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qifeng Chen, and Wenhan Luo. Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025
arXiv 2025
-
[56]
Wonder- world: Interactive 3d scene generation from a single image
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T Freeman, and Jiajun Wu. Wonder- world: Interactive 3d scene generation from a single image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5916–5926, 2025
2025
-
[57]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[58]
Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025
2025
-
[59]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
Pith/arXiv arXiv 2024
-
[60]
Chenyangguang Zhang, Botao Ye, Boqi Chen, Alexandros Delitzas, Fangjinhua Wang, Marc Pollefeys, and Xi Wang. Controllable egocentric video generation via occlusion-aware sparse 3d hand joints.arXiv preprint arXiv:2603.11755, 2026
Pith/arXiv arXiv 2026
-
[61]
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression.arXiv preprint arXiv:2512.23851, 2025
Pith/arXiv arXiv 2025
-
[62]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[63]
Yixuan Zhu, Jiaqi Feng, Wenzhao Zheng, Yuan Gao, Xin Tao, Pengfei Wan, Jie Zhou, and Jiwen Lu. Astra: General interactive world model with autoregressive denoising.arXiv preprint arXiv:2512.08931, 2025. 14 Appendix The appendix consists of four sections. Readers can click on each section number to navigate to the corresponding section: • SectionAprovides ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.