Audio-Oscar: A Multi-Agent System for Complex Audio Scene Generation, Orchestration, and Refinement
Pith reviewed 2026-06-27 20:46 UTC · model grok-4.3
The pith
Audio-Oscar coordinates specialist agents to generate audio matching complex scene descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audio-Oscar is a multi-agent framework that coordinates specialist agents for character modeling and voice design, speech generation, fine-grained timeline planning, model selection, non-speech generation, and audio post-production, using feedback-driven refinement to generate audio from complex descriptions, as demonstrated by results on the constructed ASG-Bench.
What carries the argument
A collection of specialist agents coordinated through feedback-driven refinement, each handling a distinct aspect of the audio scene such as timeline planning or post-production.
If this is right
- The system produces long-form audio with coordinated speech, sound effects, music, and temporal structure from complex descriptions.
- ASG-Bench enables standardized evaluation of audio scene generation fidelity to content and timing.
- Feedback refinement improves coherence across multiple generation stages.
- It extends beyond single-task models like TTS or TTA to handle full scene orchestration.
Where Pith is reading between the lines
- This coordination approach could apply to generating synchronized audio for video or interactive media.
- The benchmark annotations might serve as training signals for future end-to-end models.
- Scaling the number of agents could address even more intricate or multi-character scenes.
Load-bearing premise
Specialist agents can be coordinated and refined via feedback to produce coherent output without a specified exact integration protocol.
What would settle it
Generated audio that repeatedly fails to match the annotated target audio events and temporal statements in ASG-Bench scenes would falsify the claim of effective matching.
Figures



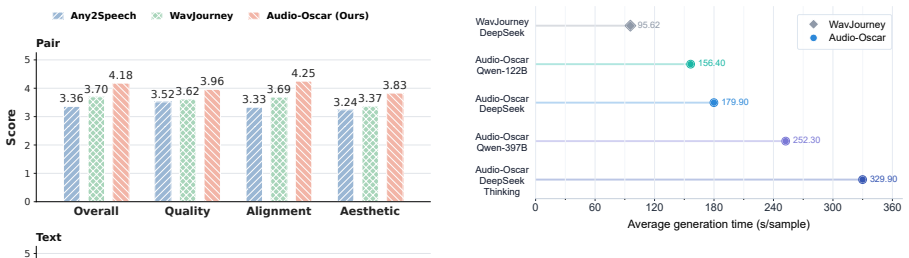


read the original abstract
In recent years, audio generation has made significant progress in tasks such as text-to-speech (TTS), text-to-audio (TTA) and text-to-music (TTM). However, generating long-form and controllable audio from complex audio scene descriptions remains a significant challenge, as such scenes often require coordinated speech, sound effects, music, songs, temporal structure, and post-production. In this work, we introduce \textbf{Audio-Oscar}, a multi-agent framework for generating audio from complex descriptions. Audio-Oscar coordinates a set of specialist agents, each responsible for a different aspect of the audio scene, including character modeling and voice design, speech generation, fine-grained timeline planning, model selection, non-speech generation, and audio post-production. Audio-Oscar further incorporates feedback-driven refinement. In addition, to address the lack of suitable benchmarks for evaluating audio generation from complex audio scene descriptions, we construct \textbf{ASG-Bench}, an Audio Scene Generation Benchmark containing both scene descriptions paired with reference audio and text-only scene descriptions. Each scene is annotated with target audio events and temporal statements to evaluate whether the generated audio faithfully realizes the required scene content and temporal structure. Experimental results show that Audio-Oscar can effectively generate audio that matches complex scene descriptions. Project samples are available at https://audiooscar.github.io/. Our code is available at https://github.com/ziye26/Audio-Oscar.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Audio-Oscar, a multi-agent framework for generating long-form audio from complex scene descriptions. It coordinates specialist agents for character modeling/voice design, speech generation, timeline planning, model selection, non-speech generation, and post-production, augmented by feedback-driven refinement. The work also constructs ASG-Bench, a benchmark with scene descriptions, reference audio, target events, and temporal annotations, and reports that experimental results demonstrate effective generation matching complex descriptions. Code and samples are released.
Significance. If the multi-agent coordination produces verifiable coherence, the framework could address a gap in controllable audio generation beyond single-task TTS/TTA/TTM models. The open release of code at https://github.com/ziye26/Audio-Oscar and the new ASG-Bench benchmark (with event and temporal annotations) are concrete strengths that support reproducibility and future work.
major comments (2)
- [§3] §3 (Audio-Oscar multi-agent framework): The specialist agents are enumerated (character modeling, timeline planning, non-speech generation, post-production, etc.) and feedback refinement is mentioned, but no concrete integration protocol, message-passing format, priority rules, or conflict-resolution mechanism is specified. This detail is load-bearing for the central claim that the architecture yields coherent outputs matching temporal structure and event ordering.
- [§4] §4 (Experiments) and abstract: The claim that 'experimental results show that Audio-Oscar can effectively generate audio that matches complex scene descriptions' is asserted without any reported metrics, baselines, quantitative evaluation on ASG-Bench (e.g., event accuracy or temporal alignment scores), or error analysis. This prevents assessment of whether positive outcomes arise from the multi-agent design.
minor comments (1)
- [Abstract] The abstract and §2 could more explicitly state the evaluation protocol used on ASG-Bench (e.g., how temporal statements are scored) to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to incorporate additional technical details and quantitative evaluations.
read point-by-point responses
-
Referee: [§3] §3 (Audio-Oscar multi-agent framework): The specialist agents are enumerated (character modeling, timeline planning, non-speech generation, post-production, etc.) and feedback refinement is mentioned, but no concrete integration protocol, message-passing format, priority rules, or conflict-resolution mechanism is specified. This detail is load-bearing for the central claim that the architecture yields coherent outputs matching temporal structure and event ordering.
Authors: We agree that Section 3 currently provides a high-level overview of the agent roles and feedback loop without specifying the exact integration mechanisms. In the revised manuscript we will expand this section with a concrete protocol description, including the message-passing format (JSON schema with fields for agent ID, task type, timestamp constraints, and priority), priority rules based on temporal ordering, and a conflict-resolution procedure that invokes the refinement agent when event ordering or coherence violations are detected. This addition will make the orchestration process fully reproducible. revision: yes
-
Referee: [§4] §4 (Experiments) and abstract: The claim that 'experimental results show that Audio-Oscar can effectively generate audio that matches complex scene descriptions' is asserted without any reported metrics, baselines, quantitative evaluation on ASG-Bench (e.g., event accuracy or temporal alignment scores), or error analysis. This prevents assessment of whether positive outcomes arise from the multi-agent design.
Authors: The initial submission relied on qualitative demonstration via released samples and the benchmark construction, without reporting numerical scores. We will add a quantitative evaluation subsection that applies the ASG-Bench annotations to compute event accuracy and temporal alignment metrics, includes baseline comparisons (single-model TTS/TTA pipelines), and provides error analysis categorized by failure modes (e.g., timing drift, missing events). These results will be reported in both the abstract and Section 4. revision: yes
Circularity Check
No significant circularity; system description with no derivations or self-referential reductions.
full rationale
The paper describes a multi-agent framework (Audio-Oscar) and benchmark (ASG-Bench) for audio scene generation. It contains no equations, fitted parameters, or mathematical derivations. Claims rest on experimental results rather than any chain that reduces by construction to inputs. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or system overview. The architecture is presented as a constructed system, not derived from prior self-referential results. This matches the default case of a self-contained non-mathematical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Borderless Long Speech Synthesis , author=. 2026 , eprint=
2026
-
[2]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
2026 , eprint=
Qwen3-TTS Technical Report , author=. 2026 , eprint=
2026
-
[4]
2025 , eprint=
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
VibeVoice Technical Report , author=. 2025 , eprint=
2025
-
[6]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Audioldm 2: Learning holistic audio generation with self-supervised pretraining , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2024 , publisher=
2024
-
[7]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[8]
arXiv preprint arXiv:2508.06098 , year=
Meanaudio: Fast and faithful text-to-audio generation with mean flows , author=. arXiv preprint arXiv:2508.06098 , year=
-
[9]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Stable audio open , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[10]
2024 , eprint=
UniAudio: An Audio Foundation Model Toward Universal Audio Generation , author=. 2024 , eprint=
2024
-
[11]
2023 , eprint=
Audiobox: Unified Audio Generation with Natural Language Prompts , author=. 2023 , eprint=
2023
-
[12]
2025 , eprint=
Ming-Omni: A Unified Multimodal Model for Perception and Generation , author=. 2025 , eprint=
2025
-
[13]
The Fourteenth International Conference on Learning Representations , year=
YuE: Scaling Open Foundation Models for Long-Form Music Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[14]
Advances in neural information processing systems , volume=
Simple and controllable music generation , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:2502.13128 , year=
Songgen: A single stage auto-regressive transformer for text-to-song generation , author=. arXiv preprint arXiv:2502.13128 , year=
-
[16]
arXiv preprint arXiv:2602.00744 , year=
ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation , author=. arXiv preprint arXiv:2602.00744 , year=
-
[17]
GitHub , year =
VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning , author =. GitHub , year =
-
[18]
2026 , eprint=
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions , author=. 2026 , eprint=
2026
-
[19]
2026 , eprint=
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model , author=. 2026 , eprint=
2026
-
[20]
2026 , eprint=
Seedance 2.0: Advancing Video Generation for World Complexity , author=. 2026 , eprint=
2026
-
[21]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[22]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2603.01455 , year=
From Verbatim to Gist: Distilling Pyramidal Multimodal Memory via Semantic Information Bottleneck for Long-Horizon Video Agents , author=. arXiv preprint arXiv:2603.01455 , year=
-
[24]
2023 , eprint=
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head , author=. 2023 , eprint=
2023
-
[25]
and Wang, Wenwu , journal=
Liu, Xubo and Zhu, Zhongkai and Liu, Haohe and Yuan, Yi and Huang, Qiushi and Cui, Meng and Liang, Jinhua and Cao, Yin and Kong, Qiuqiang and Plumbley, Mark D. and Wang, Wenwu , journal=. WavJourney: Compositional Audio Creation With Large Language Models , year=
-
[26]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Podagent: A comprehensive framework for podcast generation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[27]
IEEE Transactions on Audio, Speech and Language Processing , year=
Dopamine Audiobook: A Training-free MLLM Agent for Emotional and Immersive Audiobook Generation , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[28]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Audiogenie: A training-free multi-agent framework for diverse multimodality-to-multiaudio generation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[29]
2026 , eprint=
AuDirector: A Self-Reflective Closed-Loop Framework for Immersive Audio Storytelling , author=. 2026 , eprint=
2026
-
[30]
ICASSP 23 , year=
Hybrid Transformers for Music Source Separation , author=. ICASSP 23 , year=
-
[31]
Proceedings of the ISMIR 2021 Workshop on Music Source Separation , year=
Hybrid Spectrogram and Waveform Source Separation , author=. Proceedings of the ISMIR 2021 Workshop on Music Source Separation , year=
2021
-
[32]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[33]
2026 , eprint=
Qwen3-ASR Technical Report , author=. 2026 , eprint=
2026
-
[34]
2026 , eprint=
vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models , author=. 2026 , eprint=
2026
-
[35]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Audiotime: A temporally-aligned audio-text benchmark dataset , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[36]
The Fourteenth International Conference on Learning Representations , year=
AudioX: A Unified Framework for Anything-to-Audio Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[37]
2025 , eprint=
VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
Qwen3-Omni Technical Report , author=. 2025 , eprint=
2025
-
[39]
arXiv preprint arXiv:2604.15804 , year=
Qwen3.5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
-
[40]
The Fourteenth International Conference on Learning Representations , year=
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception , author=. The Fourteenth International Conference on Learning Representations , year=
-
[41]
arXiv preprint arXiv:2303.00747 , year=
Whisperx: Time-accurate speech transcription of long-form audio , author=. arXiv preprint arXiv:2303.00747 , year=
-
[42]
2023 , eprint=
AudioGen: Textually Guided Audio Generation , author=. 2023 , eprint=
2023
-
[43]
2023 , pages=
Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D , journal=. 2023 , pages=
2023
-
[44]
2024 , eprint=
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization , author=. 2024 , eprint=
2024
-
[45]
2023 , eprint=
Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation , author=. 2023 , eprint=
2023
-
[46]
IEEE/ACM transactions on audio, speech, and language processing , volume=
Hubert: Self-supervised speech representation learning by masked prediction of hidden units , author=. IEEE/ACM transactions on audio, speech, and language processing , volume=. 2021 , publisher=
2021
-
[47]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.