RealDocBench: A Benchmark for Field-Level QA and Layout Understanding on Real-World Regulated Documents
Pith reviewed 2026-06-27 22:06 UTC · model grok-4.3
The pith
RealDocBench evaluates document parsers on 1,356 field-level questions from 581 real regulated documents rather than clean academic pages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
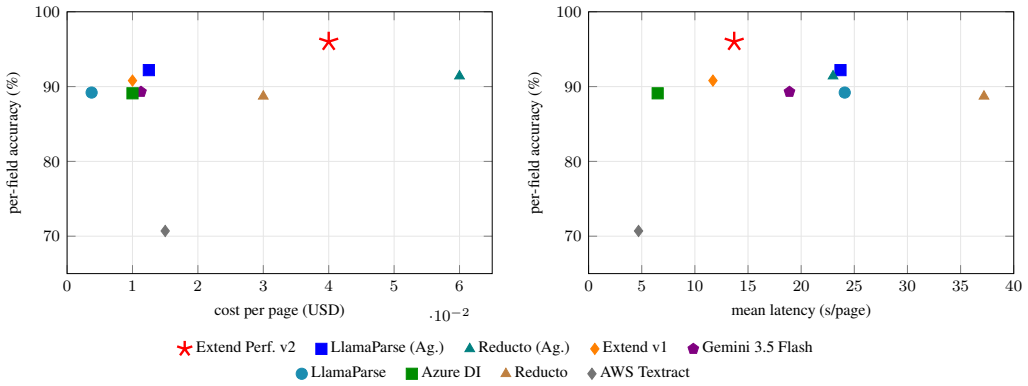
RealDocBench consists of a QA track with 1,356 field-level questions over 581 documents spanning four domains, each paired with a typed gold_dict, and a layout track with 1,500 page images annotated under a nine-class taxonomy. When eighteen systems are scored on both per-field accuracy and strict per-question accuracy plus cost and latency, the results expose wide performance variation hidden by conventional metrics, persistent difficulty in the medical subdomain, and sharp accuracy-cost-latency trade-offs.
What carries the argument
RealDocBench benchmark with its QA track for typed field extraction and layout track for COCO-style bounding-box detection scored via Hungarian matcher with split/merge recovery.
If this is right
- Parsers must be assessed on per-field correctness rather than document-level similarity scores.
- Medical regulated documents remain harder than other domains across commercial APIs, VLMs, and open OCR models.
- Operating-point selection requires explicit measurement of per-page cost and cache-busted latency alongside accuracy.
- Reproducible comparisons depend on releasing datasets, parser adapters, and a shared evaluation harness.
Where Pith is reading between the lines
- Teams could extend the taxonomy and question set to additional regulated domains without changing the core scoring protocol.
- The adjacency-aware matcher might be reused for layout evaluation in non-regulated document categories.
- Cost and latency data could guide selection of different models for batch versus interactive use cases.
Load-bearing premise
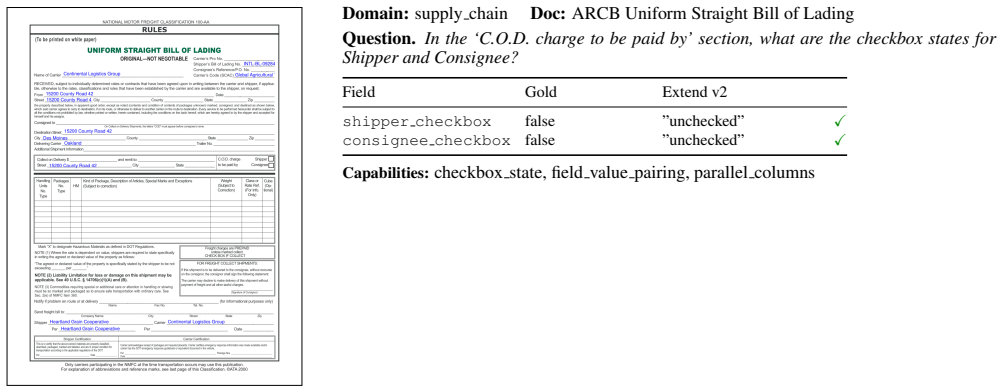
The human-verified field questions and bounding-box annotations on these 581 documents accurately represent the requirements of downstream agents in high-stakes regulated workflows.
What would settle it
A system that scores low on RealDocBench field accuracy and layout metrics yet achieves high success rates when deployed on actual mortgage underwriting or clinical record pipelines would falsify the benchmark's claim to relevance.
Figures








read the original abstract
Document parsing systems are increasingly deployed in high-stakes, regulated workflows such as mortgage underwriting, financial reporting, supply-chain logistics, and clinical records. Yet most public benchmarks evaluate parsers on clean academic layouts or synthetic prose, and report a single OCR or markdown-level similarity score. Such documents and metrics correlate poorly with what downstream agents actually need: the correct value for a specific field on a messy real-world page. We introduce RealDocBench, a two-track benchmark built from real regulated documents. The QA track contains 1,356 field-level questions over 581 documents spanning four domains, where each question is paired with a typed gold_dict of key-to-value answers and parsers are scored on both per-field and strict per-question accuracy. The layout track contains 1,500 human-verified page images annotated with COCO-style bounding boxes under a nine-class public taxonomy, scored with a Hungarian matcher that includes adjacency-aware split/merge recovery. We evaluate eighteen systems, spanning commercial parsing APIs, general-purpose VLMs, and open-source OCR models, under a uniform extraction-and-scoring protocol, and report accuracy alongside per-page cost and cache-busted latency. RealDocBench exposes a wide performance spread that single-number benchmarks hide, a persistently hard medical sub-domain, and sharp cost/latency trade-offs across operating points. We release the datasets, parser adapters, and evaluation harness to support reproducible, field-level comparison of document parsing systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RealDocBench, a two-track benchmark for document parsing on 581 real regulated documents across four domains. The QA track provides 1,356 human-verified field-level questions with typed gold_dict answers, scored on per-field and strict per-question accuracy. The layout track supplies 1,500 COCO-style bounding-box annotations under a nine-class taxonomy, scored with a Hungarian matcher that includes adjacency-aware split/merge recovery. Eighteen systems (commercial APIs, VLMs, OCR models) are evaluated under a uniform protocol that also reports per-page cost and cache-busted latency. The central claims are that the benchmark reveals a wide performance spread hidden by single-number metrics, identifies a persistently hard medical subdomain, and exposes sharp cost/latency trade-offs.
Significance. If the annotation and question-generation protocols are shown to be reliable, RealDocBench would supply a field-level evaluation resource that better matches high-stakes downstream use cases than existing synthetic or clean-layout benchmarks. The public release of the datasets, parser adapters, and evaluation harness is a concrete strength that enables reproducible comparison.
major comments (2)
- [§3 / Abstract] §3 (Benchmark Construction) and Abstract: the assertion that the 1,356 field-level questions and typed gold_dicts accurately reflect downstream agent requirements in regulated workflows is load-bearing for all three headline claims (performance spread, medical hardness, cost/latency trade-offs), yet the manuscript reports neither inter-annotator agreement statistics, annotator credentials, question-generation protocol details, nor any external workflow-validation step. Without these, the observed spreads could be artifacts of the chosen questions rather than evidence about parser behavior.
- [Table 2 / §4.2] Table 2 / §4.2 (Medical subdomain results): the claim of a 'persistently hard medical sub-domain' rests on the per-domain accuracy numbers, but the paper supplies no error analysis, confusion matrices, or breakdown by question type that would confirm the hardness is due to document properties rather than annotation or domain-specific gold_dict choices.
minor comments (3)
- [Figure 3 / §4.3] Figure 3 caption and §4.3: the latency axis label should explicitly state whether the reported times are cache-busted or include any warm-up runs.
- [§2] §2 (Related Work): the comparison to prior document benchmarks would be clearer if the table listed the exact number of field-level questions (rather than document counts) for each prior dataset.
- [§3.3] The nine-class taxonomy in the layout track is introduced without a reference to the source ontology or justification for the chosen granularity; a short footnote would suffice.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional transparency and analysis would strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3 / Abstract] §3 (Benchmark Construction) and Abstract: the assertion that the 1,356 field-level questions and typed gold_dicts accurately reflect downstream agent requirements in regulated workflows is load-bearing for all three headline claims (performance spread, medical hardness, cost/latency trade-offs), yet the manuscript reports neither inter-annotator agreement statistics, annotator credentials, question-generation protocol details, nor any external workflow-validation step. Without these, the observed spreads could be artifacts of the chosen questions rather than evidence about parser behavior.
Authors: We agree that greater detail on the annotation and question-generation process is necessary to support the benchmark's claims. In the revised version we will expand §3 with: (i) the full question-generation protocol, including how questions were derived from typical regulated workflows; (ii) annotator credentials and domain expertise; and (iii) inter-annotator agreement statistics computed on the subset of questions that received multiple annotations. We did not perform a separate external workflow-validation study; we will explicitly note this limitation and frame the questions as human-verified proxies rather than formally validated downstream tasks. These additions will reduce the risk that performance spreads are artifacts of question selection. revision: yes
-
Referee: [Table 2 / §4.2] Table 2 / §4.2 (Medical subdomain results): the claim of a 'persistently hard medical sub-domain' rests on the per-domain accuracy numbers, but the paper supplies no error analysis, confusion matrices, or breakdown by question type that would confirm the hardness is due to document properties rather than annotation or domain-specific gold_dict choices.
Authors: We accept that the current manuscript does not provide sufficient supporting analysis for the medical-subdomain claim. We will add a dedicated error-analysis subsection that includes: per-question-type accuracy breakdowns (e.g., numerical, date, entity, and free-text fields), representative failure examples from medical documents, and discussion of document properties (dense tables, specialized terminology, regulatory formatting) that correlate with lower scores. This material will help distinguish document-intrinsic difficulty from potential annotation or gold_dict artifacts. We believe the per-domain accuracy gap remains informative, but the additional analysis will make the claim more robust. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained empirical contribution
full rationale
The paper presents a new dataset (RealDocBench) consisting of 581 real regulated documents, 1,356 field-level QA pairs with typed gold_dicts, and 1,500 COCO-style bounding box annotations, followed by an empirical evaluation of 18 existing parsing systems under uniform protocols. No mathematical derivations, equations, fitted parameters, or predictions are claimed. The central results (performance spreads, medical subdomain hardness, cost/latency trade-offs) are direct outputs of running the systems on the released data and harness; they do not reduce to any self-definition, self-citation chain, or renaming of inputs. The human-verification step is presented as an independent annotation process rather than a derived quantity. This is a standard dataset paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amazon textract.https://aws
Amazon Web Services. Amazon textract.https://aws. amazon.com/textract/, 2026. Accessed 2026. 3
2026
-
[2]
Claude.https://www.anthropic.com/ claude, 2026
Anthropic. Claude.https://www.anthropic.com/ claude, 2026. Accessed 2026. 7, 8
2026
-
[3]
Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Nikolaos Livathinos, et al. Docling technical report. arXiv preprint arXiv:2408.09869, 2024. 3, 7
arXiv 2024
-
[4]
Chandra: A document ocr model.https : 10 //github.com/datalab- to/chandra, 2025
Datalab. Chandra: A document ocr model.https : 10 //github.com/datalab- to/chandra, 2025. Ac- cessed 2026. 3, 7
2025
-
[5]
Gemini.https://deepmind
Google DeepMind. Gemini.https://deepmind. google/models/gemini/, 2026. Accessed 2026. 7
2026
-
[6]
Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimos- thenis Karatzas, Shijian Lu, and C.V . Jawahar. Icdar2019 competition on scanned receipt ocr and information extrac- tion. InInternational Conference on Document Analysis and Recognition (ICDAR), 2019. 3
2019
-
[7]
Funsd: A dataset for form understanding in noisy scanned documents
Guillaume Jaume, Hazim Kemal Ekenel, and Jean-Philippe Thiran. Funsd: A dataset for form understanding in noisy scanned documents. InInternational Conference on Docu- ment Analysis and Recognition Workshops (ICDARW), 2019. 3
2019
-
[8]
Docbank: A benchmark dataset for document layout analysis
Minghao Li, Yiheng Xu, Lei Cui, Shaohan Huang, Furu Wei, Zhoujun Li, and Ming Zhou. Docbank: A benchmark dataset for document layout analysis. InInternational Conference on Computational Linguistics (COLING), 2020. 3
2020
-
[9]
Yumeng Li, Guang Yang, Hao Liu, Bowen Wang, and Colin Zhang. dots.ocr: Multilingual document layout pars- ing in a single vision-language model.arXiv preprint arXiv:2512.02498, 2025. 3, 7
arXiv 2025
-
[10]
Ocrbench: On the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xucheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: On the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 2024. 3
2024
-
[11]
Llamaparse.https : / / www
LlamaIndex. Llamaparse.https : / / www . llamaindex . ai / llamaparse, 2026. Accessed
2026
-
[12]
Parsebench: A document parsing benchmark for ai agents.arXiv preprint arXiv:2604.08538, 2026
LlamaIndex. Parsebench: A document parsing benchmark for ai agents.arXiv preprint arXiv:2604.08538, 2026. 3, 4
Pith/arXiv arXiv 2026
-
[13]
Jawa- har
Minesh Mathew, Dimosthenis Karatzas, and C.V . Jawa- har. Docvqa: A dataset for vqa on document images. In IEEE Winter Conference on Applications of Computer Vision (WACV), 2021. 3, 4
2021
-
[14]
Minesh Mathew, Viraj Bagal, Rub `en Tito, Dimosthenis Karatzas, Ernest Valveny, and C.V . Jawahar. Infographicvqa. InIEEE Winter Conference on Applications of Computer Vi- sion (WACV), 2022. 3
2022
-
[15]
Azure ai document intelligence.https : / / azure
Microsoft. Azure ai document intelligence.https : / / azure . microsoft . com / products / ai - services / ai - document - intelligence, 2026. Accessed 2026. 3
2026
-
[16]
Nanonets-ocr-s: A state-of-the-art ocr model for document markdown.https://huggingface.co/ nanonets/Nanonets- OCR- s, 2025
Nanonets. Nanonets-ocr-s: A state-of-the-art ocr model for document markdown.https://huggingface.co/ nanonets/Nanonets- OCR- s, 2025. Accessed 2026. 3, 7
2025
-
[17]
Nvidia nemotron nano v2 vl.arXiv preprint arXiv:2511.03929, 2025
NVIDIA. Nvidia nemotron nano v2 vl.arXiv preprint arXiv:2511.03929, 2025. 7
arXiv 2025
-
[18]
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, et al. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations.arXiv preprint arXiv:2412.07626, 2024. 3, 4
arXiv 2024
-
[19]
Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595, 2025
PaddlePaddle Team. Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595, 2025. 7, 8
Pith/arXiv arXiv 2025
-
[20]
PaddlePaddle Team. Paddleocr-vl: Boosting multilingual document parsing via a 0.9b ultra-compact vision-language model.arXiv preprint arXiv:2510.14528, 2025. 3, 7, 8, 9
arXiv 2025
-
[21]
Cord: A con- solidated receipt dataset for post-ocr parsing
Seunghyun Park, Seung Shin, Bado Lee, Junyeop Lee, Jae- heung Surh, Minjoon Seo, and Hwalsuk Lee. Cord: A con- solidated receipt dataset for post-ocr parsing. InNeurIPS Workshop on Document Intelligence, 2019. 3
2019
-
[22]
Nassar, and Peter Staar
Birgit Pfitzmann, Christoph Auer, Michele Dolfi, Ahmed S. Nassar, and Peter Staar. Doclaynet: A large human- annotated dataset for document-layout segmentation. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2022. 3
2022
-
[23]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wil- helm, Kyle Lo, and Luca Soldaini. olmocr: Unlocking tril- lions of tokens in pdfs with vision language models.arXiv preprint arXiv:2502.18443, 2025. 3
arXiv 2025
-
[24]
olmocr 2: Unit test rewards for document ocr.arXiv preprint arXiv:2510.19817, 2025
Jake Poznanski, Luca Soldaini, and Kyle Lo. olmocr 2: Unit test rewards for document ocr.arXiv preprint arXiv:2510.19817, 2025. 3, 4, 7
arXiv 2025
-
[25]
Reducto: Document ingestion api.https:// reducto.ai/, 2026
Reducto. Reducto: Document ingestion api.https:// reducto.ai/, 2026. Accessed 2026. 3
2026
-
[26]
unselected
Xu Zhong, Jianbin Tang, and Antonio Jimeno-Yepes. Pub- laynet: Largest dataset ever for document layout analysis. In International Conference on Document Analysis and Recog- nition (ICDAR), 2019. 3 11 A. Privacy-Preserving Document Synthesis This appendix details the pipeline used to construct the synthesized portion of the medical/healthcare and tax trac...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.