Sparsely gated tiny linear experts
Pith reviewed 2026-06-27 22:48 UTC · model grok-4.3
The pith
Sparsely gated single-neuron linear experts improve perplexity when replacing all transformer feedforward layers and enable direct interpretability of factual recall circuits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
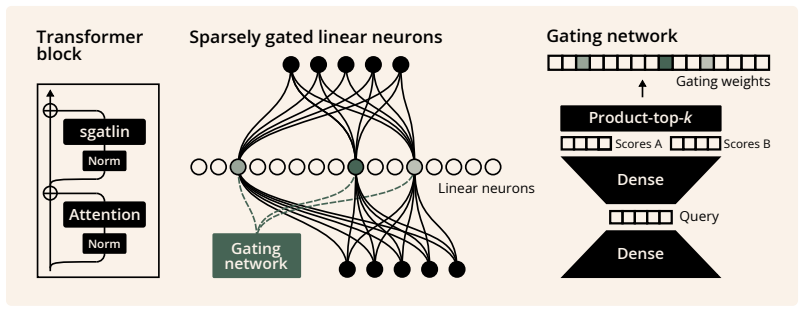
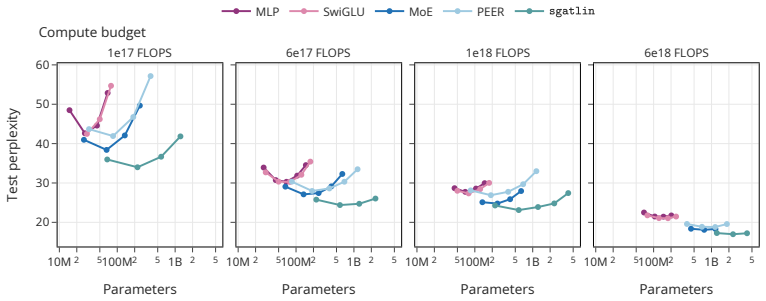
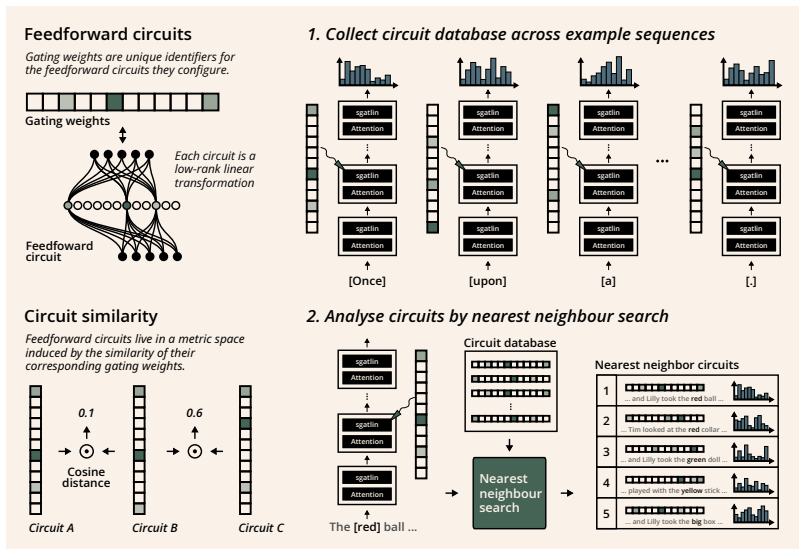
Replacing every transformer feedforward layer with sparsely gated tiny linear experts (sgatlin), each expert consisting of one linear neuron chosen by a sparse gate and lacking any nonlinearity, yields lower perplexity than the original dense nonlinear layers in isoflop-matched language-model training runs. The resulting feedforward circuits form semantically structured clusters that are causally implicated in factual recall, and these circuits can be interpreted without training auxiliary replacement models.
What carries the argument
Sparsely gated tiny linear experts (sgatlin): each expert is a single linear neuron selected by sparse gating, with nonlinearity removed, replacing the usual transformer feedforward sub-layer.
If this is right
- Perplexity improves across compute budgets when sgatlin replaces all feedforward layers.
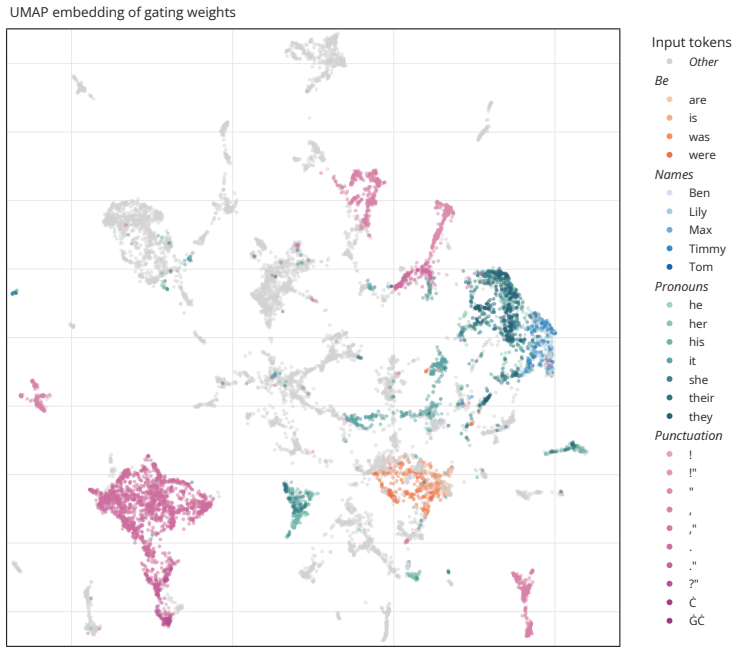
- Feedforward circuits become directly interpretable as semantically structured clusters.
- These clusters are causally implicated in factual recall.
- The approach opens a route to compute-efficient and interpretable transformer feedforward layers.
Where Pith is reading between the lines
- Hardware optimized for linear operations could see larger efficiency gains because the experts contain no nonlinearities.
- The direct interpretability might allow targeted editing of factual knowledge without retraining the whole model.
- The same single-neuron sparse gating pattern could be tested on attention or other sub-layers to check whether the efficiency and interpretability benefits generalize.
- Increasing the total pool of available linear neurons while keeping the activation count fixed could further trade parameters for compute without changing the isoflop regime.
Load-bearing premise
Removing nonlinearity from the experts and shrinking each expert to a single linear neuron under sparse gating preserves or increases effective capacity without hidden costs in training dynamics or generalization.
What would settle it
An isoflop experiment on a larger model or different dataset in which sgatlin replacement produces equal or worse perplexity, or an activation-intervention test showing that the identified clusters have no causal effect on factual recall outputs.
Figures

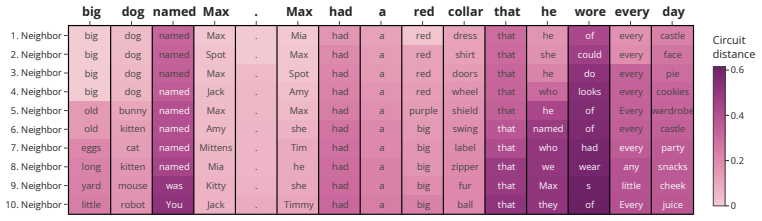
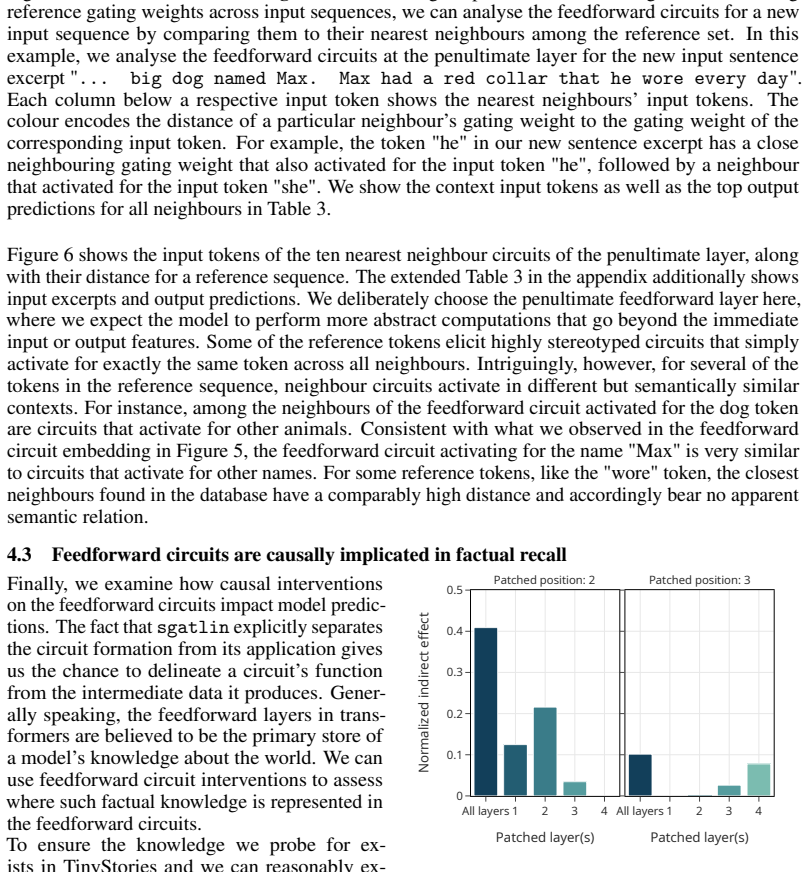


read the original abstract
Sparsity allows scaling model parameters without proportionally increasing computational cost. While mixture of experts (MoE) models are made increasingly sparse, individual experts typically remain large and dense. Here, we demonstrate that further increasing sparsity by shrinking each expert to consist of a single neuron and selecting a tiny fraction of many available neurons can improve compute efficiency and interpretability. Counterintuitively, the key to achieving both is removing the nonlinearity typically applied to the experts, resulting in a network of sparsely gated linear neurons (sgatlin). In an isoflop comparison, we find that replacing all transformer feedforward layers with sgatlin improves perplexity in language models across different compute budgets. At the same time, the sparsity and linearity of the resulting feedforward circuits present new opportunities for model interpretability. In a small-scale case study, we demonstrate that feedforward circuits in sgatlin can be interpreted without having to train additional replacement models. We find that they form semantically structured clusters and are causally implicated in factual recall. Our findings paint a possible path towards compute-efficient and interpretable transformer feedforward layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes sgatlin (sparsely gated tiny linear experts), an architecture that replaces transformer feedforward layers with a large pool of single-neuron linear experts under sparse gating, achieved by removing the usual expert nonlinearity. It claims that this yields lower perplexity than standard transformers in isoflop comparisons across compute budgets and that the resulting linear sparse circuits enable direct interpretability, forming semantically structured clusters that are causally implicated in factual recall.
Significance. If the isoflop perplexity gains and the interpretability results are robust, the work would challenge the conventional need for nonlinearity and large dense experts in MoE-style layers, potentially enabling more parameter-efficient and mechanistically interpretable transformers. The direct interpretability without auxiliary models is a notable strength if the causal findings generalize.
major comments (3)
- [results on isoflop comparison] Isoflop comparison (results section): the central claim of improved perplexity requires a precise accounting of all FLOPs, including gating-network overhead and any memory or optimizer costs from the large expert pool; without this, it remains possible that apparent gains arise from unaccounted differences in effective capacity or training dynamics rather than the linear-sparse design itself.
- [interpretability case study] Interpretability case study: the assertion that circuits form semantically structured clusters causally implicated in factual recall needs quantitative support (e.g., cluster coherence metrics and specific ablation accuracies before/after intervention) to establish causality; the linearity is presented as enabling this, but the section should demonstrate that the same analysis is infeasible or less informative in standard nonlinear FF layers.
- [method] Method (expert definition): the decision to shrink experts to single linear neurons and remove nonlinearity is load-bearing for both the efficiency and interpretability claims; the manuscript should include an ablation or expressivity argument showing that the sparse linear composition does not reduce rank or introduce optimization pathologies relative to standard FF layers at matched FLOPs.
minor comments (2)
- [abstract] The acronym 'sgatlin' is introduced in the abstract without immediate expansion; define it on first use and ensure consistent usage.
- [experimental setup] Provide the exact sparsity fraction, expert count, and model scales used in the isoflop tables so that the parameter-free nature of the comparison can be verified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript accordingly to strengthen the isoflop accounting, add quantitative support for interpretability, and include the requested ablation and expressivity discussion.
read point-by-point responses
-
Referee: [results on isoflop comparison] Isoflop comparison (results section): the central claim of improved perplexity requires a precise accounting of all FLOPs, including gating-network overhead and any memory or optimizer costs from the large expert pool; without this, it remains possible that apparent gains arise from unaccounted differences in effective capacity or training dynamics rather than the linear-sparse design itself.
Authors: We agree that a complete FLOPs accounting is necessary to substantiate the central claim. In the revised manuscript we add an explicit breakdown that includes gating-network FLOPs, memory access costs for the expert pool, and optimizer-state overhead. The updated analysis confirms that these terms remain small relative to the compute savings from extreme sparsity and that the perplexity advantage persists after their inclusion. We also report training-curve diagnostics to address potential differences in optimization dynamics. revision: yes
-
Referee: [interpretability case study] Interpretability case study: the assertion that circuits form semantically structured clusters causally implicated in factual recall needs quantitative support (e.g., cluster coherence metrics and specific ablation accuracies before/after intervention) to establish causality; the linearity is presented as enabling this, but the section should demonstrate that the same analysis is infeasible or less informative in standard nonlinear FF layers.
Authors: We accept that quantitative metrics and explicit comparisons are required. The revision adds silhouette-score cluster-coherence statistics and before/after intervention accuracies on factual-recall probes. We further include a side-by-side analysis on matched nonlinear FF layers showing that the same direct circuit extraction yields substantially lower coherence and weaker causal effects, supporting the claim that linearity enables the observed interpretability. revision: yes
-
Referee: [method] Method (expert definition): the decision to shrink experts to single linear neurons and remove nonlinearity is load-bearing for both the efficiency and interpretability claims; the manuscript should include an ablation or expressivity argument showing that the sparse linear composition does not reduce rank or introduce optimization pathologies relative to standard FF layers at matched FLOPs.
Authors: We have added both an ablation and an expressivity argument. The new ablation trains models with standard nonlinear FF layers, single-neuron linear experts, and intermediate variants at identical total FLOPs; effective rank (measured via singular-value spectra) and convergence behavior remain comparable. The expressivity section notes that sparse linear combinations of many neurons can still span high-dimensional subspaces, consistent with the observed performance parity. revision: yes
Circularity Check
No circularity: empirical isoflop results with no derivation chain
full rationale
The paper's central claims rest on experimental isoflop comparisons showing perplexity improvements when replacing transformer feedforward layers with sgatlin (sparsely gated single linear neurons, nonlinearity removed). No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes. The work is self-contained as a set of training/evaluation outcomes against external benchmarks, with interpretability observations likewise empirical. No load-bearing steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (2)
- expert count
- sparsity fraction
axioms (1)
- domain assumption Linear single-neuron experts under sparse gating can match or exceed the representational power of standard nonlinear feedforward layers
invented entities (1)
-
sgatlin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, January 2017
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, January 2017. URLhttp://arxiv.org/abs/1701.06538. arXiv:1701.06538 [cs]
Pith/arXiv arXiv 2017
-
[2]
Scaling Laws for Fine-Grained Mixture of Experts, February 2024
Jakub Krajewski, Jan Ludziejewski, Kamil Adamczewski, Maciej Pióro, Michał Krutul, Szymon Antoniak, Kamil Ciebiera, Krystian Król, Tomasz Odrzygó´ zd´ z, Piotr Sankowski, Marek Cygan, and Sebastian Jaszczur. Scaling Laws for Fine-Grained Mixture of Experts, February 2024. URLhttp://arxiv.org/abs/2402.07871. arXiv:2402.07871 [cs]
arXiv 2024
-
[3]
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices, October 2024
Andres Potapczynski, Shikai Qiu, Marc Finzi, Christopher Ferri, Zixi Chen, Micah Goldblum, Bayan Bruss, Christopher De Sa, and Andrew Gordon Wilson. Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices, October 2024. URL http://arxiv. org/abs/2410.02117. arXiv:2410.02117 [cs]
arXiv 2024
-
[4]
Language Model Circuits Are Sparse in the Neuron Basis, January 2026
Aryaman Arora, Zhengxuan Wu, Jacob Steinhardt, and Sarah Schwettmann. Language Model Circuits Are Sparse in the Neuron Basis, January 2026. URL http://arxiv.org/abs/2601. 22594. arXiv:2601.22594 [cs]
Pith/arXiv arXiv 2026
-
[5]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
Pith/arXiv arXiv 2024
-
[6]
OpenAI, Haiming Bao, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, Vlad Fome...
Pith/arXiv arXiv 2025
-
[7]
Welcome Gemma 4: Frontier multimodal intelligence on device, April 2026
Google. Welcome Gemma 4: Frontier multimodal intelligence on device, April 2026. URL https://huggingface.co/blog/gemma4
2026
-
[8]
Qwen3-Next: Towards Ultimate Training & Inference Efficiency, September 2025
Qwen Team. Qwen3-Next: Towards Ultimate Training & Inference Efficiency, September 2025. URLhttps://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
2025
-
[9]
GLM-5: from Vibe Coding to Agentic Engineering, February 2026
GLM-5-Team, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Zhon...
Pith/arXiv arXiv 2026
-
[10]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence,
DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence,
-
[11]
URLhttps://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
-
[12]
Mixture of A Million Experts, July 2024
Xu Owen He. Mixture of A Million Experts, July 2024. URL http://arxiv.org/abs/2407. 04153. arXiv:2407.04153
arXiv 2024
-
[13]
SlimPajama: A 627B token cleaned and deduplicated version of RedPajama, June 2023
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hestness, and Nolan Dey. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama, June 2023. URLhttps://huggingface.co/datasets/cerebras/SlimPajama-627B
2023
-
[14]
Large Memory Layers with Product Keys, December 2019
Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Large Memory Layers with Product Keys, December 2019. URL http://arxiv. org/abs/1907.05242. arXiv:1907.05242
arXiv 2019
-
[15]
Gaussian Error Linear Units (GELUs), 2023
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units (GELUs), 2023. URL https://arxiv.org/abs/1606.08415. _eprint: 1606.08415
Pith/arXiv arXiv 2023
-
[16]
GLU Variants Improve Transformer, 2020
Noam Shazeer. GLU Variants Improve Transformer, 2020. URL https://arxiv.org/abs/ 2002.05202. arXiv: 2002.05202
Pith/arXiv arXiv 2020
-
[17]
Decoupled Weight Decay Regularization, January 2019
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, January 2019. URLhttp://arxiv.org/abs/1711.05101. arXiv:1711.05101 [cs, math]
Pith/arXiv arXiv 2019
-
[18]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Ganqu Cui, Chaoqun He, Weilin Zhao, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Xinrong Zhang, Zhen Leng Thai, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. MiniCPM: Unveiling the Potential of Small Language Models with...
2024
-
[19]
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations
Alexander Hägele, Elie Bakouch, Atli Kosson, Loubna Ben Allal, Leandro V on Werra, and Martin Jaggi. Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations. November 2024. URLhttps://openreview.net/forum?id=Y13gSfTjGr
2024
-
[20]
Wang, David Leo Wright Hall, Percy Liang, and Tengyu Ma
Kaiyue Wen, Zhiyuan Li, Jason S. Wang, David Leo Wright Hall, Percy Liang, and Tengyu Ma. Understanding Warmup-Stable-Decay Learning Rates: A River Valley Loss Landscape View. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=m51BgoqvbP. 11
2025
-
[21]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022. ISSN 1533-7928. URL http://jmlr.org/papers/v23/21-0998. html
2022
-
[22]
Efficient Large Scale Language Modeling with Mixtures of Experts
Mikel Artetxe, Shruti Bhosale, Naman Goyal, Todor Mihaylov, Myle Ott, Sam Shleifer, Xi Vic- toria Lin, Jingfei Du, Srinivasan Iyer, Ramakanth Pasunuru, Giridharan Anantharaman, Xian Li, Shuohui Chen, Halil Akin, Mandeep Baines, Louis Martin, Xing Zhou, Punit Singh Koura, Brian O’Horo, Jeffrey Wang, Luke Zettlemoyer, Mona Diab, Zornitsa Kozareva, and Vesel...
-
[23]
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts, July 2024
Xi Victoria Lin, Akshat Shrivastava, Liang Luo, Srinivasan Iyer, Mike Lewis, Gargi Ghosh, Luke Zettlemoyer, and Armen Aghajanyan. MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts, July 2024. URLhttps://arxiv.org/abs/2407.21770v3
arXiv 2024
-
[24]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, May 2023
Ronen Eldan and Yuanzhi Li. TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, May 2023. URL http://arxiv.org/abs/2305.07759. arXiv:2305.07759 [cs]
Pith/arXiv arXiv 2023
-
[25]
Parametric UMAP Embeddings for Representation and Semisupervised Learning.Neural Computation, 33(11):2881–2907, 2021
Tim Sainburg, Leland McInnes, and Timothy Q Gentner. Parametric UMAP Embeddings for Representation and Semisupervised Learning.Neural Computation, 33(11):2881–2907, 2021
2021
-
[26]
Direct and indirect effects
Judea Pearl. Direct and indirect effects. InProceedings of the Seventeenth conference on Uncertainty in artificial intelligence, UAI’01, pages 411–420, San Francisco, CA, USA, August
-
[27]
Morgan Kaufmann Publishers Inc. ISBN 978-1-55860-800-9. URL https://dl.acm. org/doi/10.5555/2074022.2074073
-
[28]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, August 2023. URL http: //arxiv.org/abs/1706.03762. arXiv:1706.03762 [cs]
Pith/arXiv arXiv 2023
-
[29]
Improving language understanding by generative pre-training, 2018
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, and others. Improving language understanding by generative pre-training, 2018
2018
-
[30]
Del Mundo, Oncel Tuzel, Golnoosh Samei, Mohammad Rastegari, and Mehrdad Farajtabar
Iman Mirzadeh, Keivan Alizadeh, Sachin Mehta, Carlo C. Del Mundo, Oncel Tuzel, Golnoosh Samei, Mohammad Rastegari, and Mehrdad Farajtabar. ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models, 2023. URL https://arxiv.org/abs/2310. 04564
2023
-
[31]
Dauphin, Angela Fan, Michael Auli, and David Grangier
Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. Language Modeling with Gated Convolutional Networks. InProceedings of the 34th International Conference on Machine Learning, pages 933–941. PMLR, July 2017. URL https://proceedings.mlr. press/v70/dauphin17a.html
2017
-
[32]
In- terpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small, November
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. In- terpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small, November
- [33]
-
[34]
Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models. October 2024. URLhttps://openreview.net/forum?id=I4e82CIDxv
2024
-
[35]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
2025
-
[36]
Sparse Autoencoders Find Highly Interpretable Features in Language Models, October 2023
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse Autoencoders Find Highly Interpretable Features in Language Models, October 2023. URL http://arxiv.org/abs/2309.08600. arXiv:2309.08600 [cs]
Pith/arXiv arXiv 2023
-
[37]
Transcoders Find Interpretable LLM Feature Circuits, November 2024
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders Find Interpretable LLM Feature Circuits, November 2024. URL http://arxiv.org/abs/2406.11944. arXiv:2406.11944 [cs]
arXiv 2024
-
[38]
Lindsey, A
J. Lindsey, A. Templeton, J. Marcus, T. Conerly, J. Batson, and C. Olah. Sparse Crosscoders for Cross-Layer Features and Model Diffing, 2024. URL https://transformer-circuits. pub/2024/crosscoders/
2024
-
[39]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nicholas L. Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yi- fan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Henighan, and Chris Olah...
2023
-
[40]
Alon Jacovi and Yoav Goldberg. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4198–4205, Online, July 2020. Association for Computational Li...
-
[41]
SAE reconstruction errors are (empirically) pathological — AI Alignment Forum, March 2024
Wes Gurnee. SAE reconstruction errors are (empirically) pathological — AI Alignment Forum, March 2024. URL https://www.alignmentforum.org/posts/rZPiuFxESMxCDHe4B/ sae-reconstruction-errors-are-empirically-pathological
2024
-
[42]
Decomposing The Dark Matter of Sparse Autoencoders.Transactions on Machine Learning Research, December 2024
Joshua Engels, Logan Riggs Smith, and Max Tegmark. Decomposing The Dark Matter of Sparse Autoencoders.Transactions on Machine Learning Research, December 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=sXq3Wb3vef
2024
-
[43]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders
David Chanin, James Wilken-Smith, Tomáš Dulka, Hardik Bhatnagar, Satvik Golechha, and Joseph Isaac Bloom. A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders. October 2025. URLhttps://openreview.net/forum?id=R73ybUciQF
2025
-
[44]
Yutong Gao, Qinglin Meng, Yuan Zhou, and Liangming Pan. Towards Intrinsic Interpretability of Large Language Models:A Survey of Design Principles and Architectures, April 2026. URL http://arxiv.org/abs/2604.16042. arXiv:2604.16042 [cs]
Pith/arXiv arXiv 2026
-
[45]
The Expert Strikes Back: Interpreting Mixture-of-Experts Language Models at Expert Level, April 2026
Jeremy Herbst, Jae Hee Lee, and Stefan Wermter. The Expert Strikes Back: Interpreting Mixture-of-Experts Language Models at Expert Level, April 2026. URL http://arxiv.org/ abs/2604.02178. arXiv:2604.02178 [cs]
Pith/arXiv arXiv 2026
-
[46]
Softmax Linear Units, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Neel Nanda, Tom Henighan, Scott Johnston, Sheer El Showk, Nicholas Joseph, Nova DasSarma, Ben Mann, Danny Hernandez, Amanda Askell, Kamal Ndousse, Andy Jones, Dawn Drain, Anna Chen, Yuntao Bai, Deep Ganguli, Liane Lovitt, Zac Hatfield-Dodds, Jackson Kernion, Tom Conerly, Shauna Kravec, Stanislav Fort, Saurav ...
2022
-
[47]
A technical note on bilinear layers for interpretability, May 2023
Lee Sharkey. A technical note on bilinear layers for interpretability, May 2023. URL http: //arxiv.org/abs/2305.03452. arXiv:2305.03452 [cs]
arXiv 2023
-
[48]
A Mathematical Framework for Transformer Circuits, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, 13 and Chris Olah...
2021
-
[49]
Andrew M. Saxe, James L. McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks, 2014. URLhttps://arxiv.org/abs/ 1312.6120. _eprint: 1312.6120
Pith/arXiv arXiv 2014
-
[50]
Saxe, Shagun Sodhani, and Sam Lewallen
Andrew M. Saxe, Shagun Sodhani, and Sam Lewallen. The Neural Race Reduction: Dynamics of Abstraction in Gated Networks, July 2022. URL http://arxiv.org/abs/2207.10430. arXiv:2207.10430 [cs]
arXiv 2022
-
[51]
Toy Models of Superposition, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy Models of Superposition, 2022. URL https://transformer-circuits.pub/2022/toy_ model/index.html
2022
-
[52]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax
2018
-
[53]
Flax: A neural network library and ecosystem for JAX, 2023
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2023. URL http://github.com/google/flax
2023
-
[54]
The DeepMind JAX Ecosystem, 2020
Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena Martens, H...
2020
-
[55]
Grain - Feeding JAX Models, 2023
Marvin Ritter, Ihor Indyk, Aayush Singh, Andrew Audibert, Anoosha Seelam, Camelia Hanes, Eric Lau, Jacek Olesiak, Jiyang Kang, and Xihui Wu. Grain - Feeding JAX Models, 2023. URL http://github.com/google/grain
2023
-
[56]
php/AAAI/article/view/12028/11887
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger,...
-
[57]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of- the-Ar...
2020
-
[58]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, 14 M. Perrot, and E. Duchesnay. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[59]
Experiment Tracking with Weights and Biases, 2020
Lukas Biewald. Experiment Tracking with Weights and Biases, 2020. URL https://www. wandb.com/
2020
-
[60]
Collaborative data science, 2015
Plotly Technologies Inc. Collaborative data science, 2015. URL https://plot.ly. Place: Montreal, QC
2015
-
[61]
uv: An extremely fast Python package and project manager, written in Rust.,
Charlie Marsh. uv: An extremely fast Python package and project manager, written in Rust.,
-
[62]
" , ,"
URLhttps://pypi.org/project/uv/. 15 Appendix A Sparsely gated linear neuron layer 17 A.1 Parallel channels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Time and memory complexity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 B Experimental details 18 B.1 Training details . . . . . . . . . . . . . . . . ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.