DisPOSE: Projected Polystochastic Diffusion for Self-Supervised Multi-View 3D Human Pose Estimation
Pith reviewed 2026-06-27 22:04 UTC · model grok-4.3
The pith
DisPOSE models multi-view person assignment as diffusion over polystochastic tensors to recover 3D poses without synthetic data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
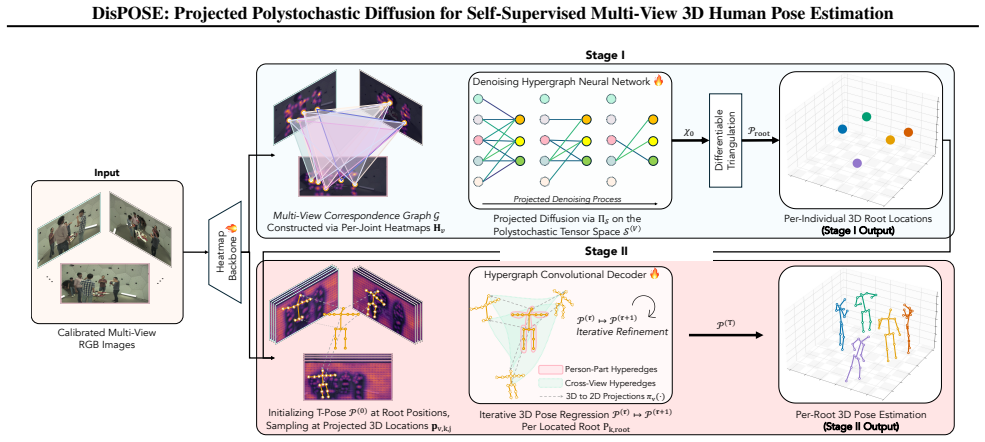
DisPOSE approximates the inherently discrete multi-view person-assignment problem as a generative diffusion process over the space of polystochastic tensors. Differentiable Sinkhorn projections during denoising guide solutions toward valid and feasible assignments based on 2D image priors. A Hypergraph-Convolutional Decoder then regresses the complete 3D skeletons by explicitly modeling relational structures and articulated joints across multiple views. The resulting method outperforms existing self-supervised approaches on standard datasets, performs strongly on highly occluded surgical scenes, demonstrates high label efficiency, and stays nearly agnostic to camera arrangements through dise
What carries the argument
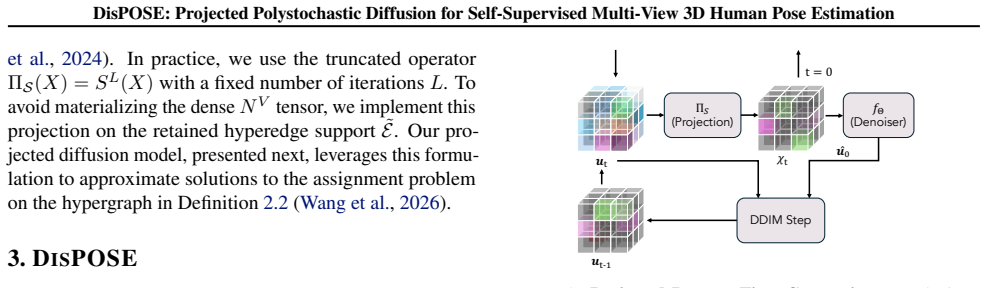
Projected polystochastic diffusion: the generative diffusion process defined over polystochastic tensors, combined with differentiable Sinkhorn projections during denoising to produce valid multi-view assignments.
If this is right
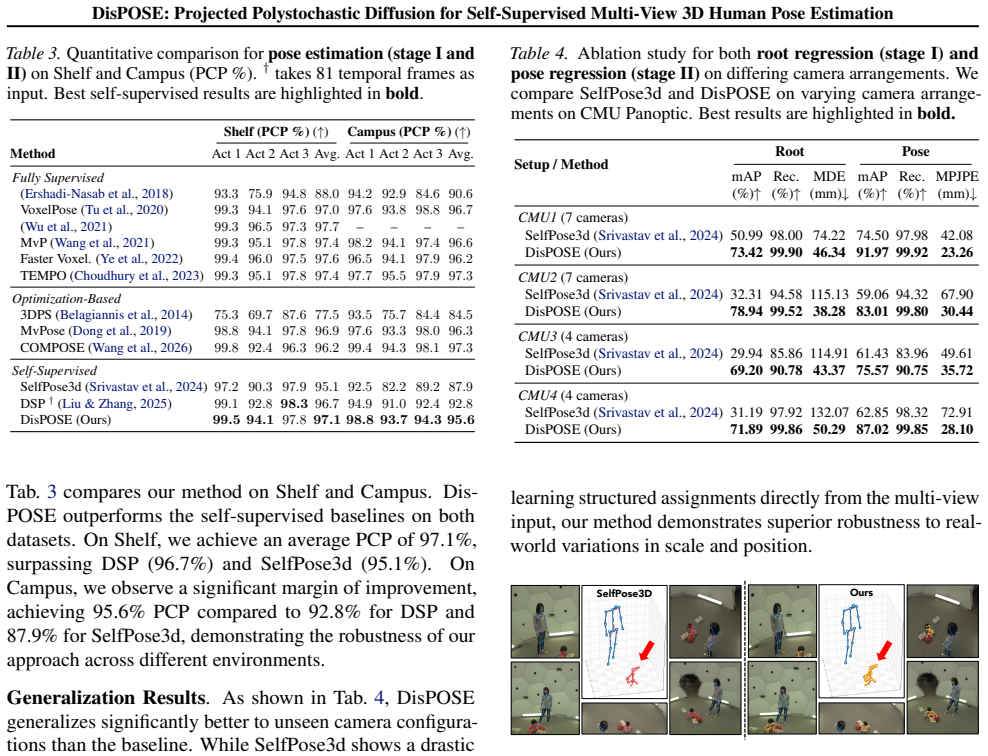
- Outperforms current state-of-the-art self-supervised multi-view pose methods on standard benchmarks.
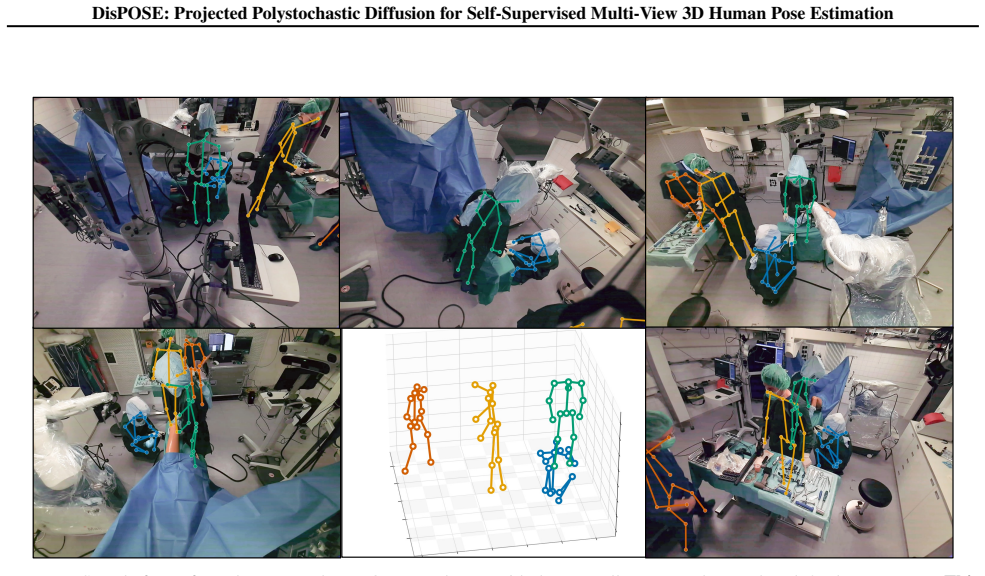
- Maintains strong accuracy on a new benchmark of highly occluded scenes from surgical operating rooms.
- Retains 99 percent of full performance when trained with only 10 percent of the pseudo-labels.
- Remains nearly independent of specific camera arrangements because assignment and root regression are disentangled while staying differentiable.
Where Pith is reading between the lines
- The same polystochastic diffusion framing could be tested on other multi-object assignment tasks such as multi-view object tracking or scene graph construction.
- High label efficiency suggests the approach may transfer usefully to semi-supervised regimes where only a small fraction of views receive manual annotations.
- Because the decoder explicitly models hypergraph relations, the method may produce more consistent 3D poses under partial view loss than purely per-person regression pipelines.
Load-bearing premise
The discrete multi-view person-assignment problem can be effectively approximated as a generative diffusion process over polystochastic tensors whose denoising is guided by differentiable Sinkhorn projections based on 2D image priors.
What would settle it
On the standard datasets or the new surgical-room benchmark, replace the diffusion-based assignment module with a non-diffusion baseline and observe whether accuracy drops below current self-supervised state-of-the-art or whether label efficiency falls sharply when using only 10 percent of the pseudo-labels.
Figures









read the original abstract
Recovering 3D human poses for multiple individuals from different camera views is a fundamental bottleneck for analyzing interacting behaviors. Existing self-supervised approaches leverage synthetic catalogues of 3D poses; however, this leads to poor generalization in real-world scenarios due to distribution shifts. We therefore introduce DisPOSE, a self-supervised framework that approximates the inherently discrete multi-view person-assignment problem as a generative diffusion process over the space of polystochastic tensors. By employing differentiable Sinkhorn projections during denoising, our model learns to guide solutions toward valid and feasible assignments based on 2D image priors. The complete 3D skeletons of localized individuals are then regressed using a Hypergraph-Convolutional Decoder that explicitly models relational structures and articulated joints across multiple views. The proposed approach outperforms current state-of-the-art self-supervised methods on standard datasets and demonstrates strong performance on a newly proposed benchmark featuring highly occluded scenes from surgical operating rooms. Our diffusion-based localization demonstrates high label efficiency, retaining 99% of its performance with only 10% of the pseudo-labels. Notably, disentangling the assignment and root regression components while maintaining differentiability makes DisPOSE nearly agnostic to different camera arrangements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DisPOSE, a self-supervised framework for multi-view 3D human pose estimation. It approximates the discrete multi-view person-assignment problem as a generative diffusion process over polystochastic tensors, employing differentiable Sinkhorn projections during denoising to guide solutions toward valid assignments from 2D image priors. A Hypergraph-Convolutional Decoder then regresses complete 3D skeletons by modeling relational structures and articulated joints. The method is claimed to outperform current state-of-the-art self-supervised approaches on standard datasets, show strong results on a new benchmark of highly occluded surgical operating room scenes, retain 99% performance with only 10% of pseudo-labels, and remain nearly agnostic to camera arrangements by disentangling assignment and root regression while preserving differentiability.
Significance. If the core diffusion-based assignment mechanism proves robust, the work could meaningfully advance self-supervised multi-view 3D pose estimation by reducing reliance on synthetic data and improving generalization to real-world occluded scenes such as surgical environments. The reported label efficiency and camera-arrangement invariance would be practically valuable strengths.
major comments (2)
- [§3 (Diffusion Model)] The central claim that a continuous diffusion process over polystochastic tensors, regularized only by differentiable Sinkhorn projections at each denoising step, reliably recovers discrete person-to-person assignments from 2D priors is load-bearing for the entire contribution. However, the manuscript reports neither per-step assignment accuracy nor permutation error metrics that would confirm the forward noise process and learned reverse process preserve the marginal constraints required for Sinkhorn to produce valid permutation-like matrices.
- [§5 (Experiments and Ablations)] No ablation is presented that removes the diffusion component while retaining the Sinkhorn projection and Hypergraph-Convolutional Decoder. This omission leaves open the possibility that reported gains derive primarily from the downstream decoder or 2D priors rather than the claimed generative assignment model, directly affecting the interpretation of the label-efficiency and outperformance results.
minor comments (2)
- [Abstract] The abstract introduces 'polystochastic tensors' without a concise definition or pointer to the formal definition in the main text, which reduces immediate accessibility for readers unfamiliar with the term.
- [§5] Table captions and axis labels in the experimental figures would benefit from explicit mention of the number of runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that directly strengthen the manuscript's claims regarding the diffusion-based assignment mechanism.
read point-by-point responses
-
Referee: [§3 (Diffusion Model)] The central claim that a continuous diffusion process over polystochastic tensors, regularized only by differentiable Sinkhorn projections at each denoising step, reliably recovers discrete person-to-person assignments from 2D priors is load-bearing for the entire contribution. However, the manuscript reports neither per-step assignment accuracy nor permutation error metrics that would confirm the forward noise process and learned reverse process preserve the marginal constraints required for Sinkhorn to produce valid permutation-like matrices.
Authors: We agree that explicit per-step metrics on assignment accuracy and permutation error would provide stronger evidence that the diffusion process maintains the required marginal constraints. In the revised manuscript we will add these analyses, including quantitative tracking of assignment validity and permutation error at each denoising step on both standard and surgical datasets. revision: yes
-
Referee: [§5 (Experiments and Ablations)] No ablation is presented that removes the diffusion component while retaining the Sinkhorn projection and Hypergraph-Convolutional Decoder. This omission leaves open the possibility that reported gains derive primarily from the downstream decoder or 2D priors rather than the claimed generative assignment model, directly affecting the interpretation of the label-efficiency and outperformance results.
Authors: We acknowledge that an ablation isolating the diffusion component is necessary to substantiate the contribution of the generative assignment model. In the revision we will include such an ablation by comparing the full DisPOSE pipeline against a non-diffusive baseline that retains the Sinkhorn projections and Hypergraph-Convolutional Decoder but replaces the diffusion process with direct optimization from the 2D priors; this will clarify the source of the observed label efficiency and performance gains. revision: yes
Circularity Check
No circularity: derivation chain not reducible to inputs
full rationale
The manuscript abstract and description introduce a diffusion process over polystochastic tensors regularized by Sinkhorn projections, followed by a Hypergraph-Convolutional Decoder, but supply no equations, self-citations, or fitted-parameter renamings that would allow any claimed prediction to reduce to its own inputs by construction. No self-definitional loops, fitted-input predictions, or load-bearing self-citations are present in the visible text. The approach is therefore treated as self-contained against external benchmarks; the absence of explicit derivations precludes identification of any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Avogaro, A., Cunico, F., Rosenhahn, B., and Setti, F
Springer, 2017. Avogaro, A., Cunico, F., Rosenhahn, B., and Setti, F. Mark- erless human pose estimation for biomedical applications: a survey.Frontiers in Computer Science, 5:1153160, 2023. Bai, S., Zhang, F., and Torr, P. H. S. Hypergraph convolu- tion and hypergraph attention.Pattern Recognition, 110: 107637, 2021. ISSN 0031-3203. Bastian, L., Wang, T....
-
[2]
IEEE, 2024. Lin, J. and Lee, G. H. Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11881–11890. IEEE, 2021. Lin, T., Ho, N., Cuturi, M., and Jordan, M. I. On the com- plexity of approximating multimarginal optimal trans- port.Journal of Machine Learning R...
2024
-
[3]
ACM, 2025. Lou, A. and Ermon, S. Reflected diffusion models. In International Conference on Machine Learning, 2023. Mena, G., Belanger, D., Linderman, S., and Snoek, J. Learn- ing latent permutations with gumbel-sinkhorn networks. InInternational Conference on Learning Representations, 2018. Moon, G., Chang, J. Y ., and Lee, K. M. V2v-posenet: V oxel-to-v...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
As defined in Eq
Coordinate Loss (Lcoord): we minimize the weighted L1 distance between the projected points and the 2D detections. As defined in Eq. (16) in the main paper, we weight this loss by the 2D detector’s confidence scoressv,k,j , ensuring the model focuses on clearly visible keypoints while ignoring low-confidence noise:
-
[5]
Heatmap Loss (Lhm): to allow the model to recover occluded joints without penalty, we employ an asymmetric loss on the heatmaps. Let Hpseudo be the Gaussian heatmap (Iskakov et al., 2019) generated from the 2D pseudo labels and H(τ) pred 14 DisPOSE: Projected Polystochastic Diffusion for Self-Supervised Multi-View 3D Human Pose Estimation be the heatmap r...
2019
-
[6]
While Ppseudo is noisy, it represents the geometric consensus of the multi-view system
3D Anchor Regularization (Lanchor):we supervise the predicted 3D poses against the triangulated weak-labels Ppseudo. While Ppseudo is noisy, it represents the geometric consensus of the multi-view system. We minimize ∥P (τ) − Ppseudo∥1 as a regularizer that anchors the network to the global coordinate system, preventing it from drifting into geometrically...
-
[7]
We apply random affine transformations to the input views and penalize discrepancies between the canonical pose predictions via anℓ 1 loss
Cross-Affine Consistency (Laffine):Following (Srivastav et al., 2024), we enforce that the predicted 3D geometry is invariant to camera frame perturbations. We apply random affine transformations to the input views and penalize discrepancies between the canonical pose predictions via anℓ 1 loss
2024
-
[8]
Triangulation Residual Loss ( Ltr):To enforce strict geometric validity of the predicted 2D offset positions, we minimize the smallest singular value of the triangulation constraint matrix, as proposed by (Zhao et al., 2023): L(τ) tr =σ min (M(ppred))2 .(18) where M(ppred) is the measurement matrix constructed from the predicted 2D positions ppred and cam...
2023
-
[9]
Wu et al. †
refines features across views. Next, we predict 2D corrections and confidence scores for each projected joint using MLPs applied to the updated node features and perform differentiable algebraic triangulation (Iskakov et al., 2019) to obtain updated 3D coordinates. Finally, a person-part hypergraph convolution aggregates information across skeletal joints...
2019
-
[10]
CMU0 w/ 2 extra
to better align with camera setups that use fewer cameras. Table 9.Definition of camera setups used in our ablation studies. We list the specific Camera IDs and the total number of views for each configuration on the CMU Panoptic dataset. Setup Name Camera IDs # Views CMU0 3, 6, 12, 13, 23 5 CMU0 w/ 2 extra 3, 6, 12, 13, 23, 10, 16 7 CMU0(K) FirstKcameras...
2022
-
[11]
proposes a transformer-decoder that iteratively refines 3D human poses from multi-view 2D features by projecting learnable 3D pose queries into each view. (Liao et al., 2024) builds upon this transformer-decoder architecture to improve generalization to unseen camera setups, by iteratively refining 2D offsets and triangulating 3D poses. (Chharia et al., 2...
2024
-
[12]
and 3D pose estimation (Zeng et al., 2021; Zou & Tang, 2021; Yu et al., 2023). However, extending these structures to multi-view multi-human settings presents a significant challenge, as the graph must expand to encompass not only intra-view body structures but also the explosive relation space of inter-view associations. To address this, (Wu et al., 2021...
2021
-
[13]
demonstrates instability with denser setups, with pose mAP dropping from 86.59% (4 views) to 78.77% (6 views). 21 DisPOSE: Projected Polystochastic Diffusion for Self-Supervised Multi-View 3D Human Pose Estimation Our proposed method effectively aggregates additional geometric evidence, achieving a peak pose mAP of 95.65% across 7 views. Table 10.Ablation...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.