Sparse Subspace-to-Expert Sharing for Task-Agnostic Continual Learning
Pith reviewed 2026-06-27 22:13 UTC · model grok-4.3
The pith
SETA decomposes LLM parameters into sparse task-specific and shared experts to support continual learning without catastrophic forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
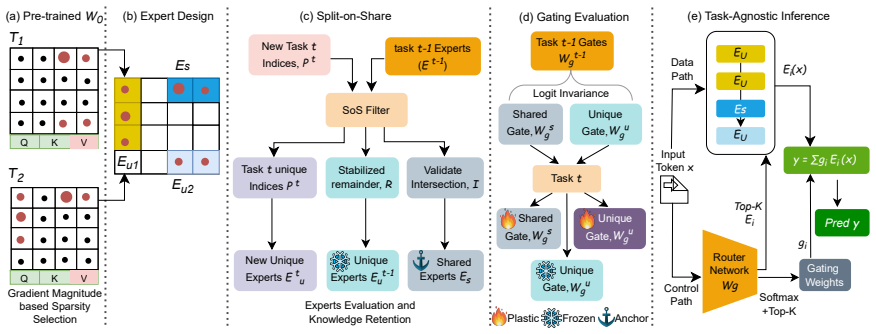
SETA resolves the plasticity-stability conflict through adaptive sparse subspace decomposition into task-specific expert modules that isolate unique patterns and shared experts that capture common features; this structure is preserved by adaptive elastic anchoring and routing-aware regularization that jointly protect shared knowledge at the weight and routing levels, allowing a unified gating network to retrieve the correct expert combination automatically during inference.
What carries the argument
Adaptive sparse subspace decomposition that creates task-specific expert modules and shared experts, protected by elastic anchoring and routing-aware regularization, with a unified gating network for inference-time retrieval.
If this is right
- Tasks no longer compete for the same parameters, reducing interference during sequential updates.
- Early-task knowledge is retained more effectively than in uniform-parameter update methods.
- Backward transfer improves on models such as LLaMA-2 7B and Qwen3-4B.
- A single gating network suffices for expert selection, keeping inference task-agnostic.
- Overall performance remains competitive or superior across diverse domain-specific benchmarks.
Where Pith is reading between the lines
- The separation of shared and specific knowledge could lower the cost of long-term model maintenance by avoiding full retraining.
- If subspace isolation scales reliably, the same pattern might extend to other sequential adaptation settings beyond language models.
- Improved backward transfer suggests that protecting shared features can actively benefit prior tasks rather than merely avoiding harm.
- The approach implies that routing regularization at both weight and network levels may be necessary to maintain stability in expert-based continual systems.
Load-bearing premise
Adaptive sparse subspace decomposition can reliably isolate task-specific patterns from shared features without introducing new interference or requiring task-specific routing at inference time.
What would settle it
An experiment on the same benchmarks where SETA shows no improvement in early-task retention or backward transfer relative to standard fine-tuning or other continual learning baselines.
Figures


read the original abstract
Continual learning in Large Language Models (LLMs) is hindered by the plasticity-stability dilemma, where acquiring new capabilities often leads to catastrophic forgetting of previous knowledge. Existing methods typically treat parameters uniformly, failing to distinguish between specific task knowledge and shared capabilities. We introduce Mixture of Sparse Experts for Task Agnostic Continual Learning (SETA), a framework that resolves the plasticity-stability conflict through adaptive sparse subspace decomposition into task-specific expert modules. Unlike standard updates, where tasks compete for the same parameters, SETA separates knowledge into unique experts, designed to isolate task-specific patterns, and shared experts, responsible for capturing common features. This structure is maintained through adaptive elastic anchoring and a routing-aware regularization that jointly protect shared knowledge at both the weight and routing levels and enable a unified gating network to automatically retrieve the correct expert combination during inference. Extensive experiments across diverse domain-specific benchmarks demonstrate that SETA achieves competitive or superior overall performance relative to state-of-the-art continual learning baselines, with particularly strong retention of early-task knowledge and improved backward transfer on LLaMA-2 7B and Qwen3-4B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SETA (Mixture of Sparse Experts for Task Agnostic Continual Learning), which performs adaptive sparse subspace decomposition of LLM parameters into task-specific experts and shared experts. These are maintained via elastic anchoring and routing-aware regularization so that a single unified gating network can retrieve the appropriate combination at inference without task identity. Experiments on LLaMA-2 7B and Qwen3-4B across domain-specific benchmarks are reported to yield competitive or superior average performance, with notably stronger retention of early-task knowledge and improved backward transfer relative to existing continual-learning baselines.
Significance. If the claimed separation of subspaces can be shown to occur without residual interference at the scale of 7B–4B models, the method would offer a concrete architectural route to the plasticity-stability trade-off that does not require task-specific routing at test time. This would be a meaningful empirical contribution to continual learning for LLMs.
major comments (2)
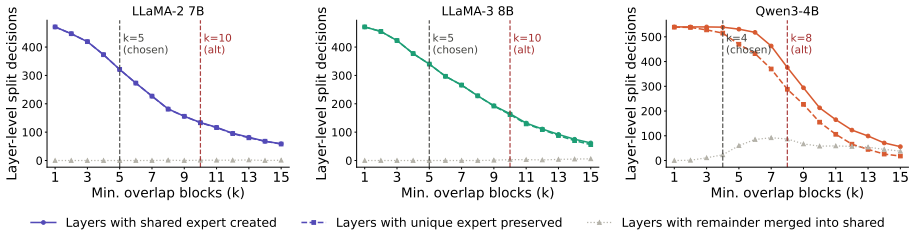
- [Experiments / §4 (or equivalent results section)] The headline performance claim (competitive/superior results plus strong early-task retention and backward transfer) is load-bearing on the assumption that adaptive sparse subspace decomposition plus elastic anchoring cleanly isolates task-specific experts from shared ones. The manuscript supplies no quantitative diagnostics—such as expert activation histograms, subspace overlap metrics, or interference measurements—demonstrating that this separation succeeds in the high-dimensional regime of LLaMA-2 7B / Qwen3-4B. Without such evidence the reported backward-transfer gains cannot be attributed to the claimed mechanism rather than to other factors.
- [Abstract and Experiments section] The abstract states that SETA “achieves competitive or superior overall performance” and “improved backward transfer,” yet the provided text contains no tables, ablation results, or statistical tests that would allow verification that baselines were matched in compute, that gains survive different random seeds, or that the unified gating network indeed operates without task-specific routing at inference.
minor comments (2)
- [Method section] Notation for the gating network and the elastic-anchoring loss should be introduced with explicit equations rather than descriptive prose only.
- [Experiments section] The paper should clarify whether the reported numbers are means over multiple runs and include standard deviations or confidence intervals.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on the empirical validation of SETA. We provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experiments / §4 (or equivalent results section)] The headline performance claim (competitive/superior results plus strong early-task retention and backward transfer) is load-bearing on the assumption that adaptive sparse subspace decomposition plus elastic anchoring cleanly isolates task-specific experts from shared ones. The manuscript supplies no quantitative diagnostics—such as expert activation histograms, subspace overlap metrics, or interference measurements—demonstrating that this separation succeeds in the high-dimensional regime of LLaMA-2 7B / Qwen3-4B. Without such evidence the reported backward-transfer gains cannot be attributed to the claimed mechanism rather than to other factors.
Authors: We agree that additional quantitative diagnostics are necessary to rigorously support the attribution of performance gains to the subspace separation mechanism. In the revised manuscript, we will incorporate expert activation histograms showing task-specific vs. shared expert usage, subspace overlap metrics (such as average cosine similarity between task-specific parameter subspaces), and interference measurements (e.g., the effect on performance when experts are cross-activated). These will be presented in the experiments section to demonstrate successful isolation at the scale of the evaluated models and to strengthen the link to improved backward transfer. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that SETA “achieves competitive or superior overall performance” and “improved backward transfer,” yet the provided text contains no tables, ablation results, or statistical tests that would allow verification that baselines were matched in compute, that gains survive different random seeds, or that the unified gating network indeed operates without task-specific routing at inference.
Authors: We acknowledge the referee's point that the provided text lacks sufficient tables, ablations, and statistical tests. We will revise the experiments section to include detailed performance tables, ablation results on random seeds and compute matching, and statistical tests for the gains. We will also add explicit verification of the task-agnostic nature of the unified gating network at inference time. revision: yes
Circularity Check
No circularity: empirical architecture validated on external benchmarks
full rationale
The paper introduces SETA as a practical framework for task-agnostic continual learning via adaptive sparse subspace decomposition, elastic anchoring, and routing-aware regularization, then reports performance through experiments on LLaMA-2 7B and Qwen3-4B. No derivation chain, equations, or first-principles results are presented that reduce to fitted inputs or self-citations by construction. The central claims rest on benchmark comparisons rather than any self-referential mathematical reduction, making the work self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[3]
Neural networks , volume=
Continual lifelong learning with neural networks: A review , author=. Neural networks , volume=. 2019 , publisher=
2019
-
[4]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[5]
On Tiny Episodic Memories in Continual Learning
On tiny episodic memories in continual learning , author=. arXiv preprint arXiv:1902.10486 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[6]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[7]
Progressive neural networks , author=. arXiv preprint arXiv:1606.04671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Learning both weights and connections for efficient neural network , author=. Advances in neural information processing systems , volume=
-
[9]
International conference on machine learning , pages=
Rigging the lottery: Making all tickets winners , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[10]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Analyzing and reducing catastrophic forgetting in parameter efficient tuning , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[11]
arXiv preprint arXiv:2402.01364 , year=
Continual learning for large language models: A survey , author=. arXiv preprint arXiv:2402.01364 , year=
-
[12]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[13]
IEEE Transactions on Audio, Speech and Language Processing , year=
An empirical study of catastrophic forgetting in large language models during continual fine-tuning , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[14]
1980 , publisher=
The need for biases in learning generalizations , author=. 1980 , publisher=
1980
-
[15]
Advances in Neural Information Processing Systems , volume=
Gradient episodic memory for continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
International Conference on Artificial Intelligence and Statistics , pages=
Orthogonal Gradient Descent for Continual Learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[17]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[18]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[19]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[20]
Efficient Lifelong Learning with A-GEM
Efficient lifelong learning with a-gem , author=. arXiv preprint arXiv:1812.00420 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning to prompt for continual learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
arXiv preprint arXiv:2301.12314 , year=
Progressive prompts: Continual learning for language models , author=. arXiv preprint arXiv:2301.12314 , year=
-
[23]
IEEE transactions on pattern analysis and machine intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[24]
Prefix-tuning: Optimizing continuous prompts for generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[25]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
1989
-
[26]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
icarl: Incremental classifier and representation learning , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of EMNLP , year=
Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning , author=. Proceedings of EMNLP , year=
-
[28]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Orthogonal subspace learning for language model continual learning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[29]
Slim: Let llm learn more and forget less with soft lora and identity mixture , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[30]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[31]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[32]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[33]
International Conference on Learning Representations , volume=
Relora: High-rank training through low-rank updates , author=. International Conference on Learning Representations , volume=
-
[34]
arXiv preprint arXiv:2406.15734 , year=
Rankadaptor: Hierarchical dynamic low-rank adaptation for structural pruned llms , author=. arXiv preprint arXiv:2406.15734 , year=
-
[35]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Adazeta: Adaptive zeroth-order tensor-train adaption for memory-efficient large language models fine-tuning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[36]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Adaptive rank selections for low-rank approximation of language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[37]
arXiv preprint arXiv:2404.15159 , year=
Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts , author=. arXiv preprint arXiv:2404.15159 , year=
-
[38]
International Conference on Learning Representations , volume=
Mixture of lora experts , author=. International Conference on Learning Representations , volume=
-
[39]
arXiv preprint arXiv:2405.00361 , year=
Adamole: Fine-tuning large language models with adaptive mixture of low-rank adaptation experts , author=. arXiv preprint arXiv:2405.00361 , year=
-
[40]
arXiv preprint arXiv:2501.16372 , year=
Low-rank adapters meet neural architecture search for llm compression , author=. arXiv preprint arXiv:2501.16372 , year=
-
[41]
International Conference on Learning Representations , volume=
Smt: Fine-tuning large language models with sparse matrices , author=. International Conference on Learning Representations , volume=
-
[42]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[44]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[45]
International Conference on Machine Learning , pages=
Base layers: Simplifying training of large, sparse models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[46]
advances in neural information processing systems , volume=
Hash layers for large sparse models , author=. advances in neural information processing systems , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
Mixture-of-experts with expert choice routing , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Advances in neural information processing systems , volume=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. Advances in neural information processing systems , volume=
-
[49]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Trillion dollar words: A new financial dataset, task & market analysis , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Meetingbank: A benchmark dataset for meeting summarization , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
C-STANCE: A large dataset for Chinese zero-shot stance detection , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
Proceedings of the 8th edition of the Swiss Text Analytics Conference , pages=
20 Minuten: A Multi-task News Summarisation Dataset for German , author=. Proceedings of the 8th edition of the Swiss Text Analytics Conference , pages=
-
[53]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
NumGLUE: A suite of fundamental yet challenging mathematical reasoning tasks , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.