Enabling KV Caching of Shared Prefix for Diffusion Language Models
Pith reviewed 2026-07-04 00:57 UTC · model grok-4.3
The pith
Diffusion language models can reuse shared-prefix KV states in shallow layers to raise serving throughput by 36-98 percent with negligible accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
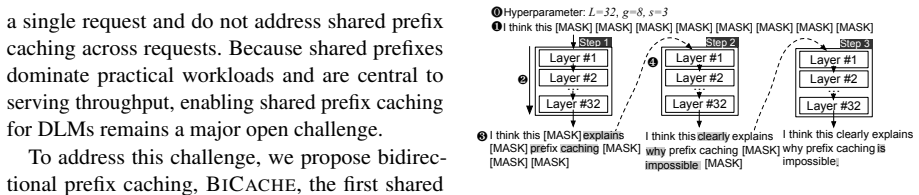
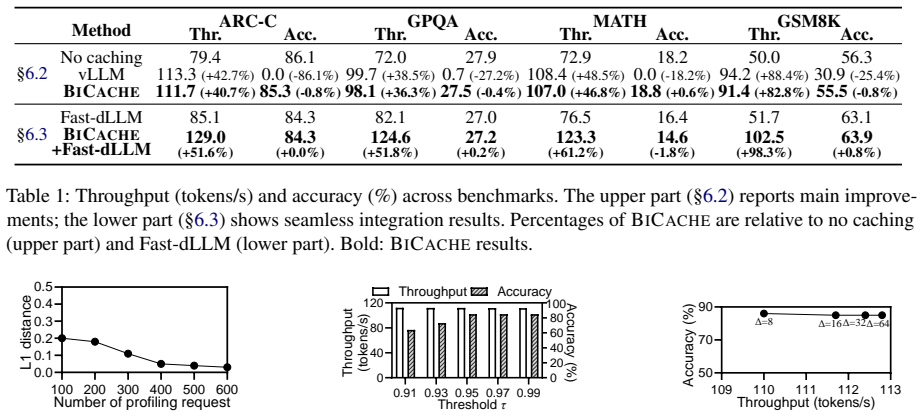
The central claim is that shared prefix KVs in diffusion language models remain stable and reusable in shallow layers, with the safe depth depending on the fraction of shared prefix tokens in each request. Bicache dynamically identifies this cutoff layer and eliminates redundant computation for the shared prefix up to that depth. When evaluated, the method delivers 36.3%-98.3% higher serving throughput than existing techniques while keeping accuracy loss between 0 and 1.8 percent.
What carries the argument
Bidirectional prefix caching (bicache), a dynamic cutoff that selects the safe layer depth for KV reuse based on the shared-prefix token fraction.
If this is right
- DLM serving achieves 36.3%-98.3% higher throughput than uncached or naively cached baselines.
- Accuracy stays within 0-1.8% of the uncached model across tested workloads.
- Existing LLM caching methods cannot be applied directly because bidirectional attention alters all KVs on any update.
- The safe reuse depth varies with the shared prefix length fraction in each request.
Where Pith is reading between the lines
- The same shallow-layer stability pattern may hold in other non-autoregressive or bidirectional architectures, opening similar caching opportunities.
- Runtime systems could track prefix fractions per request to set the cutoff without manual tuning.
- If the stability property scales with model size, bicache could be applied to larger diffusion models without additional training.
Load-bearing premise
Shared prefix key-value states remain stable enough to reuse without corrupting later computations in the shallow layers of the diffusion model.
What would settle it
Force bicache to reuse KV states past its dynamically chosen cutoff layer on a set of requests and check whether accuracy falls more than 1.8 percent below the uncached baseline.
Figures





read the original abstract
Key-value (KV) caching for shared prefixes is essential for high-throughput large language model (LLM) serving, but it faces critical challenges in emerging diffusion language models (DLMs). In DLMs, bidirectional attention means that updating any token dynamically alters the entire context and its corresponding KVs. Thus, existing caching techniques developed for LLMs, which assume that KVs remain invariant once computed, corrupt the shared prefix KVs. Our experiments show that applying these techniques to DLMs causes model accuracy to collapse to near zero. To unlock high-throughput DLM serving, we propose bidirectional prefix caching, bicache, the first KV caching technique for shared prefixes in DLMs. bicache is designed based on key observations from our comprehensive analysis: shared prefix KVs remain stable and reusable in shallow layers, while the depth of shallow layers depends on the fraction of shared prefix tokens in each request. Thus, bicache dynamically identifies a safe layer depth for reusing shared prefix KVs and eliminates redundant computation. Evaluations demonstrate that bicache significantly improves serving throughput by 36.3%-98.3% compared to existing techniques without accuracy collapse (only 0-1.8% difference).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard KV caching for shared prefixes fails in diffusion language models (DLMs) because bidirectional attention causes any token update to alter all KVs, collapsing accuracy to near zero. It introduces bicache, which exploits the empirical observation that shared-prefix KVs remain stable and reusable only in shallow layers whose depth depends on the fraction of shared prefix tokens; bicache therefore dynamically selects a safe cutoff layer to reuse those KVs and avoid recomputation. Experiments are reported to show 36.3–98.3 % throughput gains versus existing techniques while limiting accuracy degradation to 0–1.8 %.
Significance. If the layer-wise stability observation and the dynamic cutoff rule prove reliable, bicache would remove a fundamental obstacle to high-throughput DLM serving. The work supplies concrete throughput and accuracy deltas, which is a positive attribute for an empirical systems paper.
major comments (3)
- [Abstract / Method description] The central claim that accuracy remains within 0–1.8 % rests on the dynamic cutoff rule whose exact mapping from prefix fraction to layer depth is never formalized (no equation, threshold, or pseudocode is supplied). Without this definition it is impossible to verify that the reported accuracy numbers are reproducible or that the rule generalizes beyond the evaluated requests.
- [Evaluation section] No ablation or quantitative measurement (e.g., per-layer cosine similarity of reused vs. recomputed KVs, or divergence vs. accuracy delta) is presented to support the claim that stability holds precisely up to the chosen cutoff and breaks beyond it. The 0–1.8 % accuracy window is therefore an unanchored empirical result rather than a validated consequence of the stability hypothesis.
- [Evaluation section] The experimental setup (models, datasets, request traces, exact baselines, and statistical significance of the 36.3–98.3 % throughput range) is referenced only by summary numbers in the abstract; the full manuscript does not supply sufficient detail for an independent reader to reproduce or stress-test the throughput and accuracy figures.
minor comments (1)
- [Abstract] Notation for the proposed method alternates between “bicache” and “BiCache”; adopt a single consistent capitalization throughout.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, add supporting measurements, and expand experimental details.
read point-by-point responses
-
Referee: [Abstract / Method description] The central claim that accuracy remains within 0–1.8 % rests on the dynamic cutoff rule whose exact mapping from prefix fraction to layer depth is never formalized (no equation, threshold, or pseudocode is supplied). Without this definition it is impossible to verify that the reported accuracy numbers are reproducible or that the rule generalizes beyond the evaluated requests.
Authors: We agree the dynamic cutoff rule is described qualitatively but lacks a formal specification. In the revised manuscript we will add an explicit equation defining the layer-depth cutoff as a function of the shared-prefix fraction, together with pseudocode for the selection procedure. This will make the rule reproducible and clarify its generalization properties. revision: yes
-
Referee: [Evaluation section] No ablation or quantitative measurement (e.g., per-layer cosine similarity of reused vs. recomputed KVs, or divergence vs. accuracy delta) is presented to support the claim that stability holds precisely up to the chosen cutoff and breaks beyond it. The 0–1.8 % accuracy window is therefore an unanchored empirical result rather than a validated consequence of the stability hypothesis.
Authors: The manuscript reports the outcome of a comprehensive layer-wise stability analysis, yet we acknowledge the absence of the requested quantitative ablations. We will add per-layer cosine-similarity plots of reused versus recomputed KVs and corresponding divergence-versus-accuracy curves in the revised Evaluation section to directly validate the cutoff choice. revision: yes
-
Referee: [Evaluation section] The experimental setup (models, datasets, request traces, exact baselines, and statistical significance of the 36.3–98.3 % throughput range) is referenced only by summary numbers in the abstract; the full manuscript does not supply sufficient detail for an independent reader to reproduce or stress-test the throughput and accuracy figures.
Authors: We agree that additional detail is required for full reproducibility. The revised manuscript will expand the Evaluation section with explicit model configurations, dataset and trace specifications, baseline implementations, and the statistical procedures used to obtain the reported throughput range. revision: yes
Circularity Check
No circularity; bicache rests on empirical KV stability observations, not self-referential derivations
full rationale
The paper presents bicache as an engineering technique motivated by direct experimental observations that shared prefix KVs are stable in shallow layers (with cutoff depth scaling by prefix fraction). No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claim to its own inputs by construction. The throughput and accuracy results are framed as outcomes of implementation and measurement rather than tautological re-derivations, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shared prefix KVs remain stable and reusable in shallow layers of DLMs, with safe depth depending on the fraction of shared prefix tokens.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Beyond Next-Token Prediction: A Performance Characterization of Diffusion versus Autoregressive Language Models , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
TurboSpec: Closed-loop Speculation Control System for Optimizing LLM Serving Goodput , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference , author=. 2025 , eprint=
2025
-
[4]
2024 , howpublished =
Yann Collet , title =. 2024 , howpublished =
2024
-
[5]
2025 , eprint=
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
2025
-
[6]
2026 , eprint=
d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation , author=. 2026 , eprint=
2026
-
[7]
How smooth is attention? , year =
Castin, Val\'. How smooth is attention? , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[8]
Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =
Meng, Yu and Huang, Jiaxin and Wang, Guangyuan and Zhang, Chao and Zhuang, Honglei and Kaplan, Lance and Han, Jiawei , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , publisher =
2019
-
[9]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Birth of a Transformer: A Memory Viewpoint , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[10]
On the Robustness of Self-Attentive Models
Hsieh, Yu-Lun and Cheng, Minhao and Juan, Da-Cheng and Wei, Wei and Hsu, Wen-Lian and Hsieh, Cho-Jui. On the Robustness of Self-Attentive Models. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1147
-
[11]
Mattson, R. L. and Gecsei, J. and Slutz, D. R. and Traiger, I. L. , title =. IBM Syst. J. , month = jun, pages =. 1970 , issue_date =. doi:10.1147/sj.92.0078 , abstract =
-
[12]
2021 , eprint=
The Lipschitz Constant of Self-Attention , author=. 2021 , eprint=
2021
-
[13]
2020 , editor =
Karimireddy, Sai Praneeth and Kale, Satyen and Mohri, Mehryar and Reddi, Sashank and Stich, Sebastian and Suresh, Ananda Theertha , booktitle =. 2020 , editor =
2020
-
[14]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
Wonbeom Lee and Jungi Lee and Junghwan Seo and Jaewoong Sim , title =. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
-
[15]
Salton, G. and Wong, A. and Yang, C. S. , title =. Commun. ACM , month = nov, pages =. 1975 , issue_date =. doi:10.1145/361219.361220 , abstract =
-
[16]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
R elay A ttention for Efficient Large Language Model Serving with Long System Prompts
Zhu, Lei and Wang, Xinjiang and Zhang, Wayne and Lau, Rynson. R elay A ttention for Efficient Large Language Model Serving with Long System Prompts. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.270
-
[18]
First Conference on Language Modeling , year=
Measuring and Controlling Instruction (In)Stability in Language Model Dialogs , author=. First Conference on Language Modeling , year=
-
[19]
Yi, Zihao and Ouyang, Jiarui and Xu, Zhe and Liu, Yuwen and Liao, Tianhao and Luo, Haohao and Shen, Ying , title =. ACM Comput. Surv. , month = dec, articleno =. 2025 , issue_date =. doi:10.1145/3771090 , abstract =
-
[20]
2024 , eprint=
Prompt Cache: Modular Attention Reuse for Low-Latency Inference , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
2024
-
[22]
2024 , eprint=
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset , author=. 2024 , eprint=
2024
-
[23]
Marimuthu, Sushvin and Krishnamurthy, Parameswari. LTRC - IIITH at P er A ns S umm 2025: S pan S ense - Perspective-specific span identification and Summarization. Proceedings of the Second Workshop on Patient-Oriented Language Processing (CL4Health). 2025. doi:10.18653/v1/2025.cl4health-1.37
-
[24]
2025 , eprint=
Reinforcement Learning is all You Need , author=. 2025 , eprint=
2025
-
[25]
xai-org/grok-prompts: Prompts for the Grok chat assistant and the @grok bot on X , year =
-
[26]
Rethinking the Reversal Curse of LLM s: a Prescription from Human Knowledge Reversal
Lu, Zhicong and Jin, Li and Li, Peiguang and Tian, Yu and Zhang, Linhao and Wang, Sirui and Xu, Guangluan and Tian, Changyuan and Cai, Xunliang. Rethinking the Reversal Curse of LLM s: a Prescription from Human Knowledge Reversal. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.428
-
[27]
The Reversal Curse: LLMs trained on A is B fail to learn B is A , url =
Berglund, Lukas and Tong, Meg and Kaufmann, Maximilian and Balesni, Mikita and Stickland, Asa and Korbak, Tomek and Evans, Owain , booktitle =. The Reversal Curse: LLMs trained on A is B fail to learn B is A , url =
-
[28]
Xia, Heming and Yang, Zhe and Dong, Qingxiu and Wang, Peiyi and Li, Yongqi and Ge, Tao and Liu, Tianyu and Li, Wenjie and Sui, Zhifang. Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.456
-
[29]
2025 , eprint=
d ^2 Cache: Accelerating Diffusion-Based LLMs via Dual Adaptive Caching , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Esoteric Language Models , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
FlashDLM: Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Fast-dLLM v2: Efficient Block-Diffusion LLM , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author=. 2025 , eprint=
2025
-
[36]
Preble: Efficient Distributed Prompt Scheduling for
Vikranth Srivatsa and Zijian He and Reyna Abhyankar and Dongming Li and Yiying Zhang , booktitle=. Preble: Efficient Distributed Prompt Scheduling for. 2025 , url=
2025
-
[37]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[38]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[39]
L ong W eave: A Long-Form Generation Benchmark Bridging Real-World Relevance and Verifiability
Xiao, Zikai and Huang, Fei and Tu, Jianhong and Wei, Jianhui and Ma, Wen and Zhou, Yuxuan and Wu, Jian and Yu, Bowen and Liu, Zuozhu and Lin, Junyang. L ong W eave: A Long-Form Generation Benchmark Bridging Real-World Relevance and Verifiability. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.549
-
[40]
2023 , howpublished =
ChatGPT:. 2023 , howpublished =
2023
-
[41]
WildChat: 1M Chat
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , booktitle=. WildChat: 1M Chat. 2024 , url=
2024
-
[42]
PyTorch: an imperative style, high-performance deep learning library , year =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and K\". PyTorch: an imperative style, high-performance deep learning library , year =. Proceedings of the 33rd International Conference on Neural Informa...
-
[43]
2024 , eprint=
Lessons from the Trenches on Reproducible Evaluation of Language Models , author=. 2024 , eprint=
2024
-
[44]
Reward-Weighted Sampling: Enhancing Non-Autoregressive Characteristics in Masked Diffusion LLM s
Gwak, Daehoon and Jung, Minseo and Park, Junwoo and Park, Minho and Park, ChaeHun and Hyung, Junha and Choo, Jaegul. Reward-Weighted Sampling: Enhancing Non-Autoregressive Characteristics in Masked Diffusion LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1754
-
[45]
2026 , eprint=
CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.