UNIQ: Conformal Calibration for Adaptive Conservatism in Offline Reinforcement Learning
Pith reviewed 2026-06-29 08:37 UTC · model grok-4.3
The pith
UNIQ maps conformal uncertainty to state-dependent expectiles, adapting conservatism in offline RL instead of applying a fixed penalty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
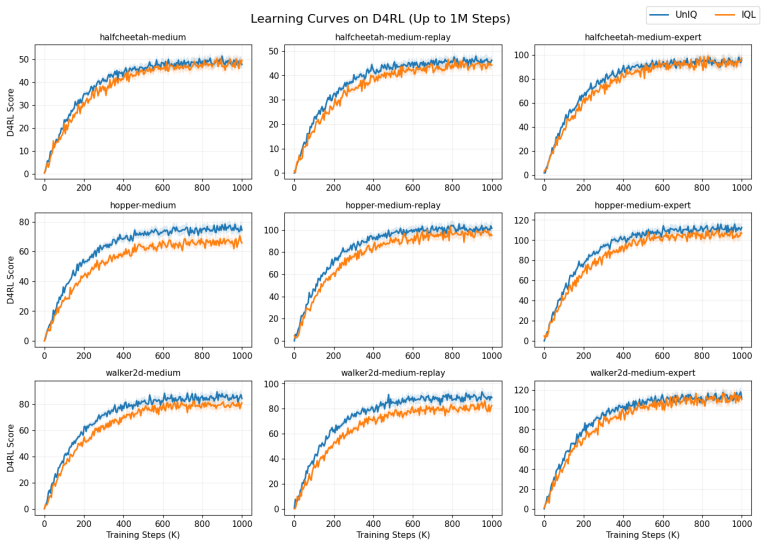
UNIQ trains a multi-expectile value ensemble on the IQL backbone, computes distribution-free uncertainty estimates via split conformal prediction, and maps the uncertainty signal to a state-dependent expectile that relaxes conservatism in well-covered regions while strengthening it in uncertain regions near the data frontier, producing consistent improvements over IQL on D4RL MuJoCo benchmarks with largest gains on Walker2d and replay-heavy tasks while operating at near-IQL memory cost.
What carries the argument
The mapping from conformally calibrated uncertainty signal to state-dependent expectile level, which modulates conservatism according to local data coverage.
If this is right
- Performance gains are largest on tasks whose data coverage varies across states, such as Walker2d and replay-heavy datasets.
- Memory footprint stays comparable to IQL at approximately 250 MB peak VRAM, offering a large reduction relative to full ensemble baselines like EDAC.
- The method supplies a practical add-on to existing value-based offline RL algorithms rather than requiring an entirely new architecture.
- Conservatism becomes stronger only where the uncertainty signal indicates poor coverage, avoiding blanket penalties across all states.
Where Pith is reading between the lines
- The same conformal-to-expectile mapping could be attached to other offline RL backbones that already maintain value ensembles, testing whether the efficiency benefit generalizes.
- The uncertainty signal itself could be monitored at deployment time to flag states where the learned policy should be treated as higher risk.
- If the mapping rule is made differentiable, the uncertainty estimates might be used inside the training loop rather than only at inference time.
Load-bearing premise
The mapping from the conformal uncertainty signal to the state-dependent expectile level preserves the validity properties of conformal prediction and does not introduce new bias into the value estimates.
What would settle it
Run the same D4RL tasks but replace the conformal uncertainty signal with random noise or a constant before the expectile mapping; if the performance gains over IQL disappear, the adaptive benefit is falsified.
Figures

read the original abstract
Offline reinforcement learning requires careful conservatism to mitigate distribution shift, yet most existing methods apply a fixed penalty uniformly across all states regardless of local data coverage. We present UNIQ (Uncertainty-Informed Quantile), an offline RL method that introduces state-adaptive conservatism through conformally calibrated uncertainty estimation. Built on the Implicit Q-Learning (IQL) backbone, UNIQ trains a multi-expectile value ensemble, computes distribution-free uncertainty estimates using split conformal prediction, and maps the resulting signal to a state-dependent expectile that relaxes conservatism in well-covered regions while strengthening it in uncertain regions near the data frontier. On D4RL MuJoCo benchmarks, UNIQ consistently improves over IQL, with the largest gains observed on Walker2d and replay-heavy tasks. At the same time, UNIQ operates at near-IQL memory cost (approximately 250 MB peak VRAM), providing roughly a 10x reduction compared to EDAC. Rather than pursuing overall state-of-the-art performance, we position UNIQ as a practical mechanism contribution that improves the performance-efficiency trade-off in offline reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UNIQ, an offline RL algorithm extending Implicit Q-Learning (IQL) by training a multi-expectile value ensemble, applying split conformal prediction to obtain distribution-free uncertainty estimates, and mapping these to a state-dependent expectile level τ(s) that adaptively relaxes conservatism in well-covered regions and strengthens it near the data frontier. It reports consistent improvements over IQL on D4RL MuJoCo benchmarks (largest on Walker2d and replay-heavy tasks) at near-IQL memory cost (~250 MB peak VRAM, ~10× lower than EDAC).
Significance. If the central mapping from conformal scores to state-dependent expectiles can be shown to preserve validity properties while delivering the reported gains, the work would provide a practical, low-memory mechanism for state-adaptive conservatism in offline RL. The emphasis on the performance-efficiency trade-off rather than raw SOTA is a constructive positioning.
major comments (3)
- [Method (uncertainty-to-expectile mapping)] The method section describing the uncertainty-to-expectile mapping (the step that converts the split-conformal score into τ(s) for use inside IQL expectile regression) supplies no argument or derivation showing that the resulting value targets retain the marginal coverage guarantee of the original conformal procedure. Split conformal prediction guarantees coverage only for the raw prediction sets; feeding a transformed, state-dependent τ(s) back into the Bellman target risks breaking this property or introducing bias, which directly underpins the abstract claim that the method “relaxes conservatism in well-covered regions while strengthening it in uncertain regions.”
- [Experiments (ablation studies)] No ablation is presented that isolates the contribution of the conformal calibration step itself (e.g., comparing the full UNIQ pipeline against an otherwise identical multi-expectile IQL baseline that uses a fixed or heuristically chosen τ). Without this, it is impossible to determine whether the reported gains on Walker2d and replay-heavy tasks stem from the conformal mechanism or from other implementation choices.
- [Experiments (D4RL results)] The empirical results section reports performance numbers and memory figures but does not include verification that the learned τ(s) mapping actually produces the intended coverage behavior (e.g., empirical coverage rates of the resulting value estimates or sensitivity analysis under distribution shift). This leaves the weakest assumption—that the mapping preserves validity and does not re-introduce bias—untested.
minor comments (2)
- [Notation] Notation for the state-dependent expectile level is rendered inconsistently (sometimes τ(s), sometimes au(s) in the provided text); a single symbol should be used throughout.
- [Abstract / Experiments] The abstract states “approximately 250 MB peak VRAM” and “roughly a 10x reduction compared to EDAC”; these figures should be accompanied by the exact measurement protocol and hardware details in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Method (uncertainty-to-expectile mapping)] The method section describing the uncertainty-to-expectile mapping (the step that converts the split-conformal score into τ(s) for use inside IQL expectile regression) supplies no argument or derivation showing that the resulting value targets retain the marginal coverage guarantee of the original conformal procedure. Split conformal prediction guarantees coverage only for the raw prediction sets; feeding a transformed, state-dependent τ(s) back into the Bellman target risks breaking this property or introducing bias, which directly underpins the abstract claim that the method “relaxes conservatism in well-covered regions while strengthening it in uncertain regions.”
Authors: We agree that the manuscript provides no formal derivation establishing that the marginal coverage guarantee is retained after mapping the conformal scores to a state-dependent τ(s) and feeding the result into the IQL expectile regression. The split conformal procedure yields distribution-free uncertainty estimates on the ensemble predictions; the subsequent mapping to τ(s) is a heuristic that uses these estimates to modulate conservatism. Because the mapping is state-dependent and the output is used as a regression target, the coverage property does not automatically transfer. In revision we will add an explicit discussion in the method section stating this limitation, clarifying that the adaptive mechanism is motivated by the empirical correlation between uncertainty and data coverage rather than by a preserved theoretical guarantee, and noting the distinction between coverage of the raw conformal sets and coverage of the final value estimates. revision: yes
-
Referee: [Experiments (ablation studies)] No ablation is presented that isolates the contribution of the conformal calibration step itself (e.g., comparing the full UNIQ pipeline against an otherwise identical multi-expectile IQL baseline that uses a fixed or heuristically chosen τ). Without this, it is impossible to determine whether the reported gains on Walker2d and replay-heavy tasks stem from the conformal mechanism or from other implementation choices.
Authors: The manuscript does not contain an ablation that isolates the conformal calibration step by comparing UNIQ against an otherwise identical multi-expectile IQL variant that uses a fixed τ. We will add this ablation to the experiments section in the revision, reporting results on the same D4RL MuJoCo tasks to quantify the incremental benefit attributable to the conformal mapping. revision: yes
-
Referee: [Experiments (D4RL results)] The empirical results section reports performance numbers and memory figures but does not include verification that the learned τ(s) mapping actually produces the intended coverage behavior (e.g., empirical coverage rates of the resulting value estimates or sensitivity analysis under distribution shift). This leaves the weakest assumption—that the mapping preserves validity and does not re-introduce bias—untested.
Authors: The current experiments section does not report empirical coverage rates of the conformal sets or sensitivity analyses of τ(s) under distribution shift. We will add these verifications to the revised experiments, including empirical coverage statistics on held-out transitions and a sensitivity plot of performance versus distribution-shift severity. revision: yes
Circularity Check
No circularity: derivation is procedural and self-contained
full rationale
The paper presents UNIQ as a procedural extension of IQL that adds a multi-expectile ensemble, applies split conformal prediction for uncertainty, and defines a mapping from that signal to a state-dependent expectile level. No equations or self-citations are supplied that reduce the claimed benchmark gains or the adaptive conservatism to a fitted hyperparameter or prior result by construction. The conformal step is an off-the-shelf statistical procedure whose marginal coverage properties are independent of the downstream RL targets, and the mapping itself is described as an explicit design choice rather than a derived necessity that loops back to the inputs. The derivation chain therefore contains no self-definitional, fitted-input, or self-citation reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
IEEE Transactions on Neural Networks and Learning Systems , year=
A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[3]
Proceedings of the 36th International Conference on Machine Learning , volume=
Off-Policy Deep Reinforcement Learning without Exploration , author=. Proceedings of the 36th International Conference on Machine Learning , volume=. 2019 , publisher=
2019
-
[4]
Advances in Neural Information Processing Systems , volume=
Conservative Q-Learning for Offline Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[6]
Behavior Regularized Offline Reinforcement Learning
Behavior Regularized Offline Reinforcement Learning , author=. arXiv preprint arXiv:1911.11361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[7]
Advances in Neural Information Processing Systems , volume=
Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Revisiting the Minimalist Approach to Offline Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
A Minimalist Approach to Offline Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
2005 , isbn=
Algorithmic Learning in a Random World , author=. 2005 , isbn=
2005
-
[11]
Journal of the American Statistical Association , volume=
Distribution-Free Predictive Inference for Regression , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
-
[12]
Advances in Neural Information Processing Systems , volume=
Conformalized Quantile Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
European Conference on Machine Learning , pages=
Inductive Confidence Machines for Regression , author=. European Conference on Machine Learning , pages=. 2002 , publisher=
2002
-
[14]
Advances in Neural Information Processing Systems , volume=
COMBO: Conservative Offline Model-Based Policy Optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[16]
Advances in Neural Information Processing Systems , volume=
CORL: Research-oriented Deep Offline Reinforcement Learning Library , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Adaptive Conformal Inference Under Distribution Shift , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the 39th International Conference on Machine Learning , volume=
Adaptive Conformal Predictions for Time Series , author=. Proceedings of the 39th International Conference on Machine Learning , volume=. 2022 , publisher=
2022
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Conformal prediction under covariate shift , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[20]
International Conference on Learning Representations (ICLR) , year =
Conformal risk control , author =. International Conference on Learning Representations (ICLR) , year =
-
[21]
International Conference on Machine Learning (ICML) , pages =
Is pessimism provably efficient for offline RL? , author =. International Conference on Machine Learning (ICML) , pages =
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Bridging offline reinforcement learning and imitation learning: A tale of pessimism , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Bellman-consistent pessimism for offline reinforcement learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[24]
International Conference on Learning Representations (ICLR) , year =
Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Simple and scalable predictive uncertainty estimation using deep ensembles , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Can you trust your model's uncertainty? evaluating predictive uncertainty under dataset shift , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
MOPO: Model-based offline policy optimization , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
MOReL: Model-based offline reinforcement learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Why so pessimistic? Estimating uncertainties for offline RL through ensembles and score-based models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[30]
arXiv preprint arXiv:2105.08140 , year =
Uncertainty weighted actor-critic for offline reinforcement learning , author =. arXiv preprint arXiv:2105.08140 , year =
-
[31]
International Conference on Learning Representations (ICLR) , year =
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels , author =. International Conference on Learning Representations (ICLR) , year =
-
[32]
International Conference on Learning Representations (ICLR) , year =
TD-MPC2: Scalable, robust world models for continuous control , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
arXiv preprint arXiv:2402.08976 , year =
Confidence-aware offline reinforcement learning via conformal prediction , author =. arXiv preprint arXiv:2402.08976 , year =
-
[34]
International Conference on Learning Representations (ICLR) , year =
Adam: A method for stochastic optimization , author =. International Conference on Learning Representations (ICLR) , year =
-
[35]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Decision transformer: Reinforcement learning via sequence modeling , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.