MetaEvo: A Meta-Optimization Framework for Experience-Driven Agent Evolution
Pith reviewed 2026-06-28 23:34 UTC · model grok-4.3
The pith
MetaEvo applies preference optimization to strengthen how LLM agents abstract reusable principles from experience, then stores them for ongoing task improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
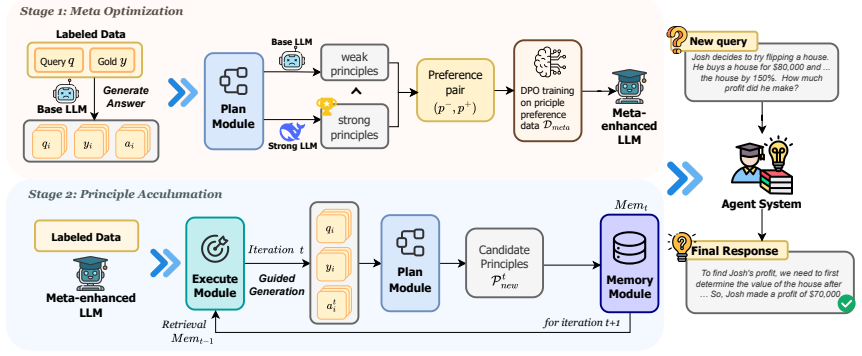
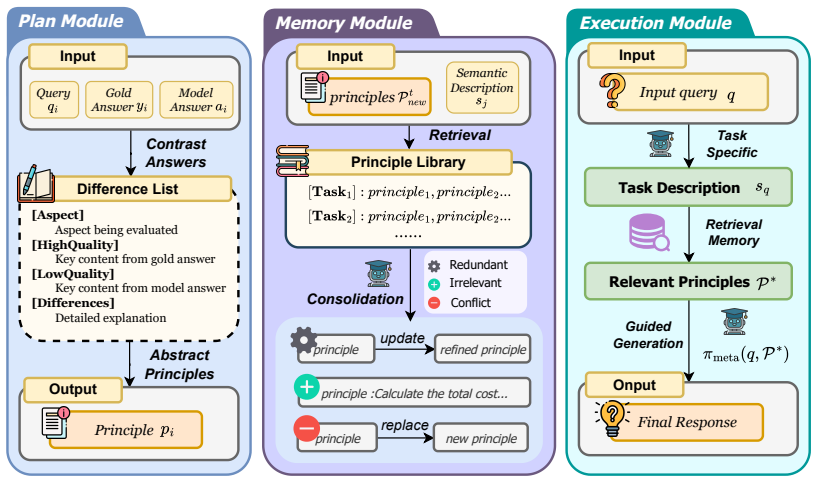
MetaEvo is a two-stage framework for continual agent evolution that first applies preference-based optimization to enhance the model's principle abstraction ability, then enables the accumulation and reuse of these principles within a modular agent architecture, producing consistent outperformance of baselines and reliable improvement across iterations on diverse reasoning benchmarks.
What carries the argument
Two-stage meta-optimization that first strengthens principle abstraction through preference optimization, then supports accumulation and modular reuse of the resulting principles.
Load-bearing premise
Preference-based optimization can improve the model's principle abstraction ability enough to produce sustained gains across iterations instead of early plateaus.
What would settle it
Experiments that run MetaEvo for many additional iterations on the same benchmarks and show performance stopping or falling back to baseline levels would falsify the claim of reliable continual improvement.
Figures



read the original abstract
Large language models (LLMs) exhibit strong reasoning capabilities, yet most LLM-based agents are statically deployed and unable to improve through task interactions. Existing experience-driven methods often rely on memory or heuristics without enhancing the model's ability to learn, treating it as a passive executor and leading to early performance plateaus and limited long-term improvement. To address this issue, we propose MetaEvo, a two-stage framework for continual agent evolution that focuses on improving how the model learns from tasks experience, rather than solely on what it stores. MetaEvo first applies preference-based optimization to enhance the model's ability of principle abstraction, then enables the accumulation and reuse of these principles within a modular agent architecture. Experimental results on diverse reasoning benchmarks demonstrate that MetaEvo consistently outperforms strong baselines, maintains reliable improvement across iterations. These findings validate the effectiveness of meta-optimization in enabling agents to learn from experience and continually enhance their reasoning capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MetaEvo, a two-stage framework for continual evolution of LLM-based agents. Stage one applies preference-based optimization to improve the model's principle abstraction ability from task experience; stage two accumulates and reuses the resulting principles inside a modular agent architecture. The central claim is that this meta-optimization enables agents to learn how to learn, yielding consistent outperformance over strong baselines on diverse reasoning benchmarks together with reliable iterative gains rather than early plateaus.
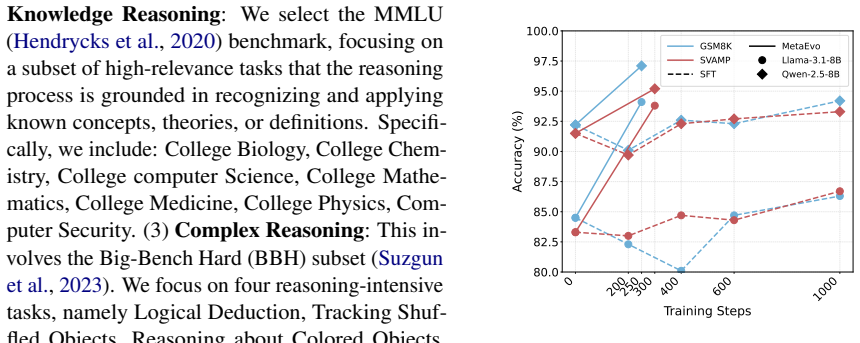
Significance. If the experimental results hold, the contribution would be significant for LLM-agent research: it directly targets the limitation that current experience-driven methods treat the model as a passive executor and therefore saturate. By focusing on improving the abstraction step itself and then enabling modular reuse, the approach offers a plausible route to sustained, compounding improvement. The absence of any quantitative results, however, prevents evaluation of whether the claimed gains are realized.
major comments (1)
- Abstract: the central claim that 'MetaEvo consistently outperforms strong baselines, maintains reliable improvement across iterations' is asserted without any metrics, baselines, datasets, ablation results, or statistical details. Because the experimental validation is the sole support for the claim that preference optimization produces transferable, non-plateauing gains, this omission is load-bearing and prevents assessment of soundness.
minor comments (1)
- Abstract: the sentence fragment 'maintains reliable improvement across iterations' lacks a coordinating conjunction and should read 'and maintains reliable improvement across iterations'.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that the high-level claims require supporting quantitative anchors to allow immediate assessment of the contribution.
read point-by-point responses
-
Referee: [—] Abstract: the central claim that 'MetaEvo consistently outperforms strong baselines, maintains reliable improvement across iterations' is asserted without any metrics, baselines, datasets, ablation results, or statistical details. Because the experimental validation is the sole support for the claim that preference optimization produces transferable, non-plateauing gains, this omission is load-bearing and prevents assessment of soundness.
Authors: We accept the point. The abstract currently summarizes the experimental outcomes at a high level without concrete numbers. In the revised manuscript we will expand the final sentence of the abstract to include the key quantitative results (e.g., average accuracy gains over the strongest baseline, number of iterations with continued improvement, and the primary datasets), while preserving the 150-word limit. The detailed tables, baselines, and statistical tests already appear in Section 4; the abstract revision will simply make those findings visible at the outset. revision: yes
Circularity Check
No derivation chain or equations present; framework is purely empirical
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or mathematical claims of any kind. The paper proposes a two-stage empirical framework (preference optimization followed by modular reuse) and reports benchmark outperformance, but makes no load-bearing predictions or first-principles results that could reduce to inputs by construction. No self-citations, ansatzes, or uniqueness theorems appear. The central claims rest on experimental results rather than any derivational chain, so no circularity is identifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[2]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , journal =. 2020 , url =. 2005.14165 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2302.13971 , eprinttype =. 2302.13971 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[4]
Zeyuan Yang and Peng Li and Yang Liu , editor =. Failures Pave the Way: Enhancing Large Language Models through Tuning-free Rule Accumulation , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.109 , timestamp =
-
[5]
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Yong. ExpeL:. Thirty-Eighth. 2024 , url =. doi:10.1609/AAAI.V38I17.29936 , timestamp =
-
[6]
Jinglong Gao and Xiao Ding and Yiming Cui and Jianbai Zhao and Hepeng Wang and Ting Liu and Bing Qin , editor =. Self-Evolving. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.346 , timestamp =
-
[7]
Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2401.03385 , eprinttype =. 2401.03385 , timestamp =
-
[8]
MoT: Memory-of-Thought Enables ChatGPT to Self-Improve , booktitle =
Xiaonan Li and Xipeng Qiu , editor =. MoT: Memory-of-Thought Enables ChatGPT to Self-Improve , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.392 , timestamp =
-
[9]
MindAgent: Emergent Gaming Interaction , booktitle =
Ran Gong and Qiuyuan Huang and Xiaojian Ma and Yusuke Noda and Zane Durante and Zilong Zheng and Demetri Terzopoulos and Li Fei. MindAgent: Emergent Gaming Interaction , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-NAACL.200 , timestamp =
-
[10]
Reflexion: language agents with verbal reinforcement learning , booktitle =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , editor =. Reflexion: language agents with verbal reinforcement learning , booktitle =. 2023 , url =
2023
-
[11]
Self-Refine: Iterative Refinement with Self-Feedback , booktitle =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , editor =. Self-Refine: Iterative Refinement with Self-Feedb...
2023
-
[12]
The Twelfth International Conference on Learning Representations,
Zhibin Gou and Zhihong Shao and Yeyun Gong and Yelong Shen and Yujiu Yang and Nan Duan and Weizhu Chen , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[13]
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives , booktitle =
Wenqi Zhang and Yongliang Shen and Linjuan Wu and Qiuying Peng and Jun Wang and Yueting Zhuang and Weiming Lu , editor =. Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.197 , timestamp =
-
[14]
Liting Chen and Lu Wang and Hang Dong and Yali Du and Jie Yan and Fangkai Yang and Shuang Li and Pu Zhao and Si Qin and Saravan Rajmohan and Qingwei Lin and Dongmei Zhang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2305.11598 , eprinttype =. 2305.11598 , timestamp =
-
[15]
Cox and Yiming Yang and Chuang Gan , editor =
Zhiqing Sun and Yikang Shen and Qinhong Zhou and Hongxin Zhang and Zhenfang Chen and David D. Cox and Yiming Yang and Chuang Gan , editor =. Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision , booktitle =. 2023 , url =
2023
-
[16]
Training Verifiers to Solve Math Word Problems
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. CoRR , volume =. 2021 , url =. 2110.14168 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Arkil Patel and Satwik Bhattamishra and Navin Goyal , editor =. Are. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2021 , url =. doi:10.18653/V1/2021.NAACL-MAIN.168 , timestamp =
work page internal anchor Pith review doi:10.18653/v1/2021.naacl-main.168 2021
-
[18]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. CoRR , volume =. 2021 , url =. 2103.03874 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Measuring Massive Multitask Language Understanding
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. CoRR , volume =. 2020 , url =. 2009.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Mirac Suzgun and Nathan Scales and Nathanael Sch. Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-ACL.824 , timestamp =
-
[21]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al. The Llama 3 Herd of Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[22]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[23]
2024 , eprint=
On the Structural Memory of LLM Agents , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
SELF: Self-Evolution with Language Feedback , author=. 2024 , eprint=
2024
-
[26]
2023 , eprint=
Large Language Models Understand and Can be Enhanced by Emotional Stimuli , author=. 2023 , eprint=
2023
-
[27]
2024 , eprint=
Self-Improving Customer Review Response Generation Based on LLMs , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[29]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[30]
2025 , eprint=
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence , author=. 2025 , eprint=
2025
-
[31]
Kolb , TITLE =
D.A. Kolb , TITLE =. 1984 , ADDRESS =
1984
-
[32]
, title =
Kolb, David A. , title =. 1984 , publisher =
1984
-
[33]
Academy of Management Learning & Education , volume=
Learning styles and learning spaces: Enhancing experiential learning in higher education , author=. Academy of Management Learning & Education , volume=. 2005 , publisher=
2005
-
[34]
arXiv preprint arXiv:2305.14045 , year=
The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning , author=. arXiv preprint arXiv:2305.14045 , year=
-
[35]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[36]
2023 , eprint=
Self-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations , author=. 2023 , eprint=
2023
-
[37]
2024 , eprint=
Self-Discover: Large Language Models Self-Compose Reasoning Structures , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
A-MEM: Agentic Memory for LLM Agents , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Task-Core Memory Management and Consolidation for Long-term Continual Learning , author=. 2025 , eprint=
2025
-
[40]
2023 , eprint=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[41]
2025 , eprint=
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. 2025 , eprint=
2025
-
[42]
2025 , eprint=
Contextual Experience Replay for Self-Improvement of Language Agents , author=. 2025 , eprint=
2025
-
[43]
2025 , eprint=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
SEDM: Scalable Self-Evolving Distributed Memory for Agents , author=. 2025 , eprint=
2025
-
[45]
2024 , eprint=
RoboCoder: Robotic Learning from Basic Skills to General Tasks with Large Language Models , author=. 2024 , eprint=
2024
-
[46]
2025 , eprint=
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.