Rosetta Memory: Adaptive Memory for Cross-LLM Agents
Pith reviewed 2026-06-27 22:40 UTC · model grok-4.3
The pith
Profile-conditioned operators enable memory written by one LLM to activate a different LLM effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We approach the upstream-downstream memory adaptation problem from both write and read sides by designing two profile-conditioned operators that are jointly trained to optimize how memory is stored and presented for better task completion; to ensure generalization across LLMs we use a minimum-gain sampling curriculum that prioritizes the least-served models, and we measure contribution with a performance-gap reward that compares against a naive memory baseline.
What carries the argument
Profile-conditioned operators that adapt memory write and read operations based on LLM profiles.
Load-bearing premise
The profile-conditioned operators trained with minimum-gain sampling will generalize to a broad set of LLMs including unseen ones rather than overfitting to the models seen during the curriculum.
What would settle it
If transferring memory written by one LLM to an unseen different LLM on HotpotQA or MuSiQue produces no gain over the naive memory baseline, the claim of effective cross-LLM adaptation would be falsified.
Figures




read the original abstract
Memory is the key component for transforming a stateless LLM into a persistent, evolving agent through experience accumulation, long-horizon planning, and continual self-improvement. Existing memory systems typically take the LLM as the center and design memory operations tailored to a specific backbone. In practice, however, users frequently switch between LLMs, for example using Claude for coding and GPT for writing across tasks, or routing different steps to different backbones within a single task for cost-effective trade-offs. As a result, memory written by one model often needs to be consumed by another. Making upstream memory effectively adapt to and activate downstream LLMs remains a critical yet underexplored problem. To bridge this gap, we shift the perspective from LLM-centric memory design to \emph{memory-centric LLM adaptation}. Specifically, we approach the above upstream-downstream memory adaptation problem from both the write and read sides, and design two profile-conditioned operators that are jointly trained to optimize how memory is stored and presented for better task completion. To ensure the learned operators generalize across a broad set of LLMs, we propose a minimum-gain sampling curriculum that prioritizes the least-served LLMs during training. To better measure the operators' actual contribution rather than the LLM's own capability, we design a performance-gap reward that compares against a naive memory baseline. Experiments on HotpotQA, 2WikiMultihopQA, and MuSiQue demonstrate that our model consistently outperforms baselines and remains robust under unseen-model replacement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rosetta Memory, a memory-centric approach to cross-LLM agent adaptation. It introduces two jointly trained profile-conditioned operators (write and read) that adapt memory storage and retrieval for better task performance across different LLMs. Training uses a minimum-gain sampling curriculum to prioritize least-served models for generalization, paired with a performance-gap reward that measures operator contribution against a naive baseline. Experiments on HotpotQA, 2WikiMultihopQA, and MuSiQue report consistent outperformance over baselines and robustness when LLMs are replaced with unseen models.
Significance. If the claimed generalization of the profile-conditioned operators holds, the work addresses a practical gap in multi-LLM workflows where memory written by one model must be consumed by another. The minimum-gain curriculum and performance-gap reward are constructive elements that could support broader applicability of memory systems beyond single-LLM designs.
major comments (2)
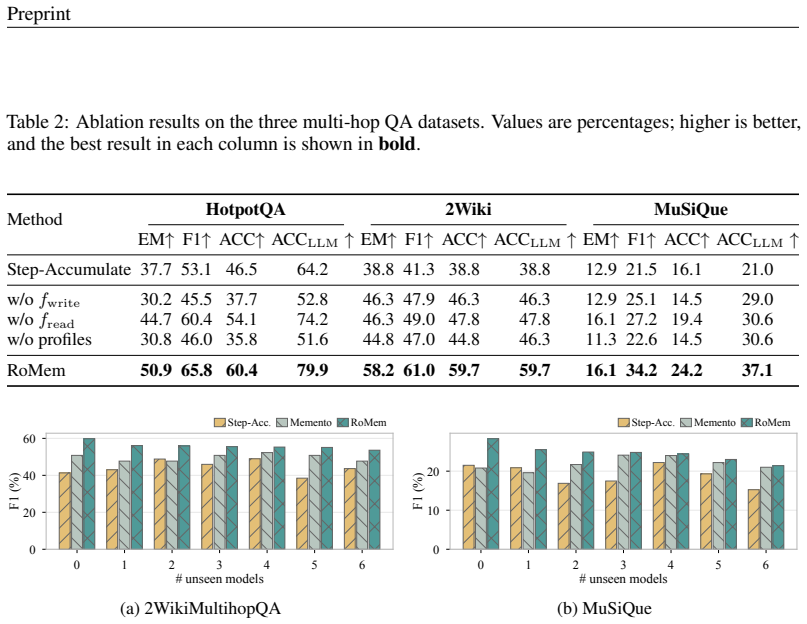
- [Experiments (unseen-model replacement)] Experiments section (unseen-model replacement results): The central robustness claim requires that the jointly trained operators generalize beyond the training LLM distribution. The minimum-gain sampling is intended to achieve this, yet no details are provided on the exact set of LLMs used in the curriculum, the specific unseen replacement models, or quantitative metrics (e.g., performance delta with vs. without the curriculum) showing that the operators capture transferable rules rather than patterns specific to the seen models. This directly affects whether the unseen-replacement experiments support the generalization conclusion.
- [Method (operators and training)] Method section (profile-conditioned operators and joint training): The write and read operators are described as profile-conditioned, but the manuscript does not specify the content or representation of the LLM profile used for conditioning, nor how the joint training objective combines the two sides with the performance-gap reward. Without these details, it is difficult to verify that the operators implement memory-centric adaptation rather than model-specific heuristics.
minor comments (2)
- [Abstract] The abstract states that the model 'remains robust under unseen-model replacement' but provides no numerical results or baseline comparisons for that setting; adding a brief quantitative summary would improve clarity.
- [Method] Notation for the performance-gap reward and minimum-gain sampling could be formalized with equations to make the training procedure reproducible from the text alone.
Simulated Author's Rebuttal
Thank you for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, providing clarifications and committing to revisions where details were insufficiently specified in the manuscript.
read point-by-point responses
-
Referee: Experiments section (unseen-model replacement results): The central robustness claim requires that the jointly trained operators generalize beyond the training LLM distribution. The minimum-gain sampling is intended to achieve this, yet no details are provided on the exact set of LLMs used in the curriculum, the specific unseen replacement models, or quantitative metrics (e.g., performance delta with vs. without the curriculum) showing that the operators capture transferable rules rather than patterns specific to the seen models. This directly affects whether the unseen-replacement experiments support the generalization conclusion.
Authors: We agree that the Experiments section would benefit from explicit enumeration of these elements to better substantiate the generalization claim. In the revised manuscript, we will add: (i) the full set of LLMs employed in the minimum-gain sampling curriculum, (ii) the precise identities of the unseen replacement models, and (iii) an ablation table reporting performance deltas with versus without the curriculum on the unseen-model replacement tasks. These additions will directly address how the operators learn transferable rules. revision: yes
-
Referee: Method section (profile-conditioned operators and joint training): The write and read operators are described as profile-conditioned, but the manuscript does not specify the content or representation of the LLM profile used for conditioning, nor how the joint training objective combines the two sides with the performance-gap reward. Without these details, it is difficult to verify that the operators implement memory-centric adaptation rather than model-specific heuristics.
Authors: We acknowledge that the manuscript would be strengthened by more precise specifications here. The LLM profile is represented as a fixed-dimensional embedding constructed from model metadata and benchmark scores; the joint training objective combines the write and read operators through a shared performance-gap reward in a single optimization loop. In the revision, we will insert the exact profile construction procedure, dimensionality, and the mathematical form of the joint objective (including how the reward is applied across both operators) into the Method section. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks and generalization tests
full rationale
The paper describes an empirical system of profile-conditioned operators trained via a minimum-gain curriculum and evaluated with a performance-gap reward against a naive baseline. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to the inputs by construction. The robustness claim under unseen-model replacement is an empirical generalization test rather than a definitional or self-referential derivation. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mohammad Aghajani Asl, Majid Asgari-Bidhendi, and Behrooz Minaei-Bidgoli. Fair-rag: Faithful adaptive iterative refinement for retrieval-augmented generation.arXiv preprint arXiv:2510.22344,
-
[2]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InInternational Conference on Learning Representations, volume 2024, pp. 20094–20136,
2024
-
[3]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
-
[4]
Tao Feng, Chongrui Ye, Tianyang Luo, Jingjun Xu, Xueqiang Xu, Haozhen Zhang, Ge Liu, and Jiaxuan You. Elasticmem: Latent memory as a learnable resource for llm agents.arXiv preprint arXiv:2605.30690, 2026a. Tao Feng, Haozhen Zhang, Zijie Lei, Peixuan Han, and Jiaxuan You. Graphplanner: Graph memory- augmented agentic routing for multi-agent llms.arXiv pre...
-
[5]
Self-evolving multi-agent systems via decentralized memory.arXiv preprint arXiv:2605.22721,
Guangya Hao, Yunbo Long, and Zhuokai Zhao. Self-evolving multi-agent systems via decentralized memory.arXiv preprint arXiv:2605.22721,
-
[6]
Does prompt formatting have any impact on llm performance?arXiv preprint arXiv:2411.10541,
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X Wang, and Sadid Hasan. Does prompt formatting have any impact on llm performance?arXiv preprint arXiv:2411.10541,
-
[7]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pp. 23247–23275,
2024
-
[8]
Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773,
Wittawat Jitkrittum, Harikrishna Narasimhan, Ankit Singh Rawat, Jeevesh Juneja, Congchao Wang, Zifeng Wang, Alec Go, Chen-Yu Lee, Pradeep Shenoy, Rina Panigrahy, et al. Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773,
-
[9]
Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. A human-inspired reading agent with gist memory of very long contexts.arXiv preprint arXiv:2402.09727,
-
[10]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 3045–3059,
2021
-
[11]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, et al. Memos: An operating system for memory-augmented generation (mag) in large language models.arXiv preprint arXiv:2505.22101,
-
[12]
Ali Modarressi, Ayyoob Imani, Mohsen Fayyaz, and Hinrich Schütze. Ret-llm: Towards a general read-write memory for large language models.arXiv preprint arXiv:2305.14322,
-
[13]
Memllm: Finetuning llms to use an explicit read-write memory.arXiv preprint arXiv:2404.11672,
Ali Modarressi, Abdullatif Köksal, Ayyoob Imani, Mohsen Fayyaz, and Hinrich Schütze. Memllm: Finetuning llms to use an explicit read-write memory.arXiv preprint arXiv:2404.11672,
-
[14]
Yasmin Moslem and John D Kelleher. Dynamic model routing and cascading for efficient llm inference: A survey.arXiv preprint arXiv:2603.04445,
-
[15]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 5687–5711,
2023
-
[16]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pp. 2383–2392,
2016
-
[17]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
-
[18]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
-
[19]
V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
-
[20]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Y Zou. Mixture-of-agents enhances large language model capabilities. InInternational Conference on Learning Representations, volume 2025, pp. 33944–33963,
2025
-
[21]
Mirix: Multi-agent memory system for llm-based agents.arXiv preprint arXiv:2507.07957,
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm-based agents.arXiv preprint arXiv:2507.07957,
-
[22]
Sikuan Yan, Ahmed Bahloul, Ercong Nie, Susanna Schwarzmann, Riccardo Trivisonno, V olker Tresp, and Yunpu Ma. Memory-r2: Fair credit assignment for long-horizon memory-augmented llm agents.arXiv preprint arXiv:2605.21768,
-
[23]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[24]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026a. Zhongming Yu, Naicheng Yu, Hejia Zhang, Wentao Ni, Mingrui Yin, Jiaying Yang, Yujie Zhao, and Jishen Zhao. Multi-agent memor...
-
[25]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625,
-
[26]
Memento: Fine-tuning llm agents without fine-tuning llms
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, et al. Memento: Fine-tuning llm agents without fine-tuning llms. arXiv preprint arXiv:2508.16153,
-
[27]
• We evaluate controlled multi-hop QA episodes with fixed evidence-chain lengths
13 Preprint A LIMITATIONS RoMem is a first step toward memory-centric adaptation for heterogeneous LLM agents, and our study has several limitations. • We evaluate controlled multi-hop QA episodes with fixed evidence-chain lengths. This setting exposes cross-LLM memory effects clearly, but it does not fully cover open-ended web navigation, tool use, dialo...
2018
-
[28]
Examples with fewer usable hops than the target episode length are filtered out before training and evaluation
are instantiated as 2-hop, 3-hop, and 4-hop episodes, respectively, matching their typical evidence-chain lengths in our processed files. Examples with fewer usable hops than the target episode length are filtered out before training and evaluation. After filtering and sampling, the training/test splits contain 1,851/159 examples for HotpotQA, 642/67 exam...
2025
-
[29]
We instantiate it by treating the hop sequence of the current QA instance as the trajectory memory
represents experience as an episodic trajectory that can guide later decisions. We instantiate it by treating the hop sequence of the current QA instance as the trajectory memory. C.5 EVALUATIONPROTOCOL All methods are evaluated on the same dataset subsets, candidate-context source, answer model, and metric implementation. We report EM, token-level F1 (Ra...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.