GNSS-FM: A Self-Supervised Foundation Model for Daily GNSS Displacement Time Series
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
Self-supervised pretraining on unlabeled GNSS displacement data produces representations that improve performance on forecasting and seismic localization tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that pretraining with self-supervised masked prediction on global GNSS data allows the model to learn representations that capture seismic offsets, tectonic drift, and seasonal patterns, leading to better results when adapted to specific tasks like forecasting displacements over 90 days and detecting seismic steps compared to models trained from scratch on those tasks.
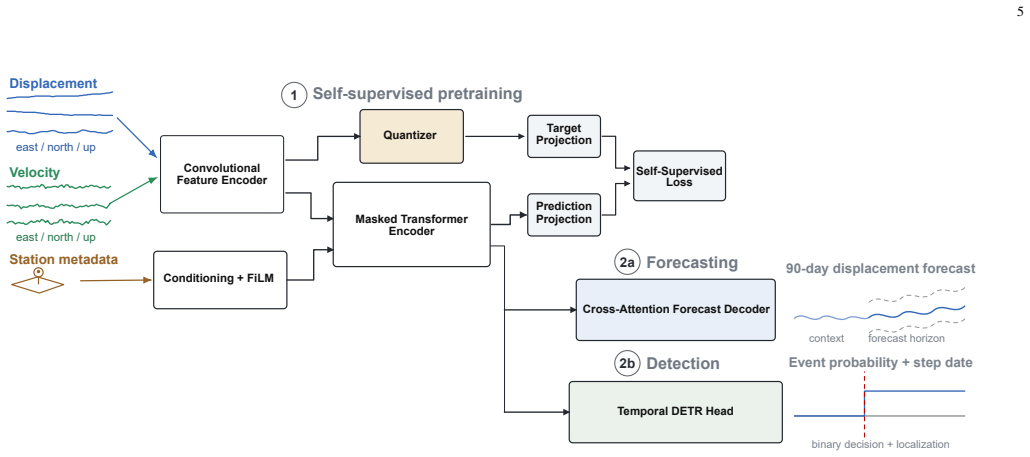
What carries the argument
Dual-stream input of displacement and velocity increments with a masked latent prediction objective using vector-quantized targets adapted from wav2vec 2.0 for geodetic time series.
If this is right
- The foundation model captures main signal types including seismic offsets, tectonic drift, and seasonal patterns.
- Fine-tuning leads to better 90-day displacement forecasting than strong task-specific baselines.
- Fine-tuning leads to better seismic step localization than strong task-specific baselines.
- Self-supervised pretraining is a promising approach for GNSS time series analysis.
Where Pith is reading between the lines
- Similar self-supervised models could be developed for other types of geophysical time series data.
- The learned codebook could enable unsupervised detection of geophysical events beyond the fine-tuned tasks.
- Pretraining on global data might allow better generalization to regions with sparse labeled data.
Load-bearing premise
The representations learned during pretraining capture the main signal types in GNSS displacement data, including seismic offsets, tectonic drift, and seasonal patterns.
What would settle it
Demonstrating that the fine-tuned GNSS-FM does not outperform task-specific baselines on either the forecasting or the seismic localization task would falsify the central claim.
Figures









read the original abstract
Displacement time series from Global Navigation Satellite Systems (GNSS) are essential for a wide range of applications, including monitoring tectonic crustal deformations and investigating the different stages of the earthquake cycle. Machine learning methods have proven promising for GNSS applications; however, most remain fully supervised. This creates a bottleneck as labeled data are scarce, even though large amounts of unlabeled GNSS data are freely available. We present GNSS-FM, a self-supervised foundation model for daily GNSS time series. The model uses a dual-stream input combining displacement and velocity-like increments, and is pretrained using a masked latent prediction objective with vector-quantized targets adapted from wav2vec 2.0, with several modifications for geodetic data. Pretrained on data from over 17,000 globally distributed GNSS stations, an analysis of the learned codebook suggests that the representations capture the main signal types in GNSS displacement data, including seismic offsets, tectonic drift, and seasonal patterns. The foundation model is later fine-tuned on two downstream tasks, namely 90-day displacement forecasting and seismic step localization, where it outperforms strong task-specific baselines in both cases. These results show that self-supervised pretraining is a promising approach for GNSS time series analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GNSS-FM, a self-supervised foundation model for daily GNSS displacement time series. It is pretrained on unlabeled data from over 17,000 globally distributed stations using a dual-stream (displacement and velocity-like increments) input and a masked latent prediction objective with vector-quantized targets adapted from wav2vec 2.0. An analysis of the learned codebook is presented as evidence that the representations capture key geophysical signals including seismic offsets, tectonic drift, and seasonal patterns. The pretrained model is then fine-tuned on two downstream tasks—90-day displacement forecasting and seismic step localization—where it is claimed to outperform strong task-specific baselines.
Significance. If the reported outperformance is shown to arise specifically from the self-supervised pretraining (rather than architecture or data scale alone), the work would demonstrate a viable path for leveraging abundant unlabeled GNSS data to improve performance on tasks where labeled examples remain scarce. The adaptation of wav2vec-style objectives to geodetic time series and the dual-stream design represent concrete technical contributions that could be adopted more broadly in the field.
major comments (2)
- [codebook analysis] Codebook analysis (abstract and associated results section): The assertion that the learned representations capture seismic offsets, tectonic drift, and seasonal patterns rests on an analysis described only as 'suggestive.' No quantitative mapping is supplied (e.g., precision/recall of codebook entries against an independent earthquake catalog for offsets, or reconstruction error conditioned on known tectonic/seasonal regimes). Without such metrics, the causal connection between pretraining and the claimed downstream gains remains unestablished; the observed improvements could equally result from model capacity or fine-tuning procedure.
- [results on downstream tasks] Downstream task evaluation (results section on 90-day forecasting and seismic step localization): The abstract states that fine-tuned GNSS-FM 'outperforms strong task-specific baselines in both cases,' yet supplies no numerical metrics, baseline specifications, statistical tests, confidence intervals, or ablation controls. These details are load-bearing for the central claim that self-supervised pretraining confers an advantage; their absence prevents assessment of whether the gains are robust or reproducible.
minor comments (1)
- [abstract] The abstract and introduction would benefit from explicit citation of the exact number of stations, total time span, and sampling rate used in pretraining to allow readers to gauge data scale.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the evidence supporting our claims regarding the codebook analysis and downstream task evaluations.
read point-by-point responses
-
Referee: [codebook analysis] Codebook analysis (abstract and associated results section): The assertion that the learned representations capture seismic offsets, tectonic drift, and seasonal patterns rests on an analysis described only as 'suggestive.' No quantitative mapping is supplied (e.g., precision/recall of codebook entries against an independent earthquake catalog for offsets, or reconstruction error conditioned on known tectonic/seasonal regimes). Without such metrics, the causal connection between pretraining and the claimed downstream gains remains unestablished; the observed improvements could equally result from model capacity or fine-tuning procedure.
Authors: We agree that describing the codebook analysis as merely 'suggestive' does not sufficiently establish the link between the learned representations and specific geophysical signals, nor does it isolate the contribution of pretraining to downstream gains. In the revised manuscript, we will add quantitative evaluations: precision and recall metrics for codebook entries associated with seismic offsets by cross-referencing against an independent earthquake catalog; and regime-conditioned reconstruction or classification errors for tectonic drift and seasonal patterns. These additions will provide a more rigorous mapping and help demonstrate that the representations capture the relevant signals. revision: yes
-
Referee: [results on downstream tasks] Downstream task evaluation (results section on 90-day forecasting and seismic step localization): The abstract states that fine-tuned GNSS-FM 'outperforms strong task-specific baselines in both cases,' yet supplies no numerical metrics, baseline specifications, statistical tests, confidence intervals, or ablation controls. These details are load-bearing for the central claim that self-supervised pretraining confers an advantage; their absence prevents assessment of whether the gains are robust or reproducible.
Authors: We concur that the absence of specific numerical metrics, baseline details, statistical tests, confidence intervals, and ablation controls in the abstract and results section limits the ability to evaluate the robustness of the claims and the specific benefit of self-supervised pretraining. The revised manuscript will include: exact performance numbers (e.g., RMSE or MAE for 90-day forecasting and precision/recall or F1 for step localization); full specifications of the task-specific baselines including architectures and training protocols; results of statistical significance tests with confidence intervals; and ablation studies comparing the pretrained GNSS-FM against non-pretrained or randomly initialized counterparts to isolate the effect of the self-supervised pretraining from model capacity or fine-tuning alone. revision: yes
Circularity Check
No significant circularity; empirical pretraining and fine-tuning chain is self-contained
full rationale
The paper describes standard self-supervised pretraining on unlabeled GNSS data (>17k stations) using a masked latent prediction objective adapted from wav2vec 2.0, followed by separate fine-tuning on two downstream tasks (90-day forecasting and seismic step localization) with reported outperformance versus task-specific baselines. No equations, definitions, or self-citations reduce any claimed result to its own inputs by construction. The codebook analysis is presented as a post-hoc observation rather than a load-bearing derivation. All performance claims rest on external empirical benchmarks, satisfying the self-contained criterion for a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geodynamics,
J. Freymueller, “Geodynamics,” inSpringer Handbook of Global Nav- igation Satellite Systems, P. J. Teunissen and O. Montenbruck, Eds. Cham: Springer International Publishing, 2017
2017
-
[2]
Harnessing the GPS data explosion for interdisciplinary science,
G. Blewitt, W. C. Hammond, and C. Kreemer, “Harnessing the GPS data explosion for interdisciplinary science,”Eos, vol. 99, 2018
2018
-
[3]
Discontinuity detection in GNSS station coordinate time series using machine learning,
L. Crocetti, M. Schartner, and B. Soja, “Discontinuity detection in GNSS station coordinate time series using machine learning,”Remote Sensing, vol. 13, p. 3906, 2021
2021
-
[4]
An improved VMD-LSTM model for time-varying GNSS time series prediction with temporally correlated noise,
H. Chen, T. Lu, J. Huang, X. He, K. Yu, X. Sun, X. Ma, and Z. Huang, “An improved VMD-LSTM model for time-varying GNSS time series prediction with temporally correlated noise,”Remote Sensing, vol. 15, no. 14, p. 3694, 2023
2023
-
[5]
Multi-station deep learning on geodetic time series detects slow slip events in cascadia,
G. Costantino, S. Giffard-Roisin, M. Radiguet, M. Dalla Mura, D. Marsan, and A. Socquet, “Multi-station deep learning on geodetic time series detects slow slip events in cascadia,”Communications Earth & Environment, vol. 4, p. 435, 2023
2023
-
[6]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of NAACL-HLT, 2019
2019
-
[7]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of CVPR,
-
[8]
Masked Autoencoders Are Scalable Vision Learners
[Online]. Available: https://arxiv.org/abs/2111.06377
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 12 449– 12 460. [Online]. Available: https://proceedings.neurips.cc/paper/2020/ hash/92d1e1eb1cd6f9fba3227870bb6d7f07-Abstract.html
2020
-
[10]
SeisLM: a foundation model for seismic waveforms,
T. Liu, J. M ¨unchmeyer, L. Laurenti, C. Marone, M. V . d. Hoop, and I. Dokmani ´c, “SeisLM: a foundation model for seismic waveforms,” arXiv preprint arXiv:2410.15765, 2024
-
[11]
Beit: Bert pre-training of image transformers,
H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[12]
Feature guided masked autoencoder for self-supervised learning in remote sens- ing,
Y . Wang, H. Hern ´andez Hern ´andez, C. Albrecht, and X. Zhu, “Feature guided masked autoencoder for self-supervised learning in remote sens- ing,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, pp. 1–17, 2024
2024
-
[13]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[14]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, Y . Qian, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[15]
TS2Vec: Towards universal representation of time series,
Z. Yue, Y . Wang, J. Duan, T. Yang, C. Huang, Y . Tong, and B. Xu, “TS2Vec: Towards universal representation of time series,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 8, 2022, pp. 8980–8987
2022
-
[16]
A transformer-based framework for multivariate time series representation learning,
G. Zerveas, S. Jayaraman, D. Patel, A. Bhamidipaty, and C. Eickhoff, “A transformer-based framework for multivariate time series representation learning,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2021, pp. 2114–2124
2021
-
[17]
Vector quantization pretraining for EEG time series with random projection and phase alignment,
H. Gui, X. Li, and X. Chen, “Vector quantization pretraining for EEG time series with random projection and phase alignment,” in Proceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, Eds., vol. 235. P...
2024
-
[18]
Effective self-supervised transformers for sparse time series data,
A. Labach, A. Pokhrel, S. E. Yi, S. Zuberi, M. V olkovs, and R. G. Krishnan, “Effective self-supervised transformers for sparse time series data,”OpenReview, 2022. [Online]. Available: https://openreview.net/forum?id=HUCgU5EQluN
2022
-
[19]
Self-supervised spatio-temporal representation learning of satellite image time series,
I. Dumeur, S. Valero, and J. Inglada, “Self-supervised spatio-temporal representation learning of satellite image time series,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 4350–4367, 2024
2024
-
[20]
Chronos: Learning the Language of Time Series
A. F. Ansariet al., “Chronos: Learning the language of time series,”arXiv preprint arXiv:2403.07815, 2024. [Online]. Available: https://arxiv.org/abs/2403.07815
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
A decoder-only foundation model for time-series forecasting
A. Das, W. Kong, R. Sen, and Y . Zhou, “A decoder-only foundation model for time-series forecasting,”arXiv preprint arXiv:2310.10688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
A. Garza, C. Challu, and M. Mergenthaler-Canseco, “TimeGPT-1,”arXiv preprint arXiv:2310.03589, 2023
-
[23]
A foundation model for the earth system,
C. Bodnar, W. P. Bruinsma, A. Lucic, M. Stanley, A. Allen, J. Brand- stetter, P. Garvan, M. Riechert, J. A. Weyn, H. Dong, J. K. Gupta, K. Thambiratnam, A. T. Archibald, C.-C. Wu, E. Heider, M. Welling, R. E. Turner, and P. Perdikaris, “A foundation model for the earth system,”Nature, vol. 641, pp. 1180–1187, 2025
2025
-
[24]
Integrating GNSS- derived atmospheric delays into large weather foundation models,
L. Trentini, F. Lehmann, L. Crocetti, and B. Soja, “Integrating GNSS- derived atmospheric delays into large weather foundation models,” in EGU General Assembly 2026. Vienna, Austria: Copernicus Meetings, 2026, eGU26-6706
2026
-
[25]
Earth system foundation model (esfm): A unified framework for heterogeneous data integration and forecasting,
F. Ozdemir, Y . Cheng, S. Mohebi, F. Lehmann, S. Adamov, Z. Zhang, L. Trentini, D. Grund, O. Fuhrer, T. Hoefler, S. Mishra, S. Schemm, B. Soja, and M. Salzmann, “Earth system foundation model (esfm): A unified framework for heterogeneous data integration and forecasting,” 2026
2026
-
[26]
Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data,
C. F. Brown, M. R. Kazmierski, V . J. Pasquarella, W. J. Ruck- lidge, M. Samsikova, C. Zhang, E. Shelhamer, E. Lahera, O. Wiles, S. Ilyushchenko, N. Gorelick, L. L. Zhang, S. Alj, E. Schechter, S. Askay, O. Guinan, R. Moore, A. Boukouvalas, and P. Kohli, “Alphaearth foundations: An embedding field model for accurate and efficient global mapping from spars...
2025
-
[27]
Denoising daily displacement GNSS time series using deep neural networks in a near real-time framing: a single-station method,
G. Mastella, J. Bedford, F. Corbi, and F. Funiciello, “Denoising daily displacement GNSS time series using deep neural networks in a near real-time framing: a single-station method,”Geophysical Journal Inter- national, vol. 242, no. 3, p. ggaf207, 2025
2025
-
[28]
Cascadia daily GNSS time series denoising: Graph neural network and stack filtering,
L. Bachelot, A. M. Thomas, D. Melgar, J. Searcy, and Y .-S. Sun, “Cascadia daily GNSS time series denoising: Graph neural network and stack filtering,”Seismica, vol. 2, no. 4, 2023
2023
-
[29]
Modeling of residual GNSS station motions through meteorological data in a machine learning approach,
P. Ruttner, R. Hohensinn, S. D’Aronco, J. D. Wegner, and B. Soja, “Modeling of residual GNSS station motions through meteorological data in a machine learning approach,”Remote Sensing, vol. 14, no. 1, p. 17, 2022
2022
-
[30]
Correction models for GNSS displacements in europe based on en- vironmental variables and XGBoost,
L. Crocetti, M. Schartner, R. Schneider, K. Schindler, and B. Soja, “Correction models for GNSS displacements in europe based on en- vironmental variables and XGBoost,”Earth and Space Science Open Archive, 2025, preprint
2025
-
[31]
Modelling of GNSS station position time series using deep learning approaches,
M. S ¸ims ¸ek, M. Tas ¸kıran, and U. Do˘gan, “Modelling of GNSS station position time series using deep learning approaches,”Earth Science Informatics, vol. 18, no. 1, p. 96, 2024
2024
-
[32]
Kiani Shahvandi and B
M. Kiani Shahvandi and B. Soja, “Inclusion of data uncertainty in machine learning and its application in geodetic data science, with case studies for the prediction of earth orientation parameters and GNSS station coordinate time series,”Advances in Space Research, vol. 70, no. 3, pp. 563–575, 2022
2022
-
[33]
The effect of coloured noise on the uncertainties of rates estimated from geodetic time series,
S. D. P. Williams, “The effect of coloured noise on the uncertainties of rates estimated from geodetic time series,”Journal of Geodesy, vol. 76, no. 9, pp. 483–494, 2003
2003
-
[34]
Anatomy of apparent seasonal variations from GPS-derived site position time series,
D. Dong, P. Fang, Y . Bock, M. K. Cheng, and S. Miyazaki, “Anatomy of apparent seasonal variations from GPS-derived site position time series,” Journal of Geophysical Research, vol. 107, no. B4, 2002. 14
2002
-
[35]
Itrf2020: an augmented reference frame refining the modeling of nonlinear station motions,
Z. Altamimi, P. Rebischung, X. Collilieux, L. M ´etivier, and K. Chanard, “Itrf2020: an augmented reference frame refining the modeling of nonlinear station motions,”Journal of Geodesy, vol. 97, no. 47, 2023
2023
-
[36]
Wdowinski, Y
S. Wdowinski, Y . Bock, J. Zhang, P. Fang, and J. Genrich, “Southern California permanent GPS geodetic array: Spatial filtering of daily posi- tions for estimating coseismic and postseismic displacements induced by the 1992 Landers earthquake,”Journal of Geophysical Research: Solid Earth, vol. 102, no. B8, pp. 18 057–18 070, 1997
1992
-
[37]
Spa- tiotemporal filtering using principal component analysis and karhunen– lo`eve expansion approaches to GPS coordinate time series,
D. Dong, P. Fang, Y . Bock, M. K. Cheng, and S. Miyazaki, “Spa- tiotemporal filtering using principal component analysis and karhunen– lo`eve expansion approaches to GPS coordinate time series,”Journal of Geophysical Research: Solid Earth, vol. 111, no. B3, 2006
2006
-
[38]
Noise-resilient GNSS coordinate time series prediction using A VMD-sLSTM-transformer hybrid model,
J. Jiao, H. Wang, Y . Dang, Y . Ren, C. Yue, X. Wu, H. Cui, and X. Wang, “Noise-resilient GNSS coordinate time series prediction using A VMD-sLSTM-transformer hybrid model,”Advances in Space Research, vol. 76, no. 11, pp. 6863–6881, 2025
2025
-
[39]
Generalized hampel filters,
R. K. Pearson, Y . Neuvo, J. Astola, and M. Gabbouj, “Generalized hampel filters,”EURASIP Journal on Advances in Signal Processing, vol. 2016, p. 87, 2016
2016
-
[40]
The identification of multiple outliers,
L. Davies and U. Gather, “The identification of multiple outliers,” Journal of the American Statistical Association, vol. 88, no. 423, pp. 782–792, 1993
1993
-
[41]
The jackknife and the bootstrap for general stationary observations,
H. R. K ¨unsch, “The jackknife and the bootstrap for general stationary observations,”The Annals of Statistics, vol. 17, no. 3, pp. 1217–1241, 1989
1989
-
[42]
A nearest neighbor bootstrap for resampling hydrologic time series,
U. Lall and A. Sharma, “A nearest neighbor bootstrap for resampling hydrologic time series,”Water Resources Research, vol. 32, no. 3, pp. 679–693, 1996
1996
-
[43]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision (ECCV), 2020
2020
-
[44]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
Go- ing deeper with image transformers,
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. J ´egou, “Go- ing deeper with image transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 32–42
2021
-
[47]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[48]
Categorical reparameterization with Gumbel-Softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with Gumbel-Softmax,” inInternational Conference on Learning Represen- tations (ICLR), 2017
2017
-
[49]
Representation learning with contrastive predictive coding,
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint, 2018
2018
-
[50]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” arXiv preprint arXiv:2211.14730, 2023. [Online]. Available: https: //arxiv.org/abs/2211.14730
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
DAB-DETR: Dynamic anchor boxes are better queries for DETR,
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, and L. Zhang, “DAB-DETR: Dynamic anchor boxes are better queries for DETR,” in International Conference on Learning Representations (ICLR), 2022
2022
-
[53]
Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed
S. Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed. Elsevier, 2008
2008
-
[54]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 785–794
2016
-
[55]
On a test of whether one of two random variables is stochastically larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,”The Annals of Mathematical Statistics, vol. 18, no. 1, pp. 50–60, 1947
1947
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.