A Framework for Evaluating and Benchmarking Concept Drift Detection Methods
Pith reviewed 2026-06-27 22:32 UTC · model grok-4.3
The pith
A benchmarking framework enables fair evaluation of concept drift detectors by simulating controlled changes on real datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By simulating four types of distributional changes on real datasets through Monte Carlo methods, applying timing-sensitive metrics, and using cross-dataset hyperparameter tuning, the framework permits supervised, comparable assessment of drift detectors that preserves the complexity of actual data streams.
What carries the argument
Monte Carlo drift simulation on real datasets combined with timing-aware metrics and leave-one-dataset-out hyperparameter selection.
If this is right
- The strengths and weaknesses of current drift detection approaches become clearer through consistent testing across drift types and transitions.
- New metrics enable direct comparison of detection performance across different data streams.
- Robust hyperparameter configurations can be identified that work across varied stream dynamics.
- Baseline performance metrics are established for future research on 14 methods.
Where Pith is reading between the lines
- The public code release allows extension of the benchmarks to new detectors or additional real datasets.
- Methods optimized under this protocol may transfer better to deployment on live streams with mixed drift patterns.
- The results on gradual transitions could guide development of detectors that handle slow changes more effectively than abrupt ones.
Load-bearing premise
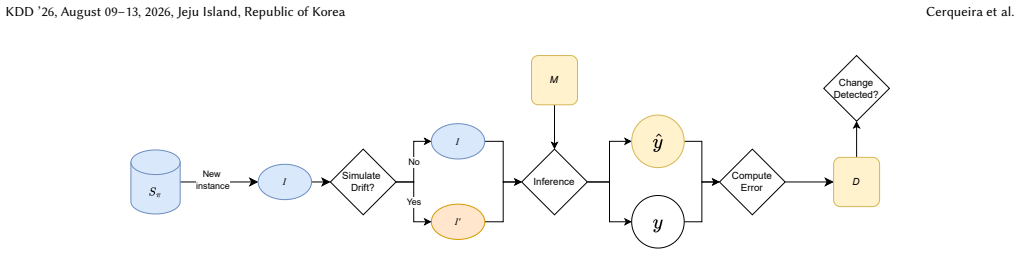
Injecting specific changes like class prior shifts or feature permutations into real datasets via Monte Carlo trials creates representative concept drift without simulation artifacts that bias results toward particular detectors.
What would settle it
Observing that the relative performance rankings of the 14 detectors reverse when evaluated on purely synthetic generators instead of the Monte Carlo-injected real datasets would challenge the framework's validity.
Figures




read the original abstract
Data stream mining is fundamentally challenged by concept drift, where distributional changes can degrade model performance. Despite the proliferation of drift detection methods, progress in the field is hindered by inconsistent evaluation practices: studies rely on oversimplified synthetic data generators, adopt incompatible metrics, and lack transparency in hyperparameter selection, making fair comparisons difficult. We address this gap with a novel benchmarking framework comprising three contributions: (1) a drift simulation method that injects controlled distributional changes into real-world datasets via Monte Carlo trials, enabling supervised evaluation while preserving real-world data complexity; (2) an evaluation protocol for drift detection with timing-aware criteria, including the derivation of new metrics (e.g., F1 detection score, normalized detection time) that are comparable across streams; and (3) we advocate for a leave-one-dataset-out hyperparameter optimization protocol for drift detection methods that promotes configuration robustness across heterogeneous stream dynamics. We benchmark 14 widely used drift detection methods on 7 realworld datasets across 4 drift types (class prior, label swap, feature permutation, feature filtering), each under both abrupt and gradual transitions. Our experimental results provide insights into the strengths and weaknesses of current drift detection approaches while establishing baseline performance metrics for future research in this area. All code and experiments are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmarking framework for concept drift detection methods. It comprises (1) a Monte Carlo drift simulation that injects four controlled distributional changes (class prior, label swap, feature permutation, feature filtering) into 7 real-world datasets under abrupt/gradual regimes to enable supervised evaluation; (2) an evaluation protocol with timing-aware criteria and new metrics (F1 detection score, normalized detection time); and (3) a leave-one-dataset-out hyperparameter optimization protocol. The authors benchmark 14 detectors, report baseline results, and release all code publicly.
Significance. If the simulation produces representative drifts without systematic bias, the framework could standardize evaluation practices in data stream mining by replacing oversimplified synthetic generators and incompatible metrics. The public code and cross-dataset hyperparameter protocol are explicit strengths that support reproducibility and robustness claims.
major comments (1)
- [Drift Simulation Method] Drift Simulation Method (contribution 1): The claim that Monte Carlo injection of the four specific changes produces representative concept-drift instances enabling fair supervised evaluation lacks any external validation against naturally occurring drifts. This is load-bearing for the benchmarking results on 14 detectors, as the chosen mechanisms may favor permutation- or filter-sensitive statistical tests while under-representing other real-world forms such as gradual covariate shift.
minor comments (1)
- [Abstract / Evaluation Protocol] The abstract states that new metrics are 'derived' but does not include their explicit formulas or normalization details; adding these in the evaluation protocol section would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. Below we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [Drift Simulation Method] Drift Simulation Method (contribution 1): The claim that Monte Carlo injection of the four specific changes produces representative concept-drift instances enabling fair supervised evaluation lacks any external validation against naturally occurring drifts. This is load-bearing for the benchmarking results on 14 detectors, as the chosen mechanisms may favor permutation- or filter-sensitive statistical tests while under-representing other real-world forms such as gradual covariate shift.
Authors: We thank the referee for this observation. The paper positions the Monte Carlo drift injection as a method to generate controlled distributional changes on real data, thereby enabling supervised evaluation with known ground truth drift locations and types. We do not claim that these specific injections produce instances that are representative of all naturally occurring drifts. The four mechanisms were chosen because they reflect common types of changes discussed in the data stream mining literature. We recognize that the absence of external validation against real-world drifts is a limitation, and that the chosen drifts might emphasize certain detector types. In the revised manuscript, we will add a dedicated paragraph in the discussion section acknowledging this limitation and outlining directions for future validation efforts. revision: partial
Circularity Check
No circularity: framework is a self-contained methodological proposal
full rationale
The paper proposes a benchmarking framework consisting of a Monte Carlo drift injection procedure, timing-aware evaluation metrics (F1 detection score, normalized detection time), and a leave-one-dataset-out hyperparameter protocol. These are presented as explicit definitions and procedural recommendations rather than predictions derived from fitted parameters or prior self-citations. No equations or claims reduce by construction to inputs defined within the paper; the simulation method and metrics are introduced as novel contributions without self-referential justification loops. The central claims rest on the described procedures themselves, which are externally verifiable via the released code and do not invoke load-bearing self-citations or uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Distributional changes of the four specified types (class prior, label swap, feature permutation, feature filtering) constitute representative instances of concept drift.
- domain assumption Monte Carlo trials can inject these changes while preserving real-world data complexity sufficiently for supervised evaluation.
Reference graph
Works this paper leans on
-
[1]
Manuel Baena-Garcıa, José del Campo-Ávila, Raul Fidalgo, Albert Bifet, Ricard Gavalda, and Rafael Morales-Bueno. 2006. Early drift detection method. InFourth international workshop on knowledge discovery from data streams, Vol. 6. 77–86
2006
-
[2]
Roberto SM Barros, Danilo RL Cabral, Paulo M Gonçalves Jr, and Silas GTC Santos
-
[3]
RDDM: Reactive drift detection method.Expert Systems with Applications 90 (2017), 344–355
2017
-
[4]
James Bergstra and Yoshua Bengio. 2012. Random search for hyper-parameter optimization.The journal of machine learning research13, 1 (2012), 281–305
2012
-
[5]
Albert Bifet. 2017. Classifier concept drift detection and the illusion of progress. InInternational conference on artificial intelligence and soft computing. Springer, 715–725
2017
-
[6]
Albert Bifet and Ricard Gavalda. 2007. Learning from time-changing data with adaptive windowing. InProceedings of the 2007 SIAM international conference on data mining. SIAM, 443–448
2007
-
[7]
Jock A Blackard and Denis J Dean. 1999. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables.Computers and electronics in agriculture24, 3 (1999), 131–151
1999
-
[8]
Vitor Cerqueira, Heitor Murilo Gomes, and Albert Bifet. 2020. Unsupervised con- cept drift detection using a student–teacher approach. InInternational conference on discovery science. Springer, 190–204
2020
-
[9]
Vitor Cerqueira, Heitor Murilo Gomes, Albert Bifet, and Luis Torgo. 2023. STUDD: A student–teacher method for unsupervised concept drift detection.Machine Learning112, 11 (2023), 4351–4378
2023
-
[10]
Gregory Ditzler and Robi Polikar. 2012. Incremental learning of concept drift from streaming imbalanced data.IEEE transactions on knowledge and data engineering 25, 10 (2012), 2283–2301
2012
-
[11]
Pedro Domingos and Geoff Hulten. 2000. Mining high-speed data streams. In Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining. 71–80
2000
-
[12]
Denis Moreira Dos Reis, Peter Flach, Stan Matwin, and Gustavo Batista. 2016. Fast unsupervised online drift detection using incremental kolmogorov-smirnov test. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1545–1554
2016
-
[13]
William J Faithfull, Juan J Rodríguez, and Ludmila I Kuncheva. 2019. Combin- ing univariate approaches for ensemble change detection in multivariate data. Information Fusion45 (2019), 202–214
2019
-
[14]
Tom Fawcett and Foster Provost. 1999. Activity monitoring: Noticing interest- ing changes in behavior. InProceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining. 53–62
1999
-
[15]
Isvani Frias-Blanco, José del Campo-Ávila, Gonzalo Ramos-Jimenez, Rafael Morales-Bueno, Agustin Ortiz-Diaz, and Yailé Caballero-Mota. 2014. Online and non-parametric drift detection methods based on Hoeffding’s bounds.IEEE Transactions on Knowledge and Data Engineering27, 3 (2014), 810–823
2014
-
[16]
Joao Gama, Pedro Medas, Gladys Castillo, and Pedro Rodrigues. 2004. Learning with drift detection. InBrazilian symposium on artificial intelligence. Springer, 286–295
2004
-
[17]
Joao Gama, Raquel Sebastiao, and Pedro Pereira Rodrigues. 2013. On evaluating stream learning algorithms.Machine learning90, 3 (2013), 317–346
2013
-
[18]
João Gama, Indr˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A survey on concept drift adaptation.ACM computing surveys (CSUR)46, 4 (2014), 1–37
2014
-
[19]
Heitor M Gomes, Albert Bifet, Jesse Read, Jean Paul Barddal, Fabrício Enembreck, Bernhard Pfharinger, Geoff Holmes, and Talel Abdessalem. 2017. Adaptive random forests for evolving data stream classification.Machine Learning106, 9 (2017), 1469–1495
2017
-
[20]
Heitor Murilo Gomes, Anton Lee, Nuwan Gunasekara, Yibin Sun, Guil- herme Weigert Cassales, Justin Liu, Marco Heyden, Vitor Cerqueira, Maroua Bahri, Yun Sing Koh, et al. 2025. CapyMOA: efficient machine learning for data streams in python.arXiv preprint arXiv:2502.07432(2025)
Pith/arXiv arXiv 2025
-
[21]
Paulo M Gonçalves Jr, Silas GT de Carvalho Santos, Roberto SM Barros, and Davi CL Vieira. 2014. A comparative study on concept drift detectors.Expert Systems with Applications41, 18 (2014), 8144–8156
2014
-
[22]
Michael Harries, New South Wales, et al. 1999. Splice-2 comparative evaluation: Electricity pricing. (1999)
1999
-
[23]
Marco Heyden, Edouard Fouché, Vadim Arzamasov, Tanja Fenn, Florian Kalinke, and Klemens Böhm. 2024. Adaptive Bernstein change detector for high- dimensional data streams.Data Mining and Knowledge Discovery38, 3 (2024), 1334–1363
2024
-
[24]
David Tse Jung Huang, Yun Sing Koh, Gillian Dobbie, and Russel Pears. 2014. Detecting volatility shift in data streams. In2014 IEEE International Conference on Data Mining. IEEE, 863–868
2014
-
[25]
Viktor Losing, Barbara Hammer, and Heiko Wersing. 2016. KNN classifier with self adjusting memory for heterogeneous concept drift. In2016 IEEE 16th inter- national conference on data mining (ICDM). IEEE, 291–300. Table 3: Dataset summary and drift parameters # Samples # Features # Classes Max Delay Drift Width Asfault 8563 62 5 500 500 Covtype 100000 54 7...
2016
-
[26]
Kyosuke Nishida and Koichiro Yamauchi. 2007. Detecting concept drift using statistical testing. InInternational conference on discovery science. Springer, 264– 269
2007
-
[27]
Ewan S Page. 1954. Continuous inspection schemes.Biometrika41, 1/2 (1954), 100–115
1954
-
[28]
Fábio Pinto, Marco OP Sampaio, and Pedro Bizarro. 2019. Automatic model monitoring for data streams.arXiv preprint arXiv:1908.04240(2019)
arXiv 2019
-
[29]
Stuart W Roberts. 2000. Control chart tests based on geometric moving averages. Technometrics42, 1 (2000), 97–101
2000
-
[30]
Gordon J Ross, Niall M Adams, Dimitris K Tasoulis, and David J Hand. 2012. Exponentially weighted moving average charts for detecting concept drift.Pattern recognition letters33, 2 (2012), 191–198
2012
-
[31]
Raquel Sebastiao and Joao Gama. 2009. A study on change detection methods. In Progress in artificial intelligence, 14th Portuguese conference on artificial intelligence, EPIA, Vol. 2009
2009
-
[32]
Vinicius MA Souza. 2018. Asphalt pavement classification using smartphone accelerometer and complexity invariant distance.Engineering Applications of Artificial Intelligence74 (2018), 198–211
2018
-
[33]
V. M. A. Souza, D. M. Reis, A. G. Maletzke, and G. E. A. P. A. Batista. 2020. Challenges in Benchmarking Stream Learning Algorithms with Real-world Data. Data Mining and Knowledge Discovery34 (2020), 1805–1858. doi:10.1007/s10618- 020-00698-5
-
[34]
W Nick Street and YongSeog Kim. 2001. A streaming ensemble algorithm (SEA) for large-scale classification. InProceedings of the seventh ACM SIGKDD interna- tional conference on Knowledge discovery and data mining. 377–382
2001
-
[35]
Yibin Sun, Heitor Murilo Gomes, Bernhard Pfahringer, and Albert Bifet. 2025. Evaluation for Regression Analyses on Evolving Data Streams.arXiv preprint arXiv:2502.07213(2025)
arXiv 2025
-
[36]
Alexander Vergara, Shankar Vembu, Tuba Ayhan, Margaret A Ryan, Margie L Homer, and Ramón Huerta. 2012. Chemical gas sensor drift compensation using classifier ensembles.Sensors and Actuators B: Chemical166 (2012), 320–329
2012
-
[37]
Gerhard Widmer and Miroslav Kubat. 1996. Learning in the presence of concept drift and hidden contexts.Machine learning23, 1 (1996), 69–101
1996
-
[38]
Giacomo Ziffer, Federico Giannini, and Emanuele Della Valle. 2024. Tenet: Bench- marking Data Stream Classifiers in Presence of Temporal Dependence. In2024 IEEE International Conference on Big Data (BigData). IEEE, 1187–1196
2024
-
[39]
Indre Žliobaite. 2010. Change with delayed labeling: When is it detectable?. In 2010 IEEE international conference on data mining workshops. IEEE, 843–850. A Drift Simulation A.1 Simulation Framework Algorithm 1 describes the procedure for simulating drift on real- world data streams based on Monte Carlo trials. A.2 Drift Types Algorithms 2, 3, 4, and 5 d...
2010
-
[40]
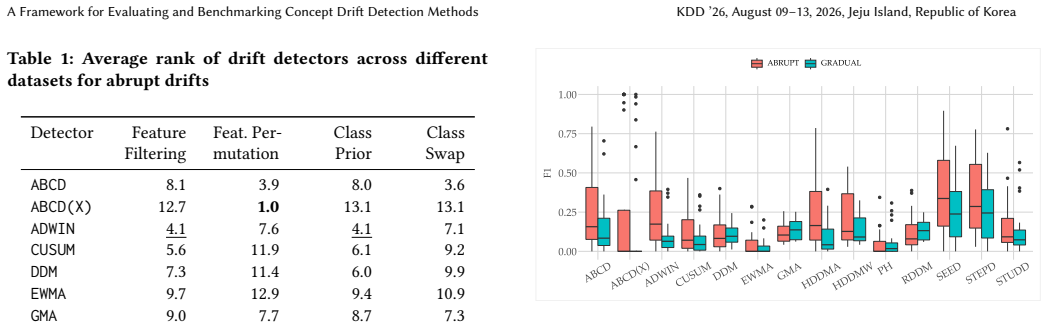
reveals different profiles across detectors and clarifies how some methods achieve similar F1 scores through different behaviors. For example, GMA exhibits a recall-dominated profile: it achieves near- perfect recall (0.97–1.0 across all drift types and abruptness condi- tions), meaning it detects almost every drift. However, its precision is among the lo...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.