Data Profiling for Change Rules
Pith reviewed 2026-06-27 19:54 UTC · model grok-4.3
The pith
Change Rules quantify sequential changes among ordered tuples in both conditions and outcomes to model trends and causal relationships.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
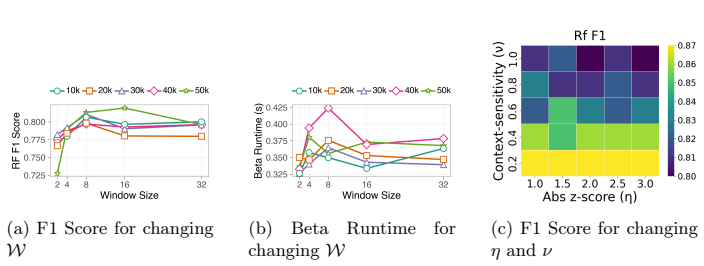
We introduce Change Rules (CRs) that quantify the sequential changes among ordered tuples in both the antecedent and consequent attributes. CRs aim to address the limitations of existing declarative dependencies to support trend analysis and causal relationships that trigger change among attributes. We propose CR-Miner, an automated algorithm for CR discovery that generates candidate change intervals in a level-wise manner. Experimental results show that CR-Miner achieves an average runtime improvement of 40-50% over existing baselines.
What carries the argument
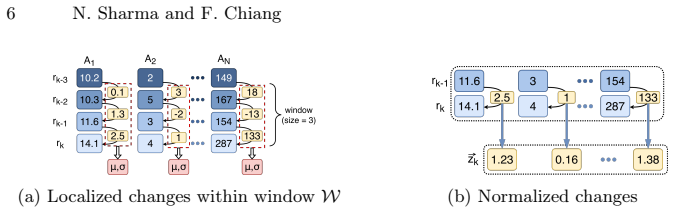
Change Rules (CRs) that quantify sequential changes among ordered tuples in both antecedent and consequent attributes, discovered by the CR-Miner algorithm through level-wise generation of candidate change intervals.
If this is right
- CRs model the context under which attribute changes occur.
- CRs support trend analysis and causal relationships that trigger change among attributes.
- CR-Miner discovers such rules with an average 40-50% runtime improvement over baselines.
- Database systems obtain improved change management through rules that handle ordered sequential changes.
Where Pith is reading between the lines
- CRs could be applied to time-stamped logs in monitoring systems to flag deviations from expected change sequences.
- Combining CRs with statistical trend models might allow prediction of future attribute shifts once the rules are learned.
- The level-wise mining approach may extend naturally to multi-attribute change patterns if candidate generation is adapted for joint intervals.
Load-bearing premise
The data consists of ordered tuples for which sequential change intervals can be meaningfully defined and that level-wise candidate generation will remain efficient without excessive pruning or false positives.
What would settle it
Running CR-Miner on an ordered dataset with independently verified ground-truth change intervals and measuring whether the output rules match the known sequential patterns without high false-positive rates.
Figures






read the original abstract
Understanding data change is critical towards understanding trends, normal vs. abnormal behaviours, recognizing patterns, and the causes of change. Existing database systems have limited support for change management, relying on statistics, triggers, and constraints. Data quality rules model sequential changes along a restricted set of attributes, quantify change among unordered tuples, and have limited ability to model the context under which attribute changes occur. In this paper, we introduce Change Rules (CRs) that quantify the sequential changes among ordered tuples in both the antecedent and consequent attributes. CRs aim to address the limitations of existing declarative dependencies to support trend analysis and causal relationships that trigger change among attributes. We propose CR-Miner, an automated algorithm for CR discovery that generates candidate change intervals in a level-wise manner. Experimental results show that CR-Miner achieves an average runtime improvement of 40-50% over existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Change Rules (CRs) as declarative dependencies that quantify sequential changes among ordered tuples in both antecedent and consequent attributes, proposes the CR-Miner algorithm that performs level-wise generation of change intervals, and reports that CR-Miner achieves 40-50% average runtime improvement over baselines in experiments. The central motivation is that existing dependencies have limited support for trend analysis and causal relationships triggering change.
Significance. A sound formalization of sequential change rules with an efficient miner could extend data-profiling techniques for ordered data. The reported runtime gains, if substantiated with full experimental details, would be a practical contribution; however, the absence of any causal-identification machinery means the 'causal relationships' framing does not add distinguishing value beyond standard co-occurrence mining.
major comments (2)
- [Abstract] Abstract: the claim that CRs 'support ... causal relationships that trigger change among attributes' is not supported by the described semantics. The approach is characterized as level-wise candidate generation on change intervals with co-occurrence quantification, which is standard association-rule style discovery and supplies no mechanism (interventions, temporal precedence with exclusion of alternatives, or confounders) that would justify a causal interpretation.
- The weakest assumption listed in the reader note (ordered tuples admit meaningful sequential change intervals and level-wise generation remains efficient) is load-bearing for the algorithm's claimed practicality, yet no analysis of pruning effectiveness, false-positive rates, or scalability on non-ideal data is referenced.
minor comments (1)
- [Abstract] The abstract supplies no information on datasets, baselines, statistical significance, or exclusion criteria for the reported 40-50% runtime improvement; these details are required to evaluate the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our paper. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CRs 'support ... causal relationships that trigger change among attributes' is not supported by the described semantics. The approach is characterized as level-wise candidate generation on change intervals with co-occurrence quantification, which is standard association-rule style discovery and supplies no mechanism (interventions, temporal precedence with exclusion of alternatives, or confounders) that would justify a causal interpretation.
Authors: We agree that the CR semantics provide co-occurrence based discovery without causal mechanisms like interventions or confounder adjustment. The abstract's reference to causal relationships was an overstatement intended to convey the utility for identifying change triggers in trends. We will revise the abstract to remove this claim and focus solely on trend analysis and sequential change quantification. revision: yes
-
Referee: [—] The weakest assumption listed in the reader note (ordered tuples admit meaningful sequential change intervals and level-wise generation remains efficient) is load-bearing for the algorithm's claimed practicality, yet no analysis of pruning effectiveness, false-positive rates, or scalability on non-ideal data is referenced.
Authors: The assumption regarding ordered tuples and efficient level-wise generation is indeed central to CR-Miner. Our experiments demonstrate runtime gains on the evaluated datasets, supporting practicality under the stated conditions. We did not provide separate analysis of pruning or false positives on non-ideal data. We will include additional discussion on these assumptions and their validity in the revised version. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces Change Rules as a new declarative dependency and presents CR-Miner as a level-wise candidate generation algorithm for mining them from ordered tuples. No equations, fitted parameters, predictions, or self-citations are described that would reduce any claimed result (such as runtime improvements) to a quantity defined by the method itself. Experimental runtime claims are benchmarked against external baselines rather than internal fits. The work is self-contained as an algorithmic proposal without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Input relations consist of ordered tuples on which sequential change intervals can be defined.
invented entities (1)
-
Change Rule (CR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the VLDB Endowment12(2), 85–98 (2018)
Bleifuß, T., Bornemann, L., Johnson, T., Kalashnikov, D.V., Naumann, F., Srivas- tava, D.: Exploring change: A new dimension of data analytics. Proceedings of the VLDB Endowment12(2), 85–98 (2018)
2018
-
[2]
Datenbank-Spektrum18, 79–87 (2018)
Bornemann, L., Bleifuß, T., Kalashnikov, D., Naumann, F., Srivastava, D.: Data change exploration using time series clustering. Datenbank-Spektrum18, 79–87 (2018)
2018
-
[3]
Celkan, T.T.: What does a hemogram say to us? Turkish Archives of Pedi- atrics/Türk Pediatri Arşivi55(2), 103 (2020)
2020
-
[4]
ACM SIGMOD Record26(2), 26–37 (1997)
Chawathe, S.S., Garcia-Molina, H.: Meaningful change detection in structured data. ACM SIGMOD Record26(2), 26–37 (1997)
1997
-
[5]
Environment and Climate Change Canada: Daily climate observations (csv) dataset.GovernmentofCanada,MeteorologicalServiceofCanadaOpenData(nd), https://dd.weather.gc.ca/today/climate/observations/daily/csv/, accessed: 2026- 04-10
2026
-
[6]
Proceedings of the VLDB Endowment2(1), 574–585 (2009)
Golab, L., Karloff, H., Korn, F., Saha, A., Srivastava, D.: Sequential dependencies. Proceedings of the VLDB Endowment2(1), 574–585 (2009)
2009
-
[7]
Heckert, N.A., Filliben, J.J., Croarkin, C.M., Hembree, B., Guthrie, W.F., Tobias, P., Prinz, J.: Handbook 151: Nist/sematech e-handbook of statistical methods (2002)
2002
-
[8]
Scientific data3(1), 1–9 (2016)
Johnson, A.E., Pollard, T.J., Shen, L., Lehman, L.w.H., Feng, M., Ghassemi, M., Moody,B.,Szolovits,P.,AnthonyCeli,L.,Mark,R.G.:Mimic-iii,afreelyaccessible critical care database. Scientific data3(1), 1–9 (2016)
2016
-
[9]
In: VLDB Workshops (2023)
Kanza, Y., Malik, R., Srivastava, D., Stone, C., Woodhull, G.: Data quality in data streams by modular change point detection. In: VLDB Workshops (2023)
2023
-
[10]
Proceedings of the VLDB Endowment17(7), 1552–1564 (2024)
Kuang, S., Yang, H., Tan, Z., Ma, S.: Efficient differential dependency discovery. Proceedings of the VLDB Endowment17(7), 1552–1564 (2024)
2024
-
[11]
In: East European Conference on Advances in Databases and Information Systems
Kwashie, S., Liu, J., Li, J., Ye, F.: Conditional differential dependencies (cdds). In: East European Conference on Advances in Databases and Information Systems. pp. 3–17. Springer (2015) Data Profiling for Change Rules 17
2015
-
[12]
Liu,F.T.,Ting,K.M.,Zhou,Z.H.:Isolationforest.In:2008eighthieeeinternational conference on data mining. pp. 413–422. IEEE (2008)
2008
-
[13]
In: Proceedings
Malhotra, P., Vig, L., Shroff, G., Agarwal, P., et al.: Long short term memory networks for anomaly detection in time series. In: Proceedings. vol. 89, p. 94 (2015)
2015
-
[14]
Big and Complex Data Analysis: Methodologies and Applications pp
Qiu, P.: Statistical process control charts as a tool for analyzing big data. Big and Complex Data Analysis: Methodologies and Applications pp. 123–138 (2017)
2017
-
[15]
In: Proceedings of the MLSDA 2014 2nd workshop on machine learning for sensory data analysis
Sakurada, M., Yairi, T.: Anomaly detection using autoencoders with nonlinear dimensionality reduction. In: Proceedings of the MLSDA 2014 2nd workshop on machine learning for sensory data analysis. pp. 4–11 (2014)
2014
-
[16]
UCI Machine Learning Repository (2018), DOI: https://doi.org/10.24432/C5B034
Salam, A., El Hibaoui, A.: Power Consumption of Tetouan City. UCI Machine Learning Repository (2018), DOI: https://doi.org/10.24432/C5B034
-
[17]
Sharma, N.: Cr-miner: Change rules discovery repository (2026), https://github.com/nishtthasharma/Change_Rules
2026
-
[18]
ACM Transactions on Database Systems (TODS)36(3), 1–41 (2011)
Song, S., Chen, L.: Differential dependencies: Reasoning and discovery. ACM Transactions on Database Systems (TODS)36(3), 1–41 (2011)
2011
-
[19]
arXiv preprint arXiv:1608.06169 (2016)
Szlichta, J., Godfrey, P., Golab, L., Kargar, M., Srivastava, D.: Effective and com- plete discovery of order dependencies via set-based axiomatization. arXiv preprint arXiv:1608.06169 (2016)
Pith/arXiv arXiv 2016
-
[20]
US Census Bureau Data (2024), https://www.census.gov/, accessed: 2026-04-10
United States Census Bureau: State naics detailed employment sizes dataset. US Census Bureau Data (2024), https://www.census.gov/, accessed: 2026-04-10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.