DD-GEPA: Prompt Optimization for Dialogue Disentanglement Focusing on Task Instruction and Utterance Representation
Pith reviewed 2026-06-27 20:55 UTC · model grok-4.3
The pith
Decomposing prompts into task instruction and utterance representation then optimizing them with GEPA raises LLM accuracy on dialogue disentanglement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
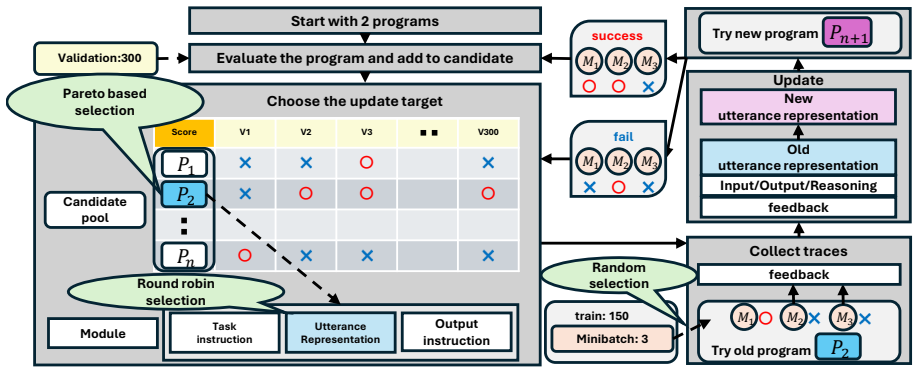
The central claim is that an automatic prompt optimization method applied after decomposing prompts into task instruction, utterance representation, and output instruction components produces prompts that improve dialogue disentanglement accuracy over the original prompts and can surpass hand-crafted prompts on benchmark datasets.
What carries the argument
GEPA, an optimization method for compound AI systems, applied after decomposing the prompt into task instruction, utterance representation, and output instruction components.
If this is right
- Optimized prompts achieve higher dialogue disentanglement accuracy than the original prompts on benchmark datasets.
- The optimized prompts can exceed the performance of hand-crafted prompts.
- The gains come from targeted optimization of the task instruction and utterance representation components.
- LLM-based dialogue disentanglement systems become more accurate at separating entangled utterance sequences without model changes.
Where Pith is reading between the lines
- The same decomposition-plus-optimization pattern could be tested on other structured output tasks such as coreference resolution in multi-speaker transcripts.
- Real-world chat logs with higher noise levels than the benchmarks might show different improvement margins.
- Replacing GEPA with alternative search methods while keeping the three-component split could isolate whether the decomposition itself drives most of the benefit.
Load-bearing premise
Decomposing the prompt into task instruction, utterance representation, and output instruction components is sufficient to allow GEPA to produce effective optimizations for the dialogue disentanglement task.
What would settle it
Evaluating the GEPA-optimized prompts on the same benchmark datasets and observing no accuracy gain or a drop relative to the original prompts would falsify the central claim.
Figures

read the original abstract
Multi-party chat often contains interleaved dialogues because multiple participants can discuss different topics at the same time. Dialogue disentanglement addresses this problem by separating an entangled utterance sequence into coherent dialogues. While large language models (LLMs) are promising for this task, they still struggle with dialogue disentanglement and achieve low accuracy. This paper proposes an automatic prompt optimization for LLM based dialogue disentanglement. We decompose the prompt into three components: task instruction, utterance representation, and output instruction, and optimize them using GEPA, an optimization method for compound AI systems. Experiments on benchmark datasets show that the optimized prompts improve dialogue disentanglement accuracy over the original prompts and can surpass hand crafted prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DD-GEPA, an automatic prompt optimization approach for LLM-based dialogue disentanglement. The prompt is decomposed into three components (task instruction, utterance representation, and output instruction) that are optimized via the GEPA method for compound AI systems. Experiments on benchmark datasets are reported to show accuracy gains over both the original prompts and hand-crafted prompts.
Significance. If the empirical results hold with appropriate controls, the work demonstrates a practical application of structured prompt decomposition and external optimization to a challenging multi-party dialogue task where standard LLM prompting underperforms. It adds to the literature on automatic prompt engineering by targeting a specific NLP problem without model fine-tuning.
minor comments (3)
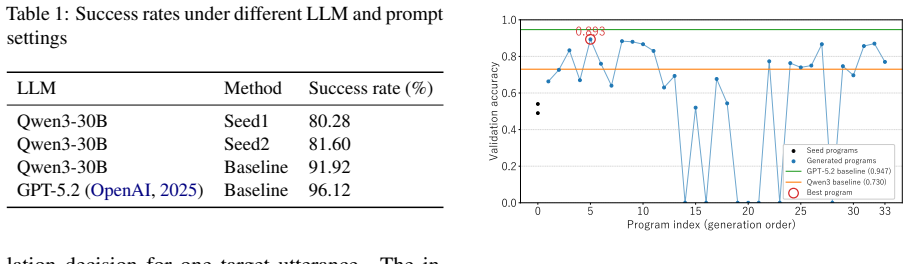
- [Abstract] Abstract: The claim of accuracy improvements is stated without any numerical results, baselines, dataset names, or statistical details; these must be supplied in the abstract or early results section for the central empirical claim to be evaluable.
- The manuscript should include an explicit description of the GEPA optimization procedure, the search space over the three prompt components, and any hyperparameters or stopping criteria used.
- Results section: Tables or figures reporting accuracy should include the original prompt, hand-crafted baselines, and the DD-GEPA variant together with error bars or multiple runs if stochasticity is present.
Simulated Author's Rebuttal
We thank the referee for the positive summary, assessment of significance, and recommendation for minor revision. No specific major comments appear in the provided report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical prompt-optimization procedure that decomposes prompts into task instruction, utterance representation, and output instruction components, then applies the external GEPA optimizer. The central claim is an experimental accuracy improvement on benchmark datasets. No equations, fitted parameters, self-citations, or derivations are present that reduce the reported result to the inputs by construction. The optimization step and accuracy metric are independent of the claim itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Title of The Article
FirstName LastName. Title of The Article. Journal of Natural Language Processing
-
[2]
Title of The Book
FirstNameA LastNameA and FirstNameB LastNameB and FirstNameC LastNameC and FirstNameD LastNameD. Title of The Book
-
[3]
著者氏名1 and 著者氏名2 and 著者氏名3. 論文タイトル. プロシーディングスの名前
-
[4]
著者氏名1 and 著者氏名2 and 著者氏名3 and 著者氏名4. 技報タイトル
-
[5]
ホームページタイトル
著者氏名. ホームページタイトル. 2017
2017
-
[6]
(2020-11閲覧)
W3C日本語組版タスクフォース.日本語組版の要件(日本語版). (2020-11閲覧)
2020
-
[7]
Patricia S. Abril and Robert Plant. The patent holder's dilemma: Buy, sell, or troll?. Communications of the ACM. 2007. doi:10.1145/1188913.1188915
-
[8]
Deciding equivalances among conjunctive aggregate queries
Sarah Cohen and Werner Nutt and Yehoshua Sagic. Deciding equivalances among conjunctive aggregate queries. 2007. doi:10.1145/1219092.1219093
-
[9]
Special issue: Digital Libraries. 1996
1996
-
[10]
Understanding Policy-Based Networking
David Kosiur. Understanding Policy-Based Networking. 2001
2001
-
[13]
The title of book two. 2008. doi:10.1007/3-540-09237-4
-
[14]
Asad Z. Spector. Achieving application requirements. Distributed Systems. 1990. doi:10.1145/90417.90738
-
[15]
Douglass and David Harel and Mark B
Bruce P. Douglass and David Harel and Mark B. Trakhtenbrot. Statecarts in use: structured analysis and object-orientation. Lectures on Embedded Systems. 1998. doi:10.1007/3-540-65193-4_29
-
[16]
Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd. ed.). 1997
1997
-
[17]
Donald E. Knuth. The Art of Computer Programming. 1998
1998
-
[18]
Structured Variational Inference Procedures and their Realizations (as incol)
Dan Geiger and Christopher Meek. Structured Variational Inference Procedures and their Realizations (as incol). Proceedings of Tenth International Workshop on Artificial Intelligence and Statistics, The Barbados
-
[19]
Stan W. Smith. An experiment in bibliographic mark-up: Parsing metadata for XML export. Proceedings of the 3rd. annual workshop on Librarians and Computers. 2010. doi:99.9999/woot07-S422
2010
-
[20]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies. 2007
2007
-
[21]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies. 2008
2008
-
[22]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies. 2009
2009
-
[23]
Sten Andler. Predicate Path expressions. Proceedings of the 6th. ACM SIGACT-SIGPLAN symposium on Principles of Programming Languages. 1979. doi:10.1145/567752.567774
-
[24]
LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER
David Harel. LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER. 1978
1978
-
[25]
Anisi , title =
David A. Anisi , title =
-
[26]
Clarkson
Kenneth L. Clarkson. Algorithms for Closest-Point Problems (Computational Geometry). 1985
1985
-
[27]
Introduction to Bayesian Statistics
Harry Thornburg. Introduction to Bayesian Statistics. 2001
2001
-
[28]
CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11
Rafal Ablamowicz and Bertfried Fauser. CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11. 2007
2007
-
[29]
Stats and Analysis
Poker-Edge.Com. Stats and Analysis. 2006
2006
-
[30]
A more perfect union
Barack Obama. A more perfect union. 2008
2008
-
[31]
The fountain of youth
Joseph Scientist. The fountain of youth. 2009
2009
-
[32]
Solder man
Dave Novak. Solder man. ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol. 145 (July 27--27, 2003). 2003. doi:99.9999/woot07-S422
2003
-
[33]
Interview with Bill Kinder: January 13, 2005
Newton Lee. Interview with Bill Kinder: January 13, 2005. Comput. Entertain. 2005. doi:10.1145/1057270.1057278
-
[34]
The Enabling of Digital Libraries
Bernard Rous. The Enabling of Digital Libraries. Digital Libraries. 2008
2008
-
[36]
(new) Finding minimum congestion spanning trees , journal =
Werneck, Renato and Setubal, Jo\. (new) Finding minimum congestion spanning trees , journal =. 2000 , issn =. doi:10.1145/351827.384253 , acmid =
-
[38]
Conti, Mauro and Di Pietro, Roberto and Mancini, Luigi V. and Mei, Alessandro , title =. Inf. Fusion , volume =. 2009 , issn =. doi:10.1016/j.inffus.2009.01.002 , acmid =
-
[39]
Li, Cheng-Lun and Buyuktur, Ayse G. and Hutchful, David K. and Sant, Natasha B. and Nainwal, Satyendra K. , title =. CHI '08 extended abstracts on Human factors in computing systems , year =. doi:10.1145/1358628.1358946 , acmid =
-
[40]
, title =
Hollis, Billy S. , title =. 1999 , isbn =
1999
-
[41]
Goossens, Michel and Rahtz, S. P. and Moore, Ross and Sutor, Robert S. , title =. 1999 , isbn =
1999
-
[42]
and Rosenberg, Arnold L
Buss, Jonathan F. and Rosenberg, Arnold L. and Knott, Judson D. , title =. 1987 , source =
1987
-
[43]
CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
, note =. CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
-
[44]
Algorithms for Closest-Point Problems (Computational Geometry) , year =
Clarkson, Kenneth Lee , advisor =. Algorithms for Closest-Point Problems (Computational Geometry) , year =
-
[45]
SIGCOMM Comput. Commun. Rev. , year =
-
[46]
IEEE TCSC Executive Committee , booktitle =. 2004 , isbn =. doi:10.1109/ICWS.2004.64 , acmid =
-
[47]
Distributed systems (2nd Ed.) , year =
-
[48]
, title =
Petrie, Charles J. , title =. 1986 , source =
1986
-
[49]
Donald E. Knuth. Seminumerical Algorithms. 1981
1981
-
[50]
E-commerce and cultural values , year =
Kong, Wei-Chang , Title =. E-commerce and cultural values , year =
-
[51]
E-commerce and cultural values , year =
Kong, Wei-Chang , type =. E-commerce and cultural values , year =
-
[52]
Chapter 9 , booktitle =
Kong, Wei-Chang , editor =. Chapter 9 , booktitle =. 2002 , address =
2002
-
[53]
E-commerce and cultural values , editor =
Kong, Wei-Chang , title =. E-commerce and cultural values , editor =. 2003 , isbn =
2003
-
[54]
E-commerce and cultural values - (InBook-num-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values - (InBook-num-in-chap) , chapter =. 2004 , address =
2004
-
[55]
E-commerce and cultural values (Inbook-text-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-text-in-chap) , chapter =. 2005 , address =
2005
-
[56]
E-commerce and cultural values (Inbook-num chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-num chap) , chapter =. 2006 , address =
2006
-
[57]
Microelectron
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi , title =. Microelectron. J. , volume =. 2010 , pages =
2010
-
[58]
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi and Zahra Sasanian , title =. J. Emerg. Technol. Comput. Syst. , volume =
-
[59]
Kirschmer, Markus and Voight, John , title =. SIAM J. Comput. , issue_date =. 2010 , issn =. doi:10.1137/080734467 , acmid =
-
[60]
Hoare, C. A. R. , title =. Structured programming (incoll) , editor =. 1972 , isbn =
1972
-
[61]
History of programming languages I (incoll) , editor =
Lee, Jan , title =. History of programming languages I (incoll) , editor =. 1981 , isbn =. doi:10.1145/800025.1198348 , acmid =
-
[62]
, title =
Dijkstra, E. , title =. Classics in software engineering (incoll) , year =
-
[63]
Wenzel, Elizabeth M. , title =. Multimedia interface design (incoll) , year =. doi:10.1145/146022.146089 , acmid =
-
[64]
, title =
Mumford, E. , title =. Critical issues in information systems research (incoll) , year =
-
[65]
and Golden, Donald G
McCracken, Daniel D. and Golden, Donald G. , title =. 1990 , isbn =
1990
-
[66]
The analysis of linear partial differential operators
H. The analysis of linear partial differential operators. 1985 , PAGES =
1985
-
[67]
IEEE", address =
A. Adya and P. Bahl and J. Padhye and A.Wolman and L. Zhou , title =. Proceedings of the IEEE 1st International Conference on Broadnets Networks (BroadNets'04) , publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[68]
I. F. Akyildiz and W. Su and Y. Sankarasubramaniam and E. Cayirci , title =. Comm. ACM , volume = 38, number = "4", year =
-
[69]
I. F. Akyildiz and T. Melodia and K. R. Chowdhury , title =. Computer Netw. , volume = 51, number = "4", year =
-
[70]
ACM", address =
P. Bahl and R. Chancre and J. Dungeon , title =. Proceeding of the 10th International Conference on Mobile Computing and Networking (MobiCom'04) , publisher = "ACM", address = "New York, NY", year =
-
[71]
8 (Special Issue on Sensor Networks)
D. Culler and D. Estrin and M. Srivastava , title =. IEEE Comput. , volume = 37, number = "8 (Special Issue on Sensor Networks)", publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[72]
Natarajan and M
A. Natarajan and M. Motani and B. de Silva and K. Yap and K. C. Chua , title =. Network Architectures , editor =. 960935712
-
[73]
Tzamaloukas and J
A. Tzamaloukas and J. J. Garcia-Luna-Aceves , title =
-
[74]
Zhou and J
G. Zhou and J. Lu and C.-Y. Wan and M. D. Yarvis and J. A. Stankovic , title =
-
[75]
Mapping Powerlists onto Hypercubes
Jacob Kornerup. Mapping Powerlists onto Hypercubes. 1994
1994
-
[76]
Automatic Parallelization for Distributed-Memory Multiprocessing Systems
Michael Gerndt. Automatic Parallelization for Distributed-Memory Multiprocessing Systems
-
[77]
J. E. Archer, Jr. and R. Conway and F. B. Schneider. User recovery and reversal in interactive systems. ACM Trans. Program. Lang. Syst
-
[78]
D. D. Dunlop and V. R. Basili. Generalizing specifications for uniformly implemented loops. ACM Trans. Program. Lang. Syst
-
[79]
Heering and P
J. Heering and P. Klint. Towards monolingual programming environments. ACM Trans. Program. Lang. Syst
-
[80]
Donald E. Knuth. The book
-
[81]
Korach and D
E. Korach and D. Rotem and N. Santoro. Distributed algorithms for finding centers and medians in networks. ACM Trans. Program. Lang. Syst
-
[82]
: A Document Preparation System
Leslie Lamport. : A Document Preparation System
-
[83]
F. Nielson. Program transformations in a denotational setting. ACM Trans. Program. Lang. Syst
-
[84]
Brian K. Reid. A high-level approach to computer document formatting. Proceedings of the 7th Annual Symposium on Principles of Programming Languages
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.