Stable Geometry, Reversing Poles: The Bipolar Structure of AI Occupational Substitutability and Its Decade-Scale Inversion
Pith reviewed 2026-06-27 19:25 UTC · model grok-4.3
The pith
AI occupational substitutability has a stable bipolar structure whose high-risk pole has inverted over a decade.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
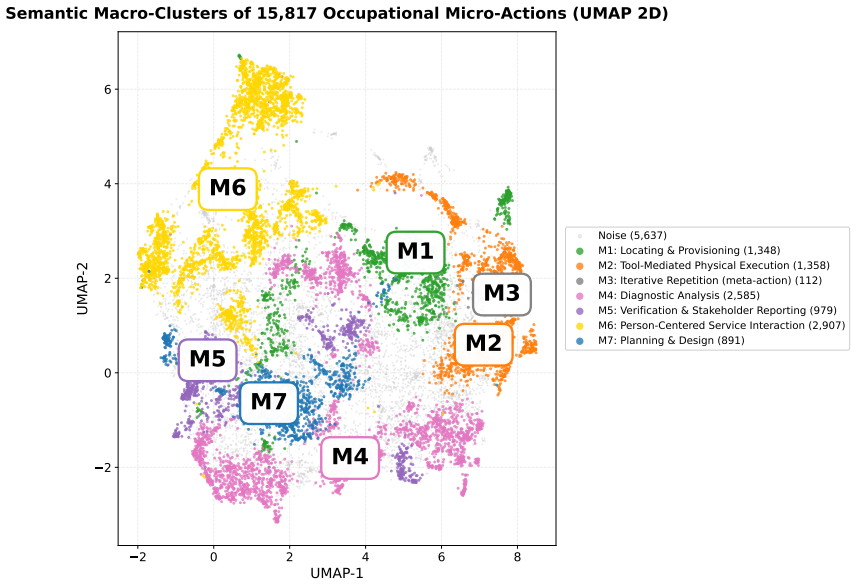
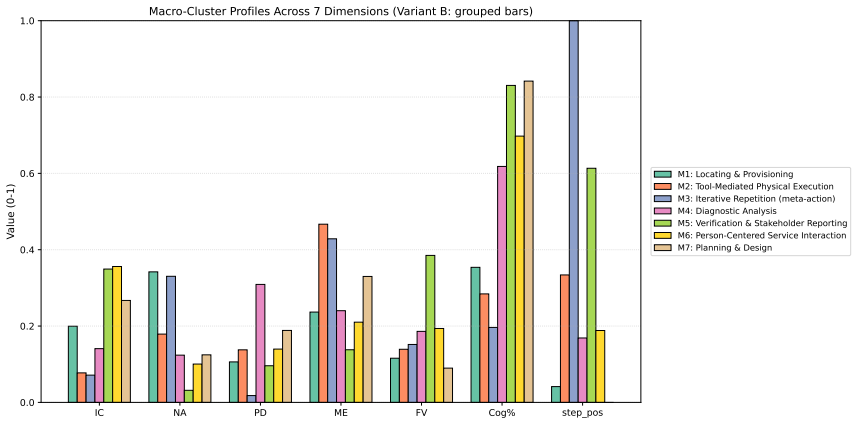
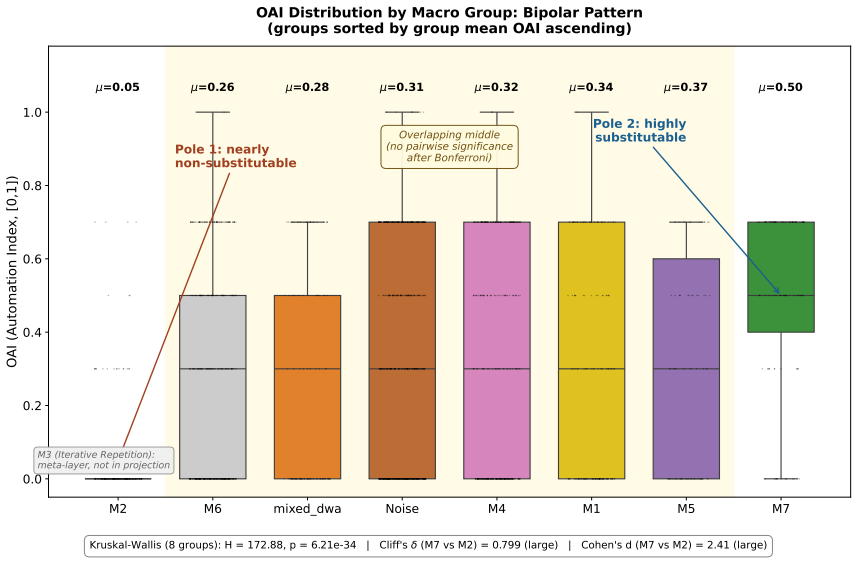
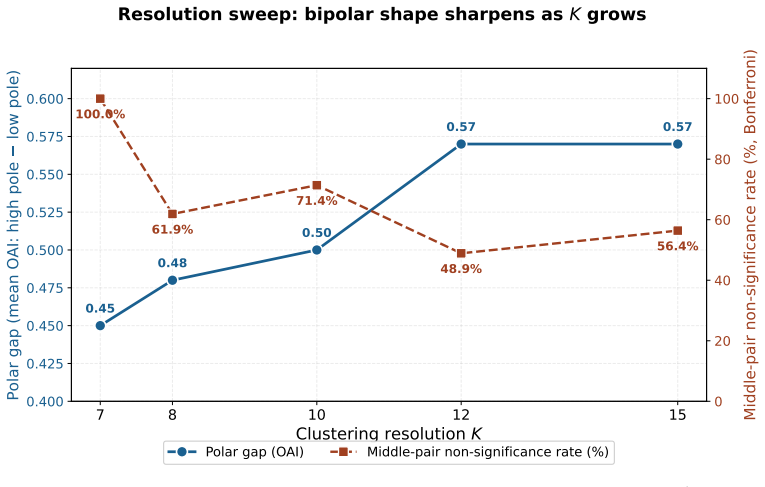
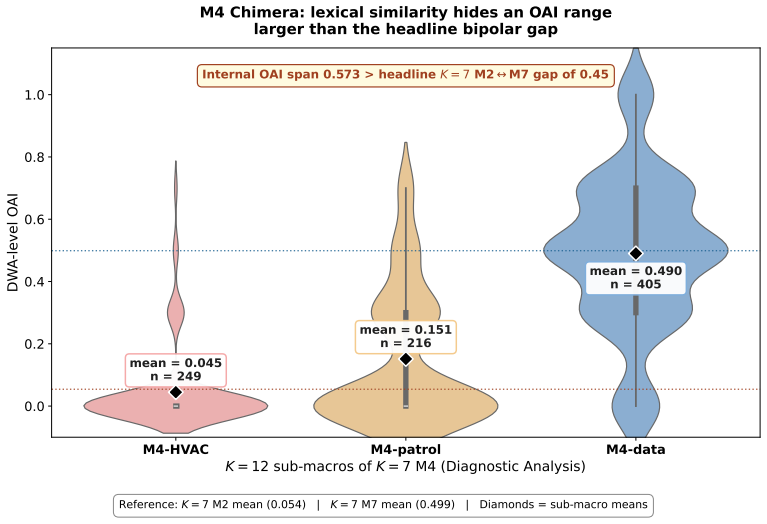
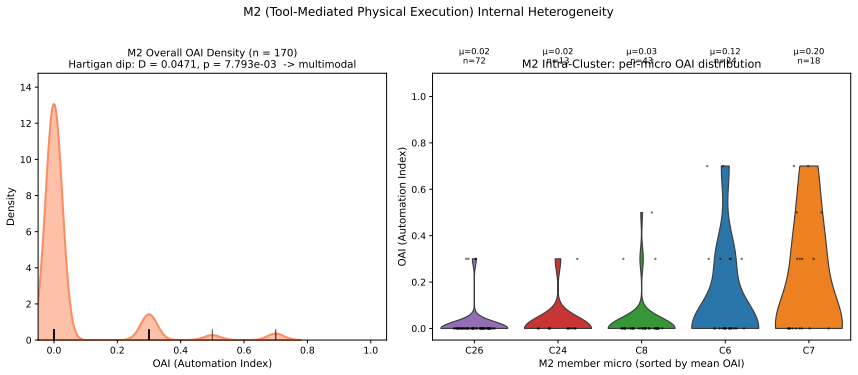
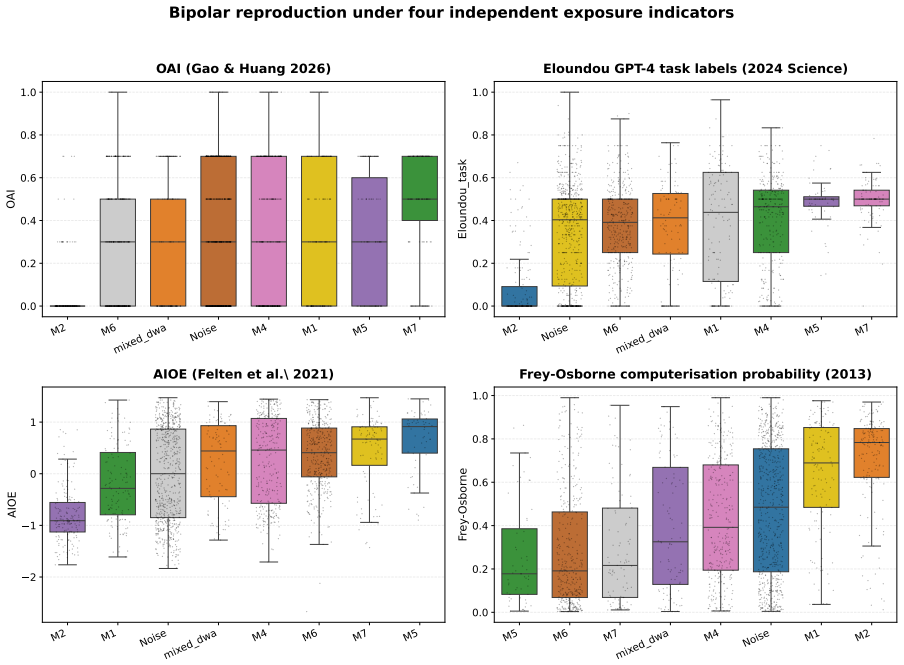
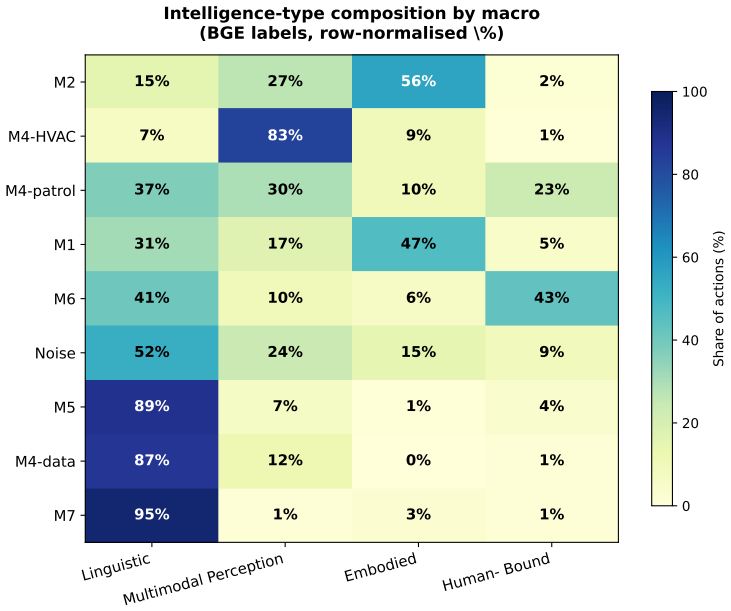
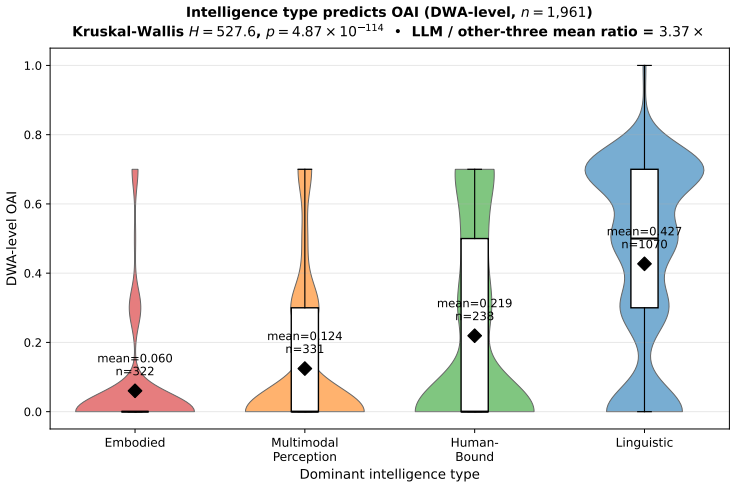
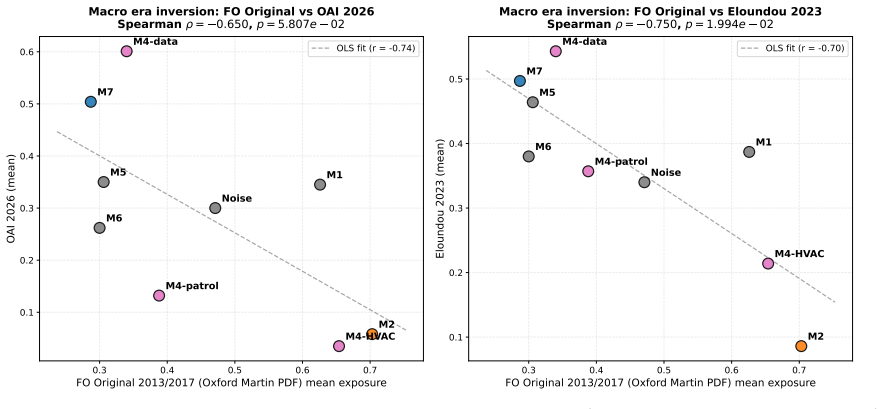
Decomposing 1,961 O*NET Detailed Work Activities into 15,817 micro-actions and projecting the prior Occupational Automation Index onto a 7-macro typology produces a bipolar geometry. Tool-Mediated Physical (mean OAI 0.054) and Planning & Design (mean OAI 0.499) sit at the extremes with Cohen's d of 2.41. The geometry remains stable when resolution increases, the encoder changes, or external ratings are used, yet the order of the poles reverses relative to Frey-Osborne rankings, shown by a macro-level Spearman correlation of -0.750.
What carries the argument
The 7-macro semantic typology applied to micro-actions from O*NET Detailed Work Activities, serving as the projection space for the Occupational Automation Index to reveal polarity.
If this is right
- The six middle macro categories form a low-contrast band with few equivalent pairs under equivalence testing.
- The bipolar gap widens when the typology is refined from 7 to 15 categories.
- Alternative encoders and external task ratings replicate the same lead for the LLM-based OAI at the poles.
- The inversion means that earlier high computerisation risk for physical tasks now corresponds to low exposure in current projections.
Where Pith is reading between the lines
- If the bipolar pattern persists at finer scales, labor analyses could shift from ranking all jobs on one axis to tracking two distinct frontiers.
- Policy responses might need to address the moving target of which pole faces higher substitution as AI improves in different domains.
- Replicating the decomposition on updated O*NET data could test whether the geometry continues to hold or begins to erode.
Load-bearing premise
The 7-macro typology derived from the LLM pipeline with expert calibration accurately reflects distinct substitutability dimensions at the level of individual micro-actions.
What would settle it
Human-coded automation exposure scores on the full set of micro-actions that do not produce a statistically significant separation between the Tool-Mediated Physical and Planning & Design groups.
Figures
read the original abstract
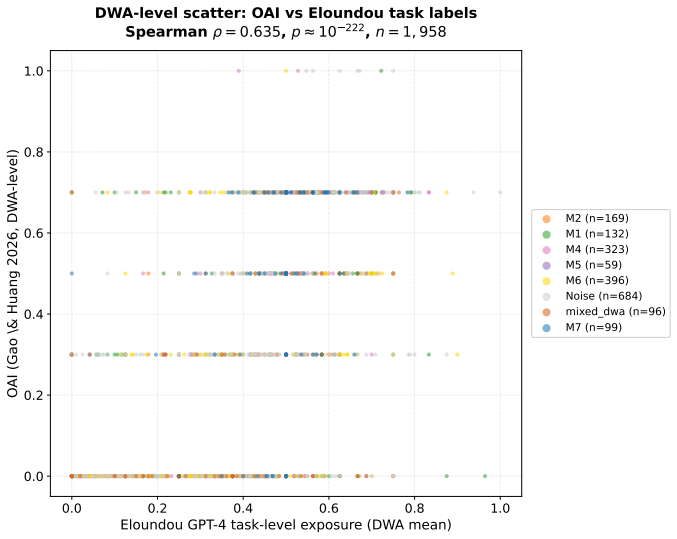
Empirical research on the labor-market impact of artificial intelligence has converged, since Frey and Osborne (2017), on a continuous-gradient representation in which each occupation is assigned a real-valued exposure score on [0,1] obtained by linear aggregation across capability dimensions. This continuity is rarely articulated as an assumption and has not been tested at the micro-action level where substitution actually occurs. We decompose 1,961 O*NET Detailed Work Activities into 15,817 micro-actions using a multi-agent LLM pipeline with 31-expert HITL calibration, then project the DWA-level Occupational Automation Index from our prior work onto a 7-macro semantic typology. The result is a bipolar structure. Tool-Mediated Physical (M2, mean OAI = 0.054) and Planning & Design (M7, mean OAI = 0.499) form two extremes separated by Cohen's d = 2.41 (H = 172.88, p = 6.21e-34). The geometry is robust under three independent stress tests: resolution (K=7 to K=15, polar gap widens from 0.45 to 0.57), encoder swap to BGE (LLM-class OAI lead replicates at 3.37x), and Eloundou's GPT-4 task ratings (DWA-level rho = 0.635). The six middle macros form a low-contrast band between the poles (TOST at d=0.2 admits only 1/15 pairs as equivalent), not a flat plain. The geometry's stability does not, however, extend to its content. Across a decade, the polarity has inverted. Frey-Osborne (2013) placed Tool-Mediated Physical near the highest computerisation risk and Planning & Design near the lowest; our LLM-era OAI reverses that order, with macro-level FO-Eloundou Spearman rho = -0.750, p = 0.020, against the original Oxford Martin appendix. Which pole is high is therefore contingent on the era's dominant capability frontier, while the stable geometry itself is the structurally robust object.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper decomposes 1,961 O*NET Detailed Work Activities into 15,817 micro-actions via a multi-agent LLM pipeline with 31-expert HITL calibration, projects the authors' prior Occupational Automation Index (OAI) onto a custom 7-macro semantic typology, and reports a stable bipolar geometry: Tool-Mediated Physical (M2, mean OAI=0.054) and Planning & Design (M7, mean OAI=0.499) are separated by Cohen's d=2.41 (H=172.88, p=6.21e-34). The geometry is robust to three stress tests, the six middle macros form a low-contrast band, and the polarity inverts relative to Frey-Osborne (2013) with macro-level Spearman rho=-0.750 (p=0.020).
Significance. If validated, the result would demonstrate that occupational substitutability is not a flat continuous gradient but exhibits stable bipolar structure whose content (which pole is high-risk) is era-dependent, offering a falsifiable alternative to linear aggregation models and a framework for tracking capability-frontier shifts.
major comments (3)
- [Methods (LLM pipeline and typology construction)] Methods (LLM pipeline and typology construction): The reported means, Cohen's d=2.41, and bipolar claim rest on assignment of 15,817 micro-actions to the 7 macros; no inter-annotator agreement, error rates, confusion matrix, or released labeled dataset from the 31-expert HITL calibration is supplied, so systematic bias in micro-action bucketing cannot be ruled out and directly affects the polarity and inversion results.
- [Results (inversion and FO comparison)] Results (inversion and FO comparison): The decade-scale inversion is quantified by macro-level FO-Eloundou Spearman rho=-0.750 (p=0.020) on 7 categories; with such small N the result is sensitive to the custom typology choice and to any projection artifacts from the prior OAI, yet no bootstrap, leave-one-macro-out, or alternative grouping robustness check is reported.
- [Stress tests section] Stress tests section: The three stress tests (K=7 o15 resolution, BGE encoder swap, Eloundou GPT-4 ratings) are invoked to support robustness, but quantitative outcomes (e.g., exact polar-gap values, replication of d=2.41, or classification agreement metrics) are only partially stated, leaving open whether they address LLM-induced classification bias.
minor comments (2)
- [Abstract] Abstract: the phrase 'three independent stress tests' is used without naming them or giving the key numeric outcomes (polar gap widening, 3.37x lead); a one-sentence enumeration would aid readability.
- [Notation] Notation: OAI is referenced before its first full expansion in some passages; ensure consistent first-use definition throughout.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We provide point-by-point responses below and commit to revisions where appropriate to address the concerns raised.
read point-by-point responses
-
Referee: Methods (LLM pipeline and typology construction): The reported means, Cohen's d=2.41, and bipolar claim rest on assignment of 15,817 micro-actions to the 7 macros; no inter-annotator agreement, error rates, confusion matrix, or released labeled dataset from the 31-expert HITL calibration is supplied, so systematic bias in micro-action bucketing cannot be ruled out and directly affects the polarity and inversion results.
Authors: We agree that additional details on the HITL calibration would strengthen the manuscript. In the revised version, we will include inter-annotator agreement statistics, a confusion matrix, and error rates from the 31-expert process. The labeled dataset will also be released publicly to allow independent verification. These additions will help rule out systematic bias in the micro-action assignments. revision: yes
-
Referee: Results (inversion and FO comparison): The decade-scale inversion is quantified by macro-level FO-Eloundou Spearman rho=-0.750 (p=0.020) on 7 categories; with such small N the result is sensitive to the custom typology choice and to any projection artifacts from the prior OAI, yet no bootstrap, leave-one-macro-out, or alternative grouping robustness check is reported.
Authors: The small sample size for the correlation is a valid concern. We will add bootstrap resampling to provide confidence intervals for the Spearman rho and perform a leave-one-macro-out sensitivity analysis in the revised results section. This will quantify the robustness of the inversion finding to the specific typology and any projection effects. revision: yes
-
Referee: Stress tests section: The three stress tests (K=7 to 15 resolution, BGE encoder swap, Eloundou GPT-4 ratings) are invoked to support robustness, but quantitative outcomes (e.g., exact polar-gap values, replication of d=2.41, or classification agreement metrics) are only partially stated, leaving open whether they address LLM-induced classification bias.
Authors: We will expand the stress tests section to include full quantitative details, such as the exact polar-gap values under each test, confirmation of d=2.41 replication where applicable, and classification agreement metrics between the LLM pipeline and expert ratings. This will more explicitly demonstrate that the tests mitigate concerns about LLM-induced bias. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation projects a DWA-level OAI taken from prior work onto a 7-macro semantic typology obtained by LLM decomposition of 15,817 micro-actions. The reported means (M2 = 0.054, M7 = 0.499), Cohen's d = 2.41, and macro-level Spearman rho = -0.750 with FO are computed outputs from this projection and external comparison; they are not equivalent to the inputs by construction. The typology is defined semantically rather than fitted to maximize separation on OAI, the stress tests (resolution, encoder swap, Eloundou ratings) are independent robustness checks, and the polarity inversion is measured against the external Frey-Osborne benchmark. No self-definitional equations, fitted-input predictions, or load-bearing self-citations that collapse the central claim appear in the provided text. The chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of macro categories (K)
axioms (2)
- standard math Cohen's d, Kruskal-Wallis H, and TOST equivalence tests are appropriate for comparing OAI distributions across the 7 macros
- domain assumption The 7-macro semantic typology partitions substitutability dimensions without systematic bias from LLM classification
Reference graph
Works this paper leans on
-
[1]
Tasks, Automation, and the Rise in U.S
Daron Acemoglu and Pascual Restrepo. Tasks, Automation, and the Rise in U.S. Wage Inequality. Econometrica, 90(5):1973–2016,
1973
-
[2]
Deming and Kadeem Noray
David J. Deming and Kadeem Noray. Earnings Dynamics, Changing Job Skills, and STEM Careers.The Quarterly Journal of Economics, 135(4):1965–2005,
1965
-
[3]
DOI 10.1126/sci- ence.adj0998. Data files used in this paper are taken from the 2023 working-paper release (arXiv:2303.10130); references to “Eloundou et al. 2023” in the body text refer to the vintage of the underlying GPT-4 task ratings rather than to the publication year. Martha S. Feldman and Brian T. Pentland. Reconceptualizing organizational routine...
-
[4]
Working-paper antecedent of Frey and Osborne (2017). Cited here for the 702-row appendix table parsed programmatically in this paper’s external-indicator alignment; the published 2017 version contains the identical probability values (verified at Spearmanρ= 1.000across 653 matched SOCs). Carl Benedikt Frey and Michael A. Osborne. The Future of Employment:...
2017
-
[5]
arXiv:2604.04464. Paweł Gmyrek, Janine Berg, and David Bescond. Generative AI and Jobs: A Global Analysis of Potential Effects on Job Quantity and Quality. ILO Working Paper 96, International Labour Organization,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
How Exposed Are UK Jobs to Generative AI? Developing and Applying a Novel Task-Based Index
arXiv:2507.22748. Lucija Ivančić, Dalia Suša Vugec, and Vesna Bosilj Vukšić. Robotic Process Automation: Systematic Literature Review. In Claudio Di Ciccio et al., editors,Business Process Man- agement: Blockchain and Central and Eastern Europe Forum (BPM 2019), volume 361 of Lecture Notes in Business Information Processing, pages 280–295. Springer, Cham,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Leland McInnes, John Healy, and James Melville
DOI 10.1007/978-3-030-30429-4_19. Leland McInnes, John Healy, and James Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.arXiv preprint,
-
[9]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
arXiv:1802.03426. Rachel Metz. OpenAI Sets Levels to Track Progress Toward Superintelligent AI. Bloomberg News, jul
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Re- ports OpenAI’s five-stage internal classification: Chatbots, Reasoners, Agents, Inno- vators, Organizations
Industry framework; non-peer-reviewed. Re- ports OpenAI’s five-stage internal classification: Chatbots, Reasoners, Agents, Inno- vators, Organizations. URL: https://www.bloomberg.com/news/articles/2024-07-11/ openai-sets-levels-to-track-progress-toward-superintelligent-ai. Henry Mintzberg.The Nature of Managerial Work. Harper & Row, New York,
2024
- [11]
-
[12]
URL: https://www.oecd.org/en/publications/2025/06/ introducing-the-oecd-ai-capability- indicators_7c0731f0.html
Nine ability domains ×five capability levels. URL: https://www.oecd.org/en/publications/2025/06/ introducing-the-oecd-ai-capability- indicators_7c0731f0.html. Edith T. Penrose.The Theory of the Growth of the Firm. Basil Blackwell, Oxford,
2025
-
[13]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China,
2019
-
[14]
DOI 10.1145/3626772.3657878. Working-paper antecedent: arXiv:2309.07597 (2023). The BGE family (BAAI/bge-large-en-v1.5) is released as part of this package. AK= 5Robustness Cut The headlineK = 7partition (§3.4) was selected on dendrogram inspection of natural breakpoints. As a robustness backup, we report the raw Ward output atK = 5(the next informative c...
-
[15]
review the operational manual
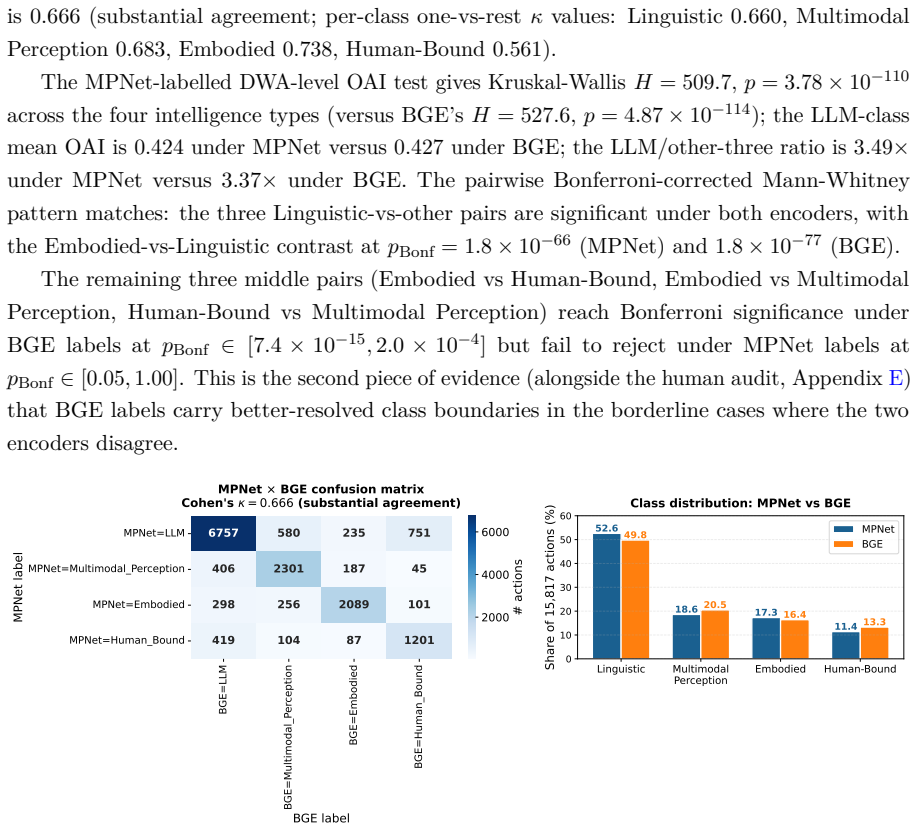
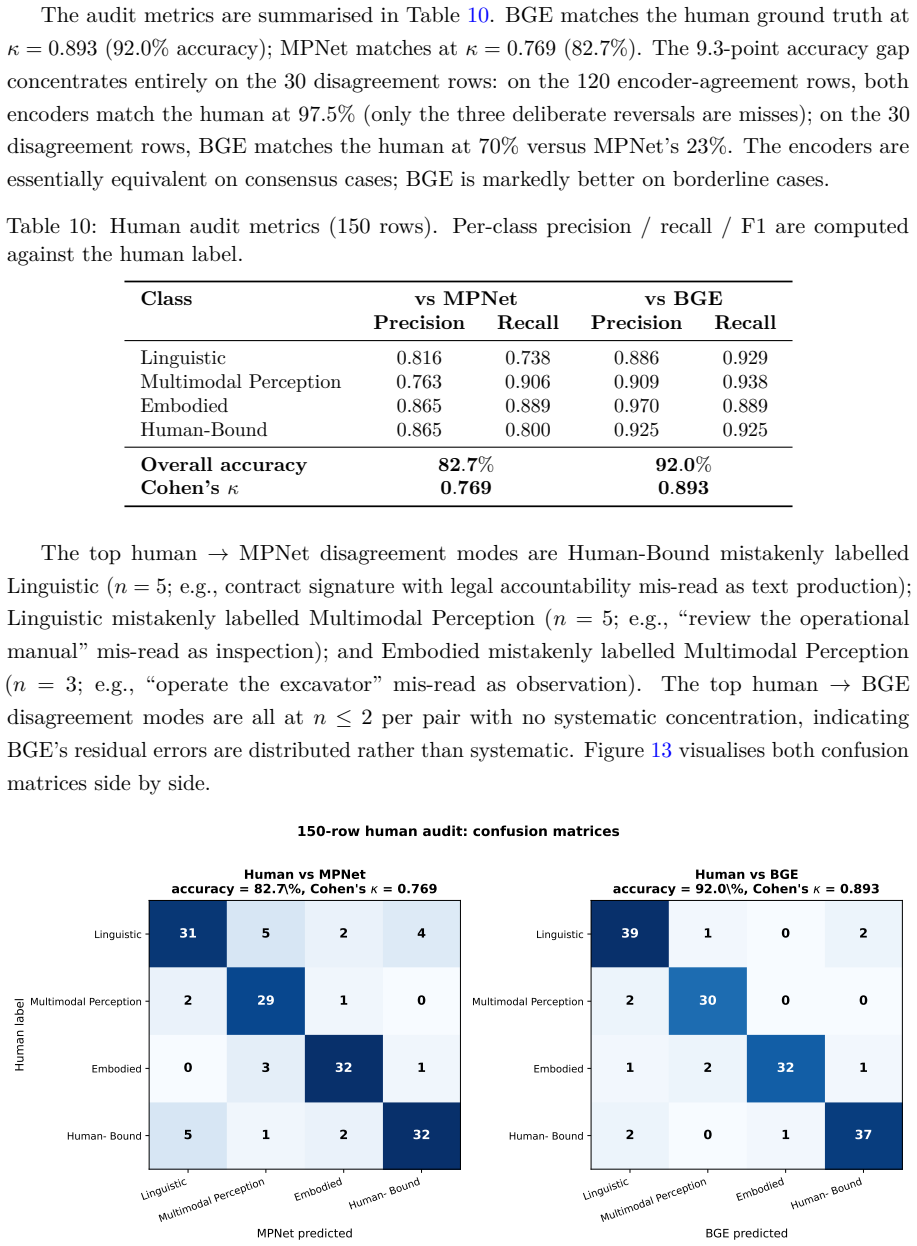
BGE matches the human ground truth at κ= 0.893(92 .0%accuracy); MPNet matches atκ= 0.769(82 .7%). The 9.3-point accuracy gap concentrates entirely on the 30 disagreement rows: on the 120 encoder-agreement rows, both encoders match the human at97.5%(only the three deliberate reversals are misses); on the 30 disagreement rows, BGE matches the human at70%ver...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.