SGTO-MAS: Secure Gorilla Troops Optimization for Multi-Agent LLM Systems
Pith reviewed 2026-06-27 19:53 UTC · model grok-4.3
The pith
Adapting Gorilla Troops Optimization with trust and risk modeling solves constrained multi-agent LLM coordination problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that multi-agent LLM coordination reduces to a constrained optimization problem whose solution is found by a security-aware variant of Gorilla Troops Optimization; this variant unifies trust modeling, risk-aware evaluation, and collective intelligence inside a single objective, yielding adaptive agent subsets that maintain stable performance, high consensus, and bounded risk across independent runs.
What carries the argument
Security-aware Gorilla Troops Optimization (SGTO) for multi-agent selection, which embeds trust and risk terms into the swarm update rules to jointly optimize performance, security, and subset size.
If this is right
- Agent subsets remain compact (around four members) while consensus stays above 0.87 and risk stays at 0.3.
- Optimization finishes in roughly 24 seconds per run with score standard deviation below 0.02.
- Performance degrades by at most 5 percent when agents are removed or consensus is disrupted.
- The same framework produces stable results across 500 independent trials under controlled threat variation.
Where Pith is reading between the lines
- The same trust-plus-risk formulation could be swapped into other swarm algorithms to test whether GTO is essential or whether any population-based optimizer suffices.
- Extending the objective to include latency or energy cost would show whether the current compact-subset result generalizes to resource-constrained deployments.
- The reported graceful degradation suggests the method could be combined with dynamic agent addition protocols without resetting the optimization state.
Load-bearing premise
The adapted Gorilla Troops Optimization algorithm can reliably locate solutions to the constrained coordination problem under varying threats without post-hoc parameter adjustments that produce the reported metrics.
What would settle it
Running the method on fresh threat models or LLM configurations and observing that average performance falls below 0.45, consensus below 0.80, or selected agent count exceeds 8 while risk exceeds 0.40.
Figures


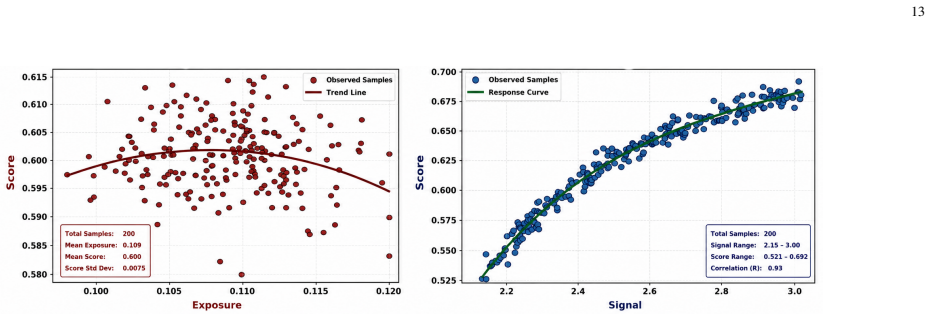
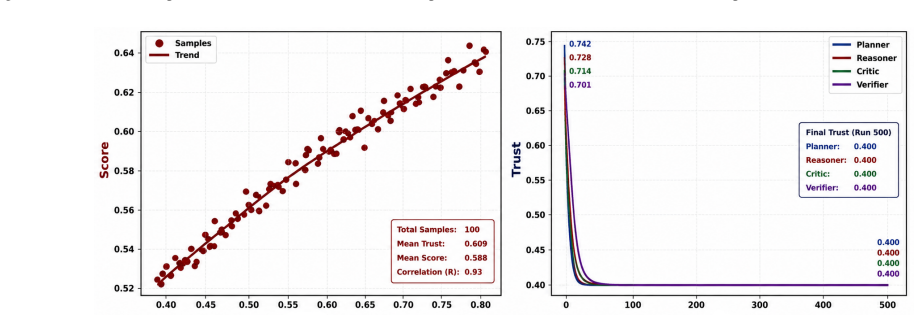
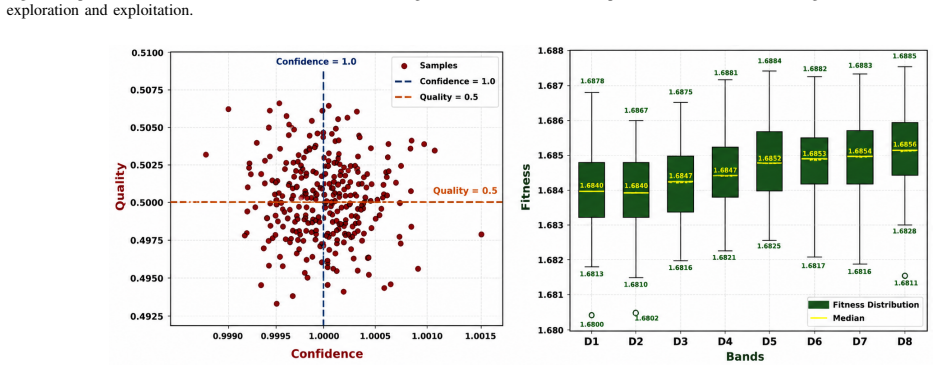

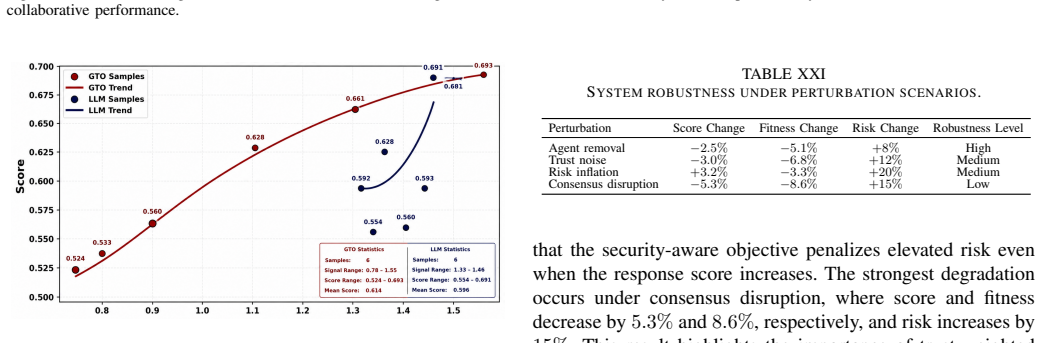

read the original abstract
Multi-agent large language model (LLM) systems offer strong capabilities for complex reasoning and decision-making, yet coordination across agents introduces error propagation, security risks, and inefficient use of resources. Existing methods often rely on heuristic, static strategies and lack a principled mechanism for balancing performance, security, and computational cost. This paper formulates multi-agent LLM coordination as a constrained optimization problem and proposes a security-aware method for adaptive agent selection. The method integrates trust modeling, risk-aware evaluation, and collective intelligence within a unified optimization objective. To solve the problem efficiently, we use a swarm-intelligence strategy inspired by Gorilla Troops Optimization (GTO), enabling adaptive coordination under varying threat conditions. Controlled experiments across 500 independent runs demonstrate the effectiveness of the proposed method. The system achieves a stable average performance score of 0.5281, with high consensus (0.8764), controlled risk (0.3000), and compact agent subsets averaging 4.04 selected agents. The optimization process converges efficiently, with an average runtime of 24.09 seconds per run and low score variability (standard deviation = 0.0173). Robustness analysis indicates graceful degradation under perturbations, with performance drops limited to 2.5% under agent removal and 5.3% under consensus disruption. These results show that effective multi-agent coordination can be achieved through structured optimization that jointly manages performance, security, and efficiency. The proposed method provides a practical security-aware solution for coordinating multi-agent LLM systems in complex adversarial settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SGTO-MAS, a method that formulates multi-agent LLM coordination as a constrained optimization problem and solves it using a security-aware adaptation of Gorilla Troops Optimization incorporating trust modeling and risk-aware evaluation. It reports results from 500 independent runs demonstrating average performance score of 0.5281, consensus of 0.8764, risk of 0.3000, average of 4.04 selected agents, runtime of 24.09 seconds, and robustness with small performance drops under perturbations.
Significance. The approach of using swarm intelligence for secure multi-agent LLM coordination could be significant for practical deployment in adversarial settings if the claims hold. The experimental design with 500 runs, reporting of standard deviation, and robustness analysis are strengths that provide some reproducibility. However, the absence of baseline comparisons limits the ability to assess the advance over existing methods.
major comments (3)
- [Abstract] Abstract: the performance score of 0.5281 is presented without definition or explanation of how it is computed from the unified objective of performance, security, and cost.
- [Abstract] Abstract: no comparisons to the heuristic or static strategies referenced in the introduction are reported, so the effectiveness claim relative to alternatives cannot be evaluated.
- [Abstract] Abstract: the specific tasks, threat models, and precise definitions of the consensus (0.8764) and risk (0.3000) metrics are absent, which is load-bearing for interpreting the 500-run results and robustness claims.
minor comments (1)
- [Abstract] Abstract: the phrase 'graceful degradation' is used without specifying the exact perturbation levels or experimental protocol for agent removal and consensus disruption.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below and will revise the manuscript accordingly to enhance clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance score of 0.5281 is presented without definition or explanation of how it is computed from the unified objective of performance, security, and cost.
Authors: We agree this definition is needed for interpretability in the abstract. The performance score is a normalized weighted combination drawn from the unified objective (performance + security - cost) as defined in Section 3. We will revise the abstract to include a concise explanation of this computation. revision: yes
-
Referee: [Abstract] Abstract: no comparisons to the heuristic or static strategies referenced in the introduction are reported, so the effectiveness claim relative to alternatives cannot be evaluated.
Authors: The experiments focus on absolute metrics and robustness across 500 runs rather than explicit baselines. We acknowledge the limitation for assessing relative advance and will add comparisons to the referenced heuristic and static strategies in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the specific tasks, threat models, and precise definitions of the consensus (0.8764) and risk (0.3000) metrics are absent, which is load-bearing for interpreting the 500-run results and robustness claims.
Authors: We will revise the abstract to incorporate brief definitions of the consensus and risk metrics along with a high-level description of the tasks and threat models. Full formal definitions and experimental setup appear in Sections 4 and 5. revision: yes
Circularity Check
No circularity; empirical validation independent of any derivation chain
full rationale
The provided abstract formulates multi-agent coordination as a constrained optimization problem and adopts a swarm-intelligence strategy inspired by existing GTO, then reports performance metrics obtained from 500 independent experimental runs. No equations, fitted parameters, or self-citations appear that would reduce the reported scores (0.5281 performance, 0.8764 consensus, etc.) to algebraic identities or prior author work by construction. The results are presented as direct simulation outputs rather than predictions forced by the method's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Foundation models and intelligent decision-making: Progress, challenges, and perspectives,
J. Huang, Y . Xu, Q. Wang, Q. C. Wang, X. Liang, F. Wang, Z. Zhang, W. Wei, B. Zhang, L. Huanget al., “Foundation models and intelligent decision-making: Progress, challenges, and perspectives,”The Innova- tion, vol. 6, no. 6, 2025
2025
-
[2]
On the planning abilities of large language models-a critical investigation,
K. Valmeekam, M. Marquez, S. Sreedharan, and S. Kambhampati, “On the planning abilities of large language models-a critical investigation,” Advances in neural information processing systems, vol. 36, pp. 75 993– 76 005, 2023
2023
-
[3]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
K. Tran, M. Nguyenet al., “Large language model based multi-agents: A survey,”arXiv preprint arXiv:2308.10848, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Llm-based multi-agent decision-making: Challenges and future directions,
Y . Sunet al., “Llm-based multi-agent decision-making: Challenges and future directions,”IEEE Robotics and Automation Letters, 2025
2025
-
[5]
Agentnet: Decentralized evolutionary coordination for llm-based multi- agent systems,
Y . Yang, H. Chai, S. Shao, Y . Song, S. Qi, R. Rui, and W. Zhang, “Agentnet: Decentralized evolutionary coordination for llm-based multi- agent systems,”Advances in Neural Information Processing Systems, vol. 38, pp. 107 309–107 336, 2026
2026
-
[6]
Llm-based multi-agent systems: Frameworks, evaluation, open challenges, and research frontiers,
S. H. Shaikh, “Llm-based multi-agent systems: Frameworks, evaluation, open challenges, and research frontiers,” inInternational Joint Confer- ence on Computational Intelligence. Springer, 2025, pp. 149–170
2025
-
[7]
A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y . Wu, and Y . Yang, “A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, vol. 1, no. 1, p. 9, 2024
2024
-
[8]
On the risk of hallucination propagation in multi-agent llm systems,
X. Zhanget al., “On the risk of hallucination propagation in multi-agent llm systems,”arXiv preprint arXiv:2402.00000, 2024
-
[9]
Managing uncertainty in multi-agent large language model systems,
J. Lianget al., “Managing uncertainty in multi-agent large language model systems,”arXiv preprint arXiv:2405.00000, 2024
-
[10]
Malf: A multi-agent llm framework for intelligent fuzzing of industrial control protocols,
B. Ning, X. Zong, and K. He, “Malf: A multi-agent llm framework for intelligent fuzzing of industrial control protocols,”arXiv preprint arXiv:2510.02694, 2025
-
[11]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024
2024
-
[12]
Camel: Communicative agents for
G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for” mind” exploration of large language model society,”Advances in neural information processing systems, vol. 36, pp. 51 991–52 008, 2023
2023
-
[13]
From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,
M. A. Ferraget al., “From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,”Internet of Things and Cyber- Physical Systems, 2025
2025
-
[14]
Artificial gorilla troops optimizer,
N. Van Thieu and L. Van Quan, “Artificial gorilla troops optimizer,” in Encyclopedia of Engineering Optimization and Heuristics. Springer, 2026, pp. 1–9
2026
-
[15]
Llm-based multi-agent systems for software engineering: Literature review and vision,
J. He, C. Treude, and D. Lo, “Llm-based multi-agent systems for software engineering: Literature review and vision,”ACM Computing Surveys, 2025
2025
-
[16]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wuet al., “Autogen: Enabling next-gen llm applications via multi- agent conversation,”arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Camel: Communicative agents for mind exploration of llm society,
G. Liet al., “Camel: Communicative agents for mind exploration of llm society,” inNeurIPS, 2023
2023
-
[18]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Y . Duet al., “Improving factuality and reasoning in language models through multiagent debate,”arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Llm-powered ai agent systems and their applications in industry,
G. Liang and Q. Tong, “Llm-powered ai agent systems and their applications in industry,”IEEE, 2025
2025
-
[20]
An in-depth survey of the artificial gorilla troops optimizer: outcomes, variations, and applications
A. G. Hussien, A. Bouaouda, A. Alzaqebah, S. Kumar, G. Hu, and H. Jia, “An in-depth survey of the artificial gorilla troops optimizer: outcomes, variations, and applications.”Artificial intelligence review, vol. 57, no. 9, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.