Customer-Agent: Overcoming Context Limitations in Ultra-Long Shopping Trajectories via Tool-Augmented Agents and RLVR
Pith reviewed 2026-06-27 20:03 UTC · model grok-4.3
The pith
An RLVR-trained agent stores ultra-long shopping trajectories externally and retrieves them via code tools to bypass LLM context windows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
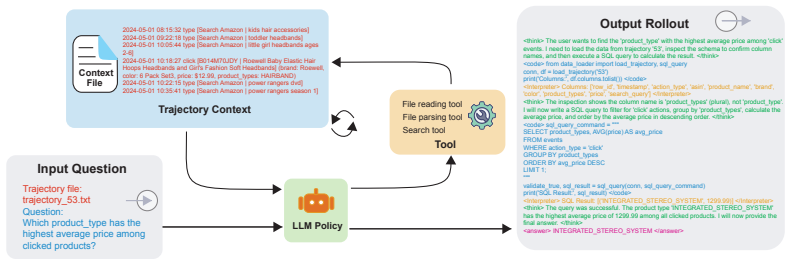
The Customer Agent Framework stores trajectories as external local files and trains the agent via an RLVR paradigm to autonomously retrieve and parse them through code-interpreter interactions such as SQL queries, thereby bypassing the fixed in-context window constraints of LLMs while delivering strong performance on ShopTrajQA and generalizing to other complex reasoning tasks.
What carries the argument
The RLVR-trained Customer Agent that issues code-interpreter calls to query and analyze externally stored trajectory files.
If this is right
- The framework produces strong results on the 32k- and 64k-token variants of ShopTrajQA.
- Performance generalizes beyond shopping to other complex reasoning tasks.
- Trajectories longer than any fixed context window become usable without truncation.
- External storage plus tool calls replace the need to fit entire histories inside the model prompt.
Where Pith is reading between the lines
- The same external-file-plus-code-tool pattern could be applied to other long sequential domains such as medical visit histories or financial transaction logs.
- Success would reduce pressure to train ever-larger context windows by shifting the burden to reliable tool use.
- The RLVR training loop may scale to agents that manage datasets orders of magnitude larger than current context limits allow.
Load-bearing premise
The premise that an agent can be trained to reliably formulate and execute code queries that retrieve the correct trajectory segments without introducing retrieval or execution errors.
What would settle it
A controlled test on ShopTrajQA where the agent receives queries requiring multi-table joins or time-range filters and either generates invalid SQL or yields lower accuracy than a baseline LLM given the full trajectory in context.
Figures




read the original abstract
Understanding customer shopping trajectories is essential for enabling personalized shopping experiences. However, shopping records (i.e., customer's search, clicks, purchases, etc.) often span long time horizons over multiple years, resulting in extremely long trajectories that pose significant challenges for existing large language models (LLMs). Despite the importance of this problem, existing benchmarks are limited to short customer trajectories, while real-world trajectories from large e-commerce platforms are rarely accessible due to data privacy constraints. To address this gap, we introduce ShopTrajQA, a long-context evaluation benchmark constructed from real-world product information and simulated shopping trajectories. The dataset includes variants of up to 32k and 64k tokens, enabling systematic evaluation of model robustness under varying context lengths. Through comprehensive benchmarking of frontier LLMs, we identify critical performance gaps in reasoning over long shopping trajectory data. To address these challenges, we propose a Customer Agent Framework for ultra-long context management. Leveraging a Reinforcement Learning with Verifiable Rewards (RLVR) agentic training paradigm, our approach stores trajectories as external local files and trains the agent to autonomously retrieve and parse them through code-interpreter interactions (e.g., SQL queries), effectively bypassing the fixed in-context window constraints of LLMs. Experimental results demonstrate that our framework achieves strong performance for ShopTrajQA and shows generalization to other complex reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShopTrajQA, a benchmark constructed from real-world product data and simulated shopping trajectories with variants up to 32k and 64k tokens, benchmarks frontier LLMs to identify reasoning gaps on long contexts, and proposes the Customer Agent Framework. This framework uses an RLVR-trained agent to store trajectories in external files and autonomously retrieve/parse them via code-interpreter interactions (e.g., SQL queries), claiming this bypasses LLM context-window limits and yields strong ShopTrajQA performance plus generalization to other complex reasoning tasks.
Significance. If the empirical results hold, the work could meaningfully advance practical long-context handling in e-commerce personalization by demonstrating tool-augmented external access as a scalable alternative to in-context processing. The introduction of a privacy-respecting, real-world-derived benchmark is a positive contribution, but the complete absence of any quantitative metrics, ablations, or implementation details in the manuscript prevents assessment of whether the claimed bypass and generalization are achieved.
major comments (2)
- [Abstract] Abstract: the central claim of 'strong performance' and effective bypassing of context limits via the RLVR code-interpreter agent is unsupported because the manuscript supplies no metrics, ablation results, error bars, success rates on 64k-token variants, or details on reward density for query failures.
- [Abstract] Abstract: the assumption that the agent reliably discovers schema/query logic for multi-year trajectories and that the code interpreter handles arbitrarily long files without truncation is stated but not demonstrated; no evidence is given that RLVR training produces the required autonomous retrieval behavior on the longest variants.
minor comments (2)
- [Abstract] The abstract refers to 'comprehensive benchmarking of frontier LLMs' and 'experimental results' but provides none of the actual numbers, model names, or tables that would allow readers to evaluate the performance gaps or the framework's gains.
- Notation for the Customer Agent Framework and RLVR paradigm is introduced without definitions or pseudocode, making the training loop difficult to reconstruct.
Simulated Author's Rebuttal
We appreciate the referee's careful reading and the identification of areas where additional empirical support is needed. We will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'strong performance' and effective bypassing of context limits via the RLVR code-interpreter agent is unsupported because the manuscript supplies no metrics, ablation results, error bars, success rates on 64k-token variants, or details on reward density for query failures.
Authors: The referee is correct that the submitted manuscript does not include these specific quantitative details. We will add a comprehensive experimental results section with tables reporting success rates on ShopTrajQA variants up to 64k tokens, ablation studies comparing RLVR to baselines, error bars from repeated experiments, and details on the reward design including handling of query failures. This revision will directly support the claims made in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the assumption that the agent reliably discovers schema/query logic for multi-year trajectories and that the code interpreter handles arbitrarily long files without truncation is stated but not demonstrated; no evidence is given that RLVR training produces the required autonomous retrieval behavior on the longest variants.
Authors: We agree that the current manuscript states these capabilities without providing direct evidence or demonstrations for the longest trajectories. In the revised version, we will include implementation details on the RLVR training process, examples of schema discovery and query generation, confirmation that the code interpreter processes files up to the required lengths without truncation, and experimental results demonstrating the autonomous retrieval behavior on 64k-token variants. We will also discuss any limitations observed. revision: yes
Circularity Check
No circularity: empirical framework and benchmark with independent evaluation
full rationale
The paper introduces a new benchmark (ShopTrajQA) and an agent framework that stores trajectories externally and trains via RLVR for code-interpreter retrieval. No equations, fitted parameters, or self-referential definitions appear in the provided text. Performance claims are presented as experimental outcomes on the benchmark rather than derivations that reduce to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The approach is an engineering solution whose validity rests on external empirical results, not internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated shopping trajectories constructed from real product information accurately reflect real-world customer behavior patterns
invented entities (1)
-
Customer Agent Framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Learning to reason with search for llms via reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[3]
arXiv preprint arXiv:2211.12588 , year=
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
-
[4]
arXiv preprint arXiv:2510.05381 , year=
Context length alone hurts LLM performance despite perfect retrieval , author=. arXiv preprint arXiv:2510.05381 , year=
-
[5]
arXiv preprint arXiv:2504.11536 , year=
Retool: Reinforcement learning for strategic tool use in llms , author=. arXiv preprint arXiv:2504.11536 , year=
-
[6]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[7]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[8]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[9]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2506.09820 , year=
Cort: Code-integrated reasoning within thinking , author=. arXiv preprint arXiv:2506.09820 , year=
-
[13]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[14]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[16]
2025 , url =
Claude Haiku 4.5 , author =. 2025 , url =
2025
-
[17]
2025 , url =
Introducing GPT-OSS , author =. 2025 , url =
2025
-
[18]
arXiv preprint arXiv:2206.06588 , year=
Shopping queries dataset: A large-scale ESCI benchmark for improving product search , author=. arXiv preprint arXiv:2206.06588 , year=
-
[19]
arXiv preprint arXiv:2503.05592 , year=
R1-searcher: Incentivizing the search capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2503.05592 , year=
-
[20]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Empowering large language models: Tool learning for real-world interaction , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[21]
arXiv preprint arXiv:2510.19363 , year=
Loongrl: Reinforcement learning for advanced reasoning over long contexts , author=. arXiv preprint arXiv:2510.19363 , year=
-
[22]
arXiv preprint arXiv:2506.05606 , year=
Opera: A dataset of observation, persona, rationale, and action for evaluating llms on human online shopping behavior simulation , author=. arXiv preprint arXiv:2506.05606 , year=
-
[23]
arXiv preprint arXiv:2510.07230 , year=
Customer-R1: Personalized simulation of human behaviors via RL-based LLM agent in online shopping , author=. arXiv preprint arXiv:2510.07230 , year=
-
[24]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[25]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[26]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2507.17842 , year=
Shop-r1: Rewarding llms to simulate human behavior in online shopping via reinforcement learning , author=. arXiv preprint arXiv:2507.17842 , year=
-
[28]
arXiv preprint arXiv:2509.01055 , year=
Verltool: Towards holistic agentic reinforcement learning with tool use , author=. arXiv preprint arXiv:2509.01055 , year=
-
[29]
arXiv preprint arXiv:2510.10649 , year=
Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning , author=. arXiv preprint arXiv:2510.10649 , year=
-
[30]
arXiv preprint arXiv:2604.10734 , year=
Self-correcting rag: Enhancing faithfulness via mmkp context selection and nli-guided mcts , author=. arXiv preprint arXiv:2604.10734 , year=
-
[31]
2026 , eprint=
Semantic-Aware Logical Reasoning via a Semiotic Framework , author=. 2026 , eprint=
2026
-
[32]
2026 , eprint=
Logical Phase Transitions: Understanding Collapse in LLM Logical Reasoning , author=. 2026 , eprint=
2026
-
[33]
arXiv preprint arXiv:2604.05516 , year=
Coupling Macro Dynamics and Micro States for Long-Horizon Social Simulation , author=. arXiv preprint arXiv:2604.05516 , year=
-
[34]
2026 , eprint=
STRIDE-ED: A Strategy-Grounded Stepwise Reasoning Framework for Empathetic Dialogue Systems , author=. 2026 , eprint=
2026
-
[35]
arXiv preprint arXiv:2512.06690 , year=
Think-While-Generating: On-the-Fly Reasoning for Personalized Long-Form Generation , author=. arXiv preprint arXiv:2512.06690 , year=
-
[36]
2026 , eprint=
GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory , author=. 2026 , eprint=
2026
-
[38]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
F ^2 Bench: An Open-ended Fairness Evaluation Benchmark for LLMs with Factuality Considerations , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[39]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
McBE: A Multi-task Chinese Bias Evaluation Benchmark for Large Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[40]
arXiv preprint arXiv:2604.10101 , year=
Who Wrote This Line? Evaluating the Detection of LLM-Generated Classical Chinese Poetry , author=. arXiv preprint arXiv:2604.10101 , year=
-
[41]
2026 , eprint=
ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models , author=. 2026 , eprint=
2026
-
[42]
arXiv preprint arXiv:2603.11863 , year=
CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges , author=. arXiv preprint arXiv:2603.11863 , year=
-
[43]
arXiv preprint arXiv:2604.07165 , year=
Reason in chains, learn in trees: Self-rectification and grafting for multi-turn agent policy optimization , author=. arXiv preprint arXiv:2604.07165 , year=
-
[44]
arXiv preprint arXiv:2603.16060 , year=
Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning , author=. arXiv preprint arXiv:2603.16060 , year=
-
[45]
DTCRS : Dynamic Tree Construction for Recursive Summarization
Luo, Guanran and Jian, Zhongquan and Qiu, Wentao and Wang, Meihong and Wu, Qingqiang. DTCRS : Dynamic Tree Construction for Recursive Summarization. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.536
-
[46]
Companion of the 2024 International Conference on Management of Data,
Changlong Yu and Xin Liu and Jefferson Maia and Yang Li and Tianyu Cao and Yifan Gao and Yangqiu Song and Rahul Goutam and Haiyang Zhang and Bing Yin and Zheng Li , editor =. Companion of the 2024 International Conference on Management of Data,. 2024 , url =. doi:10.1145/3626246.3653398 , timestamp =
-
[47]
FolkScope: Intention Knowledge Graph Construction for E-commerce Commonsense Discovery , booktitle =
Changlong Yu and Weiqi Wang and Xin Liu and Jiaxin Bai and Yangqiu Song and Zheng Li and Yifan Gao and Tianyu Cao and Bing Yin , editor =. FolkScope: Intention Knowledge Graph Construction for E-commerce Commonsense Discovery , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-ACL.76 , timestamp =
-
[48]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , booktitle =. 2020 , url =
2020
-
[49]
, author=
Measuring nominal scale agreement among many raters. , author=. Psychological bulletin , volume=. 1971 , publisher=
1971
-
[50]
Rishi Hazra and Pedro Zuidberg Dos Martires and Luc De Raedt , editor =. SayCanPay: Heuristic Planning with Large Language Models Using Learnable Domain Knowledge , booktitle =. 2024 , url =. doi:10.1609/AAAI.V38I18.29991 , timestamp =
-
[51]
Reflexion: language agents with verbal reinforcement learning , booktitle =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , editor =. Reflexion: language agents with verbal reinforcement learning , booktitle =. 2023 , url =
2023
-
[52]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al. The Llama 3 Herd of Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[53]
Detecting online commercial intention
Honghua (Kathy) Dai and Lingzhi Zhao and Zaiqing Nie and Ji. Detecting online commercial intention. Proceedings of the 15th international conference on World Wide Web,. 2006 , url =. doi:10.1145/1135777.1135902 , timestamp =
-
[54]
Chenwei Zhang and Wei Fan and Nan Du and Philip S. Yu , editor =. Mining User Intentions from Medical Queries:. Proceedings of the 25th International Conference on World Wide Web,. 2016 , url =. doi:10.1145/2872427.2874810 , timestamp =
-
[55]
Jianmo Ni and Jiacheng Li and Julian J. McAuley , editor =. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects , booktitle =. 2019 , url =. doi:10.18653/V1/D19-1018 , timestamp =
-
[56]
Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona T. Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer , title =. CoRR , volume =. 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.01068 2022
-
[57]
Yu and Xue Wang and Jian Wang , editor =
Zhenyun Hao and Jianing Hao and Zhaohui Peng and Senzhang Wang and Philip S. Yu and Xue Wang and Jian Wang , editor =. Dy-HIEN: Dynamic Evolution based Deep Hierarchical Intention Network for Membership Prediction , booktitle =. 2022 , url =. doi:10.1145/3488560.3498517 , timestamp =
-
[58]
2000 , publisher=
Intention , author=. 2000 , publisher=
2000
-
[59]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou and Jiacheng Li and Zhankui He and An Yan and Xiusi Chen and Julian J. McAuley , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2403.03952 , eprinttype =. 2403.03952 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.03952 2024
-
[60]
Journal of memory and language , volume=
The representation of scripts in memory , author=. Journal of memory and language , volume=. 1985 , publisher=
1985
-
[61]
Multimedia Generative Script Learning for Task Planning , booktitle =
Qingyun Wang and Manling Li and Hou Pong Chan and Lifu Huang and Julia Hockenmaier and Girish Chowdhary and Heng Ji , editor =. Multimedia Generative Script Learning for Task Planning , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-ACL.63 , timestamp =
-
[62]
IJCAI , volume=
Scripts, plans, and knowledge , author=. IJCAI , volume=. 1975 , organization=
1975
-
[63]
Cognitive psychology , volume=
Scripts in memory for text , author=. Cognitive psychology , volume=. 1979 , publisher=
1979
-
[64]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton. Llama 2: Open Foundation and Fine-Tuned Chat Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2307.09288 , eprinttype ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[65]
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =. 1907.11692 , timestamp =
Pith/arXiv arXiv 2019
-
[66]
The Eleventh International Conference on Learning Representations,
Pengcheng He and Jianfeng Gao and Weizhu Chen , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[67]
Findings of the Association for Computational Linguistics:
Weiqi Wang and Tianqing Fang and Wenxuan Ding and Baixuan Xu and Xin Liu and Yangqiu Song and Antoine Bosselut , editor =. Findings of the Association for Computational Linguistics:. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-EMNLP.902 , timestamp =
-
[68]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),
Weiqi Wang and Tianqing Fang and Chunyang Li and Haochen Shi and Wenxuan Ding and Baixuan Xu and Zhaowei Wang and Jiaxin Bai and Xin Liu and Cheng Jiayang and Chunkit Chan and Yangqiu Song , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =
2024
-
[69]
Smith and Yejin Choi and Hannaneh Hajishirzi , editor =
Jiacheng Liu and Wenya Wang and Dianzhuo Wang and Noah A. Smith and Yejin Choi and Hannaneh Hajishirzi , editor =. Vera:. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.81 , timestamp =
-
[70]
Gemma: Open Models Based on Gemini Research and Technology
Thomas Mesnard and Cassidy Hardin and Robert Dadashi and Surya Bhupatiraju and Shreya Pathak and Laurent Sifre and Morgane Rivi. Gemma: Open Models Based on Gemini Research and Technology , journal =. 2024 , url =. doi:10.48550/ARXIV.2403.08295 , eprinttype =. 2403.08295 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.08295 2024
-
[71]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[72]
Tianqing Fang and Hongming Zhang and Weiqi Wang and Yangqiu Song and Bin He , editor =. 2021 , url =. doi:10.1145/3442381.3450117 , timestamp =
-
[73]
Tianqing Fang and Weiqi Wang and Sehyun Choi and Shibo Hao and Hongming Zhang and Yangqiu Song and Bin He , editor =. Benchmarking Commonsense Knowledge Base Population with an Effective Evaluation Dataset , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EMNLP-MAIN.705 , timestamp =
-
[74]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. J. Mach. Learn. Res. , volume =. 2020 , url =
2020
-
[75]
Kelvin J. L. Koa and Yunshan Ma and Ritchie Ng and Tat. Learning to Generate Explainable Stock Predictions using Self-Reflective Large Language Models , booktitle =. 2024 , url =. doi:10.1145/3589334.3645611 , timestamp =
-
[76]
TasTe: Teaching Large Language Models to Translate through Self-Reflection , booktitle =
Yutong Wang and Jiali Zeng and Xuebo Liu and Fandong Meng and Jie Zhou and Min Zhang , editor =. TasTe: Teaching Large Language Models to Translate through Self-Reflection , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.333 , timestamp =
-
[77]
Jena D. Hwang and Chandra Bhagavatula and Ronan Le Bras and Jeff Da and Keisuke Sakaguchi and Antoine Bosselut and Yejin Choi , title =. Thirty-Fifth. 2021 , url =. doi:10.1609/AAAI.V35I7.16792 , timestamp =
-
[78]
Smith and Yejin Choi , title =
Maarten Sap and Ronan Le Bras and Emily Allaway and Chandra Bhagavatula and Nicholas Lourie and Hannah Rashkin and Brendan Roof and Noah A. Smith and Yejin Choi , title =. The Thirty-Third. 2019 , url =. doi:10.1609/AAAI.V33I01.33013027 , timestamp =
-
[79]
Transformers: State-of-the-Art Natural Language Processing , booktitle =
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R. Transformers: State-of-the-Art Natural Language Processing , booktitle =. 2020 , url =. doi:10.18653/V1/2020.EMNLP-DEMOS.6 , timestamp =
-
[80]
Nils Reimers and Iryna Gurevych , editor =. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , booktitle =. 2019 , url =. doi:10.18653/V1/D19-1410 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.