Q-VGM: Q-Guided Value-Gradient Matching for Flow-Matching VLA Policies
Pith reviewed 2026-06-27 19:55 UTC · model grok-4.3
The pith
Q-VGM updates flow-matching VLA policies by matching value gradients to the velocity field at each denoising step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
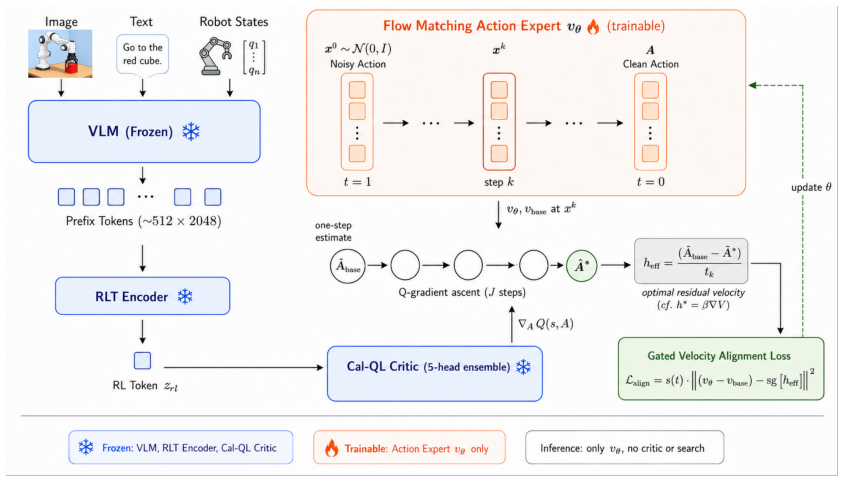
Q-VGM introduces VGG-Flow to transform the value gradient of an action-sensitive Cal-QL ensemble into a denoising-time value-gradient field that directly supervises the flow policy velocity; this requires no backpropagation through the multi-step process and no action likelihoods, enabling stable off-policy improvement from a fixed replay buffer after few-shot SFT initialization.
What carries the argument
VGG-Flow, the transformation of the critic value gradient into a per-denoising-step supervision field for the flow velocity.
Load-bearing premise
That converting the value gradient into a per-denoising-step field supplies stable and effective supervision for the velocity without full-chain backpropagation or action likelihoods.
What would settle it
Training the same flow policy with direct backpropagation of the value through the entire denoising chain at VLA scale and checking whether the resulting success rates match or exceed those obtained with Q-VGM.
Figures

read the original abstract
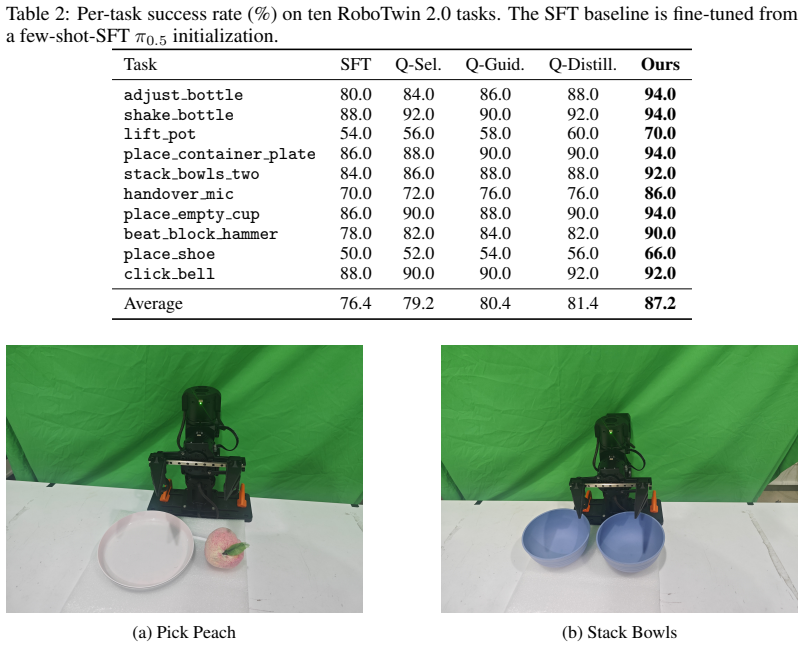
We propose Q-Guided Value-Gradient Matching (Q-VGM), an off-policy reinforcement learning (RL) method that tackles a long-standing challenge in fine-tuning flow-matching vision-language-action (VLA) policies: efficiently improving an expressive flow-matching action expert with respect to a learned Q-function. Effective improvement must exploit the first-order (gradient) information of the critic, but this is difficult for flow policies, because directly back-propagating the value through their multi-step denoising process is numerically unstable at VLA scale, while the tractable action likelihoods required by policy-gradient methods are unavailable under iterative denoising. Existing value-based methods either backpropagate through the full denoising chain, use the critic only at test time without updating the policy, or distill critic-improved actions as terminal labels without supervising the velocity field. Q-VGM sidesteps these issues by leveraging VGG-Flow, a value-gradient view of flow alignment in generative modeling that transforms value gradient into a denoising-time value-gradient field rather than an unstable end-to-end objective. This requires no action likelihoods and no backpropagation through the denoising chain, and operates on a fixed replay buffer. The critic is an action-sensitive Cal-QL ensemble over compact RLT features with per-layer action injection. Q-VGM enables a practical few-shot initialization then learn-from-experience paradigm: starting from a few-shot-SFT pi0.5 VLA, the method leverages self-generated rollout data to substantially improve task performance without additional expert supervision. On LIBERO, Q-VGM raises the average success rate from 75.0% to 92.5%; on RoboTwin 2.0, from 76.4% to 87.2%; and on two real-robot tabletop tasks, from 40.0% to 67.5%, outperforming all same-backbone, same-critic baselines across all three settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Q-Guided Value-Gradient Matching (Q-VGM), an off-policy RL approach for fine-tuning flow-matching VLA policies. It introduces VGG-Flow to convert critic value gradients into a per-denoising-step supervision field for the flow velocity, avoiding direct backpropagation through the iterative denoising chain and eliminating the need for action likelihoods. The critic is implemented as an action-sensitive Cal-QL ensemble over RLT features. The method starts from a few-shot SFT initialization and improves via self-generated rollouts on a fixed replay buffer. Reported results include average success rate increases from 75.0% to 92.5% on LIBERO, 76.4% to 87.2% on RoboTwin 2.0, and 40.0% to 67.5% on two real-robot tabletop tasks, with outperformance over same-backbone, same-critic baselines.
Significance. If the VGG-Flow construction is shown to preserve first-order return information and remain stable at VLA scale, the approach could enable practical RL fine-tuning of expressive generative policies where full-chain differentiation is intractable. The fixed-buffer, few-shot-to-experience paradigm and use of Cal-QL ensembles are pragmatic strengths for robotics deployment. The empirical gains across simulation and real-robot settings, if robustly attributed to the proposed mechanism, would represent a meaningful advance in scaling value-based improvement for flow-matching VLAs.
major comments (2)
- [Method section (VGG-Flow definition)] The VGG-Flow construction (method section): the paper states that the transformation converts the Q-gradient into a denoising-time value-gradient field that directly supervises the velocity without end-to-end differentiation, but supplies neither the explicit mapping equation from critic gradient to velocity target nor any analysis of its bias, Lipschitz constant, or behavior under iterative denoising. This is load-bearing for the central claim that the method sidesteps numerical instability while preserving expected-return information.
- [Experimental results section] Experimental results (LIBERO, RoboTwin, and real-robot tables): the success-rate improvements (75.0% o 92.5%, 76.4% o 87.2%, 40.0% o 67.5%) are reported as single point estimates with no error bars, standard deviations across seeds, or statistical significance tests against baselines. No ablation isolates the contribution of the value-gradient matching loss from the Cal-QL ensemble or replay-buffer curation, which is required to attribute gains to the claimed supervision mechanism.
minor comments (2)
- [Abstract] The abstract claims outperformance over 'all same-backbone, same-critic baselines' but does not list the specific baseline methods or their numerical results; adding a compact comparison table would improve clarity.
- [Critic architecture subsection] Notation for the per-layer action injection in the Cal-QL critic and the RLT feature extractor could be defined more explicitly with a small diagram or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate clarifications and additional results in the revised version.
read point-by-point responses
-
Referee: [Method section (VGG-Flow definition)] The VGG-Flow construction (method section): the paper states that the transformation converts the Q-gradient into a denoising-time value-gradient field that directly supervises the velocity without end-to-end differentiation, but supplies neither the explicit mapping equation from critic gradient to velocity target nor any analysis of its bias, Lipschitz constant, or behavior under iterative denoising. This is load-bearing for the central claim that the method sidesteps numerical instability while preserving expected-return information.
Authors: We agree the explicit mapping and supporting analysis are necessary for the central claim. The current manuscript describes VGG-Flow conceptually but omits the precise equation. In revision we will insert the closed-form mapping that converts the critic gradient abla_a Q(s, a) into the per-denoising-step velocity target via the flow-matching alignment objective. We will also add a short derivation showing that the mapping is unbiased with respect to expected return under the Cal-QL ensemble and provide a Lipschitz-constant bound that holds under the compact RLT feature representation, thereby confirming stability without end-to-end differentiation. revision: yes
-
Referee: [Experimental results section] Experimental results (LIBERO, RoboTwin, and real-robot tables): the success-rate improvements (75.0% to 92.5%, 76.4% to 87.2%, 40.0% to 67.5%) are reported as single point estimates with no error bars, standard deviations across seeds, or statistical significance tests against baselines. No ablation isolates the contribution of the value-gradient matching loss from the Cal-QL ensemble or replay-buffer curation, which is required to attribute gains to the claimed supervision mechanism.
Authors: We concur that single-point estimates and missing ablations limit attribution. The reported numbers reflect single training runs performed under tight compute budgets typical for VLA-scale models. In the revision we will rerun the primary LIBERO and RoboTwin experiments over three independent seeds, reporting means and standard deviations, and will add a targeted ablation that disables only the value-gradient matching term while retaining the identical Cal-QL ensemble and replay buffer. This will allow direct isolation of VGG-Flow’s contribution. revision: yes
Circularity Check
No significant circularity; derivation introduces independent supervision mechanism
full rationale
The paper presents Q-VGM as a new off-policy RL method that uses VGG-Flow to transform critic gradients into a per-denoising-step field for supervising flow velocity, explicitly avoiding backpropagation through the chain and action likelihoods. No equations, self-citations, or fitted parameters are shown that reduce the claimed performance gains (on LIBERO, RoboTwin, real-robot tasks) to quantities already present in the inputs by construction. The central transformation is framed as addressing a distinct numerical instability problem rather than renaming or refitting prior results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiao, Carles Domingo-Enrich, Weiyang Liu, and Dinghuai Zhang
Zhen Liu, Tim Z. Xiao, Carles Domingo-Enrich, Weiyang Liu, and Dinghuai Zhang. Value gradient guidance for flow matching alignment. InAdvances in Neural Information Processing Systems, 2025
2025
-
[2]
RT-2: Vision- language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision- language-action models transfer web knowledge to robotic control. InConference on Robot Learning, 2023
2023
-
[3]
Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Octo Model Team. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[4]
OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[6]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[7]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Matt Le, and Maximilian Nickel. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[8]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[9]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Xi- ang Li, Quanlu Zhang, Zhaofei Yu, Guoliang Fan, Tiejun Huang, Yu Wang, and Chao Yu. πRL: Online RL fine-tuning for flow-based vision-language-action models.arXiv preprint arXiv:2510.25889, 2025
arXiv 2025
-
[10]
Ren, Justin Lidard, Lars L
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations, 2025
2025
-
[11]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. ReinFlow: Fine-tuning flow matching policy with online reinforcement learning.arXiv preprint arXiv:2505.22094, 2025
arXiv 2025
-
[12]
Mingyang Lyu, Yinqian Sun, Erliang Lin, Huangrui Li, Ruolin Chen, Feifei Zhao, and Yi Zeng. Reinforcement fine-tuning of flow-matching policies for vision-language-action models.arXiv preprint arXiv:2510.09976, 2025
Pith/arXiv arXiv 2025
-
[13]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. arXiv preprint arXiv:2505.05470, 2025
Pith/arXiv arXiv 2025
-
[14]
Jeongjae Lee, Jinho Chang, Jeongsol Kim, and Jong Chul Ye. Reward score matching: Unify- ing reward-based fine-tuning for flow and diffusion models.arXiv preprint arXiv:2604.17415, 2026
Pith/arXiv arXiv 2026
-
[15]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InInternational Conference on Learning Rep- resentations, 2023. 10
2023
-
[16]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, Dong Wang, and Xuelong Li. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432, 2025
arXiv 2025
-
[17]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Foutter, Shulu Li, Ion Stoica, Azalia Mirho- seini, and Marco Pavone. RoboMonkey: Scaling test-time sampling and verification for vision- language-action models.arXiv preprint arXiv:2506.17811, 2025
arXiv 2025
-
[18]
Policy agnostic RL: Offline RL and online RL fine- tuning of any class and backbone
Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, and Aviral Kumar. Policy agnostic RL: Offline RL and online RL fine- tuning of any class and backbone. InInternational Conference on Learning Representations, 2025
2025
-
[19]
Efficient diffusion policies for offline reinforcement learning
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[20]
Diffusion policies creating a trust region for offline reinforcement learning
Tianyu Chen, Zhendong Wang, and Mingyuan Zhou. Diffusion policies creating a trust region for offline reinforcement learning. InAdvances in Neural Information Processing Systems, 2024
2024
-
[21]
Learning a diffusion model policy from rewards via Q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via Q-score matching. InInternational Conference on Machine Learning, 2024
2024
-
[22]
Verifier- free test-time sampling for vision language action models
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Youngsuk Kim, and Jinwoo Shin. Verifier- free test-time sampling for vision language action models. InInternational Conference on Learning Representations, 2026
2026
-
[23]
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Tommaso Biancalani, and Sergey Levine. Fine- tuning of continuous-time diffusion models as entropy-regularized control.arXiv preprint arXiv:2402.15194, 2024
arXiv 2024
-
[24]
Wenpin Tang and Fuzhong Zhou. Fine-tuning of diffusion models via stochastic control: en- tropy regularization and beyond.arXiv preprint arXiv:2403.06279, 2024
arXiv 2024
-
[25]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint match- ing: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InInternational Conference on Learning Representations, 2025
2025
-
[26]
Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
Qiyang Li and Sergey Levine. Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
Pith/arXiv arXiv 2026
-
[27]
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018
Pith/arXiv arXiv 2018
-
[28]
RL token: Bootstrapping online RL with vision-language-action mod- els
Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, and Liyiming Ke. RL token: Bootstrapping online RL with vision-language-action mod- els. Physical Intelligence whitepaper; arXiv:2604.23073, 2026. URLhttps://www.pi. website/download/rlt.pdf
Pith/arXiv arXiv 2026
-
[29]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. InAdvances in Neural Information Processing Systems, 2025
2025
-
[30]
Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning
Mitsuhiko Nakamoto, Yuexiang Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[31]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems, 2023. 11
2023
-
[32]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[33]
Steering your generalists: Improving robotic foundation models via value guidance
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foundation models via value guidance. InConference on Robot Learning, 2024
2024
-
[34]
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning.arXiv preprint arXiv:2305.13122, 2023
arXiv 2023
-
[35]
Trust region q adjoint matching.arXiv preprint arXiv:2605.27079, 2026
Yonghoon Dong, Kyungmin Lee, Changyeon Kim, Jaehyuk Kim, and Jinwoo Shin. Trust region q adjoint matching.arXiv preprint arXiv:2605.27079, 2026
Pith/arXiv arXiv 2026
-
[36]
Horizon reduction makes RL scalable
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes RL scalable. InAdvances in Neural Information Processing Systems, 2025. 12 A Critic Architecture and Training Details Critic architecture.The critic state is¯s= LayerNorm([z rl ∥W p p])∈R 2304, wherez rl ∈R 2048 is the cached RLT encodin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.