Support Vector Rubrics: Closing the Gap Between Self-Generated and Human Rubrics
Pith reviewed 2026-06-27 20:03 UTC · model grok-4.3
The pith
SVR recasts rubric construction as max-margin learning from preference pairs to close the gap with human rubrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
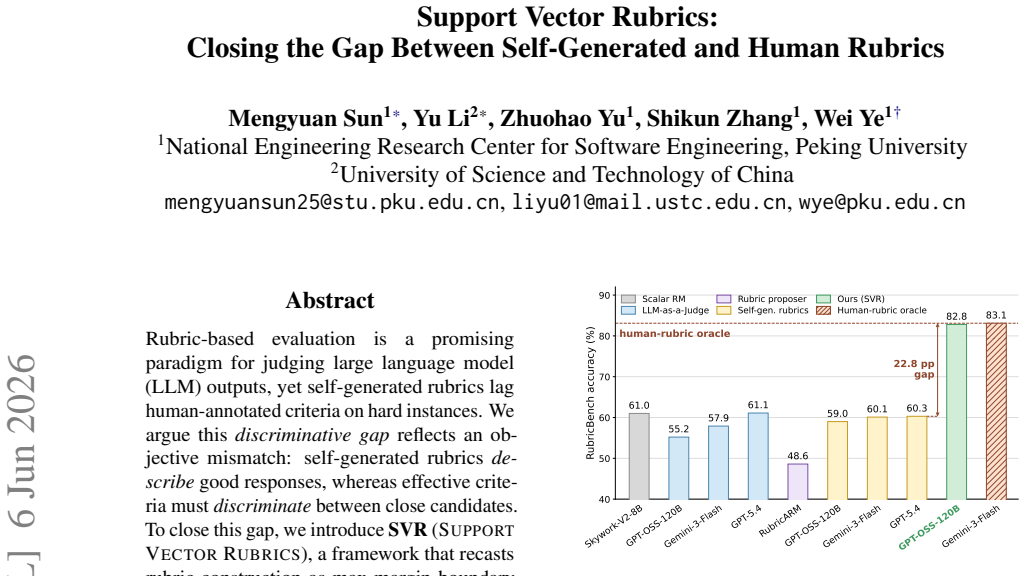
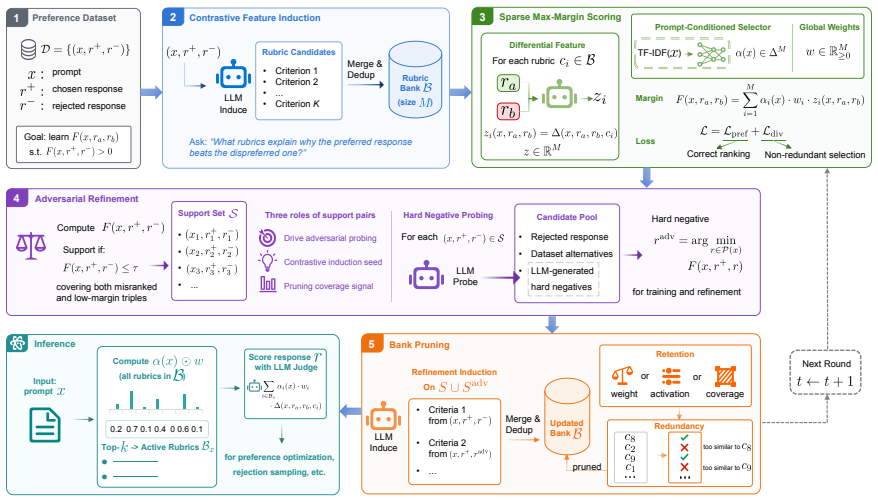
SVR recasts rubric construction as max-margin boundary learning over preference data. It mines contrastive features from preference pairs into a rubric bank, learns a prompt-conditioned selector together with global rubric weights, and iteratively refines the bank through support-pair selection and adversarial probing of hard negatives. At inference, given only the prompt, SVR retrieves the top-rubrics from the bank and scores responses. On RubricBench, SVR narrows the gap to human reference rubrics from 24.1 to 0.3 points and outperforms strong self-rubric and judge baselines, and the learned bank transfers across judges without retraining.
What carries the argument
The rubric bank of contrastive features mined from preference pairs, combined with a prompt-conditioned selector and global weights learned via max-margin optimization.
If this is right
- SVR narrows the gap to human reference rubrics from 24.1 to 0.3 points on RubricBench.
- The learned rubric bank transfers across judges without retraining.
- SVR outperforms strong self-rubric and judge baselines on RubricBench.
- SVR remains competitive with dedicated reward models on RewardBench 1&2 and RM-Bench.
Where Pith is reading between the lines
- Preference-based boundary learning could extend to creating rubrics for domains where human annotation is scarce but preference data exists.
- The iterative refinement with adversarial probing suggests a way to make evaluation criteria more robust to evolving model capabilities.
- Transferability of the bank implies potential for a shared, community-maintained rubric resource across different evaluation setups.
Load-bearing premise
That contrastive features mined from preference pairs can be assembled into a stable, transferable rubric bank whose prompt-conditioned selector generalizes to hard unseen instances without overfitting to the training preference distribution.
What would settle it
A dataset of hard preference pairs where SVR's discrimination performance does not improve over self-generated rubrics or drops when the bank is applied to a different judge model.
Figures

read the original abstract
Rubric-based evaluation is a promising paradigm for judging large language model (LLM) outputs, yet self-generated rubrics lag human-annotated criteria on hard instances. We argue this discriminative gap reflects an objective mismatch: self-generated rubrics describe good responses, whereas effective criteria must discriminate between close candidates. To close this gap, we introduce SVR (Support Vector Rubrics), a framework that recasts rubric construction as max-margin boundary learning over preference data. SVR mines contrastive features from preference pairs into a rubric bank, learns a prompt-conditioned selector together with global rubric weights, and iteratively refines the bank through support-pair selection and adversarial probing of hard negatives. At inference, given only the prompt, SVR retrieves the top-rubrics from the bank and scores responses. On RubricBench, SVR narrows the gap to human reference rubrics from 24.1 to 0.3 points and outperforms strong self-rubric and judge baselines, and the learned bank transfers across judges without retraining. On RewardBench 1&2, and RM-Bench, it remains competitive with dedicated reward models, demonstrating broader reward modeling capability. Overall, boundary-defining rubrics offer a principled route to closing the discriminative gap in LLM evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Support Vector Rubrics (SVR), a framework that recasts rubric construction for LLM evaluation as max-margin boundary learning over preference data. It mines contrastive features from preference pairs into a rubric bank, learns a prompt-conditioned selector along with global rubric weights, and performs iterative refinement via support-pair selection and adversarial probing of hard negatives. At inference, the method retrieves top rubrics from the bank given only the prompt to score responses. On RubricBench, SVR is reported to narrow the gap to human reference rubrics from 24.1 to 0.3 points while outperforming self-rubric and judge baselines; the learned bank transfers across judges without retraining. It is also competitive with dedicated reward models on RewardBench 1&2 and RM-Bench.
Significance. If the reported gains and transfer results hold under rigorous verification, the work offers a principled alternative to purely descriptive self-generated rubrics by emphasizing discriminative boundaries derived from preference data. This could meaningfully advance automated LLM evaluation and reward modeling, particularly if the rubric bank proves stable and generalizable. The framing as a support-vector-style procedure provides conceptual novelty, though its practical impact depends on the robustness of the empirical claims.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of narrowing the RubricBench gap from 24.1 to 0.3 points is presented without error bars, standard deviations across runs, or statistical significance tests. This information is load-bearing for assessing whether the result reliably closes the gap rather than reflecting a single favorable run or selection effect.
- [§3] §3 (Method): The iterative refinement through support-pair selection and adversarial probing of hard negatives is described at a high level, but no explicit procedure or diagnostic is given to confirm that the process avoids post-hoc selection bias on the training preference distribution. This directly affects the validity of the learned rubric bank and its claimed transferability.
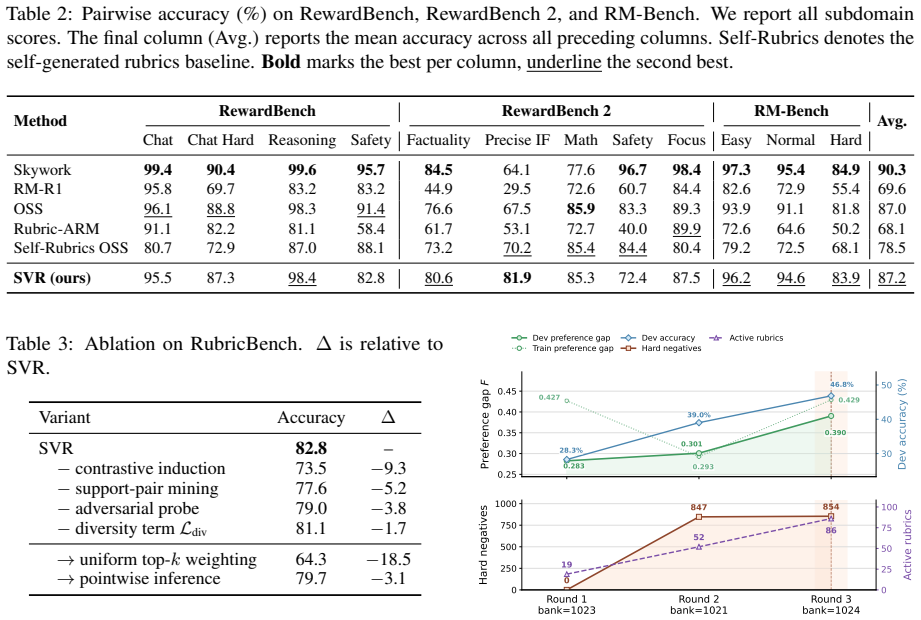
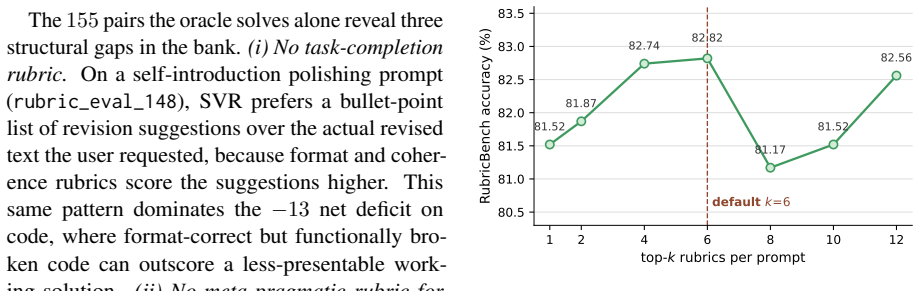
- [§4] §4 (Experiments): No ablation results are reported for key design choices such as rubric bank size, selection threshold, or the contribution of the prompt-conditioned selector versus global weights. Without these, it is difficult to attribute the performance gains to the max-margin formulation rather than other factors.
minor comments (1)
- [Abstract and §3] The abstract and method description would benefit from a short equation or pseudocode block formalizing the max-margin objective and the inference-time retrieval step to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing empirical rigor. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results, method details, and ablations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of narrowing the RubricBench gap from 24.1 to 0.3 points is presented without error bars, standard deviations across runs, or statistical significance tests. This information is load-bearing for assessing whether the result reliably closes the gap rather than reflecting a single favorable run or selection effect.
Authors: We agree that variability metrics are necessary to substantiate the central claim. In the revised version we will report mean performance and standard deviation over five independent training runs with distinct random seeds, include error bars on all RubricBench figures, and add paired t-test p-values comparing SVR against the self-rubric and judge baselines. These additions will confirm that the reduction from 24.1 to 0.3 points is statistically reliable rather than an artifact of a single run. revision: yes
-
Referee: [§3] §3 (Method): The iterative refinement through support-pair selection and adversarial probing of hard negatives is described at a high level, but no explicit procedure or diagnostic is given to confirm that the process avoids post-hoc selection bias on the training preference distribution. This directly affects the validity of the learned rubric bank and its claimed transferability.
Authors: The current description in §3 outlines support-pair selection via margin violations and adversarial probing with prompt-perturbed hard negatives, but we acknowledge the absence of an explicit bias diagnostic. We will expand §3 with a dedicated subsection providing the full algorithmic procedure (including pseudocode) and a validation diagnostic that measures overlap between selected support pairs and held-out test distributions, plus the fraction of adversarial negatives that improve validation performance. This will demonstrate that the iterative process does not introduce post-hoc selection bias and supports the reported transferability. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation results are reported for key design choices such as rubric bank size, selection threshold, or the contribution of the prompt-conditioned selector versus global weights. Without these, it is difficult to attribute the performance gains to the max-margin formulation rather than other factors.
Authors: We concur that targeted ablations are required to isolate the contribution of the max-margin formulation. The revised §4 will include a new table reporting performance for rubric bank sizes ranging from 50 to 500, varying selection thresholds, and three controlled variants: (i) global weights only, (ii) prompt-conditioned selector only, and (iii) the full SVR model. These results will show that the combination of contrastive boundary learning and prompt-conditioned selection is responsible for the observed gains on RubricBench and the transfer results. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper frames SVR as a max-margin learning procedure that mines contrastive features from preference pairs into a rubric bank, trains a prompt-conditioned selector and global weights, and performs iterative refinement. Reported gains on RubricBench (24.1 to 0.3 point gap closure) and transfer results are presented as empirical outcomes of this procedure rather than quantities defined by construction from the target metric or from self-citations. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the supplied material that would reduce the central claims to their inputs. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- rubric bank size and selection threshold
- global rubric weights
axioms (1)
- domain assumption Preference pairs contain sufficient contrastive signal to define discriminative rubric features
invented entities (1)
-
Support Vector Rubrics bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2603.01562 , year=
RubricBench: Aligning Model-Generated Rubrics with Human Standards , author=. arXiv preprint arXiv:2603.01562 , year=
-
[2]
arXiv preprint arXiv:2603.25133 , year=
RubricEval: A Rubric-Level Meta-Evaluation Benchmark for LLM Judges in Instruction Following , author=. arXiv preprint arXiv:2603.25133 , year=
-
[3]
arXiv preprint arXiv:2511.10507 , year=
Advancedif: Rubric-based benchmarking and reinforcement learning for advancing llm instruction following , author=. arXiv preprint arXiv:2511.10507 , year=
-
[4]
PaperBench: Evaluating
Giulio Starace and Oliver Jaffe and Dane Sherburn and James Aung and Jun Shern Chan and Leon Maksin and Rachel Dias and Evan Mays and Benjamin Kinsella and Wyatt Thompson and Johannes Heidecke and Amelia Glaese and Tejal Patwardhan , booktitle=. PaperBench: Evaluating. 2025 , url=
2025
-
[5]
arXiv preprint arXiv:2510.07743 , year=
Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment , author=. arXiv preprint arXiv:2510.07743 , year=
-
[6]
arXiv preprint arXiv:2602.05125 , year=
Rethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks , author=. arXiv preprint arXiv:2602.05125 , year=
-
[7]
arXiv preprint arXiv:2510.17314 , year=
Auto-Rubric: Learning From Implicit Weights to Explicit Rubrics for Reward Modeling , author=. arXiv preprint arXiv:2510.17314 , year=
-
[8]
arXiv preprint arXiv:2602.10885 , year=
Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics , author=. arXiv preprint arXiv:2602.10885 , year=
-
[9]
The Fourteenth International Conference on Learning Representations , year=
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author=. The Fourteenth International Conference on Learning Representations , year=
-
[10]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Rewardbench: Evaluating reward models for language modeling , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[11]
International Conference on Learning Representations , volume=
Rm-bench: Benchmarking reward models of language models with subtlety and style , author=. International Conference on Learning Representations , volume=
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Interpretable preferences via multi-objective reward modeling and mixture-of-experts , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[13]
arXiv preprint arXiv:2410.18451 , year=
Skywork-reward: Bag of tricks for reward modeling in llms , author=. arXiv preprint arXiv:2410.18451 , year=
-
[14]
International Conference on Learning Representations , volume=
Generative verifiers: Reward modeling as next-token prediction , author=. International Conference on Learning Representations , volume=
-
[15]
arXiv preprint arXiv:2408.11791 , year=
Critique-out-loud reward models , author=. arXiv preprint arXiv:2408.11791 , year=
-
[16]
HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages , url =
Wang, Zhilin and Zeng, Jiaqi and Delalleau, Olivier and Shin, Hoo-Chang and Soares, Felipe and Bukharin, Alexander and Evans, Ellie and Dong, Yi and Kuchaiev, Oleksii , booktitle =. HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages , url =
-
[17]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Facenet: A unified embedding for face recognition and clustering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[18]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Training region-based object detectors with online hard example mining , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[19]
Deep Reinforcement Learning from Human Preferences , url =
Christiano, Paul F and Leike, Jan and Brown, Tom and Martic, Miljan and Legg, Shane and Amodei, Dario , booktitle =. Deep Reinforcement Learning from Human Preferences , url =
-
[20]
2026 , url=
Xiusi Chen and Gaotang Li and Ziqi Wang and Bowen Jin and Cheng Qian and Yu Wang and Hongru WANG and Yu Zhang and Denghui Zhang and Tong Zhang and Hanghang Tong and Heng Ji , booktitle=. 2026 , url=
2026
-
[21]
Learning to summarize with human feedback , url =
Stiennon, Nisan and Ouyang, Long and Wu, Jeffrey and Ziegler, Daniel and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul F , booktitle =. Learning to summarize with human feedback , url =
-
[22]
International Conference on Learning Representations , volume=
Reward model ensembles help mitigate overoptimization , author=. International Conference on Learning Representations , volume=
-
[23]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[24]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
From generation to judgment: Opportunities and challenges of llm-as-a-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[26]
Language Gamification - NeurIPS 2024 Workshop , year=
Jonathan Cook and Tim Rockt. Language Gamification - NeurIPS 2024 Workshop , year=
2024
-
[27]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[28]
Proceedings of the fifth annual workshop on Computational learning theory , pages=
A training algorithm for optimal margin classifiers , author=. Proceedings of the fifth annual workshop on Computational learning theory , pages=
-
[29]
Machine learning , volume=
Support-vector networks , author=. Machine learning , volume=. 1995 , publisher=
1995
-
[30]
The Thirteenth International Conference on Learning Representations , year=
HelpSteer2-Preference: Complementing Ratings with Preferences , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
2025 , url=
Jon Saad-Falcon and Rajan Vivek and William Berrios and Nandita Shankar Naik and Matija Franklin and Bertie Vidgen and Amanpreet Singh and Douwe Kiela and Shikib Mehri , booktitle=. 2025 , url=
2025
-
[32]
International conference on machine learning , pages=
From softmax to sparsemax: A sparse model of attention and multi-label classification , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[33]
arXiv preprint arXiv:2603.12795 , year=
SteerRM: Debiasing Reward Models via Sparse Autoencoders , author=. arXiv preprint arXiv:2603.12795 , year=
-
[34]
2025 , eprint=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
2025
-
[35]
arXiv preprint arXiv:2506.01937 , year=
Rewardbench 2: Advancing reward model evaluation , author=. arXiv preprint arXiv:2506.01937 , year=
-
[36]
arXiv preprint arXiv:2602.01511 , year=
Alternating reinforcement learning for rubric-based reward modeling in non-verifiable llm post-training , author=. arXiv preprint arXiv:2602.01511 , year=
-
[37]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[38]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[39]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[40]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[41]
Information processing & management , volume=
Term-weighting approaches in automatic text retrieval , author=. Information processing & management , volume=. 1988 , publisher=
1988
-
[42]
arXiv preprint arXiv:2506.03637 , year=
Rewardanything: Generalizable principle-following reward models , author=. arXiv preprint arXiv:2506.03637 , year=
-
[43]
arXiv preprint arXiv:2604.02368 , year=
Xpertbench: Expert Level Tasks with Rubrics-Based Evaluation , author=. arXiv preprint arXiv:2604.02368 , year=
-
[44]
The annals of statistics , volume=
Boosting the margin: A new explanation for the effectiveness of voting methods , author=. The annals of statistics , volume=. 1998 , publisher=
1998
-
[45]
arXiv preprint arXiv:2507.01352 , year=
Skywork-reward-v2: Scaling preference data curation via human-ai synergy , author=. arXiv preprint arXiv:2507.01352 , year=
-
[46]
arXiv preprint arXiv:1909.08593 , year=
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
Pith/arXiv arXiv 1909
-
[47]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[48]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[49]
the Journal of machine Learning research , volume=
Scikit-learn: Machine learning in Python , author=. the Journal of machine Learning research , volume=. 2011 , publisher=
2011
-
[50]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[51]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[52]
Advances in neural information processing systems , volume=
Incorporating second-order functional knowledge for better option pricing , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.