VideoWeaver: Evaluating and Evolving Skills for Agentic Long Video Generation
Pith reviewed 2026-06-27 20:02 UTC · model grok-4.3
The pith
An agent harness lets models compose and evolve their own skills to turn single instructions into long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VideoWeaver demonstrates that an explicit composition skill improves the generation process over using foundation skills alone, that skill evolution further improves output quality, and that performance varies notably across harness and model choices. The proposed agent-as-judge also aligns well with human judgments, especially on process metrics.
What carries the argument
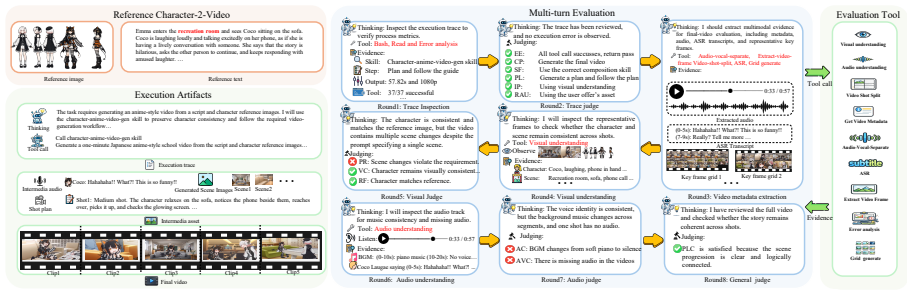
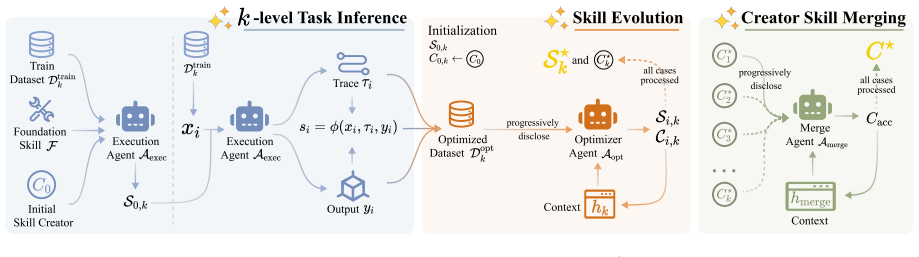
The composition skill that turns a single instruction into a long video by letting the agent build and refine its own workflow from foundation skills, combined with the skill evolution algorithm that refines and merges skills based on agent-as-judge feedback.
If this is right
- Explicit composition skills produce better long video outputs than foundation skills used without orchestration.
- Skill evolution using judge feedback raises generation quality beyond the initial composition step.
- Results differ substantially depending on which agent framework and base model is used.
- Process metrics evaluated by the agent-as-judge match human ratings more closely than final-video-only metrics.
Where Pith is reading between the lines
- The same harness and evolution loop could be applied to other long-horizon multimodal tasks such as interactive story generation.
- Future agent benchmarks may shift from testing fixed pipelines to measuring how well agents discover and merge new skills.
- If the agent-as-judge generalizes, it could reduce the cost of human evaluation for iterative workflow improvement.
Load-bearing premise
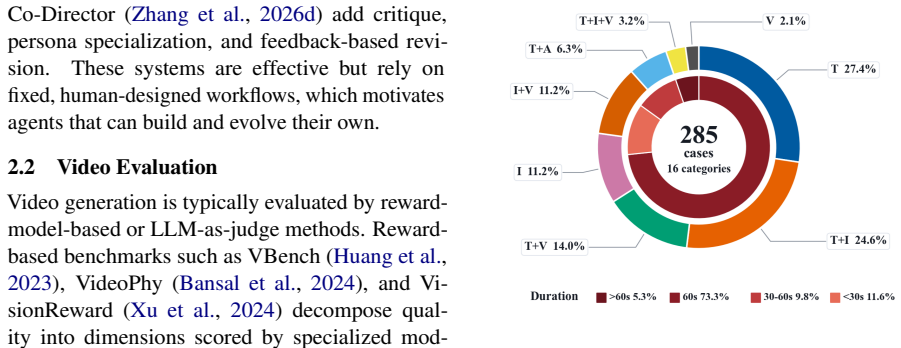
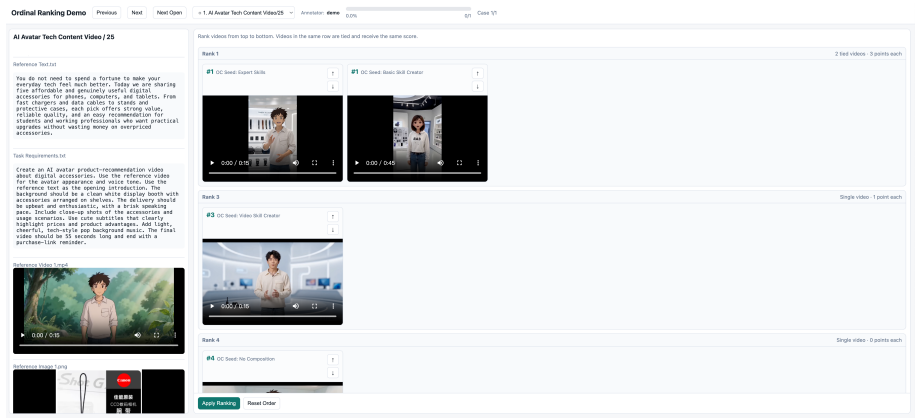
The assumption that an agent-as-judge inspecting execution traces, metadata, and intermediate files produces scores that reliably align with human judgments and that the 16 task categories plus 285 cases adequately capture the space of long video generation challenges.
What would settle it
A direct comparison in which human raters score the same execution traces and final videos on the 285 cases and show low agreement with the agent-as-judge on process metrics.
Figures

read the original abstract
Recent agent frameworks such as Claude Code, Codex, and OpenClaw are strong at tool use and orchestration, but whether they can handle long video generation, a long-horizon multimodal task, remains underexplored. Unlike earlier video agents whose pipeline is handcrafted, these frameworks can build and refine their own workflows. We introduce VideoWeaver, an agent harness and benchmark that evaluates and evolves skills for long video generation, where an agent turns a single instruction into a long video by composing foundation skills into its own workflow rather than following a predefined pipeline. The benchmark has 16 task categories and 285 cases, with references spanning text, image, audio, video, and their combinations. Because errors can arise at any stage and not just in the final video, we propose an agent-as-judge that inspects both the execution trace and the final video, grounding its scores in evidence such as metadata and intermediate files. Using this feedback, we further design a skill evolution algorithm that refines and merges the agent's skills. Across multiple frameworks and models, we find that an explicit composition skill improves the generation process over using foundation skills alone, that skill evolution further improves output quality, and that performance varies notably across harness and model choices. The proposed agent-as-judge also aligns well with human judgments, especially on process metrics. Code and dataset is available at https://github.com/JianhuiWei7/VideoWeaver
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VideoWeaver, an agent harness and benchmark for long video generation in which agents compose foundation skills into custom workflows rather than following handcrafted pipelines. The benchmark comprises 16 task categories and 285 cases spanning text, image, audio, video, and multimodal references. It proposes an agent-as-judge that scores outputs by inspecting execution traces, metadata, and intermediate files, together with a skill-evolution algorithm that refines and merges skills based on this feedback. Empirical results across multiple frameworks and models indicate that an explicit composition skill improves generation over foundation skills alone, that skill evolution yields further gains, and that performance varies across harnesses and models; the agent-as-judge is reported to align well with human judgments, especially on process metrics. Code and dataset are released publicly.
Significance. If the reported performance deltas and judge-human alignment are quantitatively substantiated, the work would supply a reproducible benchmark and methodology for evaluating agentic long-horizon multimodal generation, highlighting the value of explicit skill composition and iterative evolution. The public code release and dataset constitute a clear strength for reproducibility and follow-on research.
major comments (1)
- [Abstract] Abstract: The central claim that 'the proposed agent-as-judge also aligns well with human judgments, especially on process metrics' is unsupported by any quantitative evidence (correlation coefficients, agreement rates, number of raters, or inter-rater statistics). Because the performance comparisons across harnesses and models rest on the judge's scores being reliable proxies, the absence of these metrics renders the empirical findings difficult to interpret.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need to substantiate the agent-as-judge alignment claim. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the proposed agent-as-judge also aligns well with human judgments, especially on process metrics' is unsupported by any quantitative evidence (correlation coefficients, agreement rates, number of raters, or inter-rater statistics). Because the performance comparisons across harnesses and models rest on the judge's scores being reliable proxies, the absence of these metrics renders the empirical findings difficult to interpret.
Authors: We agree that the abstract claim regarding alignment with human judgments is presented without quantitative support (e.g., correlation coefficients, agreement rates, rater counts, or inter-rater statistics) in the submitted manuscript. This is a valid concern, as the reliability of the agent-as-judge underpins the reported performance comparisons. In the revised version we will remove the unsubstantiated phrasing from the abstract and add a dedicated human-evaluation subsection that reports the requested metrics, including Pearson/Spearman correlations, agreement percentages, number of raters, and inter-rater reliability statistics. These additions will be placed in the main text so that the empirical findings can be properly interpreted. revision: yes
Circularity Check
No circularity: empirical benchmark and evaluation with released code
full rationale
The paper introduces VideoWeaver as an agent harness, benchmark (16 categories, 285 cases), agent-as-judge, and skill evolution algorithm. All central claims are empirical comparisons across frameworks/models, with public code release. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The derivation chain consists of experimental setup and observed performance deltas rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Video generation models as world simulators , author =. 2024 , url =
2024
-
[2]
2024 , month =
Google I/O 2024: Introducing Veo and Imagen 3 generative AI tools , author =. 2024 , month =
2024
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[4]
and others , title =
Qiu, S. and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[5]
arXiv preprint arXiv:2508.13602 , year=
PersonaVlog: Personalized Multimodal Vlog Generation with Multi-Agent Collaboration and Iterative Self-Correction , author=. arXiv preprint arXiv:2508.13602 , year=
-
[6]
arXiv preprint arXiv:2512.12196 , year=
AutoMV: An Automatic Multi-Agent System for Music Video Generation , author=. arXiv preprint arXiv:2512.12196 , year=
-
[7]
arXiv preprint arXiv:2601.17737 , year=
The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation , author=. arXiv preprint arXiv:2601.17737 , year=
-
[8]
arXiv preprint arXiv:2510.22431 , year=
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration , author=. arXiv preprint arXiv:2510.22431 , year=
-
[9]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Animaker: Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[10]
and others , title =
Yuan, Z. and others , title =. Computing Research Repository , volume =. 2024 , url =
2024
-
[11]
and others , title =
Yang, X. and others , title =. Computing Research Repository , volume =. 2025 , url =
2025
-
[12]
and others , title =
Pan, Y. and others , title =. Computing Research Repository , volume =. 2024 , url =
2024
-
[13]
and others , title =
Zhang, Y. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[14]
arXiv preprint arXiv:2210.02399 , year=
Phenaki: Variable Length Video Generation From Open Domain Textual Description , author=. arXiv preprint arXiv:2210.02399 , year=
-
[15]
arXiv preprint arXiv:2312.14125 , year=
VideoPoet: A Large Language Model for Zero-Shot Video Generation , author=. arXiv preprint arXiv:2312.14125 , year=. 2312.14125 , archivePrefix=
-
[16]
International Conference on Learning Representations , year=
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction , author=. International Conference on Learning Representations , year=
-
[17]
arXiv preprint arXiv:2603.04379 , year=
Helios: Real Real-Time Long Video Generation Model , author=. arXiv preprint arXiv:2603.04379 , year=
-
[18]
and others , title =
Yuan L. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[19]
arXiv preprint arXiv:2305.16291 , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=
-
[20]
and Chen, S
Kaleb, K. and Chen, S. and Gai, J. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[21]
and Li, J
Yang, Y. and Li, J. and Pan, Q. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[22]
and Zhang, J
Jiang, G. and Zhang, J. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[23]
and Zhao, W
Li, J. and Zhao, W. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[24]
and Li, J
Zhu, T. and Li, J. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[25]
and Gai, J
Chen, S. and Gai, J. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[26]
and others , title =
Wang, K. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[27]
and others , title =
Zhang, H. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[28]
and others , title =
Liu, X. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[29]
and others , title =
Gao, X. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[30]
and Lu, C
Hu, S. and Lu, C. and Clune, J. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[31]
and others , title =
Li, L. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[32]
and others , title =
Chen, Z. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[33]
and others , title =
Xu, B. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[34]
and others , title =
Zhang, Q. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[35]
and others , title =
Liu, Y. and others , title =. Computing Research Repository , volume =. 2026 , url =
2026
-
[36]
arXiv preprint arXiv:2603.18743 , year=
Memento-Skills: Let Agents Design Agents , author=. arXiv preprint arXiv:2603.18743 , year=
-
[37]
arXiv preprint arXiv:2603.17187 , year=
MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild , author=. arXiv preprint arXiv:2603.17187 , year=
-
[38]
arXiv preprint arXiv:2309.15091 , year=
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning , author=. arXiv preprint arXiv:2309.15091 , year=
-
[39]
arXiv preprint arXiv:2605.12061 , year=
SAGE: A Self-Evolving Agentic Graph-Memory Engine for Structure-Aware Associative Memory , author=. arXiv preprint arXiv:2605.12061 , year=
-
[40]
arXiv preprint arXiv:2604.02268 , year=
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization , author=. arXiv preprint arXiv:2604.02268 , year=
-
[41]
arXiv preprint arXiv:2602.08234 , year=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. arXiv preprint arXiv:2602.08234 , year=
-
[42]
arXiv preprint arXiv:2601.03509 , year=
Evolving Programmatic Skill Networks , author=. arXiv preprint arXiv:2601.03509 , year=
-
[43]
2025 , eprint=
Defining and Characterizing Reward Hacking , author=. 2025 , eprint=
2025
-
[44]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[45]
2025 , eprint=
TRAIL: Trace Reasoning and Agentic Issue Localization , author=. 2025 , eprint=
2025
-
[46]
2026 , eprint=
AgentRx: Diagnosing AI Agent Failures from Execution Trajectories , author=. 2026 , eprint=
2026
-
[47]
arXiv preprint arXiv:2311.17982 , year=
VBench: Comprehensive Benchmark Suite for Video Generative Models , author=. arXiv preprint arXiv:2311.17982 , year=
-
[48]
arXiv preprint arXiv:2406.03520 , year=
VideoPhy: Evaluating Physical Commonsense for Video Generation , author=. arXiv preprint arXiv:2406.03520 , year=
-
[49]
arXiv preprint arXiv:2412.21059 , year=
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation , author=. arXiv preprint arXiv:2412.21059 , year=
-
[50]
arXiv preprint arXiv:2504.04907 , year=
Video-Bench: Human-Aligned Video Generation Benchmark , author=. arXiv preprint arXiv:2504.04907 , year=
-
[51]
arXiv preprint arXiv:2602.21835 , year=
UniVBench: Towards Unified Evaluation for Video Foundation Models , author=. arXiv preprint arXiv:2602.21835 , year=
-
[52]
arXiv preprint arXiv:2604.19193 , year=
How Far Are Video Models from True Multimodal Reasoning? , author=. arXiv preprint arXiv:2604.19193 , year=
-
[53]
2026 , howpublished=
GPT-5.5 System Card , author=. 2026 , howpublished=
2026
-
[54]
2026 , howpublished=
Seed2.0 , author=. 2026 , howpublished=
2026
-
[55]
arXiv preprint arXiv:2604.14148 , year=
Seedance 2.0: Advancing Video Generation for World Complexity , author=. arXiv preprint arXiv:2604.14148 , year=
-
[56]
2026 , howpublished=
Claude Code Overview , author=. 2026 , howpublished=
2026
-
[57]
2026 , howpublished=
Claude Opus 4.7 System Card , author=. 2026 , howpublished=
2026
-
[58]
2026 , howpublished=
Introducing the Codex App , author=. 2026 , howpublished=
2026
-
[59]
2026 , howpublished=
DeepSeek-V4 , author=. 2026 , howpublished=
2026
-
[60]
2026 , howpublished=
What is OpenClaw? , author=. 2026 , howpublished=
2026
-
[61]
arXiv preprint arXiv:2303.16634 , year=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. arXiv preprint arXiv:2303.16634 , year=
-
[62]
arXiv preprint arXiv:2306.05685 , year=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. arXiv preprint arXiv:2306.05685 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Llm evaluators recognize and favor their own generations , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
2025 , eprint=
StoryMem: Multi-shot Long Video Storytelling with Memory , author=. 2025 , eprint=
2025
-
[65]
2026 , eprint=
VQQA: An Agentic Approach for Video Evaluation and Quality Improvement , author=. 2026 , eprint=
2026
-
[66]
2025 , eprint=
Evaluation Agent: Efficient and Promptable Evaluation Framework for Visual Generative Models , author=. 2025 , eprint=
2025
-
[67]
2026 , eprint=
LoL: Longer than Longer, Scaling Video Generation to Hour , author=. 2026 , eprint=
2026
-
[68]
2025 , eprint=
Stable Video Infinity: Infinite-Length Video Generation with Error Recycling , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
LoViC: Efficient Long Video Generation with Context Compression , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.