One Stone, Three Birds: Self-adaptive Optimal Transport for Multi-VLM Selection, Adaptation, and Ensembling
Pith reviewed 2026-06-27 19:55 UTC · model grok-4.3
The pith
A single consensus transport plan from multiple VLMs solves selection, adaptation, and ensembling without labels or training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
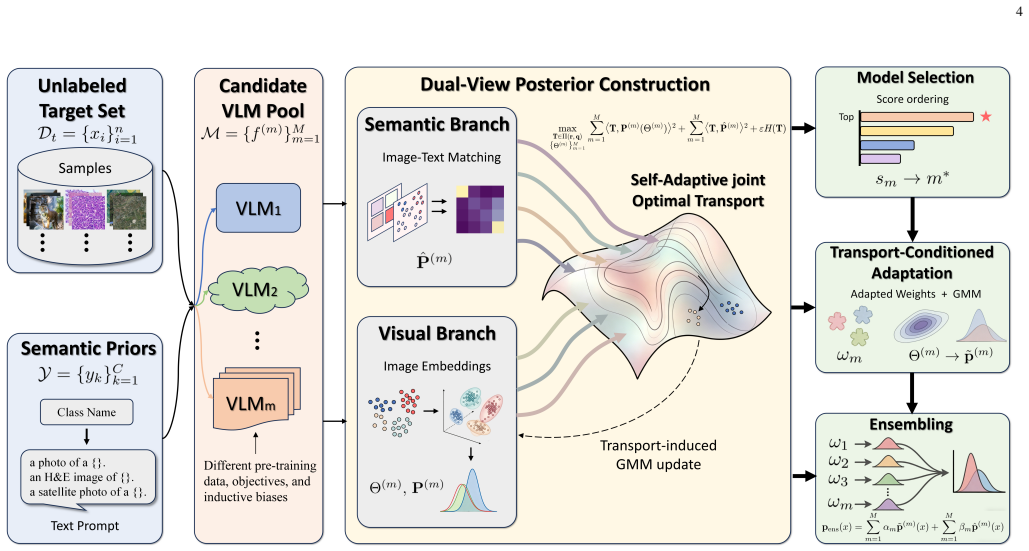
The central claim is that a trustworthy sample-class structure latent in the target set can be recovered by a self-adaptive optimal transport plan computed from the outputs of several frozen candidate VLMs, and that this single plan is sufficient to perform model selection by ranking combined semantic and visual reliability, target adaptation by fitting transport-conditioned visual classifiers, and ensembling by reliability-aware probabilistic integration.
What carries the argument
Self-adaptive optimal transport plan that estimates a consensus sample-to-class assignment from multiple VLM predictions without parameter updates.
If this is right
- Model selection reduces to ranking the reliability scores induced by the single transport plan.
- Target adaptation is obtained by training visual classifiers conditioned on the transport assignments.
- Ensembling is performed by reliability-weighted probabilistic combination of the models.
- All three tasks are solved in one forward pass over the frozen VLMs with no gradient updates.
Where Pith is reading between the lines
- The same transport structure could be reused for other downstream tasks that also require sample-to-class assignments, such as active learning or pseudo-label refinement.
- The method implies that optimal transport may act as a general-purpose consensus layer whenever multiple models observe the same unlabeled data.
- Testing the framework on candidate pools that include both general and highly specialized VLMs would reveal how much domain diversity is needed for the complementary-evidence assumption to hold.
Load-bearing premise
Outputs from different VLMs supply complementary evidence for the underlying sample-class structure even when their individual predictions conflict on the unlabeled target set.
What would settle it
Run the method on a labeled cross-domain benchmark; if the consensus plan produces worse model ranking accuracy or lower adaptation accuracy than the best single VLM or than simple averaging, the claim is falsified.
Figures


read the original abstract
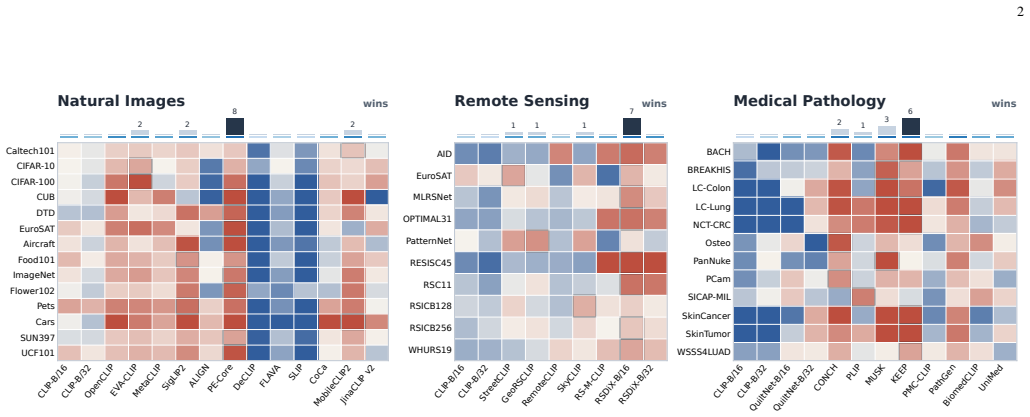
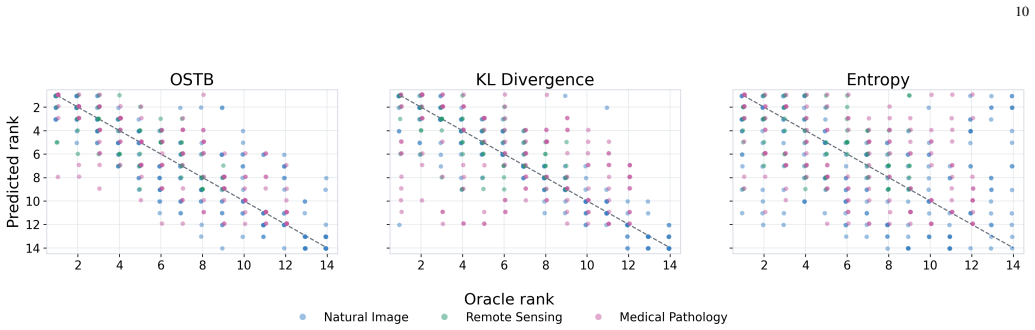
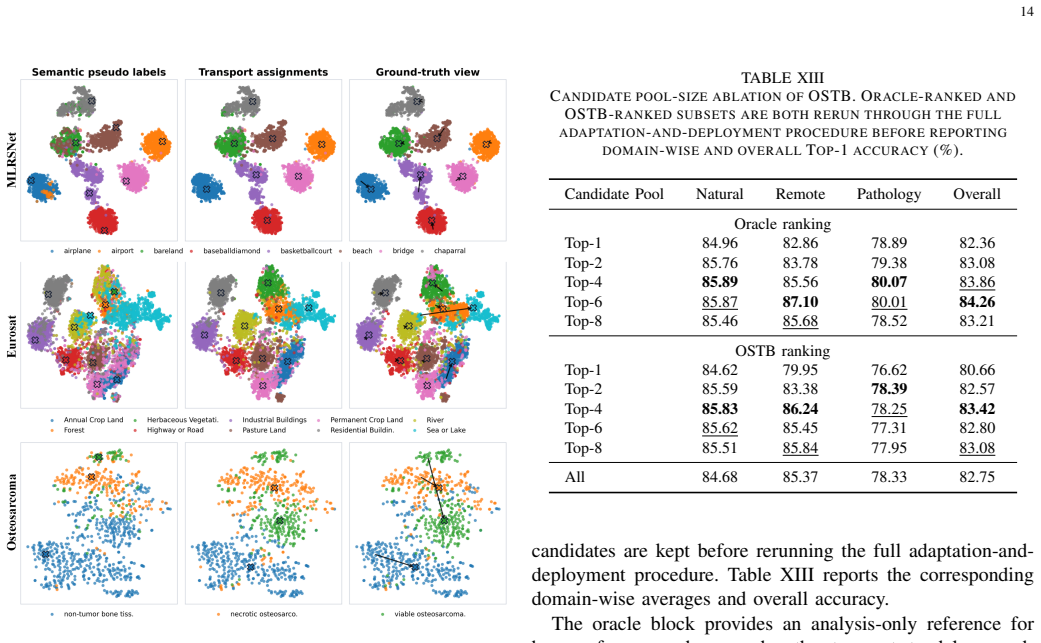
Vision-language models (VLMs) enable visual recognition from semantic class descriptions, which makes them attractive when target annotations are scarce or unavailable. Most deployment pipelines, however, first choose a single VLM and then adapt that model to the unlabeled target set. This single-backbone paradigm hides a critical assumption: the selected VLM is already compatible with the target domain. In realistic cross-domain deployment, several general-purpose and domain-specialized VLMs may be plausible, yet no instance-level target labels are available to identify the reliable ones. Deployment therefore requires a coupled solution for model selection, target adaptation, and prediction integration. We revisit this problem from a system-level multi-VLM perspective. Our central observation is that the three decisions above depend on the same latent object: a trustworthy sample-class structure in the target set. Different VLMs may encode different transfer biases and produce conflicting predictions, but their outputs can still provide complementary evidence for estimating this structure. We propose One Stone, Three Birds, a training-free framework based on self-adaptive optimal transport. Given a pool of frozen candidate VLMs, OSTB estimates a consensus sample-to-class transport plan without updating VLM parameters. The learned transport structure is then reused for all deployment objectives: model selection is performed by ranking the combined semantic and visual reliability induced by the consensus plan; target adaptation is obtained by fitting transport-conditioned visual classifiers; and ensembling is implemented through reliability-aware probabilistic integration. Extensive experiments on natural-image, remote-sensing, and medical-pathology benchmarks show that OSTB improves model ranking, adaptation stability, and ensemble robustness under heterogeneous candidate pools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'One Stone, Three Birds' (OSTB), a training-free framework using self-adaptive optimal transport to estimate a consensus sample-to-class transport plan from multiple frozen VLMs' outputs on an unlabeled target set. This plan is then reused for model selection (ranking by semantic and visual reliability), target adaptation (fitting transport-conditioned visual classifiers), and ensembling (reliability-aware probabilistic integration). Experiments on natural-image, remote-sensing, and medical-pathology benchmarks demonstrate improvements in model ranking, adaptation stability, and ensemble robustness.
Significance. If the central claim holds, the work offers a practical, unified solution for deploying multiple VLMs in label-scarce cross-domain settings without requiring target annotations or parameter updates. The training-free aspect, the shared latent structure premise, and the empirical results across three domains are strengths that could influence multi-model deployment strategies in computer vision.
major comments (2)
- [Abstract] Abstract (central observation paragraph): the premise that 'different VLMs may encode different transfer biases and produce conflicting predictions, but their outputs can still provide complementary evidence for estimating this structure' is load-bearing for all three tasks, yet no concrete test, ablation, or failure case is described to bound when complementarity holds under conflict.
- [Abstract] Abstract (method description): the transport plan is presented as simultaneously defining reliability for selection, adaptation, and ensembling while remaining 'self-adaptive' and training-free; without the explicit estimation equations it is unclear whether the plan is recovered from VLM outputs alone or implicitly depends on a fitted quantity derived from the same outputs.
minor comments (1)
- The abstract states 'extensive experiments' but provides no details on the number of candidate VLMs, specific datasets, or comparison baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (central observation paragraph): the premise that 'different VLMs may encode different transfer biases and produce conflicting predictions, but their outputs can still provide complementary evidence for estimating this structure' is load-bearing for all three tasks, yet no concrete test, ablation, or failure case is described to bound when complementarity holds under conflict.
Authors: We agree that the complementarity premise is central to the framework and that the current manuscript does not sufficiently bound the conditions under which it holds. In the revised version we will add a new subsection (in the experiments or analysis section) containing (i) controlled ablations that systematically vary the level of prediction conflict among the VLMs (e.g., by selecting subsets with increasing disagreement or by injecting calibrated label noise) and (ii) a failure-case study that identifies regimes where the consensus transport plan ceases to improve over single-VLM baselines. These additions will make the scope and limitations of the central observation explicit. revision: yes
-
Referee: [Abstract] Abstract (method description): the transport plan is presented as simultaneously defining reliability for selection, adaptation, and ensembling while remaining 'self-adaptive' and training-free; without the explicit estimation equations it is unclear whether the plan is recovered from VLM outputs alone or implicitly depends on a fitted quantity derived from the same outputs.
Authors: We acknowledge that the abstract does not contain the estimation equations, which can leave the precise origin of the transport plan ambiguous. The plan is recovered exclusively from the frozen VLM output distributions on the unlabeled target set via a self-adaptive optimal-transport procedure whose only variables are the transport couplings themselves; no additional parameters are fitted. In the revision we will (i) insert a concise reference to the key estimation equation in the abstract and (ii) expand the method section to present the full self-adaptive OT formulation with explicit notation showing that all quantities are derived directly from the VLM logits. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from stated premise
full rationale
The paper's central claim follows directly from the explicit observation that model selection, adaptation, and ensembling share a latent sample-class structure recoverable from complementary VLM outputs via self-adaptive OT. The transport plan is estimated from frozen VLM predictions on the target set and then applied to the three tasks; this reuse is a logical consequence of the premise rather than a definitional loop or fitted quantity renamed as prediction. No equations, self-citations, uniqueness theorems, or ansatzes are shown reducing the result to its inputs by construction. The framework is described as training-free with empirical support across benchmarks, making the derivation independent of the target quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different VLMs may encode different transfer biases and produce conflicting predictions, but their outputs can still provide complementary evidence for estimating this structure.
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 139, 2021, ...
2021
-
[2]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H ´enaff, J. Harmsen, A. Steiner, and X. Zhai, “SigLIP 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[3]
Reproducible scaling laws for contrastive language-image learning,
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev, “Reproducible scaling laws for contrastive language-image learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 2818–2829
2023
-
[4]
EV A-CLIP: Improved training techniques for CLIP at scale,
Q. Sun, Y . Fang, L. Wu, X. Wang, and Y . Cao, “EV A-CLIP: Improved training techniques for CLIP at scale,”arXiv preprint arXiv:2303.15389, 2023
Pith/arXiv arXiv 2023
-
[5]
Demystifying CLIP data,
H. Xu, S. Xie, X. Tan, P.-Y . Huang, R. Howes, V . Sharma, S.-W. Li, G. Ghosh, L. Zettlemoyer, and C. Feichtenhofer, “Demystifying CLIP data,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[6]
RemoteCLIP: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “RemoteCLIP: A vision language foundation model for remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1– 16, 2024
2024
-
[7]
RS5M and GeoRSCLIP: A large scale vision-language dataset and a large vision-language model for remote sensing,
Z. Zhang, T. Zhao, Y . Guo, and J. Yin, “RS5M and GeoRSCLIP: A large scale vision-language dataset and a large vision-language model for remote sensing,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–23, 2024
2024
-
[8]
A multimodal biomedical foundation model trained from fifteen million image-text pairs,
S. Zhang, Y . Xu, N. Usuyama, H. Xu, J. Bagga, R. Tinn, S. Preston, R. Rao, M. Wei, N. Valluri, C. Wong, A. Tupini, Y . Wang, M. Mazzola, S. Shukla, L. Liden, J. Gao, A. Crabtree, B. Piening, C. Bifulco, M. P. Lungren, T. Naumann, S. Wang, and H. Poon, “A multimodal biomedical foundation model trained from fifteen million image-text pairs,”NEJM AI, vol. 2...
2025
-
[9]
A visual-language foundation model for pathology image analysis using medical twitter,
Z. Huang, F. Bianchi, M. Yuksekgonul, T. J. Montine, and J. Zou, “A visual-language foundation model for pathology image analysis using medical twitter,”Nature Medicine, vol. 29, no. 9, pp. 2307–2316, 2023
2023
-
[10]
A visual-language foundation model for computational pathology,
M. Y . Lu, B. Chen, D. F. K. Williamson, R. J. Chen, I. Liang, T. Ding, G. Jaume, I. Odintsov, L. P. Le, G. Gerber, A. V . Parwani, A. Zhang, and F. Mahmood, “A visual-language foundation model for computational pathology,”Nature Medicine, vol. 30, no. 3, pp. 863–874, 2024
2024
-
[11]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”International Journal of Computer Vision, vol. 130, no. 9, pp. 2337–2348, 2022
2022
-
[12]
Conditional prompt learning for vision-language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16 816–16 825
2022
-
[13]
LaFTer: Label-free tuning of zero-shot classifier using language and unlabeled image collections,
M. J. Mirza, L. Karlinsky, W. Lin, M. Kozinski, H. Possegger, R. Feris, and H. Bischof, “LaFTer: Label-free tuning of zero-shot classifier using language and unlabeled image collections,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 5765– 5777
2023
-
[14]
Test-time prompt tuning for zero-shot generalization in vision-language models,
M. Shu, W. Nie, D.-A. Huang, Z. Yu, T. Goldstein, A. Anandkumar, and C. Xiao, “Test-time prompt tuning for zero-shot generalization in vision-language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 14 274–14 289
2022
-
[15]
Transductive zero-shot and few-shot CLIP,
S. Martin, Y . Huang, F. Shakeri, J.-C. Pesquet, and I. Ben Ayed, “Transductive zero-shot and few-shot CLIP,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 28 816–28 826
2024
-
[16]
Frustratingly easy test-time adaptation of vision-language models,
M. Farina, G. Franchi, G. Iacca, M. Mancini, and E. Ricci, “Frustratingly easy test-time adaptation of vision-language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 129 062–129 093
2024
-
[17]
Efficient test-time adaptation of vision-language models,
A. Karmanov, D. Guan, S. Lu, A. El Saddik, and E. Xing, “Efficient test-time adaptation of vision-language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 14 162–14 171
2024
-
[18]
Computational optimal transport: With appli- cations to data science,
G. Peyr ´e and M. Cuturi, “Computational optimal transport: With appli- cations to data science,”Foundations and Trends® in Machine Learning, vol. 11, no. 5–6, pp. 355–607, 2019
2019
-
[19]
Sota: Self-adaptive optimal transport for zero-shot classification with multiple foundation models,
Z. Hu, Q. Xu, Y . Duan, Y . Tai, and H. Li, “Sota: Self-adaptive optimal transport for zero-shot classification with multiple foundation models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 26 624–26 634
2026
-
[20]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. V . Le, Y .- H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inProceedings of the 38th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 139, 2021, pp. 4904– 4916
2021
-
[21]
FLA V A: A foundational language and vision alignment model,
A. Singh, R. Hu, V . Goswami, G. Couairon, W. Galuba, M. Rohrbach, and D. Kiela, “FLA V A: A foundational language and vision alignment model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 15 617–15 629
2022
-
[22]
CoCa: Contrastive captioners are image-text foundation mod- els,
J. Yu, Z. Wang, V . Vasudevan, L. Yeung, M. Seyedhosseini, and Y . Wu, “CoCa: Contrastive captioners are image-text foundation mod- els,”Transactions on Machine Learning Research, 2022
2022
-
[23]
Jina-CLIP- v2: Multilingual multimodal embeddings for text and images,
A. Koukounas, G. Mastrapas, S. Eslami, B. Wang, M. K. Akram, M. G ¨unther, I. Mohr, S. Sturua, N. Wang, and H. Xiao, “Jina-CLIP- v2: Multilingual multimodal embeddings for text and images,”arXiv preprint arXiv:2412.08802, 2024. 17
arXiv 2024
-
[24]
Perception encoder: The best visual embeddings are not at the output of the network,
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheed, J. Wang, M. Monteiro, H. Xu, S. Dong, N. Ravi, D. Li, P. Doll ´ar, and C. Feichtenhofer, “Perception encoder: The best visual embeddings are not at the output of the network,”arXiv preprint arXiv:2504.13181, 2025
Pith/arXiv arXiv 2025
-
[25]
M. U. Khattak, S. Kunhimon, M. Naseer, S. Khan, and F. S. Khan, “UniMed-CLIP: Towards a unified image-text pretraining paradigm for diverse medical imaging modalities,”arXiv preprint arXiv:2412.10372, 2024
arXiv 2024
-
[26]
Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis,
X. Zhou, L. Sun, D. He, W. Guan, G. Wang, R. Wang, L. Wang, X. Yuan, X. Sun, Y . Zhang, K. Sun, Y . Wang, and W. Xie, “Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis,”Cancer Cell, vol. 44, no. 4, pp. 777–791, 2026
2026
-
[27]
PMC-CLIP: Contrastive language-image pre-training using biomedical documents,
W. Lin, Z. Zhao, X. Zhang, C. Wu, Y . Zhang, Y . Wang, and W. Xie, “PMC-CLIP: Contrastive language-image pre-training using biomedical documents,” inMedical Image Computing and Computer Assisted In- tervention – MICCAI 2023, 2023, pp. 525–536
2023
-
[28]
PathGen-1.6M: 1.6 million pathology image-text pairs generation through multi-agent collaboration,
Y . Sun, Y . Zhang, Y . Si, C. Zhu, K. Zhang, Z. Shui, J. Li, X. Gong, X. Lyu, T. Lin, and L. Yang, “PathGen-1.6M: 1.6 million pathology image-text pairs generation through multi-agent collaboration,” inPro- ceedings of the International Conference on Learning Representations (ICLR), vol. 2025, 2025, pp. 94 611–94 653
2025
-
[29]
A vision– language foundation model for precision oncology,
J. Xiang, X. Wang, X. Zhang, Y . Xi, F. Eweje, Y . Chen, Y . Li, C. Bergstrom, M. Gopaulchan, T. Kim, K.-H. Yu, S. Willens, F. M. Olguin, J. J. Nirschl, J. Neal, M. Diehn, S. Yang, and R. Li, “A vision– language foundation model for precision oncology,”Nature, vol. 638, pp. 769–778, 2025
2025
-
[30]
Quilt-1m: One million image-text pairs for histopathology,
W. O. Ikezogwo, M. S. Seyfioglu, F. Ghezloo, D. S. C. Geva, F. S. Mohammed, P. K. Anand, R. Krishna, and L. Shapiro, “Quilt-1m: One million image-text pairs for histopathology,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 37 995–38 017
2023
-
[31]
SkyScript: A large and semantically diverse vision-language dataset for remote sens- ing,
Z. Wang, R. Prabha, T. Huang, J. Wu, and R. Rajagopal, “SkyScript: A large and semantically diverse vision-language dataset for remote sens- ing,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 38, no. 6, 2024, pp. 5805–5813
2024
-
[32]
Multilingual vision- language pre-training for the remote sensing domain,
J. D. Silva, J. Magalh ˜aes, D. Tuia, and B. Martins, “Multilingual vision- language pre-training for the remote sensing domain,” inProceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL), 2024, pp. 220–232
2024
-
[33]
RSDiX: Lightweight and data-efficient VLMs for remote sensing through self-distillation,
A. Terlizzi, A. Nazzaro, L. Bernardi, F. Bardozzo, and R. Tagliaferri, “RSDiX: Lightweight and data-efficient VLMs for remote sensing through self-distillation,” inProceedings of the International Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–10
2025
-
[34]
Learning generalized zero- shot learners for open-domain image geolocalization,
L. Haas, S. Alberti, and M. Skreta, “Learning generalized zero- shot learners for open-domain image geolocalization,”arXiv preprint arXiv:2302.00275, 2023
arXiv 2023
-
[35]
COSMIC: Clique-oriented semantic multi-space integration for robust CLIP test-time adaptation,
F. Huang, J. Jiang, Q. Jiang, H. Li, F. N. Khan, and Z. Wang, “COSMIC: Clique-oriented semantic multi-space integration for robust CLIP test-time adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 9772– 9781
2025
-
[36]
Dual prototype evolving for test-time generalization of vision-language models,
C. Zhang, S. Stepputtis, K. Sycara, and Y . Xie, “Dual prototype evolving for test-time generalization of vision-language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 32 111–32 136
2024
-
[37]
Dual memory networks: A versatile adaptation approach for vision-language models,
Y . Zhang, W. Zhu, H. Tang, Z. Ma, K. Zhou, and L. Zhang, “Dual memory networks: A versatile adaptation approach for vision-language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 28 718–28 728
2024
-
[38]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features withou...
2024
-
[39]
Open- vocabulary panoptic segmentation with text-to-image diffusion models,
J. Xu, S. Liu, A. Vahdat, W. Byeon, X. Wang, and S. De Mello, “Open- vocabulary panoptic segmentation with text-to-image diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 2955–2966
2023
-
[40]
Segment everything everywhere all at once,
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee, “Segment everything everywhere all at once,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[41]
Grounded SAM: Assembling open-world models for diverse visual tasks,
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded SAM: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
Pith/arXiv arXiv 2024
-
[42]
SAM 3: Segment anything with concepts,
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwalaet al., “SAM 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[43]
An information-theoretic approach to transferability in task transfer learning,
Y . Bao, Y . Li, S.-L. Huang, L. Zhang, L. Zheng, A. R. Zamir, and L. J. Guibas, “An information-theoretic approach to transferability in task transfer learning,” in2019 IEEE International Conference on Image Processing (ICIP), 2019, pp. 2309–2313
2019
-
[44]
LEEP: A new measure to evaluate transferability of learned representations,
C. Nguyen, T. Hassner, M. Seeger, and C. Archambeau, “LEEP: A new measure to evaluate transferability of learned representations,” in Proceedings of the 37th International Conference on Machine Learning (ICML), vol. 119, 2020, pp. 7294–7305
2020
-
[45]
LogME: Practical assessment of pre-trained models for transfer learning,
K. You, Y . Liu, J. Wang, and M. Long, “LogME: Practical assessment of pre-trained models for transfer learning,” inProceedings of the 38th International Conference on Machine Learning (ICML), vol. 139, 2021, pp. 12 133–12 143
2021
-
[46]
Frustratingly easy transferability estimation,
L.-K. Huang, J. Huang, Y . Rong, Q. Yang, and Y . Wei, “Frustratingly easy transferability estimation,” inProceedings of the 39th International Conference on Machine Learning (ICML), vol. 162, 2022, pp. 9201– 9225
2022
-
[47]
Scalable diverse model selec- tion for accessible transfer learning,
D. Bolya, R. Mittapalli, and J. Hoffman, “Scalable diverse model selec- tion for accessible transfer learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 19 301–19 312
2021
-
[48]
Transferability metrics for selecting source model ensembles,
A. Agostinelli, J. Uijlings, T. Mensink, and V . Ferrari, “Transferability metrics for selecting source model ensembles,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 7936–7946
2022
-
[49]
Building a winning team: Selecting source model ensembles using a submodular transferability estimation approach,
V . K. B, S. Bachu, T. Garg, N. L. Narasimhan, R. Konuru, and V . N. Balasubramanian, “Building a winning team: Selecting source model ensembles using a submodular transferability estimation approach,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11 609–11 620
2023
-
[50]
How stable are transferability metrics evaluations?
A. Agostinelli, M. P ´andy, J. Uijlings, T. Mensink, and V . Ferrari, “How stable are transferability metrics evaluations?” inProceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 303–321
2022
-
[51]
Rethinking model selection in VLM through the lens of Gromov-Wasserstein distance,
M. Li, Y . Liu, J. Ma, E. Osborne, B. Han, and T. Liu, “Rethinking model selection in VLM through the lens of Gromov-Wasserstein distance,” arXiv preprint arXiv:2605.01325, 2026
Pith/arXiv arXiv 2026
-
[52]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[53]
Model soups: Averaging weights of multiple fine- tuned models improves accuracy without increasing inference time,
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith, and L. Schmidt, “Model soups: Averaging weights of multiple fine- tuned models improves accuracy without increasing inference time,” in Proceedings of the 39th International Conference on Machine Learning (ICML), vol. 162, 2022
2022
-
[54]
Unified optimal transport framework for universal domain adaptation,
W. Chang, Y . Shi, H. D. Tuan, and J. Wang, “Unified optimal transport framework for universal domain adaptation,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 29 512– 29 524
2022
-
[55]
PLOT: Prompt learning with optimal transport for vision-language models,
G. Chen, W. Yao, X. Song, X. Li, Y . Rao, and K. Zhang, “PLOT: Prompt learning with optimal transport for vision-language models,” inThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[56]
Recover and match: Open-vocabulary multi-label recognition through knowledge-constrained optimal transport,
H. Tan, Z. Tan, J. Li, A. Liu, J. Wan, and Z. Lei, “Recover and match: Open-vocabulary multi-label recognition through knowledge-constrained optimal transport,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 4650– 4660
2025
-
[57]
AWT: Transferring vision- language models via augmentation, weighting, and transportation,
Y . Zhu, Y . Ji, Z. Zhao, G. Wu, and L. Wang, “AWT: Transferring vision- language models via augmentation, weighting, and transportation,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 25 561–25 591
2024
-
[58]
A tutorial on MM algorithms,
D. R. Hunter and K. Lange, “A tutorial on MM algorithms,”The American Statistician, vol. 58, no. 1, pp. 30–37, 2004
2004
-
[59]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255
2009
-
[60]
SUN database: Large-scale scene recognition from abbey to zoo,
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “SUN database: Large-scale scene recognition from abbey to zoo,” inPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010, pp. 3485–3492
2010
-
[61]
Fine- grained visual classification of aircraft,
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine- grained visual classification of aircraft,”arXiv preprint arXiv:1306.5151, 2013. 18
Pith/arXiv arXiv 2013
-
[62]
EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classi- fication,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classi- fication,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, no. 7, pp. 2217–2226, 2019
2019
-
[63]
3D object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3D object representations for fine-grained categorization,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops (ICCVW), 2013, pp. 554–561
2013
-
[64]
Food-101: Mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101: Mining discriminative components with random forests,” inComputer Vision – ECCV 2014. Springer, 2014, pp. 446–461
2014
-
[65]
Cats and dogs,
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. V . Jawahar, “Cats and dogs,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 3498–3505
2012
-
[66]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” inProceedings of the Sixth Indian Conference on Computer Vision, Graphics & Image Processing, 2008, pp. 722–729
2008
-
[67]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,
L. Fei-Fei, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” inProceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Work- shops, 2004, p. 178
2004
-
[68]
Describing textures in the wild,
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 3606– 3613
2014
-
[69]
UCF101: A dataset of 101 human actions classes from videos in the wild,
K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
Pith/arXiv arXiv 2012
-
[70]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep., 2009
2009
-
[71]
The caltech-UCSD birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-UCSD birds-200-2011 dataset,” inCalifornia Institute of Tech- nology Technical Report CNS-TR-2011-001, 2011
2011
-
[72]
Proportion constrained weakly supervised histopathology image clas- sification,
J. Silva-Rodr ´ıguez, A. Schmidt, M. A. Sales, R. Molina, and V . Naranjo, “Proportion constrained weakly supervised histopathology image clas- sification,”Computers in Biology and Medicine, vol. 147, p. 105714, 2022
2022
-
[73]
Rotation equivariant CNNs for digital pathology,
B. S. Veeling, J. Linmans, J. Winkens, T. Cohen, and M. Welling, “Rotation equivariant CNNs for digital pathology,” inMedical Im- age Computing and Computer Assisted Intervention – MICCAI 2018. Springer, 2018, pp. 210–218
2018
-
[74]
Osteosarcoma data from UT southwestern/UT dallas for viable and necrotic tumor assessment,
P. Leavey, A. Sengupta, D. Rakheja, O. Daescu, H. B. Arunachalam, and R. Mishra, “Osteosarcoma data from UT southwestern/UT dallas for viable and necrotic tumor assessment,” The Cancer Imaging Archive, 2019
2019
-
[75]
BACH: Grand challenge on breast cancer histology images,
G. Aresta, T. Ara ´ujo, S. Kwok, S. S. Chennamsetty, M. Safwan, V . Alex, B. Marami, M. Prastawa, M. Chan, M. Donovanet al., “BACH: Grand challenge on breast cancer histology images,”Medical Image Analysis, vol. 56, pp. 122–139, 2019
2019
-
[76]
A dataset for breast cancer histopathological image classification,
F. A. Spanhol, L. S. Oliveira, C. Petitjean, and L. Heutte, “A dataset for breast cancer histopathological image classification,”IEEE Transactions on Biomedical Engineering, vol. 63, no. 7, pp. 1455–1462, 2016
2016
-
[77]
Deep learning for the detection of anatomical tissue structures and neoplasms of the skin on scanned histopathological tissue sections,
K. Kriegsmann, F. L ¨obers, C. Zgorzelski, J. Kriegsmann, C. Janssen, R. R. Meliß, T. Muley, U. Sack, G. Steinbuss, and M. Kriegsmann, “Deep learning for the detection of anatomical tissue structures and neoplasms of the skin on scanned histopathological tissue sections,” Frontiers in Oncology, vol. 12, p. 1022967, 2022
2022
-
[78]
Lung and colon cancer histopathological image dataset (LC25000),
A. A. Borkowski, M. M. Bui, L. B. Thomas, C. P. Wilson, L. A. DeLand, and S. M. Mastorides, “Lung and colon cancer histopathological image dataset (LC25000),”arXiv preprint arXiv:1912.12142, 2019
arXiv 1912
-
[79]
100,000 histological images of human colorectal cancer and healthy tissue,
J. N. Kather, N. Halama, and A. Marx, “100,000 histological images of human colorectal cancer and healthy tissue,”Zenodo, 2018
2018
-
[80]
Multi-layer pseudo-supervision for histopathology tissue semantic segmentation using patch-level classification labels,
C. Han, J. Lin, J. Mai, Y . Wang, Q. Zhang, B. Zhao, X. Chen, X. Pan, Z. Shi, Z. Xuet al., “Multi-layer pseudo-supervision for histopathology tissue semantic segmentation using patch-level classification labels,” Medical Image Analysis, vol. 80, p. 102487, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.