TextEconomizer: Enhancing Lossy Text Compression with Denoising Transformers and Entropy Coding
Pith reviewed 2026-06-27 19:52 UTC · model grok-4.3
The pith
TextEconomizer uses a denoising transformer encoder-decoder with entropy coding to compress text lossily at 5.39x ratio using 153x fewer parameters than comparable models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
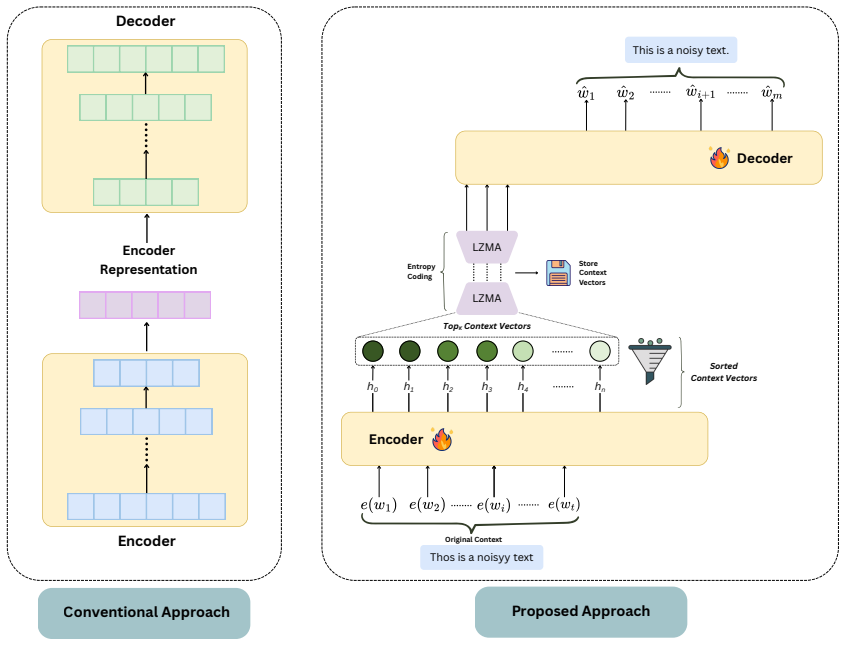
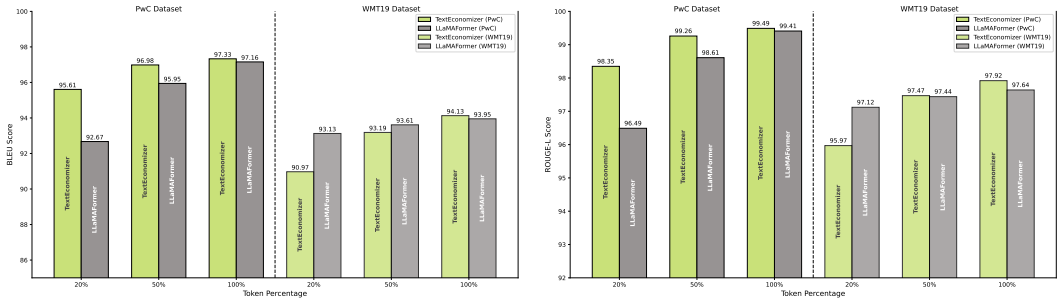
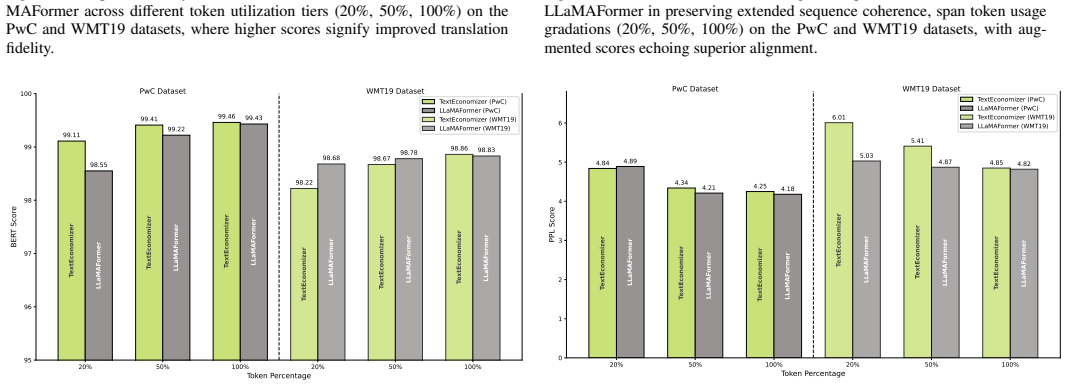
TextEconomizer is an encoder-decoder framework paired with a transformer neural network that reduces variable-sized inputs by 50% to 80% without prior knowledge of dataset dimensions. Our model achieves competitive compression ratios via entropy coding while delivering near-perfect text quality, assessed by BLEU, ROUGE, METEOR, and semantic similarity scores. TextEconomizer operates with approximately 153x fewer parameters than comparable models, achieving a 5.39x compression ratio without sacrificing semantic quality. We also evaluate an LSTM-based autoencoder achieving a state-of-the-art 67x compression ratio with 196x fewer parameters, and LLaMAFormer, a modified transformer with 263x few
What carries the argument
The encoder-decoder transformer that selects the most informative context vectors from encoder output and combines them with entropy coding for storage efficiency.
If this is right
- The framework reduces inputs by 50% to 80% on variable-sized data without prior dimension knowledge.
- It delivers a 5.39x compression ratio at 153x fewer parameters than comparable models while keeping semantic quality.
- An LSTM-based autoencoder version reaches 67x compression at 196x fewer parameters.
- LLaMAFormer keeps competitive text quality at 263x fewer parameters than ICAE.
- The overall method exceeds prior transformer models in memory efficiency paired with high-fidelity output.
Where Pith is reading between the lines
- The same selection of context vectors and entropy coding could reduce storage needs for large text archives on limited hardware.
- The denoising aspect may help the approach handle real-world data that contains typos or transcription errors.
- Similar encoder-decoder structures might adapt to compress other ordered data such as program code or logs.
- Combining this with existing large language models could lower the cost of keeping generated text outputs.
Load-bearing premise
The transformer reliably identifies the most informative context vectors from encoder output and uses entropy coding to store them efficiently while preserving output quality even on noisy text.
What would settle it
Testing the model on a collection of noisy text inputs and finding that BLEU, ROUGE, or semantic similarity scores fall below those of standard non-transformer baselines would show the performance claims do not hold.
Figures
read the original abstract
Lossy text compression reduces data size while preserving core meaning, making it well-suited for summarization, automated analysis, and digital archives. Despite the dominance of transformer-based models in language modeling, integrating context vectors and entropy coding into Sequence-to-Sequence (Seq2Seq) generation remains underexplored. A key challenge lies in identifying the most informative context vectors from encoder output and incorporating entropy coding to enhance storage efficiency while maintaining high-quality outputs, even under noisy text. We introduce TextEconomizer, an encoder-decoder framework paired with a transformer neural network that reduces variable-sized inputs by 50% to 80% without prior knowledge of dataset dimensions. Our model achieves competitive compression ratios via entropy coding while delivering near-perfect text quality, assessed by BLEU, ROUGE, METEOR, and semantic similarity scores. TextEconomizer operates with approximately 153x fewer parameters than comparable models, achieving a 5.39x compression ratio without sacrificing semantic quality. We also evaluate an LSTM-based autoencoder achieving a state-of-the-art 67x compression ratio with 196x fewer parameters, and LLaMAFormer, a modified transformer with 263x fewer parameters than ICAE while maintaining competitive text quality. TextEconomizer significantly surpasses existing transformer-based models in balancing memory efficiency and high-fidelity outputs, marking a breakthrough in lossy compression with optimal space utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TextEconomizer, an encoder-decoder framework paired with a transformer neural network for lossy text compression that integrates context vectors and entropy coding. It claims to reduce variable-sized inputs by 50% to 80% without prior knowledge of dataset dimensions, achieve a 5.39x compression ratio with approximately 153x fewer parameters than comparable models while maintaining near-perfect quality (assessed by BLEU, ROUGE, METEOR, and semantic similarity), and also evaluates an LSTM-based autoencoder achieving 67x compression with 196x fewer parameters plus LLaMAFormer with 263x fewer parameters than ICAE.
Significance. If the claimed compression ratios, parameter reductions, and quality preservation hold under proper validation, the work would represent a notable advance in parameter-efficient lossy text compression, enabling more practical deployment in summarization, analysis, and archiving tasks by addressing the integration of entropy coding with Seq2Seq models.
major comments (1)
- Abstract: The abstract asserts specific numerical results (5.39x ratio, 153x parameter reduction, quality scores) and claims of near-perfect quality without any data, experimental setup, derivations, error bars, or methods; central claims lack any supporting evidence in the provided text.
Simulated Author's Rebuttal
We thank the referee for their review. The single major comment concerns the abstract's presentation of results. We address it directly below.
read point-by-point responses
-
Referee: Abstract: The abstract asserts specific numerical results (5.39x ratio, 153x parameter reduction, quality scores) and claims of near-perfect quality without any data, experimental setup, derivations, error bars, or methods; central claims lack any supporting evidence in the provided text.
Authors: Abstracts are concise summaries by design and do not contain full experimental details, derivations, or error bars; those appear in the body of the manuscript (Sections 3–5). The provided manuscript text includes the experimental setup, datasets, evaluation metrics (BLEU, ROUGE, METEOR, semantic similarity), and parameter counts supporting the reported figures. If the referee received only the abstract, the full paper supplies the requested evidence. revision: no
Circularity Check
No derivation chain or equations present; claims are empirical assertions only
full rationale
The supplied text (abstract plus placeholder for full manuscript) contains no equations, no derivation steps, no fitted parameters, no self-citations to uniqueness theorems, and no algorithmic reductions that could be inspected for circularity. All performance numbers (5.39x compression, 153x parameter reduction, 67x LSTM ratio) are presented as experimental outcomes rather than derived results. With no load-bearing derivation chain to walk, the circularity score is 0 and steps array is empty.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015, , 579, A101
Aladro, R., Martín, S., Riquelme, D., et al. 2015, , 579, A101
2015
-
[2]
, author Goel, R
author Acharya, A. , author Goel, R. , author Metallinou, A. , author Dhillon, I. , year 2019 . title Online embedding compression for text classification using low rank matrix factorization , in: booktitle Proceedings of the aaai conference on artificial intelligence , pp. pages 6196--6203
2019
-
[3]
author Aghanya, N. , author Li, J. , author Wang, K. , year 2025 . title The lossy horizon: Error-bounded predictive coding for lossy text compression (episode i) . journal arXiv preprint arXiv:2510.22207
arXiv 2025
-
[4]
author Bahdanau, D. , year 2014 . title Neural machine translation by jointly learning to align and translate . journal arXiv preprint arXiv:1409.0473
Pith/arXiv arXiv 2014
-
[5]
, author Lavie, A
author Banerjee, S. , author Lavie, A. , year 2005 . title Meteor: An automatic metric for mt evaluation with improved correlation with human judgments , in: booktitle Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pp. pages 65--72
2005
-
[6]
author Barrault, L. , author Bojar, O. , author Costa-juss \`a , M.R. , author Federmann, C. , author Fishel, M. , author Graham, Y. , author Haddow, B. , author Huck, M. , author Koehn, P. , author Malmasi, S. , author Monz, C. , author M \"u ller, M. , author Pal, S. , author Post, M. , author Zampieri, M. , year 2019 . title Findings of the 2019 confer...
-
[7]
, author Tharaniesh, P.R
author Bhuvaneswari, R. , author Tharaniesh, P.R. , year 2023 . title Exploring chatgpt for email content compression and summarization , in: booktitle 2023 4th International Conference on Communication, Computing and Industry 6.0 (C216) , organization IEEE . pp. pages 01--07
2023
-
[8]
author Bijoy, M.H. , author Faria, M.F.A. , author E Sobhani, M. , author Ferdoush, T. , author Shatabda, S. , year 2023 . title Advancing B angla punctuation restoration by a monolingual transformer-based method and a large-scale corpus , in: editor Alam, F. , editor Kar, S. , editor Chowdhury, S.A. , editor Sadeque, F. , editor Amin, R. (Eds.), booktitl...
-
[9]
, author Buck, C
author Bojar, O. , author Buck, C. , author Federmann, C. , author Haddow, B. , author Koehn, P. , author Leveling, J. , author Monz, C. , author Pecina, P. , author Post, M. , author Saint-Amand, H. , et al., year 2014 . title Findings of the 2014 workshop on statistical machine translation , in: booktitle Proceedings of the ninth workshop on statistical...
2014
-
[10]
, author Macdonald, C
author Catena, M. , author Macdonald, C. , author Ounis, I. , year 2014 . title On inverted index compression for search engine efficiency , in: editor de Rijke, M. , editor Kenter, T. , editor de Vries, A.P. , editor Zhai, C. , editor de Jong, F. , editor Radinsky, K. , editor Hofmann, K. (Eds.), booktitle Advances in Information Retrieval , publisher Sp...
2014
-
[11]
author Chevalier, A. , author Wettig, A. , author Ajith, A. , author Chen, D. , year 2023 . title Adapting language models to compress contexts , in: editor Bouamor, H. , editor Pino, J. , editor Bali, K. (Eds.), booktitle Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , publisher Association for Computational Lingu...
-
[12]
author Chung, J. , author Gulcehre, C. , author Cho, K. , author Bengio, Y. , year 2014 . title Empirical evaluation of gated recurrent neural networks on sequence modeling . journal arXiv preprint arXiv:1412.3555
Pith/arXiv arXiv 2014
-
[13]
, author Kucherawy, M
author Collet, Y. , author Kucherawy, M. , year 2021 . title RFC 8878: Zstandard Compression and the 'application/zstd' Media Type . type Request for Comments number 8878 . RFC Editor. address USA
2021
-
[14]
, year 2023
author CONSOLVO, A.C.M.a.I.B. , year 2023 . title Hardware Available on Kaggle . howpublished https://www.kaggle.com/code/bconsolvo/hardware-available-on-kaggle/notebook . note [Online; accessed 2025-12-05]
2023
-
[15]
author Delétang, G. , author Ruoss, A. , author Duquenne, P.A. , author Catt, E. , author Genewein, T. , author Mattern, C. , author Grau-Moya, J. , author Wenliang, L.K. , author Aitchison, M. , author Orseau, L. , author Hutter, M. , author Veness, J. , year 2024 . title Language modeling is compression . https://arxiv.org/abs/2309.10668, http://arxiv.o...
Pith/arXiv arXiv 2024
-
[16]
, year 1996
author Deutsch, P. , year 1996 . title GZIP File Format Specification Version 4.3 . type Request for Comments number 1952 . RFC Editor
1996
-
[17]
, author Gailly, J.L
author Deutsch, P. , author Gailly, J.L. , year 1996 . title Zlib compressed data format specification version 3.3 . type Technical Report . Association for Computing Machinery
1996
-
[18]
author Elias, N. , author Esfahanizadeh, H. , author Kale, K. , author Vishwanath, S. , author Medard, M. , year 2025 . title Multitok: Variable-length tokenization for efficient llms adapted from lzw compression . https://arxiv.org/abs/2410.21548, http://arxiv.org/abs/2410.21548 arXiv:2410.21548
Pith/arXiv arXiv 2025
-
[19]
author Farsad, N. , author Rao, M. , author Goldsmith, A. , year 2018 . title Deep learning for joint source-channel coding of text , in: booktitle 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , publisher IEEE Press . p. pages 2326–2330 . https://doi.org/10.1109/ICASSP.2018.8461983, :10.1109/ICASSP.2018.8461983
-
[20]
author Freitag, M. , author Roy, S. , year 2018 . title Unsupervised natural language generation with denoising autoencoders , in: editor Riloff, E. , editor Chiang, D. , editor Hockenmaier, J. , editor Tsujii, J. (Eds.), booktitle Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , publisher Association for Computatio...
-
[21]
author Ge, T. , author Hu, J. , author Wang, L. , author Wang, X. , author Chen, S.Q. , author Wei, F. , year 2023 . title In-context autoencoder for context compression in a large language model . journal arXiv preprint arXiv:2307.06945
arXiv 2023
-
[22]
author Ge, T. , author Xia, H. , author Sun, X. , author Chen, S.Q. , author Wei, F. , year 2022 . title Lossless acceleration for seq2seq generation with aggressive decoding . journal arXiv preprint arXiv:2205.10350
arXiv 2022
-
[23]
, author Mas Montserrat, D
author Geleta, M. , author Mas Montserrat, D. , author Giro-i Nieto, X. , author Ioannidis, A.G. , year 2023 . title Deep variational autoencoders for population genetics . journal biorxiv , pages 2023--09
2023
-
[24]
author Goyal, M. , author Tatwawadi, K. , author Chandak, S. , author Ochoa, I. , year 2018 . title Deepzip: Lossless data compression using recurrent neural networks . journal arXiv preprint arXiv:1811.08162
Pith/arXiv arXiv 2018
-
[25]
, author Pleiss, G
author Guo, C. , author Pleiss, G. , author Sun, Y. , author Weinberger, K.Q. , year 2017 . title On calibration of modern neural networks , in: booktitle International conference on machine learning , organization PMLR . pp. pages 1321--1330
2017
-
[26]
, author Schmidhuber, J
author Hochreiter, S. , author Schmidhuber, J. , year 1997 . title Long short-term memory . journal Neural computation volume 9 , pages 1735--1780
1997
-
[27]
author Hu, E.J. , author Shen, Y. , author Wallis, P. , author Allen-Zhu, Z. , author Li, Y. , author Wang, S. , author Wang, L. , author Chen, W. , year 2021 . title Lora: Low-rank adaptation of large language models . https://arxiv.org/abs/2106.09685, http://arxiv.org/abs/2106.09685 arXiv:2106.09685
Pith/arXiv arXiv 2021
-
[28]
author Huang, C. , author Xie, Y. , author Jiang, Z. , author Lin, J. , author Li, M. , year 2023 . title Approximating human-like few-shot learning with gpt-based compression . journal arXiv preprint arXiv:2308.06942
arXiv 2023
-
[29]
, year 1976
author Jelinek, F. , year 1976 . title Continuous speech recognition by statistical methods . journal Proceedings of the IEEE volume 64 , pages 532--556
1976
-
[30]
author Lara, F. , author Arellano, J. , author Castillo, M. , author Topón, L. , author Carrera, E.V. , year 2020 . title Source coding for text transmission using a deep neural network as a lossy compression stage , in: booktitle 2020 IEEE ANDESCON , pp. pages 1--5 . :10.1109/ANDESCON50619.2020.9272105
-
[31]
, year 2020
author Leggett, E.R. , year 2020 . title Digitization and digital archiving: A practical guide for librarians . publisher Rowman & Littlefield
2020
-
[32]
author Lewis, M. , author Liu, Y. , author Goyal, N. , author Ghazvininejad, M. , author Mohamed, A. , author Levy, O. , author Stoyanov, V. , author Zettlemoyer, L. , year 2020 . title BART : Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension , in: editor Jurafsky, D. , editor Chai, J. , editor Sch...
-
[33]
author Li, M. , author Jin, R. , author Xiang, L. , author Shen, K. , author Cui, S. , year 2024 . title Crossword: A semantic approach to text compression via masking , in: booktitle ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp. pages 9171--9175 . :10.1109/ICASSP48485.2024.10447857
-
[34]
, author Wang, R
author Li, Z. , author Wang, R. , author Chen, K. , author Utiyama, M. , author Sumita, E. , author Zhang, Z. , author Zhao, H. , year 2020 . title Explicit sentence compression for neural machine translation , in: booktitle Proceedings of the AAAI Conference on Artificial Intelligence , pp. pages 8311--8318
2020
-
[35]
, author Zhang, Z
author Li, Z. , author Zhang, Z. , author Zhao, H. , author Wang, R. , author Chen, K. , author Utiyama, M. , author Sumita, E. , year 2021 . title Text compression-aided transformer encoding . journal IEEE Transactions on Pattern Analysis and Machine Intelligence volume 44 , pages 3840--3857
2021
-
[36]
, year 2004
author Lin, C.Y. , year 2004 . title Rouge: A package for automatic evaluation of summaries , in: booktitle Text summarization branches out , pp. pages 74--81
2004
-
[37]
, author Sun, H
author Liu, J. , author Sun, H. , author Katto, J. , year 2023 . title Learned image compression with mixed transformer-cnn architectures , in: booktitle Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. pages 14388--14397
2023
-
[38]
, author Su \'a rez-Paniagua, V
author Lopez-Avila, A. , author Su \'a rez-Paniagua, V. , year 2023 . title Combining denoising autoencoders with contrastive learning to fine-tune transformer models , in: editor Bouamor, H. , editor Pino, J. , editor Bali, K. (Eds.), booktitle Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , publisher Association ...
-
[39]
, author Maniar, T
author Malireddy, C. , author Maniar, T. , author Shrivastava, M. , year 2020 . title Scar: Sentence compression using autoencoders for reconstruction , in: booktitle Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop , pp. pages 88--94
2020
-
[40]
, author Cui, Y
author Mao, Y. , author Cui, Y. , author Kuo, T.W. , author Xue, C.J. , year 2022 . title Trace: A fast transformer-based general-purpose lossless compressor , in: booktitle Proceedings of the ACM Web Conference 2022 , pp. pages 1829--1838
2022
-
[41]
author Mao, Y. , author Pirk, H. , author Xue, C.J. , year 2025 . title Lossless compression of large language model-generated text via next-token prediction . journal arXiv preprint arXiv:2505.06297
arXiv 2025
-
[42]
, year 2018
author Matt, P. , year 2018 . title A call for clarity in reporting BLEU scores , in: booktitle Proceedings of the Third Conference on Machine Translation: Research Papers , publisher Association for Computational Linguistics , address Belgium, Brussels . pp. pages 186--191 . https://www.aclweb.org/anthology/W18-6319
2018
-
[43]
, author Li, X
author Mu, J. , author Li, X. , author Goodman, N. , year 2024 . title Learning to compress prompts with gist tokens . journal Advances in Neural Information Processing Systems volume 36
2024
-
[44]
, year 2023
author Niu, J. , year 2023 . title Corporate archives in the wild . journal Global Knowledge, Memory and Communication
2023
-
[45]
, year 2023
author Office, V.S.S.H. , year 2023 . title Worldwide texting statistics . https://shso.vermont.gov/sites/ghsp/files/documents/Worldwide
2023
-
[46]
, author Latifi, S
author Palaniappan, V. , author Latifi, S. , year 2007 . title Lossy text compression techniques , in: booktitle ICCS 2007: Proceedings of the 15th International Workshops on Conceptual Structures , organization Springer . pp. pages 205--210
2007
-
[47]
URL https://aclanthology.org/2023
author Peng, B. , author Alcaide, E. , author Anthony, Q. , author Albalak, A. , author Arcadinho, S. , author Biderman, S. , author Cao, H. , author Cheng, X. , author Chung, M. , author Derczynski, L. , author Du, X. , author Grella, M. , author Gv, K. , author He, X. , author Hou, H. , author Kazienko, P. , author Kocon, J. , author Kong, J. , author K...
-
[48]
author Prato, G. , author Duchesneau, M. , author Chandar, S. , author Tapp, A. , year 2019 . title Towards lossless encoding of sentences , in: editor Korhonen, A. , editor Traum, D. , editor M \`a rquez, L. (Eds.), booktitle Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , publisher Association for Computational ...
-
[49]
author Qin, G. , author Rosset, C. , author Chau, E. , author Rao, N. , author Van Durme, B. , year 2024 . title Dodo: Dynamic contextual compression for decoder-only LM s , in: editor Ku, L.W. , editor Martins, A. , editor Srikumar, V. (Eds.), booktitle Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[50]
, author Van, D
author Qin, G. , author Van, D. , author Benjamin , year 2023 . title Nugget: Neural agglomerative embeddings of text , in: booktitle International Conference on Machine Learning , organization PMLR . pp. pages 28337--28350
2023
-
[51]
author Rae, J.W. , author Potapenko, A. , author Jayakumar, S.M. , author Lillicrap, T.P. , year 2019 . title Compressive transformers for long-range sequence modelling . https://arxiv.org/abs/1911.05507, http://arxiv.org/abs/1911.05507 arXiv:1911.05507
Pith/arXiv arXiv 2019
-
[52]
, year 2023
author Rahimi, S. , year 2023 . title I have been using this compression technique with amazing results for a chatbot platform . https://medium.com/@samrahimi420/i-have-been-using-this-compression-technique-with-amazing-results-for-a-chatbot-platform-im-b1f425aa361a. note accessed: 2025-02-23
2023
-
[53]
author Savinov, N. , author Chung, J. , author Binkowski, M. , author Elsen, E. , author van den Oord, A. , year 2022 . title Step-unrolled denoising autoencoders for text generation . https://arxiv.org/abs/2112.06749, http://arxiv.org/abs/2112.06749 arXiv:2112.06749
arXiv 2022
-
[54]
, author Paliwal, K.K
author Schuster, M. , author Paliwal, K.K. , year 1997 . title Bidirectional recurrent neural networks . journal IEEE transactions on Signal Processing volume 45 , pages 2673--2681
1997
-
[55]
author Shazeer, N. , year 2020 . title Glu variants improve transformer . https://arxiv.org/abs/2002.05202, http://arxiv.org/abs/2002.05202 arXiv:2002.05202
Pith/arXiv arXiv 2020
-
[56]
, author Mueller, J
author Shen, T. , author Mueller, J. , author Barzilay, R. , author Jaakkola, T. , year 2020 . title Educating text autoencoders: Latent representation guidance via denoising , in: booktitle International conference on machine learning , organization PMLR . pp. pages 8719--8729
2020
-
[57]
, author Rodela, A.T
author Sobhani, M.E. , author Rodela, A.T. , author Farid, D.M. , year 2025 . title Adaptive treehive: Ensemble of trees for enhancing imbalanced intrusion classification . journal PLoS One volume 20 , pages e0331307
2025
-
[58]
, author Ahmed, M
author Su, J. , author Ahmed, M. , author Lu, Y. , author Pan, S. , author Bo, W. , author Liu, Y. , year 2024 . title Roformer: Enhanced transformer with rotary position embedding . journal Neurocomputing volume 568 , pages 127063
2024
-
[59]
, author Gravier, C
author Tissier, J. , author Gravier, C. , author Habrard, A. , year 2019 . title Near-lossless binarization of word embeddings , in: booktitle Proceedings of the AAAI Conference on Artificial Intelligence , pp. pages 7104--7111
2019
-
[60]
author Touvron, H. , author Lavril, T. , author Izacard, G. , author Martinet, X. , author Lachaux, M.A. , author Lacroix, T. , author Rozi \`e re, B. , author Goyal, N. , author Hambro, E. , author Azhar, F. , et al., year 2023 . title Llama: Open and efficient foundation language models . journal arXiv preprint arXiv:2302.13971
Pith/arXiv arXiv 2023
-
[61]
author Valmeekam, C.S.K. , author Narayanan, K. , author Kalathil, D. , author Chamberland, J.F. , author Shakkottai, S. , year 2023 . title Llmzip: Lossless text compression using large language models . https://arxiv.org/abs/2306.04050, http://arxiv.org/abs/2306.04050 arXiv:2306.04050
arXiv 2023
-
[62]
, year 2017
author Vaswani, A. , year 2017 . title Attention is all you need . journal Advances in Neural Information Processing Systems
2017
-
[63]
author Wang, K. , author Reimers, N. , author Gurevych, I. , year 2021 . title Tsdae: Using transformer-based sequential denoising auto-encoder for unsupervised sentence embedding learning . https://arxiv.org/abs/2104.06979, http://arxiv.org/abs/2104.06979 arXiv:2104.06979
arXiv 2021
-
[64]
, year 2012
author Williams, H.E. , year 2012 . title Compression, speed, and search engines . https://hughewilliams.com/2012/03/24/compression-speed-search-engines/. note accessed: 2025-02-23
2012
-
[65]
, author Sennrich, R
author Zhang, B. , author Sennrich, R. , year 2019 . title Root mean square layer normalization . journal Advances in neural information processing systems volume 32
2019
-
[66]
, author Cheng, Z
author Zhang, J. , author Cheng, Z. , author Zhao, Y. , author Wang, S. , author Zhou, D. , author Lu, G. , author Song, L. , year 2025 a. title L3tc: Leveraging rwkv for learned lossless low-complexity text compression , in: booktitle Proceedings of the AAAI Conference on Artificial Intelligence , pp. pages 13251--13259
2025
-
[67]
, author Li, M
author Zhang, Q. , author Li, M. , author Wang, Z. , author Liao, R. , author Wang, L. , year 2025 b. title Test-time steering for lossless text compression via weighted product of experts , in: booktitle Findings of the Association for Computational Linguistics: EMNLP 2025 , pp. pages 2076--2088
2025
-
[68]
author Zhang, S. , author Roller, S. , author Goyal, N. , author Artetxe, M. , author Chen, M. , author Chen, S. , author Dewan, C. , author Diab, M. , author Li, X. , author Lin, X.V. , author Mihaylov, T. , author Ott, M. , author Shleifer, S. , author Shuster, K. , author Simig, D. , author Koura, P.S. , author Sridhar, A. , author Wang, T. , author Ze...
Pith/arXiv arXiv 2022
-
[69]
author Zhang, T. , author Kishore, V. , author Wu, F. , author Weinberger, K.Q. , author Artzi, Y. , year 2020 . title Bertscore: Evaluating text generation with bert . https://arxiv.org/abs/1904.09675, http://arxiv.org/abs/1904.09675 arXiv:1904.09675
Pith/arXiv arXiv 2020
-
[70]
, author Kiros, R
author Zhu, Y. , author Kiros, R. , author Zemel, R. , author Salakhutdinov, R. , author Urtasun, R. , author Torralba, A. , author Fidler, S. , year 2015 . title Aligning books and movies: Towards story-like visual explanations by watching movies and reading books , in: booktitle Proceedings of the IEEE international conference on computer vision , pp. p...
2015
-
[71]
, author Lempel, A
author Ziv, J. , author Lempel, A. , year 1978 . title Compression of individual sequences via variable-rate coding . journal IEEE transactions on Information Theory volume 24 , pages 530--536
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.