Macro Economists in the Machine: A Multi-Agent LLM Framework for Commodity-Related ETF Portfolio Construction
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
LLM agents with fixed macro z-scores outperform a deterministic rule agent in commodity ETF portfolios by lifting Sharpe ratios 0.04 points while retaining an edge at 30 basis points in trading costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
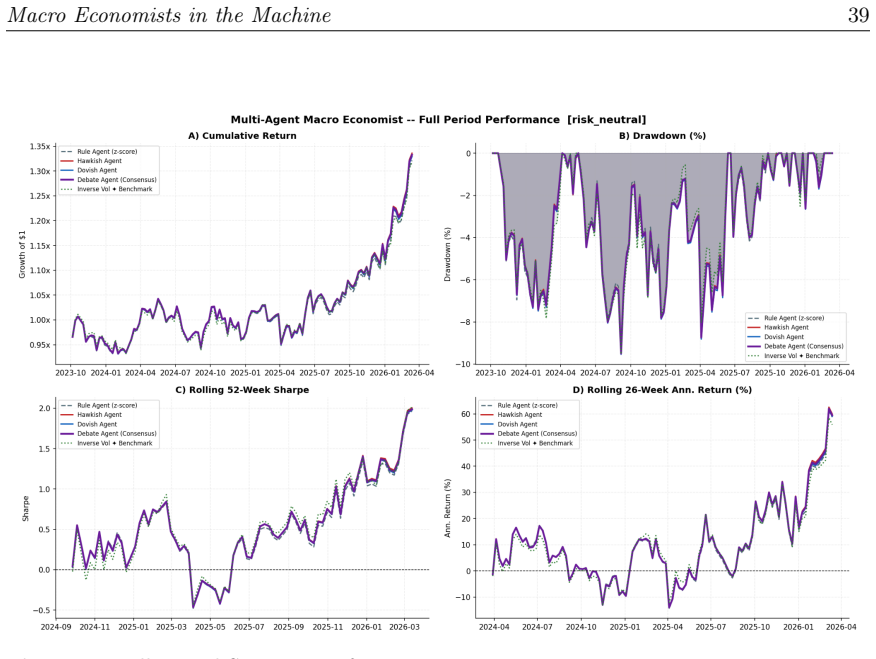
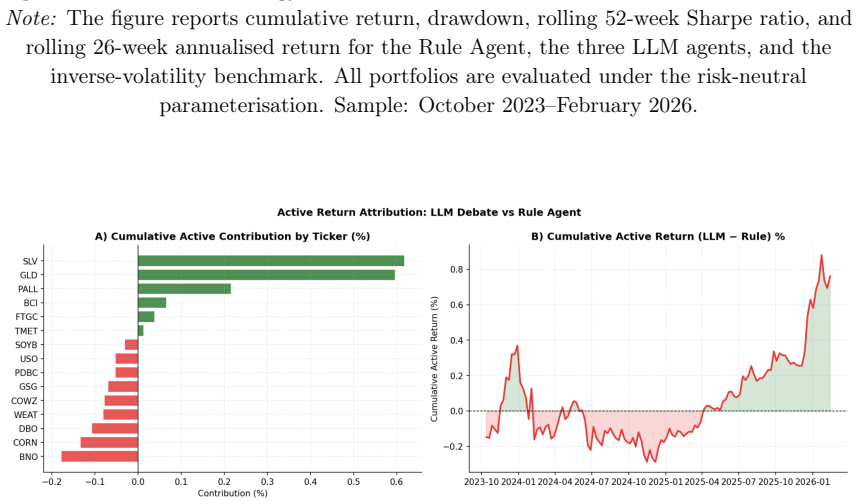
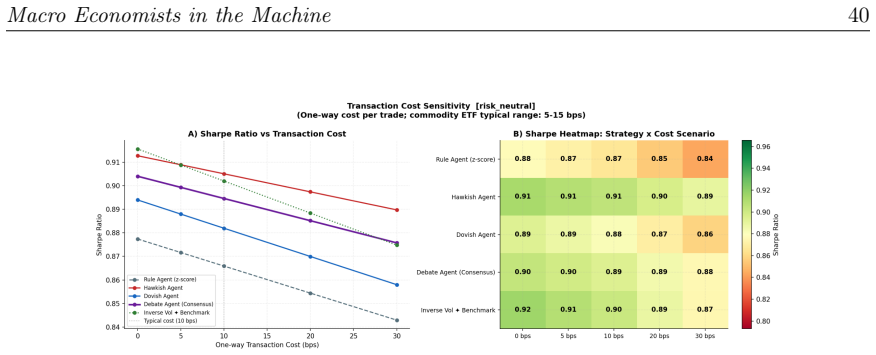
When given identical FRED macro z-scores, the Hawkish Agent and Debate Agent each improve Sharpe ratio by roughly 0.04 over the Rule Agent across the full sample; the Debate Agent corrects the Dovish Agent's miscalibrated prior rather than generating incremental return through interaction, and the net-of-cost advantage over passive inverse-volatility allocation survives one-way costs up to 30 basis points while the Rule Agent's margin vanishes near 5 basis points.
What carries the argument
The constrained macro-interpretation function in which LLM agents with differing priors receive the same FRED macro z-scores and feed tilt signals into an identical portfolio engine.
If this is right
- An LLM can serve as a macro-interpretation layer that extracts modest value beyond a transparent rule on the same inputs.
- The Debate Agent's contribution is bias averaging rather than deliberation-generated alpha.
- The net advantage holds at one-way trading costs up to 30 basis points but is concentrated in the soft-landing portion of the sample.
- The Rule Agent's edge over passive allocation erodes once costs reach approximately 5 basis points.
Where Pith is reading between the lines
- The same constrained-agent design could be applied to equity or fixed-income universes using the identical macro z-score inputs.
- Ensemble averaging across differently biased agents may offer a general method for reducing prior misalignment in macro-driven strategies.
- Results from a single rate cycle leave open whether the observed margin would survive a different inflation or growth regime.
Load-bearing premise
The performance edge seen during the single 2023-2025 U.S. rate cycle will appear in other macroeconomic regimes.
What would settle it
Re-running the identical setup on data from a subsequent rate-hiking cycle or recession and finding that the 0.04 Sharpe advantage disappears or reverses.
Figures

read the original abstract
We test whether large language models (LLMs) add value in commodity portfolio construction when the information set and implementation rules are held fixed across strategies. A Hawkish Agent (inflation-tightening prior), a Dovish Agent (growth-easing prior), a Debate Agent, and a deterministic z-score Rule Agent each receive identical FRED macro z-scores and route their tilt signals through the same portfolio engine. Across 124 weekly rebalancing dates spanning the 2023 U.S. rate peak and the 2024-2025 soft landing, all three LLM strategies outperform the Rule Agent in Sharpe terms; the Hawkish and Debate Agents record the largest gains (\Delta Sharpe = +0.044 and +0.040, both p < 0.10 under a block bootstrap) and preserve a net-of-cost advantage over the passive inverse-volatility benchmark at one-way trading costs up to 30 basis points, while the Rule Agent's thin margin over passive disappears at approximately 5 basis points.The Debate Agent does not outperform the best single agent (\Delta Sharpe = -0.004, p = 0.769); its contribution is bias correction -- averaging out the Dovish Agent's miscalibrated prior -- rather than deliberation-generated return. The performance advantage is concentrated in the soft-landing sub-period, the evaluation window spans a single rate cycle, and the reported $p$-values are unadjusted for multiple comparisons. Within these limits, the results suggest that an LLM acting as a constrained macro-interpretation function can add modest but economically meaningful value over a transparent rule layer, though the margin is small and its persistence beyond this sample is unknown.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether LLMs add value as macro interpreters in commodity ETF portfolio construction by comparing three LLM agents (Hawkish with inflation-tightening prior, Dovish with growth-easing prior, and Debate) against a deterministic z-score Rule Agent. All agents receive identical FRED macro z-scores and feed tilt signals into the same portfolio engine. Across 124 weekly rebalancings from the 2023 rate peak through the 2024-2025 soft landing, the Hawkish and Debate agents show Sharpe improvements over the Rule Agent of +0.044 and +0.040 (block-bootstrap p < 0.10), with net-of-cost outperformance versus inverse-volatility benchmark up to 30 bp one-way costs; the Debate agent's role is characterized as bias correction rather than deliberation-driven alpha. The abstract explicitly flags concentration of gains in the soft-landing sub-period, the single rate-cycle sample, and unadjusted p-values.
Significance. If the reported Sharpe differentials hold under the stated constraints, the work supplies controlled evidence that LLMs can serve as modest, bias-correcting macro-interpretation layers on top of transparent rules, with the fixed-input design and explicit Rule baseline eliminating many confounding channels. Credit is due for the block-bootstrap inference, one-way cost sensitivity checks up to 30 bp, and the out-of-sample-style backtest on fixed public FRED data with no fitted parameters or circularity. The single-cycle limitation and sub-period concentration are already noted by the authors, which appropriately bounds the interpretation.
major comments (2)
- [Abstract] Abstract: The central statistical claims rest on unadjusted p-values (p < 0.10) for three separate LLM-vs-Rule Sharpe comparisons. Because the outperformance evidence is load-bearing for the paper's conclusion that LLMs add value, multiplicity-adjusted p-values (or an alternative testing procedure) should be reported to confirm whether the nominal significance survives correction.
- [Abstract] Abstract and results: The reported advantage is concentrated in the soft-landing sub-period within a single 2023-2025 rate cycle. This regime specificity is load-bearing for any broader claim that LLMs function as reliable constrained macro interpreters; without either sub-period breakdowns or an explicit robustness check on an earlier or later cycle, the generalizability of the ΔSharpe findings remains untested.
minor comments (1)
- [Abstract] The abstract could more explicitly quantify the Rule Agent's margin over the passive benchmark and the exact point at which that margin vanishes under costs, to make the comparative cost-sensitivity results immediately visible.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central statistical claims rest on unadjusted p-values (p < 0.10) for three separate LLM-vs-Rule Sharpe comparisons. Because the outperformance evidence is load-bearing for the paper's conclusion that LLMs add value, multiplicity-adjusted p-values (or an alternative testing procedure) should be reported to confirm whether the nominal significance survives correction.
Authors: We agree that the reported p-values are unadjusted for multiple comparisons across the three LLM agents. In the revised manuscript we will add Bonferroni-adjusted p-values (and note the dependence structure among the tests) while retaining the block-bootstrap procedure. revision: yes
-
Referee: [Abstract] Abstract and results: The reported advantage is concentrated in the soft-landing sub-period within a single 2023-2025 rate cycle. This regime specificity is load-bearing for any broader claim that LLMs function as reliable constrained macro interpreters; without either sub-period breakdowns or an explicit robustness check on an earlier or later cycle, the generalizability of the ΔSharpe findings remains untested.
Authors: The manuscript already states that gains are concentrated in the soft-landing sub-period and that the sample covers only a single rate cycle; sub-period results are reported in the main text. We cannot add robustness checks on earlier or later cycles without extending the data window beyond the 2023–2025 period examined. We will strengthen the explicit caveats on generalizability in the abstract and conclusion. revision: partial
Circularity Check
No circularity: empirical backtest with fixed inputs and direct return computation
full rationale
The paper reports a straightforward out-of-sample backtest on fixed FRED macro z-scores across 124 weekly dates. All agents (LLM variants and deterministic Rule Agent) receive identical inputs and route signals through the same portfolio engine; Sharpe ratios, p-values (block bootstrap), and cost thresholds are computed directly from realized portfolio returns. No derivation, prediction, or uniqueness claim reduces to a fitted parameter, self-citation loop, or definitional equivalence. The single-rate-cycle limitation is a generalizability concern, not a circularity issue. The central performance comparison is externally falsifiable against the data and rules stated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Financial Analysts Journal , volume=
Facts and fantasies about commodity futures , author=. Financial Analysts Journal , volume=. 2006 , publisher=
2006
-
[2]
Financial Analysts Journal , volume=
The strategic and tactical value of commodity futures , author=. Financial Analysts Journal , volume=. 2006 , publisher=
2006
-
[3]
Review of Finance , volume=
The fundamentals of commodity futures returns , author=. Review of Finance , volume=. 2013 , publisher=
2013
-
[4]
The Journal of Finance , volume=
An anatomy of commodity futures risk premia , author=. The Journal of Finance , volume=. 2014 , publisher=
2014
-
[5]
Journal of Banking & Finance , volume=
Are there common factors in individual commodity futures returns? , author=. Journal of Banking & Finance , volume=. 2014 , publisher=
2014
-
[6]
Management Science , volume=
Understanding the sources of risk underlying the cross section of commodity returns , author=. Management Science , volume=. 2019 , publisher=
2019
-
[7]
Financial analysts journal , volume=
Index investment and the financialization of commodities , author=. Financial analysts journal , volume=. 2012 , publisher=
2012
-
[8]
The Journal of finance , volume=
When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks , author=. The Journal of finance , volume=. 2011 , publisher=
2011
-
[9]
1986 , publisher=
Society of mind , author=. 1986 , publisher=
1986
-
[10]
and Mordatch, Igor , title =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[11]
ChatEval: Towards Better
Chi-Min Chan and Weize Chen and Yusheng Su and Jianxuan Yu and Wei Xue and Shanghang Zhang and Jie Fu and Zhiyuan Liu , booktitle=. ChatEval: Towards Better. 2024 , url=
2024
-
[12]
arXiv preprint arXiv:2412.20138 , year=
Tradingagents: Multi-agents llm financial trading framework , author=. arXiv preprint arXiv:2412.20138 , year=
-
[13]
arXiv preprint arXiv:2512.00338 , year=
On Statistical Inference for High-Dimensional Binary Time Series , author=. arXiv preprint arXiv:2512.00338 , year=
-
[14]
The review of Financial studies , volume=
Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? , author=. The review of Financial studies , volume=. 2009 , publisher=
2009
-
[15]
Management science , volume=
A generalized approach to portfolio optimization: Improving performance by constraining portfolio norms , author=. Management science , volume=. 2009 , publisher=
2009
-
[16]
Econometrica , volume=
A reality check for data snooping , author=. Econometrica , volume=. 2000 , publisher=
2000
-
[17]
Journal of Business & Economic Statistics , volume=
A test for superior predictive ability , author=. Journal of Business & Economic Statistics , volume=. 2005 , publisher=
2005
-
[18]
Notices of the AMS , volume=
Pseudomathematics and financial charlatanism: The effects of backtest over fitting on out-of-sample performance , author=. Notices of the AMS , volume=
-
[19]
The Review of financial studies , volume=
… and the cross-section of expected returns , author=. The Review of financial studies , volume=. 2016 , publisher=
2016
-
[20]
Financial analysts journal , volume=
The statistics of Sharpe ratios , author=. Financial analysts journal , volume=. 2002 , publisher=
2002
-
[21]
Journal of Empirical Finance , volume=
Robust performance hypothesis testing with the Sharpe ratio , author=. Journal of Empirical Finance , volume=. 2008 , publisher=
2008
-
[22]
Journal of the American Statistical association , volume=
The stationary bootstrap , author=. Journal of the American Statistical association , volume=. 1994 , publisher=
1994
-
[23]
Econometric reviews , volume=
Automatic block-length selection for the dependent bootstrap , author=. Econometric reviews , volume=. 2004 , publisher=
2004
-
[24]
Econometrica , volume=
Stepwise multiple testing as formalized data snooping , author=. Econometrica , volume=. 2005 , publisher=
2005
-
[25]
Journal of the American Statistical Association , volume=
Exact and approximate stepdown methods for multiple hypothesis testing , author=. Journal of the American Statistical Association , volume=. 2005 , publisher=
2005
-
[26]
BloombergGPT: A Large Language Model for Finance
Bloomberggpt: A large language model for finance , author=. arXiv preprint arXiv:2303.17564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2306.06031 (2023)
Fingpt: Open-source financial large language models , author=. arXiv preprint arXiv:2306.06031 , year=
-
[28]
arXiv preprint arXiv:2304.07619 , year=
Can chatgpt forecast stock price movements? return predictability and large language models , author=. arXiv preprint arXiv:2304.07619 , year=
-
[29]
arXiv preprint arXiv:2407.17866 , year=
Financial statement analysis with large language models , author=. arXiv preprint arXiv:2407.17866 , year=
-
[30]
arXiv preprint arXiv:2603.11408 , year=
Beyond Polarity: Multi-Dimensional LLM Sentiment Signals for WTI Crude Oil Futures Return Prediction , author=. arXiv preprint arXiv:2603.11408 , year=
-
[31]
The Review of Financial Studies , volume=
Empirical asset pricing via machine learning , author=. The Review of Financial Studies , volume=. 2020 , publisher=
2020
-
[32]
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem
A deep reinforcement learning framework for the financial portfolio management problem , author=. arXiv preprint arXiv:1706.10059 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Foundations and Trends
Financial machine learning , author=. Foundations and Trends. 2023 , publisher=
2023
-
[34]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[35]
arXiv preprint arXiv:2508.11152 , year=
Alphaagents: Large language model based multi-agents for equity portfolio constructions , author=. arXiv preprint arXiv:2508.11152 , year=
-
[36]
, title =
Tetlock, Paul C. , title =. The Journal of Finance , year =
-
[37]
The Journal of Finance , year =
Loughran, Tim and McDonald, Bill , title =. The Journal of Finance , year =
-
[38]
Minsky, Marvin , title =
-
[39]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. arXiv preprint arXiv:2305.14325 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.