HACK++: Towards More Effective Head-Aware Key-Value Compression for Efficient Visual Autoregressive Modeling
Pith reviewed 2026-06-27 19:45 UTC · model grok-4.3
The pith
HACK++ classifies VAR attention heads into contextual and structural types to apply separate compression budgets that cut cache use to 10% while keeping generation near lossless.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
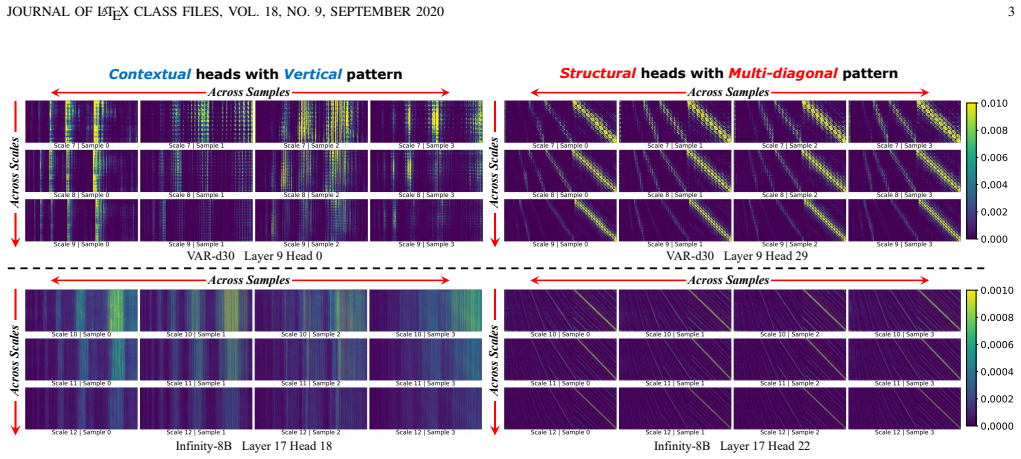
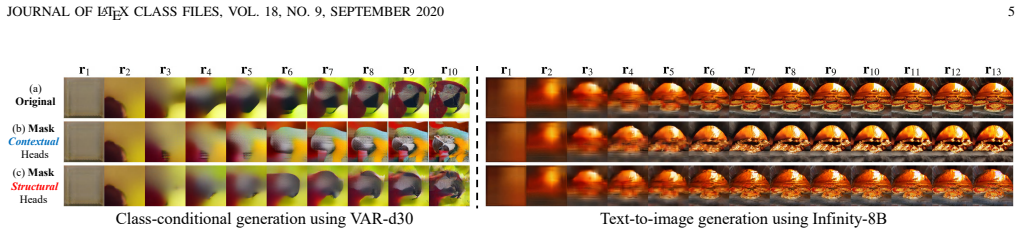
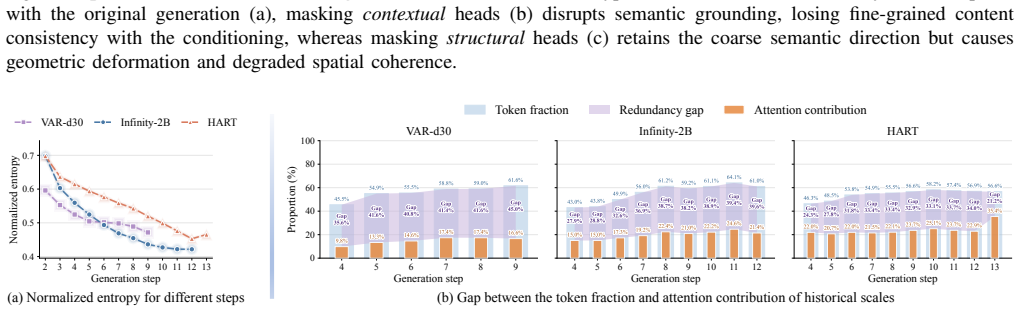
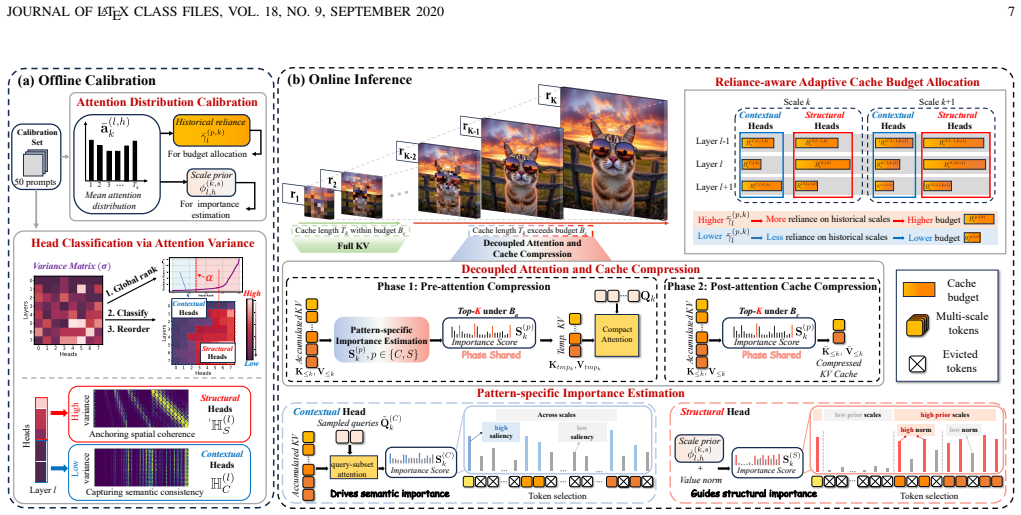
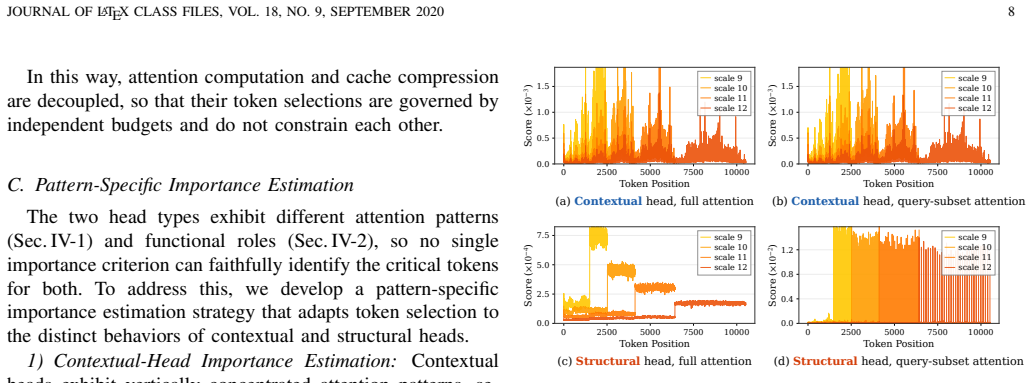
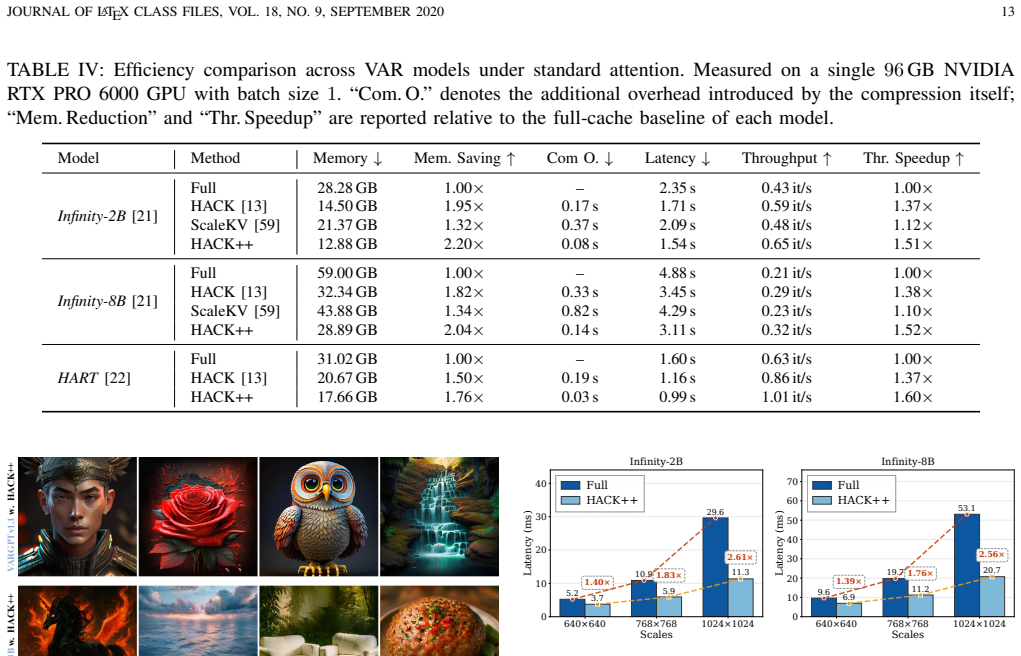
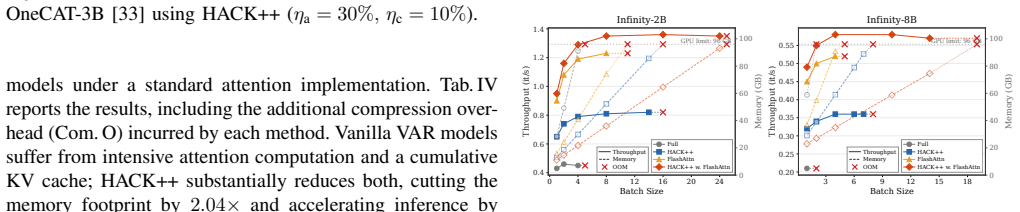
HACK++ is a training-free framework that first partitions VAR attention heads via offline calibration into Contextual Heads focused on semantic consistency and Structural Heads focused on spatial coherence; these types exhibit distinct and shifting reliance on historical scales across layers and steps. At inference the method applies independent budgets to bound current-scale attention cost while compressing the accumulated KV cache far more aggressively through pattern-specific strategies and reliance-aware per-head allocation, delivering near-lossless generation quality at 30% attention budget and 10% cache budget on Infinity-2B/8B models.
What carries the argument
Head-type classification into Contextual and Structural categories with decoupled attention and cache budgets plus reliance-aware allocation.
If this is right
- VAR models can run with 90% less KV cache memory while preserving generation quality.
- The same head-aware split supports even 1% cache budgets without collapse.
- No retraining is required, so the compression applies directly to existing VAR checkpoints.
- Attention cost stays bounded independently of how aggressively the historical cache is reduced.
Where Pith is reading between the lines
- The offline head classification could transfer to other next-scale or next-token autoregressive vision models that accumulate caches.
- If reliance patterns drift more than expected, an online update to the head labels might yield still-higher compression ratios.
- Reduced memory footprint could enable higher-resolution outputs or additional scales on the same hardware.
Load-bearing premise
Attention heads in VAR models can be stably partitioned into two functional categories by a single offline calibration whose labels and reliance patterns remain valid across layers and generation steps.
What would settle it
Run HACK++ on Infinity-8B at 10% cache budget and compare FID scores or visual coherence against the full-cache baseline; a large quality drop would show the near-lossless claim does not hold.
Figures






read the original abstract
Visual Autoregressive (VAR) models adopt a next-scale prediction paradigm, offering high-quality generation with substantially fewer decoding steps. However, existing VAR models suffer from significant attention complexity and severe memory overhead due to the accumulation of key-value (KV) caches across scales. In this paper, we tackle this challenge by introducing KV cache compression into the next-scale paradigm. We begin with an in-depth analysis of VAR attention and observe that attention heads can be stably divided into two functionally distinct categories: Contextual Heads focus on maintaining semantic consistency, while Structural Heads preserve spatial coherence. Their functional divergence makes existing one-size-fits-all compression methods perform poorly on VAR models. We further find that the two head types differ markedly in their reliance on historical scales, and that this reliance shifts across layers and generation steps, arguing for an adaptive cache budget allocation. To address these challenges, we propose HACK++, a training-free Head-Aware key-value Compression frameworK for VAR models. From a one-time offline calibration, HACK++ classifies head types and derives head-specific priors. At inference, it decouples attention from cache compression under independent budgets, bounding the current-scale attention cost while compressing the accumulated cache far more aggressively, via pattern-specific strategies and a reliance-aware budget allocation. Extensive experiments on multiple VAR models across text-to-image, class-conditional, and unified understanding-and-generation tasks validate the effectiveness and generalizability of HACK++. For example, on Infinity-2B/8B, HACK++ maintains near-lossless generation with only a 30% attention budget and a 10% cache budget, and remains robust even under a 1% cache budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HACK++, a training-free Head-Aware Key-Value Compression framework for Visual Autoregressive (VAR) models. It analyzes attention heads, classifying them into Contextual Heads (semantic consistency) and Structural Heads (spatial coherence) through one-time offline calibration, notes differences in reliance on historical scales that shift across layers and steps, and proposes decoupled compression with independent budgets for current-scale attention and accumulated cache using pattern-specific strategies and reliance-aware allocation. Experiments claim near-lossless generation on models like Infinity-2B/8B with 30% attention budget and 10% (or 1%) cache budget across various tasks.
Significance. If the head classification remains stable and the adaptive allocation holds, this method could substantially improve the efficiency of VAR models by mitigating KV cache memory overhead and attention complexity without retraining, potentially enabling larger models or real-time applications in text-to-image generation and unified tasks. The training-free nature and extreme compression robustness are positive aspects.
major comments (2)
- [Abstract] The assertion that attention heads 'can be stably divided' into two categories via one-time offline calibration is load-bearing for the entire approach, yet no details on validation of this stability across different inputs, prompts, or generation steps are provided; this directly impacts whether the decoupled budgets can reliably maintain near-lossless quality at the claimed 30% attention / 10% cache budgets on Infinity-2B/8B.
- [Head Classification and Reliance Analysis] The method relies on the functional divergence and predictable reliance shifts being consistent enough for adaptive per-head budget allocation; without reported cross-validation or sensitivity analysis of the calibration step, the claims of robustness even under a 1% cache budget risk being overstated if Contextual/Structural roles vary with input or step.
minor comments (1)
- [Experiments] The abstract mentions extensive experiments on multiple VAR models and tasks, but specific metrics, baseline comparisons, and controls for post-hoc tuning should be clearly tabulated for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the two major comments point-by-point below, agreeing that additional validation details would strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The assertion that attention heads 'can be stably divided' into two categories via one-time offline calibration is load-bearing for the entire approach, yet no details on validation of this stability across different inputs, prompts, or generation steps are provided; this directly impacts whether the decoupled budgets can reliably maintain near-lossless quality at the claimed 30% attention / 10% cache budgets on Infinity-2B/8B.
Authors: We agree that explicit validation of classification stability is important for supporting the load-bearing claim. The manuscript derives the Contextual/Structural division from offline calibration on a representative prompt set and reports consistent near-lossless results across text-to-image, class-conditional, and unified tasks on Infinity-2B/8B. To directly address the concern, the revised version will add a new subsection (and appendix) reporting head-type consistency metrics across varied prompts, generation steps, and calibration-set perturbations. revision: yes
-
Referee: [Head Classification and Reliance Analysis] The method relies on the functional divergence and predictable reliance shifts being consistent enough for adaptive per-head budget allocation; without reported cross-validation or sensitivity analysis of the calibration step, the claims of robustness even under a 1% cache budget risk being overstated if Contextual/Structural roles vary with input or step.
Authors: We concur that cross-validation and sensitivity analysis of the calibration would better support the adaptive allocation and 1% cache-budget claims. The current experiments demonstrate robustness across models and tasks, but we will add explicit sensitivity results on reliance shifts and head-role stability in the revision to mitigate the risk of overstatement. revision: yes
Circularity Check
No circularity: empirical method with independent calibration and validation
full rationale
The paper's core contribution is a training-free compression scheme whose head classification and budget allocation derive from a one-time offline analysis of attention patterns, not from any equation or fit that tautologically reproduces the reported performance metrics. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text; the near-lossless claims rest on external experimental measurements on Infinity-2B/8B rather than on quantities defined in terms of themselves. The derivation chain therefore remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads in VAR models divide stably into Contextual Heads (semantic consistency) and Structural Heads (spatial coherence) whose reliance on historical scales differs and shifts across layers and steps.
Reference graph
Works this paper leans on
-
[1]
Mars: Mixture of auto-regressive models for fine- grained text-to-image synthesis,
W. He, S. Fu, M. Liu, X. Wang, W. Xiao, F. Shu, Y . Wang, L. Zhang, Z. Yu, H. Liet al., “Mars: Mixture of auto-regressive models for fine- grained text-to-image synthesis,”arXiv preprint arXiv:2407.07614, 2024
arXiv 2024
-
[2]
Autoregressive model beats diffusion: Llama for scalable image generation,
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image generation,”arXiv preprint arXiv:2406.06525, 2024
Pith/arXiv arXiv 2024
-
[3]
Autoregressive image gen- eration without vector quantization,
T. Li, Y . Tian, H. Li, M. Deng, and K. He, “Autoregressive image gen- eration without vector quantization,”Advances in Neural Information Processing Systems, vol. 37, pp. 56 424–56 445, 2024
2024
-
[4]
Janus-pro: Unified multimodal understanding and generation with data and model scaling,
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-pro: Unified multimodal understanding and generation with data and model scaling,”arXiv preprint arXiv:2501.17811, 2025
Pith/arXiv arXiv 2025
-
[5]
Janus: Decoupling visual encoding for unified multimodal understanding and generation,
C. Wu, X. Chen, Z. Wu, Y . Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruanet al., “Janus: Decoupling visual encoding for unified multimodal understanding and generation,”arXiv preprint arXiv:2410.13848, 2024
Pith/arXiv arXiv 2024
-
[6]
Chameleon: Mixed-modal early-fusion foundation models,
C. Team, “Chameleon: Mixed-modal early-fusion foundation models,”
-
[7]
Available: https://arxiv.org/abs/2405.09818
[Online]. Available: https://arxiv.org/abs/2405.09818
-
[8]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in neural information processing systems, 2020, pp. 6840–6851
2020
-
[9]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[10]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[11]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
2024
-
[12]
Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,” inEuropean Conference on Computer Vision, 2024, pp. 74–91
2024
-
[13]
Visual autoregres- sive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregres- sive modeling: Scalable image generation via next-scale prediction,” Advances in neural information processing systems, vol. 37, pp. 84 839–84 865, 2024
2024
-
[14]
Head- aware kv cache compression for efficient visual autoregressive model- ing,
Z. Qin, Y . Lv, M. Lin, H. Guo, Z. Zhang, D. Zou, and W. Lin, “Head- aware kv cache compression for efficient visual autoregressive model- ing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 30, 2026, pp. 24 982–24 990
2026
-
[15]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[16]
The claude 3 model family: Opus, sonnet, haiku,
Anthropic, “The claude 3 model family: Opus, sonnet, haiku,” 2024. [Online]. Available: https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model Card Claude 3.pdf
2024
-
[17]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[18]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[19]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[20]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[21]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883
2021
-
[22]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,
J. Han, J. Liu, Y . Jiang, B. Yan, Y . Zhang, Z. Yuan, B. Peng, and X. Liu, “Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,”arXiv preprint arXiv:2412.04431, 2024
arXiv 2024
-
[23]
Hart: Efficient visual generation with hybrid autoregressive transformer,
H. Tang, Y . Wu, S. Yang, E. Xie, J. Chen, J. Chen, Z. Zhang, H. Cai, Y . Lu, and S. Han, “Hart: Efficient visual generation with hybrid autoregressive transformer,”arXiv preprint arXiv:2410.10812, 2024
arXiv 2024
-
[24]
Toward guidance-free ar visual generation via condition contrastive alignment,
H. Chen, H. Su, P. Sun, and J. Zhu, “Toward guidance-free ar visual generation via condition contrastive alignment,”arXiv preprint arXiv:2410.09347, 2024
arXiv 2024
-
[25]
M-var: Decoupled scale-wise autoregressive modeling for high-quality image generation,
S. Ren, Y . Yu, N. Ruiz, F. Wang, A. Yuille, and C. Xie, “M-var: Decoupled scale-wise autoregressive modeling for high-quality image generation,”arXiv preprint arXiv:2411.10433, 2024
arXiv 2024
-
[26]
Switti: Designing scale-wise transformers for text-to- image synthesis,
A. V oronov, D. Kuznedelev, M. Khoroshikh, V . Khrulkov, and D. Baranchuk, “Switti: Designing scale-wise transformers for text-to- image synthesis,” 2024
2024
-
[27]
Infinitystar: Unified spacetime autoregressive modeling JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 17 for visual generation,
J. Liu, J. Han, B. Yan, H. Wu, F. Zhu, X. Wang, Y . Jiang, B. Peng, and Z. Yuan, “Infinitystar: Unified spacetime autoregressive modeling JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 17 for visual generation,”Advances in Neural Information Processing Systems, vol. 38, pp. 170 054–170 072, 2026
2020
-
[28]
Videoar: Autoregressive video generation via next-frame & scale prediction,
L. Ji, X. Liu, J. Shang, S. Wang, Y . Sun, H. Wu, and H. Wang, “Videoar: Autoregressive video generation via next-frame & scale prediction,”arXiv preprint arXiv:2601.05966, 2026
arXiv 2026
-
[29]
Controlvar: Exploring controllable visual autoregressive modeling,
X. Li, K. Qiu, H. Chen, J. Kuen, Z. Lin, R. Singh, and B. Raj, “Controlvar: Exploring controllable visual autoregressive modeling,” arXiv preprint arXiv:2406.09750, 2024
arXiv 2024
-
[30]
Visual autoregressive modeling for image super-resolution,
Y . Qu, K. Yuan, J. Hao, K. Zhao, Q. Xie, M. Sun, and C. Zhou, “Visual autoregressive modeling for image super-resolution,”arXiv preprint arXiv:2501.18993, 2025
arXiv 2025
-
[31]
Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae,
Y . Chen, Y . Lan, S. Zhou, T. Wang, and X. Pan, “Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae,” in CVPR, 2025
2025
-
[32]
Mars: Mesh autoregressive model for 3d shape detailization,
J. Gao, W. Liu, W. Sun, S. Wang, X. Song, T. Shang, S. Chen, H. Li, X. Yang, Y . Yanet al., “Mars: Mesh autoregressive model for 3d shape detailization,”arXiv preprint arXiv:2502.11390, 2025
arXiv 2025
-
[33]
X. Zhuang, Y . Xie, Y . Deng, L. Liang, J. Ru, Y . Yin, and Y . Zou, “Vargpt: Unified understanding and generation in a visual autoregressive multimodal large language model,”arXiv preprint arXiv:2501.12327, 2025
arXiv 2025
-
[34]
Onecat: Decoder-only auto-regressive model for unified understanding and generation,
H. Li, X. Peng, Y . Wang, Z. Peng, X. Chen, R. Weng, J. Wang, X. Cai, W. Dai, and H. Xiong, “Onecat: Decoder-only auto-regressive model for unified understanding and generation,”ArXiv, vol. abs/2509.03498,
-
[35]
Available: https://api.semanticscholar.org/CorpusID: 281092364
[Online]. Available: https://api.semanticscholar.org/CorpusID: 281092364
-
[36]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache,
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu, “Kivi: A tuning-free asymmetric 2bit quantization for kv cache,”arXiv preprint arXiv:2402.02750, 2024
Pith/arXiv arXiv 2024
-
[37]
Wkvquant: Quantizing weight and key/value cache for large language models gains more,
Y . Yue, Z. Yuan, H. Duanmu, S. Zhou, J. Wu, and L. Nie, “Wkvquant: Quantizing weight and key/value cache for large language models gains more,”arXiv preprint arXiv:2402.12065, 2024
arXiv 2024
-
[38]
Gear: An efficient kv cache compression recipefor near- lossless generative inference of llm,
H. Kang, Q. Zhang, S. Kundu, G. Jeong, Z. Liu, T. Krishna, and T. Zhao, “Gear: An efficient kv cache compression recipefor near- lossless generative inference of llm,”arXiv preprint arXiv:2403.05527, 2024
arXiv 2024
-
[39]
Zipcache: Accurate and efficient kv cache quantization with salient token iden- tification,
Y . He, L. Zhang, W. Wu, J. Liu, H. Zhou, and B. Zhuang, “Zipcache: Accurate and efficient kv cache quantization with salient token iden- tification,”arXiv preprint arXiv:2405.14256, 2024
arXiv 2024
-
[40]
H2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R´e, C. Barrettet al., “H2o: Heavy-hitter oracle for efficient generative inference of large language models,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[41]
Snapkv: Llm knows what you are looking for before generation,
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “Snapkv: Llm knows what you are looking for before generation,”arXiv preprint arXiv:2404.14469, 2024
Pith/arXiv arXiv 2024
-
[42]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[43]
Transformers are multi- state rnns,
M. Oren, M. Hassid, Y . Adi, and R. Schwartz, “Transformers are multi- state rnns,”arXiv preprint arXiv:2401.06104, 2024
arXiv 2024
-
[44]
On the efficacy of eviction policy for key- value constrained generative language model inference,
S. Ren and K. Q. Zhu, “On the efficacy of eviction policy for key- value constrained generative language model inference,”arXiv preprint arXiv:2402.06262, 2024
arXiv 2024
-
[45]
Autoregressive image generation needs only a few lines of cached tokens,
Z. Qin, Y . Lv, M. Lin, Z. Zhang, C. Gan, T. Chen, and W. Lin, “Autoregressive image generation needs only a few lines of cached tokens,”arXiv preprint arXiv:2512.04857, 2025
arXiv 2025
-
[46]
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference,
Z. Wan, Z. Wu, C. Liu, J. Huang, Z. Zhu, P. Jin, L. Wang, and L. Yuan, “Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference,”arXiv preprint arXiv:2406.18139, 2024
arXiv 2024
-
[47]
Cam: Cache merging for memory-efficient llms inference,
Y . Zhang, Y . Du, G. Luo, Y . Zhong, Z. Zhang, S. Liu, and R. Ji, “Cam: Cache merging for memory-efficient llms inference,” inForty- first International Conference on Machine Learning, 2024
2024
-
[48]
Minicache: Kv cache compression in depth dimension for large language models,
A. Liu, J. Liu, Z. Pan, Y . He, G. Haffari, and B. Zhuang, “Minicache: Kv cache compression in depth dimension for large language models,” arXiv preprint arXiv:2405.14366, 2024
arXiv 2024
-
[49]
D2o: Dynamic discriminative operations for efficient generative inference of large language models,
Z. Wan, X. Wu, Y . Zhang, Y . Xin, C. Tao, Z. Zhu, X. Wang, S. Luo, J. Xiong, and M. Zhang, “D2o: Dynamic discriminative operations for efficient generative inference of large language models,”arXiv preprint arXiv:2406.13035, 2024
arXiv 2024
-
[50]
Efficient streaming language models with attention sinks,
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,”arXiv preprint arXiv:2309.17453, 2023
Pith/arXiv arXiv 2023
-
[51]
Duoattention: Efficient long-context llm inference with retrieval and streaming heads,
G. Xiao, J. Tang, J. Zuo, J. Guo, S. Yang, H. Tang, Y . Fu, and S. Han, “Duoattention: Efficient long-context llm inference with retrieval and streaming heads,” inInternational Conference on Learning Represen- tations, vol. 2025, 2025, pp. 37 228–37 253
2025
-
[52]
CAKE: Cascading and adaptive KV cache eviction with layer preferences,
Z. Qin, Y . Cao, M. Lin, W. Hu, S. Fan, K. Cheng, W. Lin, and J. Li, “CAKE: Cascading and adaptive KV cache eviction with layer preferences,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https: //openreview.net/forum?id=EQgEMAD4kv
2025
-
[53]
Vl-cache: Sparsity and modality-aware kv cache compression for vision-language model inference acceleration,
D. Tu, D. Vashchilenko, Y . Lu, and P. Xu, “Vl-cache: Sparsity and modality-aware kv cache compression for vision-language model inference acceleration,” inInternational Conference on Learning Rep- resentations, vol. 2025, 2025, pp. 219–239
2025
-
[54]
Collaborative decod- ing makes visual auto-regressive modeling efficient,
Z. Chen, X. Ma, G. Fang, and X. Wang, “Collaborative decod- ing makes visual auto-regressive modeling efficient,”arXiv preprint arXiv:2411.17787, 2024
arXiv 2024
-
[55]
Progressive supernet training for efficient visual autoregressive mod- eling,
X. Chen, Y . Shi, K. Li, H. Wang, Y . Li, X. Gu, X. Chen, and M. Lin, “Progressive supernet training for efficient visual autoregressive mod- eling,”arXiv preprint arXiv:2511.16546, 2025
arXiv 2025
-
[56]
Fastvar: Linear visual autoregressive modeling via cached token pruning,
H. Guo, Y . Li, T. Zhang, J. Wang, T. Dai, S.-T. Xia, and L. Benini, “Fastvar: Linear visual autoregressive modeling via cached token pruning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 011–19 021
2025
-
[57]
Frequency-aware au- toregressive modeling for efficient high-resolution image synthesis,
Z. Chen, J. Fan, Z. Yu, B. Zhuang, and M. Tan, “Frequency-aware au- toregressive modeling for efficient high-resolution image synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 17 140–17 149
2025
-
[58]
J. Chen, R. Lin, Z. Zheng, J. Li, M. Li, G. Luo, and X. Chen, “Toprovar: Efficient visual autoregressive modeling via tri-dimensional entropy-aware semantic analysis and sparsity optimization,”arXiv preprint arXiv:2602.22948, 2026
arXiv 2026
-
[59]
Litevar: Compressing visual autoregressive modelling with efficient attention and quantization,
R. Xie, T. Zhao, Z. Yuan, R. Wan, W. Gao, Z. Zhu, X. Ning, and Y . Wang, “Litevar: Compressing visual autoregressive modelling with efficient attention and quantization,”arXiv preprint arXiv:2411.17178, 2024
arXiv 2024
-
[60]
Sparvar: Exploring sparsity in visual autoregressive modeling for training-free acceleration,
Z. Li, N. Wang, T. Bai, C. Mei, P. Wang, S. Qiu, and J. Cheng, “Sparvar: Exploring sparsity in visual autoregressive modeling for training-free acceleration,”arXiv preprint arXiv:2602.04361, 2026
arXiv 2026
-
[61]
Memory-efficient visual autoregressive modeling with scale-aware kv cache compression,
K. Li, Z. Chen, C.-Y . Yang, and J.-N. Hwang, “Memory-efficient visual autoregressive modeling with scale-aware kv cache compression,” Advances in Neural Information Processing Systems, 2025
2025
-
[62]
Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation,
D. Li, A. Kamko, E. Akhgari, A. Sabet, L. Xu, and S. Doshi, “Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation,”arXiv preprint arXiv:2402.17245, 2024
Pith/arXiv arXiv 2024
-
[63]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li, “Human preference score v2: A solid benchmark for evaluating human pref- erences of text-to-image synthesis,”arXiv preprint arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[64]
Meda: Dynamic kv cache allocation for efficient multimodal long-context inference,
Z. Wan, H. Shen, X. Wang, C. Liu, Z. Mai, and M. Zhang, “Meda: Dynamic kv cache allocation for efficient multimodal long-context inference,”arXiv preprint arXiv:2502.17599, 2025
arXiv 2025
-
[65]
Imagereward: Learning and evaluating human preferences for text- to-image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “Imagereward: Learning and evaluating human preferences for text- to-image generation,”Advances in Neural Information Processing Systems, pp. 15 903–15 935, 2023
2023
-
[66]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inIEEE conference on computer vision and pattern recognition, 2009, pp. 248–255
2009
-
[67]
Geneval: An object- focused framework for evaluating text-to-image alignment,
D. Ghosh, H. Hajishirzi, and L. Schmidt, “Geneval: An object- focused framework for evaluating text-to-image alignment,”Advances in Neural Information Processing Systems, pp. 52 132–52 152, 2023
2023
-
[68]
Ella: Equip diffusion models with llm for enhanced semantic alignment,
X. Hu, R. Wang, Y . Fang, B. Fu, P. Cheng, and G. Yu, “Ella: Equip diffusion models with llm for enhanced semantic alignment,”arXiv preprint arXiv:2403.05135, 2024
Pith/arXiv arXiv 2024
-
[69]
Flashattention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning,”arXiv preprint arXiv:2307.08691, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.