Towards Graph Foundation Models for Dynamics in Complex Networked Systems: Lessons from Super-Spreader Identification in Multilayer Networks
Pith reviewed 2026-06-27 20:05 UTC · model grok-4.3
The pith
A model trained only on synthetic multilayer networks identifies super-spreaders in real ones without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
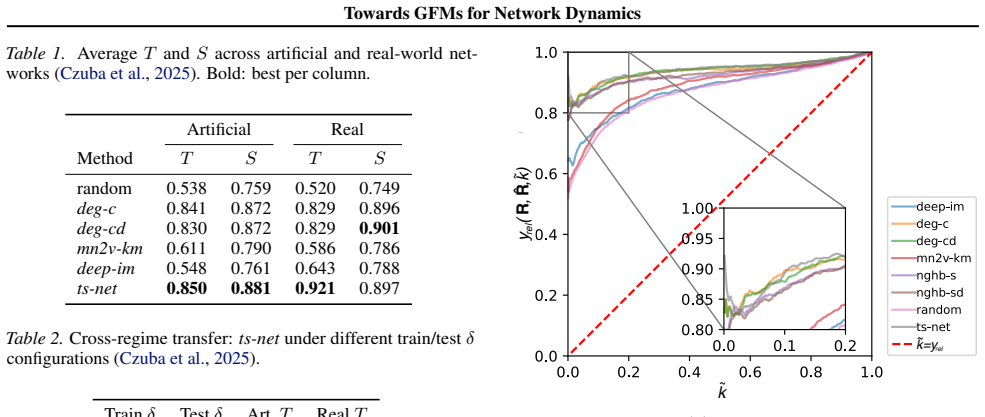
ts-net, trained solely on synthetic multilayer networks, demonstrates zero-shot generalisation to real-world multilayer networks of varying size and layer count and outperforms classical heuristics together with transductive baselines on three of four metrics for super-spreader identification.
What carries the argument
ts-net (TopSpreadersNetwork), an inductive model whose training distribution consists only of synthetic multilayer networks and whose inference is applied directly to unseen real multilayer networks.
If this is right
- Inductive models can replace per-network retraining for spreading-related tasks once the four design properties are met.
- Synthetic data alone can produce models that transfer to real multilayer networks of different sizes and layer counts.
- Super-spreader identification is one concrete task where cross-network reuse is already observable.
- Five further challenges (scale, many-layer generalisation, self-supervised pretraining, cross-task transfer, node-attribute integration) must be addressed before broader foundation models emerge.
Where Pith is reading between the lines
- The same training recipe could be tested on other dynamics tasks such as influence maximisation or epidemic threshold estimation.
- If synthetic pretraining works here, it may reduce the need for labelled real-world graphs in related network-science applications.
- The listed open challenges provide a concrete roadmap that future work can follow without first inventing new architectures.
Load-bearing premise
The structural properties of the synthetic multilayer networks used for training are sufficiently representative of those in real-world multilayer networks for the super-spreader identification task to transfer without retraining.
What would settle it
If ts-net is evaluated on additional real-world multilayer networks whose layer-interconnection statistics fall outside the range seen in the synthetic training set and its performance drops below the transductive baselines, the zero-shot generalisation claim would be falsified.
Figures
read the original abstract
Network dynamics - including spreading, influence maximisation, and epidemic modelling - remain largely confined to the transductive paradigm, where models are trained on a single network and cannot be reused on unseen graphs without retraining. We argue that inductive cross-network generalisation is a necessary prerequisite for Graph Foundation Models (GFMs) in this domain and propose four design properties towards this goal. As a proof of concept, ts-net (TopSpreadersNetwork), trained solely on synthetic multilayer networks (MLNs), demonstrates zero-shot generalisation to real-world MLNs of varying size and layer count, outperforming classical heuristics and transductive baselines on three of four metrics. Based on ts-net's performance, we further outline five open challenges towards building GFMs for network dynamics: scale, many-layer generalisation, self-supervised pretraining, cross-task transfer, and node-attribute integration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that inductive cross-network generalization is a prerequisite for Graph Foundation Models (GFMs) applied to network dynamics tasks such as spreading processes. It proposes four design properties toward this goal and presents ts-net (TopSpreadersNetwork) as a proof-of-concept model trained exclusively on synthetic multilayer networks (MLNs). The model is claimed to achieve zero-shot generalization to real-world MLNs of varying size and layer count, outperforming classical heuristics and transductive baselines on three of four metrics for super-spreader identification. The manuscript concludes by outlining five open challenges: scale, many-layer generalization, self-supervised pretraining, cross-task transfer, and node-attribute integration.
Significance. If the zero-shot generalization result is substantiated, the work would mark a meaningful advance by demonstrating that models for network dynamics can move beyond the dominant transductive setting. The explicit framing around design properties for GFMs and the enumeration of open challenges provide a useful roadmap for the community working on inductive graph models for dynamical processes.
major comments (2)
- [Abstract] Abstract: The central claim that ts-net, trained solely on synthetic MLNs, demonstrates zero-shot generalization to real-world MLNs of varying size and layer count rests on the unverified assumption that the synthetic generation process produces networks whose degree distributions, interlayer correlations, clustering, and spreading-relevant motifs are statistically close to the real test networks. No parameters of the synthetic model or any Kolmogorov-Smirnov/moment-matching validation between train and test distributions are supplied, leaving open the possibility that reported gains reflect coincidental overlap rather than true cross-network generalization.
- [Abstract] Abstract: The stated outperformance on three of four metrics supplies no information on model architecture, training details, statistical significance, dataset sizes, or exact baseline implementations. This absence prevents assessment of whether the empirical data actually support the zero-shot generalization claim that is load-bearing for the paper's contribution to GFMs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to substantiate the zero-shot generalization claims. We address each major comment below and agree that revisions are required to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ts-net, trained solely on synthetic MLNs, demonstrates zero-shot generalization to real-world MLNs of varying size and layer count rests on the unverified assumption that the synthetic generation process produces networks whose degree distributions, interlayer correlations, clustering, and spreading-relevant motifs are statistically close to the real test networks. No parameters of the synthetic model or any Kolmogorov-Smirnov/moment-matching validation between train and test distributions are supplied, leaving open the possibility that reported gains reflect coincidental overlap rather than true cross-network generalization.
Authors: We agree that the abstract does not explicitly state the synthetic generator parameters or include distributional validation. Section 3.2 of the manuscript describes the multilayer network generation process and its parameters. However, no Kolmogorov-Smirnov or moment-matching comparisons between synthetic training distributions and real test networks are currently reported. We will add these parameters to the abstract and include a new analysis (e.g., KS tests on degree distributions, interlayer correlations, and clustering coefficients) in the revised manuscript or supplementary material to directly address this concern. revision: yes
-
Referee: [Abstract] Abstract: The stated outperformance on three of four metrics supplies no information on model architecture, training details, statistical significance, dataset sizes, or exact baseline implementations. This absence prevents assessment of whether the empirical data actually support the zero-shot generalization claim that is load-bearing for the paper's contribution to GFMs.
Authors: We acknowledge that the abstract's brevity omits these specifics. Full details appear in the manuscript: model architecture in Section 4, training procedure and dataset sizes in Section 5, statistical significance testing in Section 6, and baseline implementations in Section 6.1. To improve assessability, we will revise the abstract to incorporate a concise summary of key experimental elements (e.g., training set size and metrics) and ensure the results section explicitly references the statistical tests and baseline configurations. revision: yes
Circularity Check
No circularity: empirical zero-shot evaluation on external real-world data
full rationale
The paper's central claim is an empirical demonstration that ts-net, trained only on synthetic multilayer networks, achieves zero-shot transfer to real-world MLNs of varying sizes and layer counts, outperforming heuristics and transductive baselines on three of four metrics. This is a direct comparison against external benchmarks with no reduction of the reported performance to fitted parameters, self-referential equations, or self-citation chains. No load-bearing steps invoke uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results. The design properties and open challenges are presented as forward-looking discussion rather than derived claims. The result is therefore self-contained against external test data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scientific Reports , volume =
Cardillo, Alessio and Gómez-Gardeñes, Jesús and Zanin, Massimiliano and Romance, Miguel and Papo, David and Pozo, Francisco del and Boccaletti, Stefano , title =. Scientific Reports , volume =. 2013 , month =
2013
-
[2]
Proceedings of the 15th ACM SIGKDD internat
Efficient influence maximization in social networks , author =. Proceedings of the 15th ACM SIGKDD internat. conf. on Knowledge discovery and data mining , pages =
-
[3]
Social Network Analysis and Mining , volume =
Czuba, Micha. Social Network Analysis and Mining , volume =. 2025 , month = apr, issn =
2025
-
[4]
Identifying super spreaders in multilayer networks,
Identifying Super Spreaders in Multilayer Networks [Preprint with Appendices] , author =. arXiv , year =. 2505.20980 , archiveprefix =
-
[5]
Marketing Letters , volume =
Goldenberg, Jacob and Libai, Barak and Muller, Eitan , title =. Marketing Letters , volume =. 2001 , month = aug, issn =
2001
-
[6]
international conference on machine learning , year =
Gnnrank: Learning global rankings from pairwise comparisons via directed GNNs , author =. international conference on machine learning , year =
-
[7]
A multilayer network dataset of interaction and influence spreading in a virtual world , journal =
Jankowski, Jaros. A multilayer network dataset of interaction and influence spreading in a virtual world , journal =. 2017 , issn =
2017
-
[8]
Journal of Complex Networks , volume =
Multilayer Networks , author =. Journal of Complex Networks , volume =. 2014 , month =
2014
-
[9]
and Xue, Lukas and Song, James and Qiu, Meikang and Zhao, Liang , title =
Ling, Chen and Jiang, Junji and Wang, Junxiang and Thai, My T. and Xue, Lukas and Song, James and Qiu, Meikang and Zhao, Liang , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[10]
The Twelfth International Conference on Learning Representations , year =
One for All: Towards Training One Graph Model for All Classification Tasks , author =. The Twelfth International Conference on Learning Representations , year =
-
[11]
Spreading Processes in Multilayer Networks , year =
Salehi, Mostafa and Sharma, Rajesh and Marzolla, Moreno and Magnani, Matteo and Siyari, Payam and Montesi, Danilo , journal =. Spreading Processes in Multilayer Networks , year =
-
[12]
, title =
Panagopoulos, George and Tziortziotis, Nikolaos and Vazirgiannis, Michalis and Pang, Jun and Malliaros, Fragkiskos D. , title =. Social Network Analysis and Mining , volume =. 2024 , month = oct, urldate =
2024
-
[13]
and Rayhan, Joty Shafiq and Sun, Changsheng and Cui, Jiangtao , journal =
Li, Hui and Xu, Mengting and Bhowmick, Sourav S. and Rayhan, Joty Shafiq and Sun, Changsheng and Cui, Jiangtao , journal =. PIANO: Influence Maximization Meets Deep Reinforcement Learning , year =
-
[14]
Proceedings of the 14th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , year =
Bollobas, Bela and Borgs, Christian and Chayes, Jennifer and Riordan, Oliver , title =. Proceedings of the 14th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , year =
-
[15]
Tang, Jiabin and Yang, Yuhao and Wei, Wei and Shi, Lei and Su, Lixin and Cheng, Suqi and Yin, Dawei and Huang, Chao , booktitle =
-
[16]
Graph attention networks , author =. arXiv preprint arXiv:1710.10903 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Network Science , volume =
Analysis of population functional connectivity data via multilayer network embeddings , author =. Network Science , volume =. 2021 , publisher =
2021
-
[18]
How Powerful are Graph Neural Networks?
How powerful are graph neural networks? , author =. arXiv preprint arXiv:1810.00826 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Yuan, Zirui and Shao, Minglai and Chen, Zhiqian , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.