TS-Neyman: Posterior Sampling for Adaptive Stratified Estimation
Pith reviewed 2026-06-27 18:15 UTC · model grok-4.3
The pith
TS-Neyman replaces unknown within-stratum variances with independent inverse-chi-squared posterior draws to produce an adaptive allocation that converges almost surely to the Neyman target for any fixed finite number of strata.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
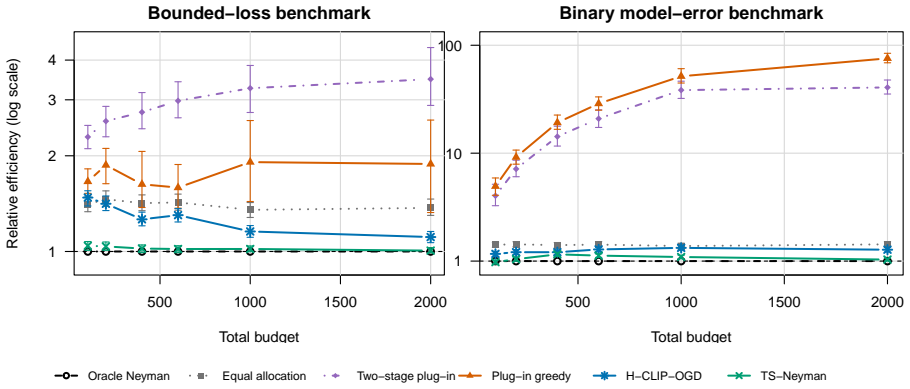
TS-Neyman is a Thompson-sampling allocation rule that draws independent inverse-chi-squared posteriors for each stratum variance, computes the exact one-step marginal reduction in variance for each possible next observation under those draws, and samples the next stratum according to the normalized priorities. For any fixed finite number of strata the resulting allocation proportions converge almost surely to the Neyman target, the proxy variance is asymptotically optimal, and the adaptive stratified estimator satisfies a central limit theorem; the same rule stays within a few percent of oracle efficiency on bounded-loss and binary benchmarks and improves on equal allocation in a CivilCommen
What carries the argument
The TS-Neyman priority index formed by replacing unknown within-stratum variances with independent inverse-chi-squared posterior draws and evaluating the exact one-step marginal variance reduction under each draw.
If this is right
- The adaptive estimator inherits the same asymptotic variance as the oracle Neyman estimator once the fixed-strata condition holds.
- Common-pilot warm starts and working-prior misspecification do not destroy the convergence or the efficiency gains shown in the benchmarks.
- Plug-in greedy and two-stage plug-in rules can degrade by more than an order of magnitude under sparse pilots, while TS-Neyman remains stable.
- The central limit theorem supplies valid asymptotic confidence intervals once the allocation has stabilized.
Where Pith is reading between the lines
- The same posterior-sampling construction could be applied to strata defined by continuous scores or by model uncertainty rather than fixed categories.
- If the number of strata grows slowly with the budget, the almost-sure convergence may still hold but the rate and the CLT constant would require additional analysis.
- The method supplies a practical way to allocate labels when the final metric is a weighted average across subgroups whose variances are learned on the fly.
Load-bearing premise
The number of strata is fixed and finite in advance so that the marginal-gain structure remains well-defined and the posterior draws preserve the separation between allocation and final estimation.
What would settle it
A simulation with fixed finite strata in which the long-run allocation proportions deviate from the Neyman target by more than sampling error after the budget exceeds several thousand observations per stratum.
Figures
read the original abstract
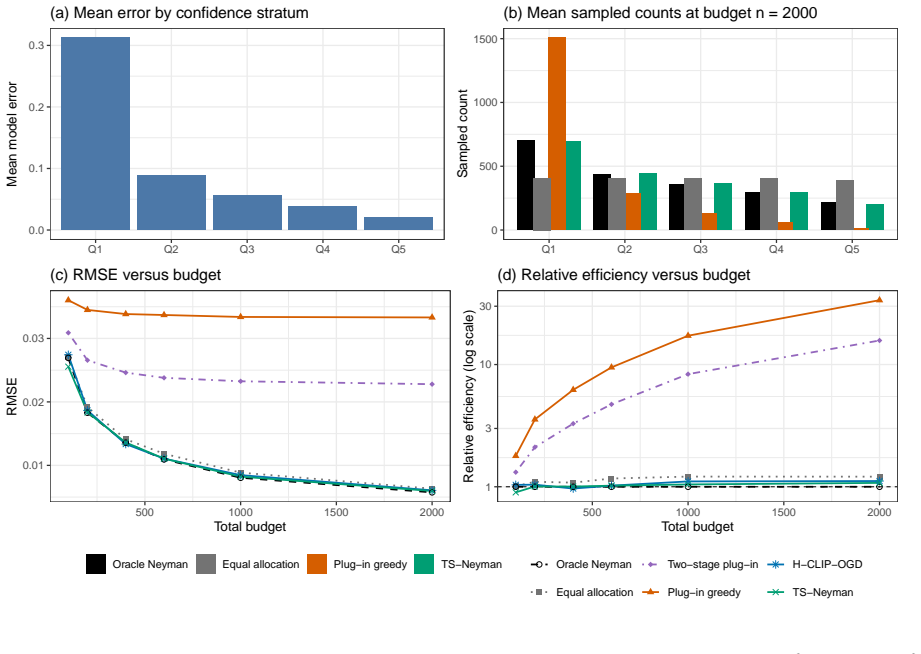
Many model evaluation tasks reduce to estimating an average loss, error rate, or subgroup metric on a stratified pool when each label, human rating, or simulator call is costly. The precision-optimal Neyman allocation depends on within-stratum variances, which must be learned from the same observations used for estimation. We formulate this as a sequential allocation problem and use the exact one-step marginal variance reduction as the priority index. Replacing the unknown variances by independent inverse-chi-squared posterior draws yields TS-Neyman, a Thompson-sampling rule that preserves the oracle marginal-gain structure while randomizing over variance uncertainty. For any fixed finite number of strata, we prove almost-sure convergence of the TS-Neyman allocation proportions to the Neyman target, asymptotic optimality of the variance proxy, and a central limit theorem for the resulting adaptive stratified estimator. In two five-stratum budget-scaling benchmarks, one bounded-loss benchmark and one binary model-error benchmark in the spirit of Dai et al. 2023, TS-Neyman's relative efficiency stays within 5 percent of the oracle on the bounded-loss population and within about 15 percent on the binary benchmark. In an additional CivilComments real-data replay with confidence-based strata, it stays within about 8 percent of the oracle and improves on equal allocation by roughly 7 to 14 percent in MSE across budgets, while plug-in greedy and two-stage plug-in can degrade by over an order of magnitude under sparse pilots. Common-pilot warm-start and prior-sensitivity studies show that this behavior is stable under working-model and working-prior misspecification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TS-Neyman, a Thompson-sampling allocation rule for sequential stratified estimation that draws independent inverse-chi-squared posteriors over within-stratum variances and uses the exact one-step marginal variance reduction as the priority index. For any fixed finite number of strata it claims to prove almost-sure convergence of the allocation proportions to the Neyman target, asymptotic optimality of the resulting variance proxy, and a central limit theorem for the adaptive estimator. On two five-stratum synthetic benchmarks (bounded-loss and binary model-error) and a CivilComments real-data replay the method stays within 5–15 % of oracle efficiency and improves on equal allocation while plug-in greedy and two-stage plug-in can degrade sharply under sparse pilots.
Significance. If the stated convergence and CLT results hold, the work supplies a theoretically grounded, randomization-based alternative to plug-in Neyman allocation that remains stable under working-model misspecification and yields concrete efficiency gains on realistic costly-label tasks. The explicit conditioning on fixed finite strata together with the marginal-gain structure that avoids direct circular dependence on the same observations for both allocation and final estimation is a clear strength.
major comments (2)
- [Theoretical results] Theoretical results section: the manuscript asserts almost-sure convergence, asymptotic optimality, and a CLT but supplies neither the full proof details nor an appendix containing the key martingale or concentration arguments that establish how independent posterior draws preserve the one-step marginal structure; this is load-bearing for the central claims.
- [Experiments] Empirical section and reproducibility: the reported relative-efficiency figures (within 5 % on bounded-loss, ~15 % on binary, ~8 % on CivilComments) are central to the practical contribution, yet no code, data splits, or exact hyper-parameter settings for the inverse-chi-squared working prior are provided, preventing independent verification of the benchmark numbers.
minor comments (2)
- [Notation] Notation: the distinction between the random allocation proportions π_t and the limiting Neyman proportions π* should be made explicit in the statement of the CLT.
- [References] The abstract and introduction cite Dai et al. 2023 but the reference list entry is missing the full bibliographic details.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The two major comments are addressed point by point below; both can be resolved by additions to the manuscript and supplementary material.
read point-by-point responses
-
Referee: [Theoretical results] Theoretical results section: the manuscript asserts almost-sure convergence, asymptotic optimality, and a CLT but supplies neither the full proof details nor an appendix containing the key martingale or concentration arguments that establish how independent posterior draws preserve the one-step marginal structure; this is load-bearing for the central claims.
Authors: We agree that the detailed arguments are necessary to substantiate the central claims. The current version sketches the proof strategy in the main text but does not expand the martingale convergence, concentration bounds, or the preservation of the marginal-gain structure under independent inverse-chi-squared draws into a self-contained appendix. We will add a new appendix that supplies the complete proofs, including the relevant martingale arguments and the one-step marginal structure preservation. revision: yes
-
Referee: [Experiments] Empirical section and reproducibility: the reported relative-efficiency figures (within 5 % on bounded-loss, ~15 % on binary, ~8 % on CivilComments) are central to the practical contribution, yet no code, data splits, or exact hyper-parameter settings for the inverse-chi-squared working prior are provided, preventing independent verification of the benchmark numbers.
Authors: We acknowledge that the absence of code, data splits, and exact prior hyper-parameters limits reproducibility. The manuscript describes the experimental setup at a high level but does not include the implementation, the precise inverse-chi-squared parameters, or the CivilComments data-processing pipeline. In the revision we will add a supplementary file (or public repository link) containing the full code, data splits, random seeds, and the exact hyper-parameter values used for the working prior, together with instructions to reproduce the reported efficiency numbers. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core claims are almost-sure convergence of TS-Neyman allocation proportions to the externally defined Neyman target (proportions minimizing variance given true within-stratum variances), asymptotic optimality of the variance proxy, and a CLT for the resulting estimator. These rest on the one-step marginal variance reduction index and independent inverse-chi-squared posterior draws, which are constructed to preserve the oracle structure without redefining the target in terms of the procedure's own outputs. No equation reduces a claimed result to a fitted quantity computed from the same data, no self-citation supplies a load-bearing uniqueness theorem, and the fixed finite strata assumption keeps the derivation self-contained against standard martingale and stratified sampling arguments.
Axiom & Free-Parameter Ledger
free parameters (1)
- working prior hyperparameters for inverse-chi-squared
axioms (2)
- standard math Standard martingale convergence and central limit theorems for adaptive allocation with fixed finite strata apply once the allocation proportions converge.
- domain assumption The one-step marginal variance reduction remains a valid priority index when variances are replaced by independent posterior draws.
Reference graph
Works this paper leans on
-
[1]
org/files/papers/batch_adaptive.pdf
URLhttps://www.mattblackwell. org/files/papers/batch_adaptive.pdf. Daniel Borkan, Jeffrey Sorensen, Nithum Thain, and Lucas Dixon. Nuanced metrics for measuring unintended bias with real data for text classification. InCompanion Proceedings of the 2019 World Wide Web Conference,
2019
-
[2]
11 Jinyong Hahn, Keisuke Hirano, and Dean Karlan
doi: 10.1111/j.1467-985X.2006.00423.x. 11 Jinyong Hahn, Keisuke Hirano, and Dean Karlan. Adaptive experimental design using the propensity score.Journal of Business & Economic Statistics, 29(1):96–108,
-
[3]
doi: 10.1198/jbes.2009.08161. Peter Hall and C. C. Heyde.Martingale Limit Theory and Its Application. Academic Press,
-
[4]
A Generalization of Sampling Without Replacement from a Finite Universe
doi: 10.1080/01621459.1952.10483446. Edward V. Huntington. The apportionment of representatives in congress.Transactions of the American Mathematical Society, 30(1):85–110,
-
[5]
doi: 10.2307/1989268. Joseph B. Kadane. Optimal dynamic sample allocation among strata.Journal of Official Statistics, 21(4):531–541,
-
[6]
doi: 10.2307/2342192. Daniel J. Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. A tutorial on Thompson sampling.Foundations and Trends in Machine Learning, 11(1):1–96,
-
[7]
Mohammad Salehi, Mohammad Moradi, Jennifer A
doi: 10.1561/2200000070. Mohammad Salehi, Mohammad Moradi, Jennifer A. Brown, and David R. Smith. Efficient estimators for adaptive stratified sequential sampling.Journal of Statistical Computation and Simulation, 80 (10):1163–1179,
-
[8]
Barry Schouten, Melania Calinescu, and Annemieke Luiten
doi: 10.1080/00949650903005664. Barry Schouten, Melania Calinescu, and Annemieke Luiten. Optimizing quality of response through adaptive survey designs.Survey Methodology, 39(1):29–58,
-
[9]
gc.ca/n1/pub/12-001-x/2013001/article/11824-eng.htm
URLhttps://www150.statcan. gc.ca/n1/pub/12-001-x/2013001/article/11824-eng.htm. William R. Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3–4):285–294,
-
[10]
doi: 10.2307/2332286. Tommy Wright. Exact optimal sample allocation: More efficient than neyman.Statistics & Probability Letters, 129:50–57,
-
[11]
doi: 10.1016/j.spl.2017.04.026. Tommy Wright. A general exact optimal sample allocation algorithm: With bounded cost and bounded sample sizes.Statistics & Probability Letters, 165:108829,
-
[12]
doi: 10.1016/j.spl.2020. 108829. Jasper B. Yang, Thomas Lumley, Bryan E. Shepherd, and Pamela A. Shaw. Optimum allocation for adaptive multi-wave sampling in R: The R package optimall.Journal of Statistical Software, 114 (10):1–31,
-
[13]
Near Optimal Stratified Sampling
doi: 10.18637/jss.v114.i10. URLhttps://www.jstatsoft.org/article/view/ v114i10. Tiancheng Yu, Xiyu Zhai, and Suvrit Sra. Near optimal stratified sampling.arXiv preprint arXiv:1906.11289,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18637/jss.v114.i10 1906
-
[14]
Near Optimal Stratified Sampling
doi: 10.48550/arXiv.1906.11289. URLhttps://arxiv.org/abs/1906. 11289. 12 Table 2: Relative efficiency in the CivilComments replay experiment. Oracle Neyman is normalized to 1 and omitted. Budget Equal allocation Two-stage plug-in Plug-in greedy H-CLIP-OGD TS–Neyman 100 1.011 1.316 1.790 1.037 0.900 200 1.099 2.109 3.555 1.040 1.006 400 1.081 3.285 6.211 0...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.11289 1906
-
[15]
doi: 10.1080/00401706.1970.10488639. Jinglong Zhao. Adaptive neyman allocation.arXiv preprint arXiv:2309.08808,
-
[16]
URLhttps: //arxiv.org/abs/2309.08808. A Additional numerical results A.1 CivilComments replay details Table 2 reports the full per-budget relative-efficiency summary for the CivilComments confidence- quintile replay. Oracle Neyman is normalized to 1 and omitted. A.2 Warm-start robustness details Table 3 reports the full common-pilot warm-start summary wit...
arXiv 2000
-
[17]
CLIP-OGD-inspired projected-gradient baseline forH strata
TS-Neyman 0.003 0.176 0.176 0.999 B H-CLIP-OGD construction Section 3.2 introducesH-CLIP-OGD as an empirical comparator inspired by CLIP-OGD (Dai et al., 2023). Here we give the full construction. Naming caveat.We call the algorithm H-CLIP-OGD for brevity. The name should be read as “CLIP-OGD-inspired projected-gradient baseline forH strata” rather than a...
2023
-
[18]
= (N1/N)2s2 1 p + (N2/N)2s2 2 1−p , and Algorithm 2 becomes clipped projected stochastic gradient descent on this scalar function with a plug-in gradient. This is structurally similar to CLIP-OGD (Dai et al., 2023), with two 16 principal differences: the action space here is two strata in a sequential survey rather than treatment and control in a sequenti...
2023
-
[19]
On the event n |τ 2 h(t)−σ 2 h| ≤η o ∩ n Zt/νh(t)−1 ≤η o , one hasν h(t)/Zt ≤(1−η) −1 ≤2, and hence eσ2 h(t)−σ 2 h ≤ τ 2 h(t)−σ 2 h νh(t) Zt +σ 2 h νh(t) Zt −1 < δ
+η < δ. On the event n |τ 2 h(t)−σ 2 h| ≤η o ∩ n Zt/νh(t)−1 ≤η o , one hasν h(t)/Zt ≤(1−η) −1 ≤2, and hence eσ2 h(t)−σ 2 h ≤ τ 2 h(t)−σ 2 h νh(t) Zt +σ 2 h νh(t) Zt −1 < δ. Thus P |eσ2 h(t)−σ 2 h|> δ| F t ≤1{|τ 2 h(t)−σ 2 h|> η}+P χ2 νh(t) νh(t) −1 > η ! , and the right-hand side converges almost surely to zero. C.3 Persistent exploration Proposition C.3(...
2019
-
[20]
The martingale strong law (Hall and Heyde, 1980, Chapter
2 <∞a.s. The martingale strong law (Hall and Heyde, 1980, Chapter
1980
-
[21]
Fora h ̸= 0, E h a2 h(∆M Y h (s+ 1)) 21{|ah| |∆M Y h (s+ 1)|> ε √ t} Fs i =a 2 hπs+1,hE h (Yh1 −µ h)21{|ah| |Yh1 −µ h|> ε √ t} i
Because at most one increment can be nonzero at each step, (a⊤∆MY (s+ 1)) 21{|a⊤∆MY (s+ 1)|> ε √ t} ≤ HX h=1 a2 h(∆M Y h (s+ 1)) 21{|ah| |∆M Y h (s+ 1)|> ε √ t}. Fora h ̸= 0, E h a2 h(∆M Y h (s+ 1)) 21{|ah| |∆M Y h (s+ 1)|> ε √ t} Fs i =a 2 hπs+1,hE h (Yh1 −µ h)21{|ah| |Yh1 −µ h|> ε √ t} i . The expectation on the right converges to zero by dominated conv...
1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.