TRADE: Transducer-Augmented Decoder for Speech LLM
Pith reviewed 2026-06-27 18:38 UTC · model grok-4.3
The pith
A transducer branch added to a speech LLM lets one checkpoint support both offline and streaming recognition across latency points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
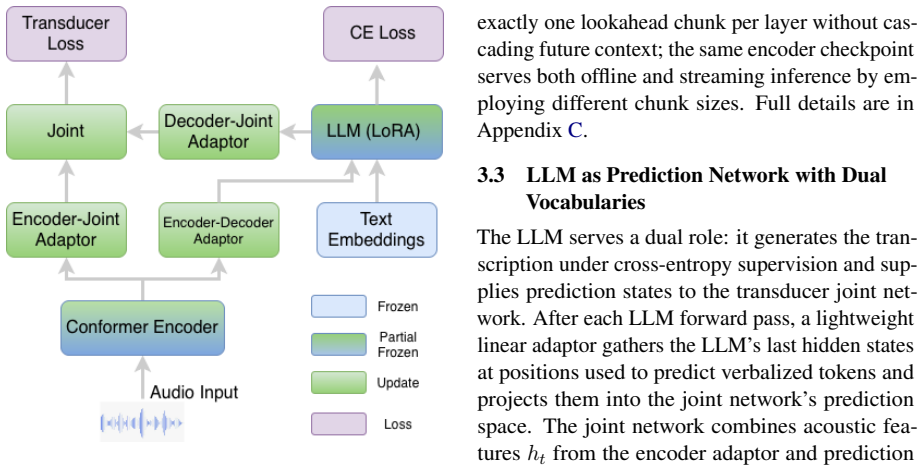
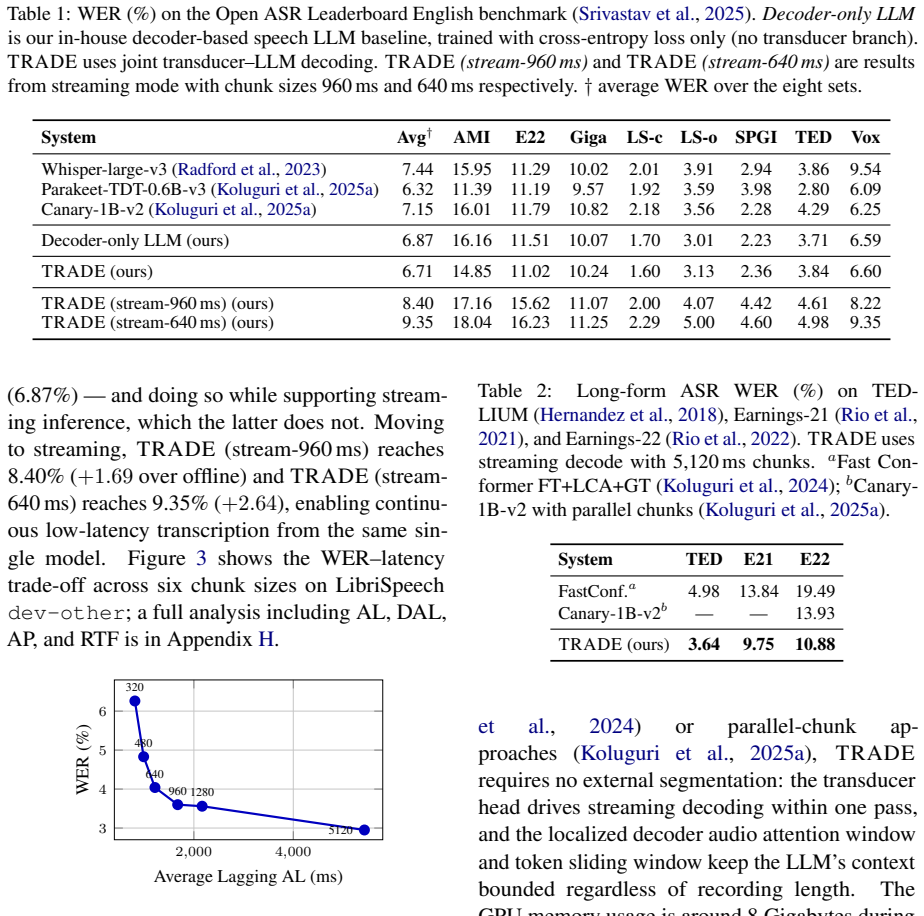
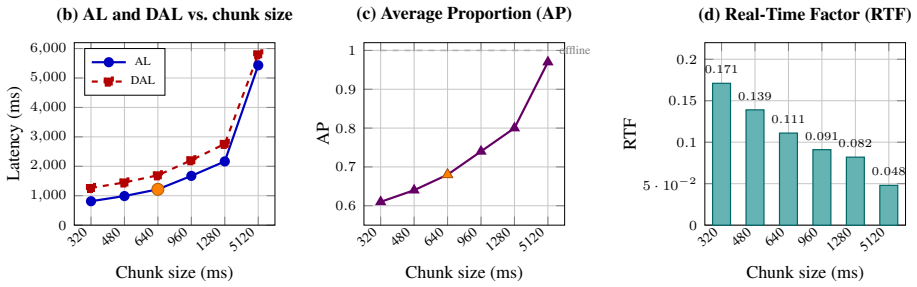
TRADE augments a multimodal LLM with a transducer branch that shares the audio encoder and uses the LLM's hidden states directly as the prediction network. With tightly coupled dual vocabularies, chunk-synchronized streaming training with gradient stopping, and Localized Decoder Audio Attention, a single checkpoint supports offline and streaming decoding across a continuous range of latency operating points, achieving 6.71 percent average WER on the Open ASR Leaderboard and 8.40 percent streaming with 960 ms chunks from the same checkpoint, along with 3.64 percent WER on TED-LIUM and 10.88 percent on Earnings-22 without external segmentation.
What carries the argument
The transducer branch that uses the LLM hidden states directly as its prediction network, together with chunk-synchronized training and Localized Decoder Audio Attention (LDAA) for causal memory control.
If this is right
- A single trained model can be deployed for any chosen latency operating point without retraining.
- Long utterances can be processed end-to-end without relying on external segmentation.
- Sentence-end punctuation timestamps from the transducer improve end-of-utterance detection when fused with acoustic VAD.
- The same architecture supports a continuous spectrum of chunk sizes while preserving linguistic reasoning from the LLM.
Where Pith is reading between the lines
- Production ASR systems could reduce the number of distinct models they maintain by adopting this shared-branch design.
- The approach may extend to other multimodal sequence tasks that need both batch and real-time modes from one set of weights.
- Further scaling the dual-vocabulary coupling could test whether fusion remains zero-cost at larger LLM vocabularies.
Load-bearing premise
The transducer branch can share the LLM hidden states and dual vocabularies without introducing train-inference mismatch or accuracy loss that would require separate models or post-hoc fixes.
What would settle it
An experiment showing that the same checkpoint cannot reach both the reported 6.71 percent offline WER and 8.40 percent streaming WER without separate training runs or post-training adjustments would falsify the claim.
Figures

read the original abstract
Speech Large Language Models (Speech LLMs) lack a principled mechanism for streaming inference: their label-synchronous generation has no acoustic-frame alignment, making real-time decoding and end-of-utterance detection difficult. We propose TRADE TRansducer-Augmented DEcoder, which augments a multimodal LLM with a transducer branch that shares the audio encoder and uses the LLM's hidden states directly as the prediction network -- coupling frame-synchronous acoustic alignment with the LLM's linguistic reasoning. Three design choices make the system accurate, streamable, and long-form capable: (1)Tightly coupled dual vocabularies -- a compact transducer vocabulary derived from the LLM vocabulary, enabling zero-cost score fusion; (2)Chunk-synchronized streaming training with gradient stopping, eliminating the train-inference mismatch at offline-equivalent memory cost; and (3)Localized Decoder Audio Attention (LDAA), a causal sliding window that caps KV-cache memory independently of utterance length. A single TRADE checkpoint supports offline and streaming decoding across a continuous range of latency operating points. TRADE achieves 6.71% average WER on the Open ASR Leaderboard, while the streaming recognition with 960ms chunk size reaches 8.40% from the same checkpoint. On long-form speech, it obtains 3.64% WER on TED-LIUM and 10.88% on Earnings-22 without external segmentation. TRADE provides sentence-end punctuation timestamps that, when combined with acoustic voice activity detection (VAD), improve end-of-utterance detection by +0.03 F_1 over acoustic VAD alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRADE, a transducer-augmented decoder for Speech LLMs. It augments a multimodal LLM with a transducer branch that shares the audio encoder and uses LLM hidden states as the prediction network, combined with tightly coupled dual vocabularies for zero-cost fusion, chunk-synchronized streaming training with gradient stopping to eliminate train-inference mismatch, and Localized Decoder Audio Attention (LDAA) for bounded KV-cache memory. A single checkpoint is claimed to support both offline and streaming decoding over a continuous latency range, achieving 6.71% average WER on the Open ASR Leaderboard (offline) and 8.40% at 960 ms chunk size (streaming), plus strong long-form results on TED-LIUM (3.64%) and Earnings-22 (10.88%) without external segmentation, and improved end-of-utterance detection via punctuation timestamps.
Significance. If the single-checkpoint claim and mismatch elimination hold under rigorous verification, the work offers a principled integration of frame-synchronous transducer alignment with LLM linguistic reasoning, enabling flexible latency operating points without separate models or high memory overhead. This would be a meaningful advance for practical deployment of Speech LLMs in real-time and long-form ASR.
major comments (2)
- [Abstract] Abstract: the central claim that 'a single TRADE checkpoint supports offline and streaming decoding across a continuous range of latency operating points' rests on chunk-synchronized training with gradient stopping eliminating mismatch, yet only two operating points are reported (6.71% offline, 8.40% at 960 ms) with no results shown for intermediate chunk sizes and no ablation isolating the gradient-stopping component.
- [Abstract] Abstract: no explicit train-inference mismatch metric (e.g., divergence between offline and streaming forward passes on identical inputs) or ablation on the shared transducer branch using LLM hidden states is supplied, leaving the effectiveness of gradient stopping and dual-vocabulary fusion unverified despite being load-bearing for the single-checkpoint architecture.
minor comments (2)
- [Abstract] Abstract: the Open ASR Leaderboard WER comparison lacks explicit baseline models, test-set breakdown, or error analysis to contextualize the reported gains.
- [Abstract] Abstract: LDAA is described only at high level; a concrete definition of the causal sliding window and its interaction with the transducer branch would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential significance of the single-checkpoint architecture. We address each major comment below and will incorporate revisions to provide stronger empirical support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'a single TRADE checkpoint supports offline and streaming decoding across a continuous range of latency operating points' rests on chunk-synchronized training with gradient stopping eliminating mismatch, yet only two operating points are reported (6.71% offline, 8.40% at 960 ms) with no results shown for intermediate chunk sizes and no ablation isolating the gradient-stopping component.
Authors: We agree that the current reporting of only the offline and 960 ms points provides limited direct evidence for continuous latency coverage. The chunk-synchronized training with gradient stopping is designed to support arbitrary chunk sizes by aligning train and inference distributions. In revision we will add WER results for intermediate chunk sizes (320 ms, 480 ms, 640 ms) on the Open ASR Leaderboard and include an ablation that isolates gradient stopping by comparing the full method against a variant without gradient stopping. revision: yes
-
Referee: [Abstract] Abstract: no explicit train-inference mismatch metric (e.g., divergence between offline and streaming forward passes on identical inputs) or ablation on the shared transducer branch using LLM hidden states is supplied, leaving the effectiveness of gradient stopping and dual-vocabulary fusion unverified despite being load-bearing for the single-checkpoint architecture.
Authors: We acknowledge that an explicit mismatch metric and targeted ablations on the shared transducer branch and dual-vocabulary fusion are absent. We will add (1) a quantitative mismatch metric (token-level prediction divergence and alignment error between offline and streaming forward passes on identical inputs), (2) an ablation replacing LLM hidden states with a dedicated prediction network, and (3) an ablation comparing tightly-coupled dual-vocabulary fusion against independent scoring. These will appear in the revised manuscript. revision: yes
Circularity Check
No significant circularity; architecture and results are independently constructed
full rationale
The paper introduces TRADE as a new architectural augmentation to Speech LLMs, specifying three concrete design choices (dual vocabularies, chunk-synchronized training with gradient stopping, and LDAA) and reporting empirical WER numbers on external benchmarks (Open ASR Leaderboard, TED-LIUM, Earnings-22). No equations, derivations, or parameter-fitting steps are described that reduce the central claims (single-checkpoint offline/streaming support, continuous latency range) back to the inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing justifications. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arivazhagan, Colin Cherry, Wolfgang Macherey, Chung-Cheng Chiu, Semih Yavuz, Ruoming Pang, Wei Li, and Colin Raffel
N. Arivazhagan, Colin Cherry, Wolfgang Macherey, Chung-Cheng Chiu, Semih Yavuz, Ruoming Pang, Wei Li, and Colin Raffel. 2019. Monotonic infinite lookback attention for simultaneous machine translation. In ACL
2019
- [2]
-
[3]
Puvvada, Jason Li, Subhankar Ghosh, Jagadeesh Balam, and Boris Ginsburg
Zhehuai Chen, He Huang, Andrei Andrusenko, Oleksii Hrinchuk, Krishna C. Puvvada, Jason Li, Subhankar Ghosh, Jagadeesh Balam, and Boris Ginsburg. 2024 a . https://arxiv.org/abs/2310.09424 SALM : Speech-Augmented Language Model with In-Context Learning for Speech Recognition and Translation . In Proc. ICASSP
-
[4]
Puvvada, Nithin Rao Koluguri, Piotr \.Z elasko, Jagadeesh Balam, and Boris Ginsburg
Zhehuai Chen, He Huang, Oleksii Hrinchuk, Krishna C. Puvvada, Nithin Rao Koluguri, Piotr \.Z elasko, Jagadeesh Balam, and Boris Ginsburg. 2024 b . https://arxiv.org/abs/2406.19954 BESTOW : Efficient and Streamable Speech Language Model with the Best of Two Worlds in GPT and T5 . In Proc. SLT
-
[7]
Alexandre D \'e fossez, Laurent Mazar \'e , Manu Orsini, Am \'e lie Royer, Patrick P \'e rez, Herv \'e J \'e gou, Edouard Grave, and Neil Zeghidour. 2024. https://arxiv.org/abs/2410.00037 Moshi: A Speech-Text Foundation Model for Real-Time Dialogue https://arxiv.org/abs/2410.00037 . Preprint, arXiv:2410.00037
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Alex Graves, Abdel rahman Mohamed, and Geoffrey Hinton. 2013. Speech Recognition with Deep Recurrent Neural Networks https://arxiv.org/abs/1303.5778. In Proc. ICASSP
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [11]
- [12]
-
[13]
François Hernandez, Vincent Nguyen, Sahar Ghannay, Natalia Tomashenko, and Yannick Estève. 2018. https://arxiv.org/abs/1805.04699 TED-LIUM 3: Twice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation . In Proc. SPECOM
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://arxiv.org/abs/2106.09685 LoRA : Low-Rank Adaptation of Large Language Models . In Proc. ICLR
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Nithin Rao Koluguri, Monica Sekoyan, Ante Jukić, Somshubra Majumdar, Vitaly Lavrukhin, Jagadeesh Balam, and Boris Ginsburg. 2025 a . https://arxiv.org/abs/2509.14128 https://arxiv.org/abs/2509.14128 Canary-1B-v2 & Parakeet- TDT -0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST . Preprint, arXiv:2509.14128
-
[16]
Nithin Rao Koluguri, Monica Sekoyan, Gilad Zelenfroynd, Slava Meister, Shangshang Ding, Sergei Kostandian, He Huang, Nikolay Karpov, Jagadeesh Balam, Vitaly Lavrukhin, Yi Peng, Sara Papi, Marco Gaido, Adriano Brutti, and Boris Ginsburg. 2025 b . https://arxiv.org/abs/2505.13404 Granary: Speech Recognition and Translation Dataset in 25 European Languages h...
- [17]
- [18]
-
[19]
Egor Lakomkin, Chunyang Wu, Yassir Fathullah, Ozlem Kalinli, Michael L. Seltzer, and Christian Fuegen. 2024. End-to-End Speech Recognition Contextualization with Large Language Models https://arxiv.org/abs/2309.10917. In Proc. ICASSP, pages 12406--12410
-
[20]
Dan Liu, Mengge Du, Xiaoxi Li, Ya Li, and Enhong Chen. 2021. Cross Attention Augmented Transducer Networks for Simultaneous Translation https://aclanthology.org/2021.emnlp-main.4. In Proc. EMNLP
2021
-
[21]
Mingbo Ma, Liang Huang, Hao Xiong, Renjie Zheng, Kaibo Liu, Baigong Zheng, Chuanqiang Zhang, Zhongjun He, Hairong Liu, Xing Li, Hua Wu, and Haifeng Wang. 2019. https://aclanthology.org/P19-1289 STACL : Simultaneous Translation with Implicit Anticipation and Controllable Latency using Prefix-to-Prefix Framework . In Proc. ACL
2019
-
[22]
Xutai Ma, Juan Pino, James Cross, Liezl Puzon, and Jiatao Gu. 2020 a . Monotonic multihead attention. In ICLR
2020
-
[23]
Di Gangi, Sara Papi, Luisa Bentivogli, Marcello Federico, and Philipp Koehn
Xutai Ma, Mohammad Javad Salameh, Ljiljana Majstorovic, Elena Meylan, Roldano Cattoni, Mattia A. Di Gangi, Sara Papi, Luisa Bentivogli, Marcello Federico, and Philipp Koehn. 2020 b . https://aclanthology.org/2020.emnlp-demos.19 SimulEval : An Evaluation Toolkit for Simultaneous Translation . In Proc. EMNLP (Demo)
2020
-
[24]
Ziyang Ma, Guanrou Yang, Yifan Yang, Zhifu Gao, Jiaming Wang, Zhihao Du, Fan Yu, Qian Chen, Siqi Zheng, Shiliang Zhang, and Xie Chen. 2024. https://arxiv.org/abs/2402.08846 https://arxiv.org/abs/2402.08846 An Embarrassingly Simple Approach for LLM with Strong ASR Capacity . Preprint, arXiv:2402.08846
-
[25]
Iain McCowan, Jean Carletta, Wessel Kraaij, Simone Ashby, Samuel Bourban, Mike Flynn, Mael Guillemot, Thomas Hain, Jaroslav Kadlec, Vasilis Karaiskos, and 1 others. 2005. The AMI meeting corpus. In Proc. International Conference on Methods and Techniques in Behavioral Research
2005
-
[26]
Takafumi Moriya, Masato Mimura, Tomohiro Tanaka, Hiroshi Sato, Ryo Masumura, and Atsunori Ogawa. 2024. https://arxiv.org/abs/2512.11543 https://arxiv.org/abs/2512.11543 All-in-One ASR : Unifying Encoder-Decoder Models of CTC , attention, and transducer in dual-mode ASR . Preprint, arXiv:2512.11543
-
[27]
Spirit LM: Interleaved spoken and written language model,
Tu Anh Nguyen, Benjamin Muller, Bokai Yu, Marta R. Costa-juss \`a , Maha Elbayad, Sravya Popuri, Paul-Ambroise Duquenne, Robin Algayres, Ruslan Mavlyutov, Itai Gat, Gabriel Synnaeve, Juan Pino, Benoit Sagot, and Emmanuel Dupoux. 2025. https://arxiv.org/abs/2402.05755 SpiRit-LM : Interleaved Spoken and Written Language Model . Transactions of the Associati...
-
[28]
Patrick K. O'Neill, Vitaly Lavrukhin, Somshubra Majumdar, Vahid Noroozi, Yuekai Zhang, Oleksii Kuchaiev, Jagadeesh Balam, Yuliya Dovzhenko, Keenan Freyberg, Nathaniel Macedo, and 1 others. 2021. https://arxiv.org/abs/2104.02014 https://arxiv.org/abs/2104.02014 SPGI Speech: 5,000 Hours of Transcribed Financial Audio for Fully Formatted End-to-End Speech Re...
-
[29]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. LibriSpeech : An ASR corpus based on public domain audio books. In Proc. ICASSP
2015
-
[30]
Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D
Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, and Quoc V. Le. 2019. https://arxiv.org/abs/1904.08779 SpecAugment : A Simple Data Augmentation Method for Automatic Speech Recognition . In Proc. Interspeech
-
[31]
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. https://arxiv.org/abs/2012.03411 MLS : A Large-Scale Multilingual Dataset for Speech Research . In Proc. Interspeech
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Supervision https://arxiv.org/abs/2212.04356. In Proc. ICML
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [33]
-
[34]
Miguel Del Rio, Natalie Delworth, Ryan Westerman, Michelle Liu, Nishchal Bhandari, Joseph Palakapilly, Quinten McNamara, Joshua Dong, Piotr Zelasko, and Miguel Jett \' e . 2022. https://arxiv.org/abs/2203.15591 Earnings-22: A Practical Benchmark for Accents in the Wild https://arxiv.org/abs/2203.15591 . Preprint, arXiv:2203.15591
- [35]
- [36]
-
[37]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural Machine Translation of Rare Words with Subword Units https://arxiv.org/abs/1508.07909. In Proc. ACL
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Silero Team . 2021. https://github.com/snakers4/silero-vad Silero VAD : Pre-trained Enterprise-Grade Voice Activity Detector . https://github.com/snakers4/silero-vad
2021
-
[39]
Vaibhav Srivastav, Steven Zheng, Eric Bezzam, Eustache Le Bihan , Nithin Rao Koluguri, Piotr \.Z elasko, Somshubra Majumdar, Adel Moumen, and Sanchit Gandhi. 2025. https://arxiv.org/abs/2510.06961 https://arxiv.org/abs/2510.06961 Open ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation . Preprint,...
-
[40]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. https://arxiv.org/abs/2310.13289 SALMONN : Towards Generic Hearing Abilities for Large Language Models . In Proc. ICLR
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [41]
- [42]
-
[44]
Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux. 2021. https://doi.org/10.18653/v1/2021.acl-long.80 https://aclanthology.org/2021.acl-long.80/ VoxPopuli : A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation . I...
-
[45]
Mingqiu Wang, Wei Han, Izhak Shafran, Zelin Wu, Chung-Cheng Chiu, Yuan Cao, Yongqiang Wang, Nanxin Chen, Yu Zhang, Hagen Soltau, Paul K. Rubenstein, Lukas Zilka, Dian Yu, Zhong Meng, Golan Pundak, Nikhil Siddhartha, Johan Schalkwyk, and Yonghui Wu. 2023. https://arxiv.org/abs/2310.00230 SLM : Bridge the Thin Gap Between Speech and Text Foundation Models ....
-
[46]
Shinji Watanabe, Takaaki Hori, Suyoun Kim, John R. Hershey, and Tomoki Hayashi. 2017. https://doi.org/10.1109/JSTSP.2017.2763455 https://doi.org/10.1109/JSTSP.2017.2763455 Hybrid CTC/Attention Architecture for End-to-End Speech Recognition . IEEE Journal of Selected Topics in Signal Processing , 11(8):1240--1253
-
[47]
Akmal Haidar, Nicola Ferri, Jes'us Andr'es-Ferrer, and Puming Zhan
Felix Weninger, Marco Gaudesi, Md. Akmal Haidar, Nicola Ferri, Jes'us Andr'es-Ferrer, and Puming Zhan. 2022. Conformer with dual-mode chunked attention for joint online and offline asr. In Interspeech
2022
- [48]
-
[49]
Yu, Chao Yang, Liyong Guo, Yaguang Hu, Lei Xie, and Xin Lei
Binbin Zhang, Di Wu, Zhuoyuan Yao, Xiong Wang, F. Yu, Chao Yang, Liyong Guo, Yaguang Hu, Lei Xie, and Xin Lei. 2020. Unified streaming and non-streaming two-pass end-to-end model for speech recognition. ArXiv, abs/2012.05481
-
[50]
Alex Graves and Abdel-rahman Mohamed and Geoffrey Hinton , title =. Proc. ICASSP , year =
-
[51]
Fangjun Kuang and Liyong Guo and Wei Kang and Long Lin and Mingshuang Luo and Zengwei Yao and Daniel Povey , title =. Proc. Interspeech , year =
-
[52]
Qian Zhang and Han Lu and Hasim Sak and Anshuman Tripathi and Erik McDermott and Khe Chai Sim and Shankar Kumar , title =. Proc. ICASSP , year =
-
[53]
Faris Khalil Botros and Thibault de Boissiere and Ha Nguyen and Imran Sheikh , title =. Proc. Interspeech , year =
-
[54]
2023 , eprint =
Hainan Xu and Fangjun Kuang and Liyong Guo and Yifan Yang and Long Lin and Hao Wen and Hao Yao and Daniel Povey , title =. 2023 , eprint =
2023
-
[55]
Anmol Gulati and James Qin and Chung-Cheng Chiu and Niki Parmar and Yu Zhang and Jiahui Yu and Wei Han and Shibo Wang and Zhengdong Zhang and Yonghui Wu and Ruoming Pang , title =. Proc. Interspeech , year =
-
[56]
Park and William Chan and Yu Zhang and Chung-Cheng Chiu and Barret Zoph and Ekin D
Daniel S. Park and William Chan and Yu Zhang and Chung-Cheng Chiu and Barret Zoph and Ekin D. Cubuk and Quoc V. Le , title =. Proc. Interspeech , year =
-
[57]
Hershey and Tomoki Hayashi , title =
Shinji Watanabe and Takaaki Hori and Suyoun Kim and John R. Hershey and Tomoki Hayashi , title =. 2017 , doi =
2017
-
[58]
Yun Tang and Anna Sun and Hirofumi Inaguma and Xinyue Chen and Ning Dong and Xutai Ma and Paden Tomasello and Juan Pino , title =. Proc. ACL , year =
-
[59]
Dan Liu and Mengge Du and Xiaoxi Li and Ya Li and Enhong Chen , title =. Proc. EMNLP , year =
-
[60]
arXiv preprint arXiv:2509.15579 , year =
Yun Tang and Cindy Tseng , title =. arXiv preprint arXiv:2509.15579 , year =
-
[61]
Yun Tang and Eesung Kim and Vijendra Raj Apsingekar , title =. Proc. Interspeech , year =
-
[62]
Alec Radford and Jong Wook Kim and Tao Xu and Greg Brockman and Christine McLeavey and Ilya Sutskever , title =. Proc. ICML , year =
-
[63]
Vassil Panayotov and Guoguo Chen and Daniel Povey and Sanjeev Khudanpur , title =. Proc. ICASSP , year =
-
[64]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. Proc. ICLR , year =
-
[65]
Junnan Li and Dongxu Li and Silvio Savarese and Steven Hoi , title =. Proc. ICML , year =
-
[66]
2015 , eprint =
Caglar Gulcehre and Orhan Firat and Kelvin Xu and Kyunghyun Cho and Loic Barrault and Huei-Chi Lin and Fethi Bougares and Holger Schwenk and Yoshua Bengio , title =. 2015 , eprint =
2015
-
[67]
Changli Tang and Wenyi Yu and Guangzhi Sun and Xianzhao Chen and Tian Tan and Wei Li and Lu Lu and Zejun Ma and Chao Zhang , title =. Proc. ICLR , year =
-
[68]
2023 , eprint =
Yunfei Chu and Jin Xu and Xiaohuan Zhou and Qian Yang and Shiliang Zhang and Zhijie Yan and Chang Zhou and Jingren Zhou , title =. 2023 , eprint =
2023
-
[69]
Rubenstein and Chulayuth Asawaroengchai and Duc Dung Nguyen and Ankur Bapna and Zal
Paul K. Rubenstein and Chulayuth Asawaroengchai and Duc Dung Nguyen and Ankur Bapna and Zal. 2023 , eprint =
2023
-
[70]
2024 , eprint =
Shengpeng Ji and Chaofan Tian and Minghui Fang and Jialong Zuo and Jiawei Chen and Zhengqi Wen and Baolong Bi and Zu-Yu Kan and Tao Jin and Zhou Zhao , title =. 2024 , eprint =
2024
-
[71]
Soham Deshmukh and Benjamin Elizalde and Rita Singh and Huaming Wang , title =. Proc. NeurIPS , year =
-
[72]
Jan Chorowski and Dzmitry Bahdanau and Dmitriy Serdyuk and Kyunghyun Cho and Yoshua Bengio , title =. Proc. NeurIPS , year =
-
[73]
Le and Oriol Vinyals , title =
William Chan and Navdeep Jaitly and Quoc V. Le and Oriol Vinyals , title =. Proc. ICASSP , year =
-
[74]
2025 , eprint =
Vaibhav Srivastav and Steven Zheng and Eric Bezzam and Eustache. 2025 , eprint =
2025
-
[75]
2024 , eprint =
Ziyang Ma and Guanrou Yang and Yifan Yang and Zhifu Gao and Jiaming Wang and Zhihao Du and Fan Yu and Qian Chen and Siqi Zheng and Shiliang Zhang and Xie Chen , title =. 2024 , eprint =
2024
-
[76]
Rubenstein and Lukas Zilka and Dian Yu and Zhong Meng and Golan Pundak and Nikhil Siddhartha and Johan Schalkwyk and Yonghui Wu , title =
Mingqiu Wang and Wei Han and Izhak Shafran and Zelin Wu and Chung-Cheng Chiu and Yuan Cao and Yongqiang Wang and Nanxin Chen and Yu Zhang and Hagen Soltau and Paul K. Rubenstein and Lukas Zilka and Dian Yu and Zhong Meng and Golan Pundak and Nikhil Siddhartha and Johan Schalkwyk and Yonghui Wu , title =. Proc. ASRU , year =
-
[77]
Puvvada and Jason Li and Subhankar Ghosh and Jagadeesh Balam and Boris Ginsburg , title =
Zhehuai Chen and He Huang and Andrei Andrusenko and Oleksii Hrinchuk and Krishna C. Puvvada and Jason Li and Subhankar Ghosh and Jagadeesh Balam and Boris Ginsburg , title =. Proc. ICASSP , year =
-
[78]
Wenyi Yu and Changli Tang and Guangzhi Sun and Xianzhao Chen and Tian Tan and Wei Li and Lu Lu and Zejun Ma and Chao Zhang , title =. Proc. ICASSP , year =
-
[79]
2024 , eprint =
Ye Bai and Jingping Chen and Jitong Chen and others , title =. 2024 , eprint =
2024
-
[80]
Francesco Verdini and Danni Liu and Jan Niehues and Marco Gaido and Luisa Bentivogli , title =. Proc. Interspeech , year =
-
[81]
Tsz Kin Lam and Marco Gaido and Sara Papi and Luisa Bentivogli and Barry Haddow , title =. Proc. NAACL , year =
-
[82]
Dominik Wagner and Alexander Churchill and Siddharth Sigtia and Erik Marchi , title =. Proc. ICASSP , year =
-
[83]
Ankit Gupta and George Saon and Brian Kingsbury , title =. Proc. Interspeech , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.