Towards Accurate Emotion-Attributed Video Captioning via Fine-grained Emotion-Cause Pair Extraction
Pith reviewed 2026-06-27 18:52 UTC · model grok-4.3
The pith
Extracting emotion-cause pairs from core video segments yields more accurate emotional captions than using overall video features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
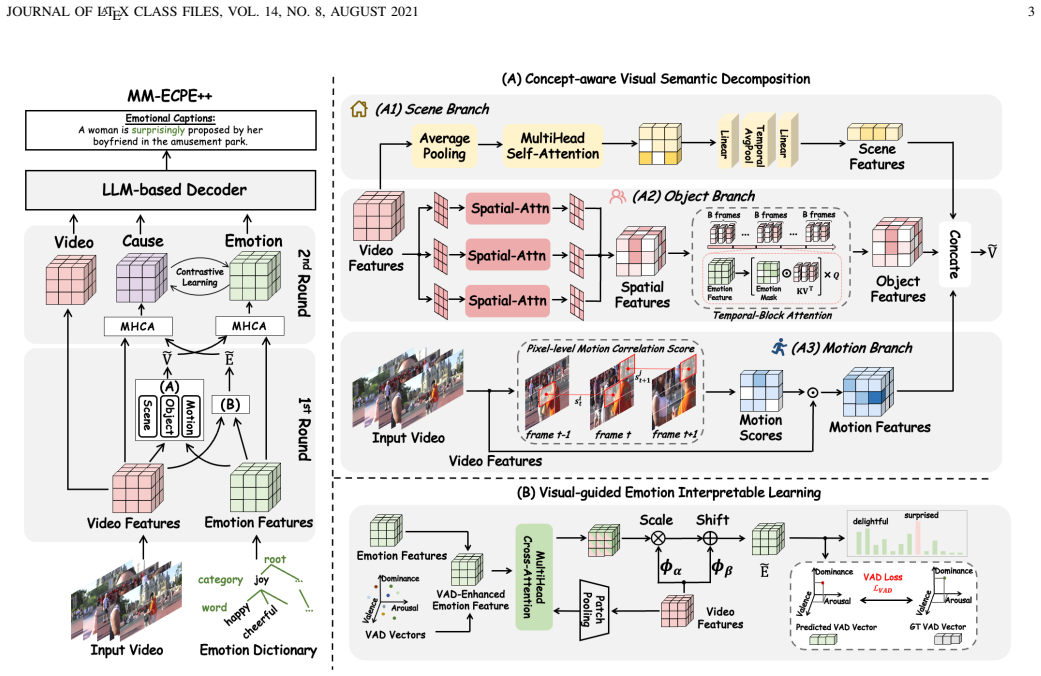
A two-round fine-grained emotion-cause pair extraction process, built from a Concept-aware Visual Semantic Decomposition module and a Visual-guided Emotion Interpretable Learning module, followed by cross-coupling of pre- and post-refinement features with contrastive alignment, produces superior emotion-attributed video captions by reducing information redundancy and sharpening emotional cues.
What carries the argument
The fine-grained emotion-cause pair extraction framework that performs concept decomposition, visual-guided emotion refinement, and cross-coupling with contrastive loss to align cause and emotion features.
If this is right
- Captions gain both factual accuracy and emotional richness because redundant visual signals are filtered out before generation.
- Emotion perception becomes more interpretable through the explicit pairing of causes with refined emotion vectors.
- Performance gains appear on multiple emotional video captioning benchmarks when the full pipeline is used.
- Each added module (decomposition, guided refinement, contrastive alignment) contributes measurable improvement in isolation.
Where Pith is reading between the lines
- The same localized cause-extraction step could be tested on tasks that require grounding emotions to actions, such as affective dialogue generation from video.
- If core segments can be identified without full supervision, the approach might scale to longer untrimmed videos where global features become even noisier.
- The VAD-vector constraint used for refinement suggests a route to incorporate psychological priors into other multimodal emotion models.
Load-bearing premise
Visual emotions are evoked by specific motivational causes that appear only inside limited core segments of a video.
What would settle it
An experiment on the EVC-MSVD dataset in which removing the pair-extraction stage produces no drop or an increase in BLEU-2 and ROUGE-L scores.
Figures




read the original abstract
Emotional Video Captioning (EVC) is a challenging task that aims to generate factually accurate and emotionally rich descriptions for videos. Existing EVC methods leverage holistic visual features to mine global emotional cues, and then aggregate multimodal features to guide the emotional caption generation, which ignores the critical characteristic of the EVC task. Visual emotions are evoked by specific motivational causes, which are usually only implied in core video segments. The holistic mining brings significant information redundancy and inaccurate emotional cues. Thus, fine-grained visual cause extraction has a facilitative effect on both emotion perception and emotion-attributed caption generation. To this end, we propose a fine-grained emotion-cause pair extraction framework for emotion-attributed video captioning. Specifically, we learn pair-wise emotion and cause features in two rounds: 1) We propose a Concept-aware Visual Semantic Decomposition module to augment visual features by exploring scene, object, and motion concepts. Besides, to enhance emotional features, we propose a Visual-guided Emotion Interpretable Learning module, which guides emotion refinement with visual temporal dynamics, and augments the interpretable refinement process by reliable VAD-vector constraints. 2) We achieve emotion-cause pair extraction by cross-coupling the visual and emotional features before and after refinement, and leverage contrastive loss to achieve semantic forced alignment. Overall, our approach optimizes complex semantic understanding and emotion perception of videos, leading to a promising performance in emotional captioning. Extensive experiments on three challenging datasets demonstrate the superiority of our approach and each proposed module, e.g., achieving the best performances with +4.4% and +5.4% w.r.t. BLEU-2 and ROUGE-L, respectively, on the EVC-MSVD dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fine-grained emotion-cause pair extraction framework for emotion-attributed video captioning (EVC). It introduces a Concept-aware Visual Semantic Decomposition module to augment visual features using scene, object, and motion concepts, and a Visual-guided Emotion Interpretable Learning module that refines emotional features via visual temporal dynamics and VAD-vector constraints. Emotion-cause pairs are extracted through cross-coupling of visual and emotional features with contrastive alignment. The approach is claimed to reduce redundancy from holistic mining of emotional cues in videos and is evaluated on three datasets, reporting gains such as +4.4% BLEU-2 and +5.4% ROUGE-L on EVC-MSVD.
Significance. If the empirical results hold after proper validation, the work could contribute to EVC by shifting from holistic to cause-specific emotion modeling, potentially improving caption accuracy and interpretability through VAD constraints and contrastive alignment. The modular design allows testing of individual components, which is a positive aspect if ablations are provided.
major comments (3)
- [Abstract] Abstract: The central claim that 'holistic mining brings significant information redundancy and inaccurate emotional cues' and that 'fine-grained visual cause extraction has a facilitative effect' is load-bearing for the proposed two-round pair extraction, yet the abstract provides no ablation isolating the pair-extraction step from the Concept-aware Visual Semantic Decomposition or Visual-guided Emotion Interpretable Learning modules. Without such isolation, it is unclear whether the reported +4.4% BLEU-2 gain arises from the core premise or from the added concept/VAD components.
- [Abstract] Abstract (paragraph 2) and method description: The pipeline is described as operating via cross-coupling on features 'before and after refinement' without an explicit mechanism (e.g., masking or localization) to identify or restrict processing to 'core video segments.' This leaves the redundancy-reduction assumption untested against a holistic baseline that uses the same decomposition and VAD modules.
- [Abstract] Abstract (final sentence): Performance claims are stated without reference to specific baselines, number of runs, error bars, or statistical tests. The assertion of 'best performances' and 'superiority of our approach and each proposed module' cannot be evaluated for robustness without these details in the experimental section.
minor comments (1)
- [Abstract] Abstract: The phrase 'two rounds' is used for the learning process but the description lists the modules sequentially without clarifying whether the rounds are iterative or sequential passes over the same features.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's clarity and the need for stronger isolation of contributions. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'holistic mining brings significant information redundancy and inaccurate emotional cues' and that 'fine-grained visual cause extraction has a facilitative effect' is load-bearing for the proposed two-round pair extraction, yet the abstract provides no ablation isolating the pair-extraction step from the Concept-aware Visual Semantic Decomposition or Visual-guided Emotion Interpretable Learning modules. Without such isolation, it is unclear whether the reported +4.4% BLEU-2 gain arises from the core premise or from the added concept/VAD components.
Authors: The full manuscript includes module ablations in Section 4.3 (Tables 3-4) that isolate the pair-extraction step via cross-coupling and contrastive alignment from the decomposition and VAD modules. To address the abstract's omission, we will revise it to explicitly reference these ablation results demonstrating the incremental benefit of the pair-extraction component. revision: yes
-
Referee: [Abstract] Abstract (paragraph 2) and method description: The pipeline is described as operating via cross-coupling on features 'before and after refinement' without an explicit mechanism (e.g., masking or localization) to identify or restrict processing to 'core video segments.' This leaves the redundancy-reduction assumption untested against a holistic baseline that uses the same decomposition and VAD modules.
Authors: The refinement process uses visual temporal dynamics to emphasize cause-relevant segments implicitly, with cross-coupling then aligning refined pairs. We agree an explicit masking mechanism is not detailed. We will revise the method section to clarify this implicit focus and add an ablation comparing against a holistic baseline that retains the same decomposition and VAD modules. revision: partial
-
Referee: [Abstract] Abstract (final sentence): Performance claims are stated without reference to specific baselines, number of runs, error bars, or statistical tests. The assertion of 'best performances' and 'superiority of our approach and each proposed module' cannot be evaluated for robustness without these details in the experimental section.
Authors: The experimental section reports results against multiple baselines across three datasets. We will revise the abstract to name the primary baselines and ensure the experimental section includes the number of runs, error bars, and statistical tests (e.g., t-tests) for the reported gains. revision: yes
Circularity Check
No significant circularity in the proposed framework
full rationale
The paper proposes a new fine-grained emotion-cause pair extraction framework consisting of Concept-aware Visual Semantic Decomposition, Visual-guided Emotion Interpretable Learning, and cross-coupling with contrastive alignment for emotion-attributed video captioning. No equations, derivations, or parameter-fitting steps are described that reduce to self-definition or fitted inputs called predictions. The motivating assumption about holistic mining introducing redundancy is stated as a premise but does not create a circular reduction in any load-bearing step. Empirical results on EVC-MSVD and other datasets are reported as independent validation. No self-citation chains or uniqueness theorems are invoked as load-bearing. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mdkat: Multimodal decoupling with knowledge aggregation and transfer for video emotion recognition,
J. Wang, C. Wang, L. Guo, S. Zhao, D. Wang, S. Zhang, X. Zhao, J. Yu, Y . Wang, Y . Yanget al., “Mdkat: Multimodal decoupling with knowledge aggregation and transfer for video emotion recognition,” IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[2]
Feature evaluation and joint interaction for audio-visual emotion recognition,
S. Li, C. Lu, Y . Zong, H. Lian, and W. Zheng, “Feature evaluation and joint interaction for audio-visual emotion recognition,”IEEE Transac- tions on Circuits and Systems for Video Technology, 2025
2025
-
[3]
Glove: Global vectors for word representation,
J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” inProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543
2014
-
[4]
Weakly supervised text-based actor-action video segmentation by clip-level multi-instance learning,
W. Chen, G. Li, X. Zhang, S. Wang, L. Li, and Q. Huang, “Weakly supervised text-based actor-action video segmentation by clip-level multi-instance learning,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 1, pp. 1–22, 2023
2023
-
[5]
Graph mixture of experts and memory-augmented routers for multivariate time series anomaly detec- tion,
X. Huang, W. Chen, B. Hu, and Z. Mao, “Graph mixture of experts and memory-augmented routers for multivariate time series anomaly detec- tion,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 16, 2025, pp. 17 476–17 484
2025
-
[6]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Ecpec: Emotion-cause pair extraction in conversations,
W. Li, Y . Li, V . Pandelea, M. Ge, L. Zhu, and E. Cambria, “Ecpec: Emotion-cause pair extraction in conversations,”IEEE Transactions on Affective Computing, vol. 14, no. 3, pp. 1754–1765, 2022
2022
-
[8]
Multi- round mutual emotion-cause pair extraction for emotion-attributed video captioning,
C. Ye, W. Chen, P. Song, X. Liu, L. Zhang, and Z. Mao, “Multi- round mutual emotion-cause pair extraction for emotion-attributed video captioning,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3320–3329
2025
-
[9]
Global-view and speaker-aware emotion cause extraction in conversations,
J. An, Z. Ding, K. Li, and R. Xia, “Global-view and speaker-aware emotion cause extraction in conversations,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 3814–3823, 2023
2023
-
[10]
Multimodal emotion- cause pair extraction with holistic interaction and label constraint,
B. Li, H. Fei, F. Li, T.-s. Chua, and D. Ji, “Multimodal emotion- cause pair extraction with holistic interaction and label constraint,” ACM Transactions on Multimedia Computing, Communications and Applications, 2024
2024
-
[11]
Reconstruction network for video captioning,
B. Wang, L. Ma, W. Zhang, and W. Liu, “Reconstruction network for video captioning,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7622–7631
2018
-
[12]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Enhancing emotion-cause pair extraction in conversations via center event detection and reasoning,
B. Wang, K. Tang, and P. Zhu, “Enhancing emotion-cause pair extraction in conversations via center event detection and reasoning,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 10 773–10 783
2024
-
[14]
Prompting video-language foundation models with domain-specific fine-grained heuristics for video question answering,
T. Yu, K. Fu, S. Wang, Q. Huang, and J. Yu, “Prompting video-language foundation models with domain-specific fine-grained heuristics for video question answering,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 2, pp. 1615–1630, 2024
2024
-
[15]
Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,” inProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
2005
-
[16]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”
-
[17]
LoRA: Low-Rank Adaptation of Large Language Models
[Online]. Available: https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[19]
Learning probabilistic presence-absence evidence for weakly-supervised audio-visual event perception,
J. Gao, M. Chen, and C. Xu, “Learning probabilistic presence-absence evidence for weakly-supervised audio-visual event perception,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[20]
Expllm: Towards chain of thought for facial expression recognition,
X. Lan, J. Xue, J. Qi, D. Jiang, K. Lu, and T.-S. Chua, “Expllm: Towards chain of thought for facial expression recognition,”IEEE Transactions on Multimedia, 2025
2025
-
[21]
Benchmarking micro- action recognition: Dataset, method, and application,
D. Guo, K. Li, B. Hu, Y . Zhang, and M. Wang, “Benchmarking micro- action recognition: Dataset, method, and application,”IEEE Transac- tions on Circuits and Systems for Video Technology, 2024
2024
-
[22]
Contextual attention network for emotional video captioning,
P. Song, D. Guo, J. Cheng, and M. Wang, “Contextual attention network for emotional video captioning,”IEEE Transactions on Multimedia, 2022
2022
-
[23]
Observe before generate: Emotion-cause aware video caption for multimodal emotion cause gen- eration in conversations,
F. Wang, H. Ma, X. Shen, J. Yu, and R. Xia, “Observe before generate: Emotion-cause aware video caption for multimodal emotion cause gen- eration in conversations,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 5820–5828
2024
-
[24]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[25]
Cross-modal coherence-enhanced feedback prompting for news captioning,
N. Xu, Y . Gao, T.-T. Zhang, H. Tian, and A.-A. Liu, “Cross-modal coherence-enhanced feedback prompting for news captioning,” inPro- ceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 9369–9377
2024
-
[26]
Cider: Consensus- based image description evaluation,
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus- based image description evaluation,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2015, pp. 4566–4575
2015
-
[27]
Semantic grouping network for video captioning,
H. Ryu, S. Kang, H. Kang, and C. D. Yoo, “Semantic grouping network for video captioning,” inproceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2514–2522
2021
-
[28]
Rule-driven news captioning,
N. Xu, T. Zhang, H. Tian, and A.-A. Liu, “Rule-driven news captioning,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[29]
Eliciting in-context learning in vision-language models for videos through curated data distributional properties,
K. Yu, Z. Zhang, F. Hu, S. Storks, and J. Chai, “Eliciting in-context learning in vision-language models for videos through curated data distributional properties,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 20 416– 20 431
2024
-
[30]
A versatile multimodal learning framework for zero-shot emotion recognition,
F. Qi, H. Zhang, X. Yang, and C. Xu, “A versatile multimodal learning framework for zero-shot emotion recognition,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 5728– 5741, 2024
2024
-
[31]
Cascade cross-modal attention network for video actor and action segmentation from a sentence,
W. Chen, G. Li, X. Zhang, H. Yu, S. Wang, and Q. Huang, “Cascade cross-modal attention network for video actor and action segmentation from a sentence,” inProceedings of the 29th ACM International Con- ference on Multimedia, 2021, pp. 4053–4062
2021
-
[32]
Emotion-cause pair extraction: A new task to emotion analysis in texts,
R. Xia and Z. Ding, “Emotion-cause pair extraction: A new task to emotion analysis in texts,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 1003–1012
2019
-
[33]
Collecting highly parallel data for paraphrase evaluation,
D. Chen and W. B. Dolan, “Collecting highly parallel data for paraphrase evaluation,” inProceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, 2011, pp. 190–200
2011
-
[34]
From coarse to fine: A distillation method for fine-grained emotion-causal span pair extraction in conversation,
X. Chen, C. Yang, C. Sun, M. Lan, and A. Zhou, “From coarse to fine: A distillation method for fine-grained emotion-causal span pair extraction in conversation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 790–17 798. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2024
-
[35]
From extraction to generation: multimodal emotion-cause pair generation in conversations,
H. Ma, J. Yu, F. Wang, H. Cao, and R. Xia, “From extraction to generation: multimodal emotion-cause pair generation in conversations,” IEEE Transactions on Affective Computing, 2024
2024
-
[36]
Improving image captioning via predicting structured concepts,
T. Wang, W. Chen, Y . Tian, Y . Song, and Z. Mao, “Improving image captioning via predicting structured concepts,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, 2023, pp. 360–370
2023
-
[37]
Bootstrapping large language models for radiology report generation,
C. Liu, Y . Tian, W. Chen, Y . Song, and Y . Zhang, “Bootstrapping large language models for radiology report generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 18 635–18 643
2024
-
[38]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y . Yuan, G. Chen, S. Leng, Y . Jiang, H. Zhang, X. Liet al., “Videollama 3: Frontier multimodal foundation models for image and video understanding,”arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Improving radiology report generation with d 2-net: When diffusion meets dis- criminator,
Y . Jin, W. Chen, Y . Tian, Y . Song, C. Yan, and Z. Mao, “Improving radiology report generation with d 2-net: When diffusion meets dis- criminator,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 2215–2219
2024
-
[40]
Improving radiology report generation with multi-grained abnormality prediction,
Y . Jin, W. Chen, Y . Tian, Y . Song, and C. Yan, “Improving radiology report generation with multi-grained abnormality prediction,”Neurocom- puting, vol. 600, p. 128122, 2024
2024
-
[41]
Enriched image cap- tioning based on knowledge divergence and focus,
A.-A. Liu, Q. Wu, N. Xu, H. Tian, and L. Wang, “Enriched image cap- tioning based on knowledge divergence and focus,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[42]
Emotional video captioning with vision-based emotion interpretation network,
P. Song, D. Guo, X. Yang, S. Tang, and M. Wang, “Emotional video captioning with vision-based emotion interpretation network,”IEEE Transactions on Image Processing, 2024
2024
-
[43]
Emotion- prior awareness network for emotional video captioning,
P. Song, D. Guo, X. Yang, S. Tang, E. Yang, and M. Wang, “Emotion- prior awareness network for emotional video captioning,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 589–600
2023
-
[44]
Combatting data imbalance and noise in micro-action recognition,
C. Wang, W. Chen, X. Cui, Y . Zhao, Z. Qi, P. Huang, X. Liu, and W. Zhang, “Combatting data imbalance and noise in micro-action recognition,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 14 229–14 235
2025
-
[45]
Eliciting in-context learning in vision-language models for videos through curated data distributional properties,
K. Yu, Z. Zhang, F. Hu, S. Storks, and J. Chai, “Eliciting in-context learning in vision-language models for videos through curated data distributional properties,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Li...
2024
-
[46]
Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 english words,
S. Mohammad, “Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 english words,” inProceedings of the 56th annual meeting of the association for computational linguistics (volume 1: Long papers), 2018, pp. 174–184
2018
-
[47]
Linguistic-aware patch slimming framework for fine-grained cross-modal alignment,
Z. Fu, L. Zhang, H. Xia, and Z. Mao, “Linguistic-aware patch slimming framework for fine-grained cross-modal alignment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 307–26 316
2024
-
[48]
Emotion-oriented cross-modal prompting and alignment for human- centric emotional video captioning,
Y . Wang, Y . Liu, S. Zhou, Y . Huang, C. Tang, W. Zhou, and Z. Chen, “Emotion-oriented cross-modal prompting and alignment for human- centric emotional video captioning,”IEEE Transactions on Multimedia, 2025
2025
-
[49]
Dual-path collaborative generation network for emotional video captioning,
C. Ye, W. Chen, J. Li, L. Zhang, and Z. Mao, “Dual-path collaborative generation network for emotional video captioning,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, p. 496–505
2024
-
[50]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[51]
A knowledge-guided graph attention network for emotion-cause pair ex- traction,
P. Zhu, B. Wang, K. Tang, H. Zhang, X. Cui, and Z. Wang, “A knowledge-guided graph attention network for emotion-cause pair ex- traction,”Knowledge-Based Systems, vol. 286, p. 111342, 2024
2024
-
[52]
A comprehen- sive survey of 3d dense captioning: Localizing and describing objects in 3d scenes,
T. Yu, X. Lin, S. Wang, W. Sheng, Q. Huang, and J. Yu, “A comprehen- sive survey of 3d dense captioning: Localizing and describing objects in 3d scenes,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 3, pp. 1322–1338, 2023
2023
-
[53]
Predicting emotions in user-generated videos,
Y .-G. Jiang, B. Xu, and X. Xue, “Predicting emotions in user-generated videos,” inProceedings of the AAAI conference on artificial intelligence, vol. 28, no. 1, 2014
2014
-
[54]
Multi-attention network for compressed video referring object segmentation,
W. Chen, D. Hong, Y . Qi, Z. Han, S. Wang, L. Qing, Q. Huang, and G. Li, “Multi-attention network for compressed video referring object segmentation,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 4416–4425
2022
-
[55]
Towards efficient partially relevant video retrieval with active moment discovering,
P. Song, L. Zhang, L. Lan, W. Chen, D. Guo, X. Yang, and M. Wang, “Towards efficient partially relevant video retrieval with active moment discovering,”IEEE Transactions on Multimedia, 2025
2025
-
[56]
Vectorized evidential learning for weakly- supervised temporal action localization,
J. Gao, M. Chen, and C. Xu, “Vectorized evidential learning for weakly- supervised temporal action localization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 15 949 – 15 963, 2023
2023
-
[57]
Sentiment-oriented transformer- based variational autoencoder network for live video commenting,
F. Fu, S. Fang, W. Chen, and Z. Mao, “Sentiment-oriented transformer- based variational autoencoder network for live video commenting,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 20, no. 4, pp. 1–24, 2024
2024
-
[58]
Prompting few-shot multi- hop question generation via comprehending type-aware semantics,
Z. Lin, W. Chen, Y . Song, and Y . Zhang, “Prompting few-shot multi- hop question generation via comprehending type-aware semantics,” in Findings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 3730–3740
2024
-
[59]
Affectnet+: A database for enhancing facial expression recognition with soft-labels,
A. P. Fard, M. M. Hosseini, T. D. Sweeny, and M. H. Mahoor, “Affectnet+: A database for enhancing facial expression recognition with soft-labels,”IEEE Transactions on Affective Computing, 2025
2025
-
[60]
Emotion expression with fact transfer for video description,
H. Wang, P. Tang, Q. Li, and M. Cheng, “Emotion expression with fact transfer for video description,”IEEE Transactions on Multimedia
-
[61]
Graph-based multimodal sequential embedding for sign language translation,
S. Tang, D. Guo, R. Hong, and M. Wang, “Graph-based multimodal sequential embedding for sign language translation,”IEEE Transactions on Multimedia, vol. 24, pp. 4433–4445, 2021
2021
-
[62]
Boost tracking by natural language with prompt-guided grounding,
H. Li, X. Liu, G. Li, S. Wang, L. Qing, and Q. Huang, “Boost tracking by natural language with prompt-guided grounding,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 1, pp. 1088–1100, 2025
2025
-
[63]
Multimodal emotion- cause pair extraction in conversations,
F. Wang, Z. Ding, R. Xia, Z. Li, and J. Yu, “Multimodal emotion- cause pair extraction in conversations,”IEEE Transactions on Affective Computing, vol. 14, no. 3, pp. 1832–1844, 2022
2022
-
[64]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[65]
Syntax- guided hierarchical attention network for video captioning,
J. Deng, L. Li, B. Zhang, S. Wang, Z. Zha, and Q. Huang, “Syntax- guided hierarchical attention network for video captioning,”IEEE Trans- actions on Circuits and Systems for Video Technology, vol. 32, no. 2, pp. 880–892, 2021
2021
-
[66]
Enhanced generative framework with llms for multimodal emotion-cause pair extraction in conversations,
X. Ju, D. Zhang, J. Li, S. Li, and G. Zhou, “Enhanced generative framework with llms for multimodal emotion-cause pair extraction in conversations,”IEEE Transactions on Multimedia, 2025
2025
-
[67]
Improving video summarization by exploring the coherence between corresponding captions,
C. Ye, W. Chen, B. Hu, L. Zhang, Y . Zhang, and Z. Mao, “Improving video summarization by exploring the coherence between corresponding captions,”IEEE Transactions on Image Processing, 2025
2025
-
[68]
Emotion prediction oriented method with multiple supervisions for emotion-cause pair extraction,
G. Hu, Y . Zhao, and G. Lu, “Emotion prediction oriented method with multiple supervisions for emotion-cause pair extraction,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1141–1152, 2023
2023
-
[69]
Subjective- objective emotion correlated generation network for subjective video captioning,
W. Chen, C. Ye, P. Song, L. Zhang, Y . Zhang, and Z. Mao, “Subjective- objective emotion correlated generation network for subjective video captioning,”IEEE Transactions on Image Processing, 2026. Weidong Chen(member, IEEE) received the Ph.D. degree in computer application technology from University of Chinese Academy of Sciences, in
2026
-
[70]
He was a post-doctor with the School of Information Science and Technology, University of Science and Technology of China, from 2022 to 2024
He is currently an Associate Researcher with the School of Information Science and Technology, University of Science and Technology of China, Hefei, China. He was a post-doctor with the School of Information Science and Technology, University of Science and Technology of China, from 2022 to 2024. His research interests include computer vision, natural lan...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.