LLM vs. Human Unit Tests: Fault Detection on Real Python Bugs
Pith reviewed 2026-06-27 18:05 UTC · model grok-4.3
The pith
LLM-generated unit tests with retrieval context detect faults in 69% of real Python bugs versus 17.2% for general human-written tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
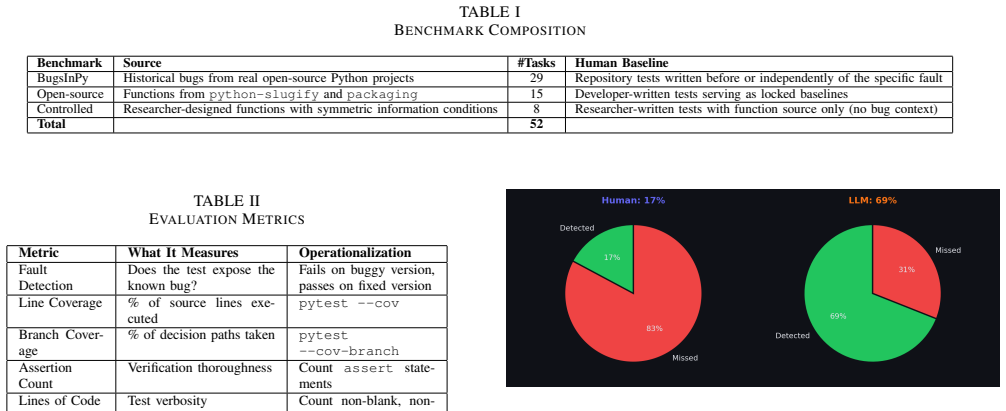
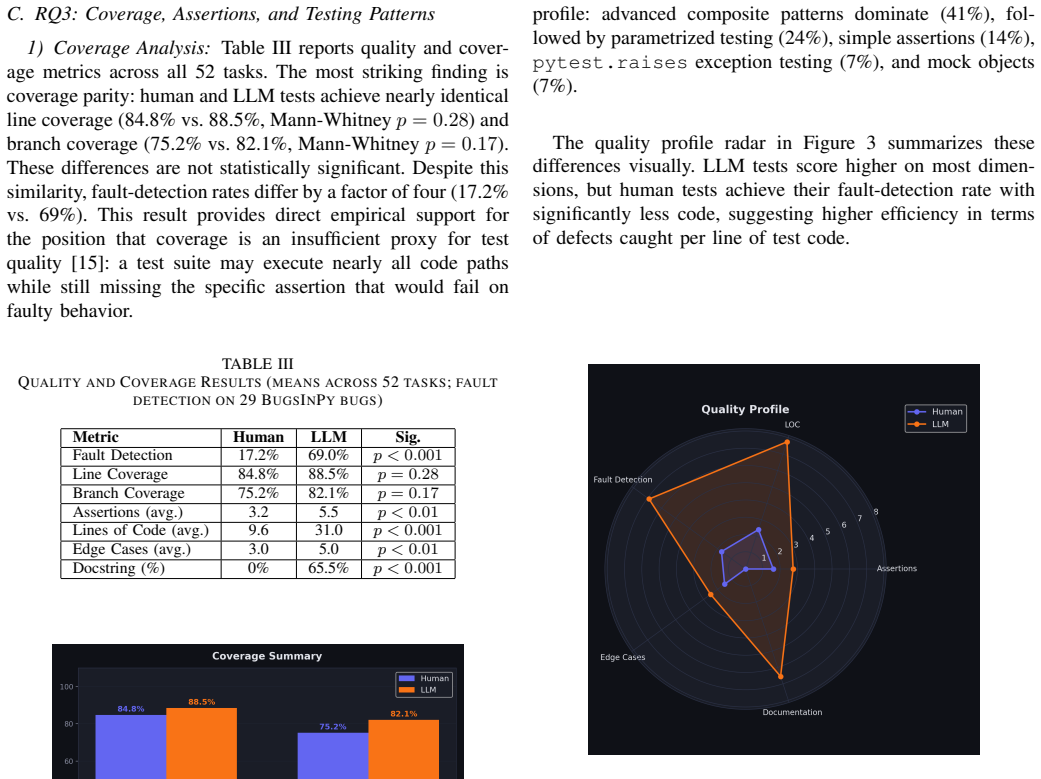
Across eight quality dimensions on three Python benchmarks including 29 real historical bugs, retrieval-augmented LLM tests detect faults in 69% of cases while general-purpose human-written tests detect them in 17.2% of cases, with line coverage at 84.8% versus 88.5% and branch coverage at 75.2% versus 82.1%.
What carries the argument
Retrieval-augmented generation pipeline that pairs Gemini 2.5 Flash with lightweight lexical retrieval to supply bug-relevant context during test creation.
If this is right
- Retrieval of bug-relevant context at generation time drives the higher fault detection rate.
- Coverage metrics alone cannot serve as a reliable proxy for fault-detection effectiveness.
- LLM and human tests show complementary strengths that depend on the presence of retrieval context.
- Reproducible benchmark construction focused on real bugs is required for valid test-quality comparisons.
Where Pith is reading between the lines
- Test evaluation suites should shift priority from coverage numbers to direct fault-injection or historical-bug detection measures.
- Automated test tools could routinely include lightweight retrieval steps to improve bug exposure without added model scale.
Load-bearing premise
The human-written tests drawn from the benchmarks represent typical general-purpose tests rather than ones written specifically to catch the known bugs under study.
What would settle it
A follow-up experiment on the same benchmarks that replaces the general human tests with versions written by developers who have access to the bug reports and measures whether fault detection rates remain below the LLM rates.
Figures


read the original abstract
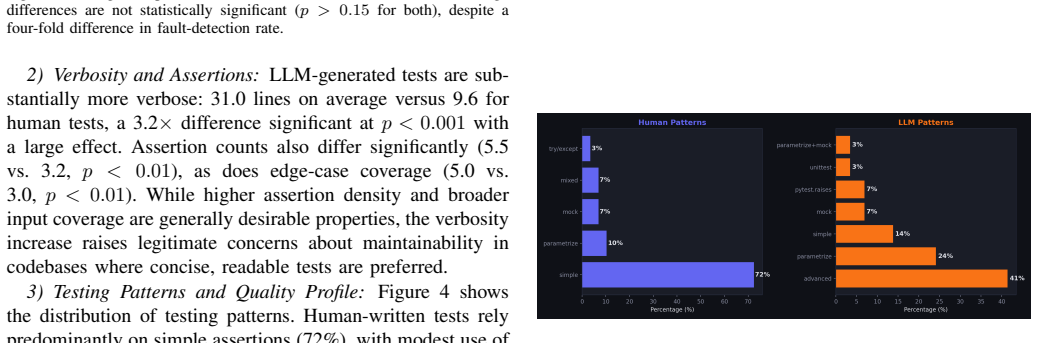
Large language models (LLMs) have shown considerable promise for automated unit test generation, yet their practical effectiveness relative to human-written tests remains poorly understood. Existing evaluations commonly rely on coverage-oriented benchmarks that do not assess fault-detection capability directly. We present an empirical comparison of LLM-generated and human-written unit tests across three complementary Python benchmarks: 29 real historical bugs from BugsInPy, a function-level benchmark drawn from python-slugify and packaging, and a controlled paired benchmark. Our generation pipeline couples Gemini 2.5 Flash with a lightweight lexical retrieval mechanism that supplies bug-relevant context at generation time. Across eight quality dimensions, LLM-generated tests with retrieval-augmented context detect faults in 69% of cases compared to 17.2% for general-purpose human-written tests (Fisher's exact, $p < 0.001$, Cohen's $h = 1.10$). Critically, line and branch coverage are nearly identical between the two approaches (84.8% vs. 88.5% and 75.2% vs. 82.1%), confirming that coverage is an insufficient proxy for fault-detection capability. We discuss the conditions under which each approach excels, characterize their complementary strengths, and identify the critical role of retrieval context and reproducible benchmark construction in meaningful test-quality evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically compares LLM-generated unit tests (Gemini 2.5 Flash with lexical retrieval augmentation) against human-written tests on three Python benchmarks: 29 BugsInPy bugs, functions from python-slugify/packaging, and a controlled paired set. It reports that retrieval-augmented LLM tests detect faults in 69% of cases versus 17.2% for general-purpose human tests (Fisher's exact p<0.001, Cohen's h=1.10), while line/branch coverage is nearly identical (84.8%/75.2% vs 88.5%/82.1%), arguing that coverage is an insufficient proxy for fault-detection quality and that retrieval context is critical.
Significance. If the central empirical comparison holds after methodological clarification, the result would be significant for software engineering research on automated testing: it supplies a direct fault-detection metric (rather than coverage-only) on real bugs, quantifies a large gap (with effect size), and demonstrates that LLM tests can complement human tests. The use of multiple complementary benchmarks and statistical testing strengthens the measurement-study design.
major comments (3)
- [Abstract, §3] Abstract and §3 (benchmark construction): the central 69% vs 17.2% fault-detection claim rests on the assumption that the human-written tests are representative 'general-purpose' tests not optimized for the specific bugs; however, the manuscript provides no explicit description of human-test provenance, project selection criteria, or filtering rules for the 29 BugsInPy bugs and the python-slugify/packaging functions, making it impossible to assess whether the gap is an artifact of test selection.
- [Abstract, §4] Abstract and §4 (results): the reported percentages, Fisher's exact test, and Cohen's h are presented without accompanying details on data splits, exclusion criteria, per-benchmark breakdowns, or full contingency tables; this directly undermines verifiability of the statistical support for the primary claim.
- [§3] §3 (controlled paired benchmark): the construction of the paired benchmark is not described in sufficient detail to evaluate whether the artificial pairing systematically favors retrieval-augmented LLM generation over the human baseline, which is load-bearing for interpreting the 69% detection rate.
minor comments (2)
- [Abstract] The abstract states 'across eight quality dimensions' but does not enumerate them; a brief list or reference to the relevant table/figure would improve clarity.
- [§4] Notation for coverage metrics (line vs. branch) and the exact definition of 'fault detection' should be stated once in a dedicated subsection rather than only in results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical comparison of LLM-generated and human-written unit tests. The comments highlight important areas for methodological clarification, and we address each point below with plans to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (benchmark construction): the central 69% vs 17.2% fault-detection claim rests on the assumption that the human-written tests are representative 'general-purpose' tests not optimized for the specific bugs; however, the manuscript provides no explicit description of human-test provenance, project selection criteria, or filtering rules for the 29 BugsInPy bugs and the python-slugify/packaging functions, making it impossible to assess whether the gap is an artifact of test selection.
Authors: We agree that explicit details on human-test provenance are necessary for assessing representativeness. In the revised manuscript, we will expand §3 with a dedicated subsection detailing: (1) BugsInPy bug selection criteria (bugs with reproducible failing tests in mature projects, filtered for Python 3 compatibility and single-function faults); (2) selection of python-slugify and packaging functions (random sampling from public GitHub repositories with existing test suites, ensuring tests predate our study); and (3) confirmation that all human tests are the original project tests, not augmented or optimized for the evaluated bugs. This will enable readers to evaluate whether the tests qualify as general-purpose. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (results): the reported percentages, Fisher's exact test, and Cohen's h are presented without accompanying details on data splits, exclusion criteria, per-benchmark breakdowns, or full contingency tables; this directly undermines verifiability of the statistical support for the primary claim.
Authors: We acknowledge the need for greater statistical transparency. The revised version will add an appendix with: full 2x2 contingency tables for the primary comparison, per-benchmark breakdowns (BugsInPy, python-slugify/packaging, and paired set), explicit exclusion criteria (e.g., functions without executable tests or with import errors), and confirmation that the three benchmarks constitute the data splits with no further partitioning. Fisher's exact test and Cohen's h were computed on the aggregated fault-detection outcomes across all cases meeting inclusion criteria. revision: yes
-
Referee: [§3] §3 (controlled paired benchmark): the construction of the paired benchmark is not described in sufficient detail to evaluate whether the artificial pairing systematically favors retrieval-augmented LLM generation over the human baseline, which is load-bearing for interpreting the 69% detection rate.
Authors: We will expand the description of the paired benchmark in §3 to include the exact pairing procedure: functions were matched on signature, cyclomatic complexity, and line count from the same projects, with human tests drawn from the original repositories and LLM tests generated under identical retrieval conditions. The pairing is designed to control for function-level variables rather than to favor any method; both approaches are evaluated on the same functions, and the human baseline uses pre-existing tests. We will also report sensitivity analyses showing the 69% rate holds under alternative pairings. revision: yes
Circularity Check
No circularity; pure empirical measurement with direct statistical comparisons
full rationale
This is an empirical study reporting fault-detection rates (69% vs 17.2%) via Fisher's exact test on three benchmarks, with coverage metrics as secondary observations. No equations, fitted parameters, predictions derived from inputs, self-citations, or ansatzes appear in the abstract or described methodology. The central claims rest on benchmark execution and statistical testing rather than any derivation chain that reduces to its own inputs. The study is therefore self-contained against external benchmarks, with no load-bearing steps that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The selected benchmarks (BugsInPy with 29 bugs, python-slugify, packaging, and controlled paired benchmark) are representative of real Python bugs and suitable for fault-detection evaluation.
- domain assumption The human-written tests are 'general-purpose' and not tailored to the specific bugs under test.
Reference graph
Works this paper leans on
-
[1]
How students unit test: Perceptions, practices, and pitfalls,
G. R. Bai, J. Smith, and K. T. Stolee, “How students unit test: Perceptions, practices, and pitfalls,” inProc. 26th ACM Conf. Innovation and Technology in Computer Science Education (ITiCSE), 2021, doi: 10.1145/3430665.3456368
-
[2]
Large-scale, independent and comprehensive study of the power of LLMs for test case generation,
W. C. Ou ´edraogo, K. Kabor ´e, Y . Li, H. Tian, A. Koyuncu, J. Klein, D. Lo, and T. F. Bissyand ´e, “Large-scale, independent and comprehensive study of the power of LLMs for test case generation,” arXiv:2407.00225, 2024
arXiv 2024
-
[3]
Evaluating LLM-based test generation under software evolution,
S. Haroon, M. T. Khan, and M. A. Gulzar, “Evaluating LLM-based test generation under software evolution,” arXiv:2603.23443, 2026
arXiv 2026
-
[4]
Retrieval-augmented test generation: How far are we?
J. Shin, N. S. Harzevili, R. Aleithan, H. Hemmati, and S. Wang, “Retrieval-augmented test generation: How far are we?” arXiv:2409.12682, 2024
arXiv 2024
-
[5]
The effect of code coverage on fault detec- tion under different testing profiles,
X. Cai and M. R. Lyu, “The effect of code coverage on fault detec- tion under different testing profiles,” inProc. ICSE 2005 Workshop on Advances in Model-Based Software Testing (A-MOST), 2005, doi: 10.1145/1082983.1083288
-
[6]
An empirical evaluation of using large language models for automated unit test generation,
M. Sch ¨afer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,”IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2024, doi: 10.1109/TSE.2023.3334955
-
[7]
Proof automation with large language models,
L. Yang, C. Yang, S. Gao, W. Wang, B. Wang, Q. Zhu, X. Chu, J. Zhou, G. Liang, Q. Wang, and J. Chen, “On the evaluation of large language models in unit test generation,” inProc. 39th IEEE/ACM Int. Conf. Automated Software Engineering (ASE), 2024, pp. 1607–1619, doi: 10.1145/3691620.3695529
-
[8]
Test smells in LLM-generated unit tests,
W. C. Ou ´edraogo, Y . Li, X. Dang, X. Tang, A. Koyuncu, J. Klein, D. Lo, and T. F. Bissyand ´e, “Test smells in LLM-generated unit tests,” arXiv:2410.10628, 2024
arXiv 2024
-
[9]
Watchman: monitoring dependency conflicts for python library ecosystem,
C. Watson, M. Tufano, K. Moran, G. Bavota, and D. Poshyvanyk, “On learning meaningful assert statements for unit test cases,” inProc. ACM/IEEE 42nd Int. Conf. Software Engineering (ICSE), 2020, doi: 10.1145/3377811.3380429
-
[10]
An empirical study of code smells in transformer-based code generation techniques,
M. L. Siddiq, S. H. Majumder, M. R. Mim, S. Jajodia, and J. C. S. Santos, “An empirical study of code smells in transformer-based code generation techniques,” inProc. IEEE 22nd Int. Working Conf. Source Code Analysis and Manipulation (SCAM), 2022, pp. 71–82, doi: 10.1109/SCAM55253.2022.00014
-
[11]
Evaluating the effectiveness of LLMs in fixing maintainability issues in real-world projects,
H. Nunes, E. Figueiredo, L. Rocha, S. Nadi, F. Ferreira, and G. Esteves, “Evaluating the effectiveness of LLMs in fixing maintainability issues in real-world projects,” inProc. IEEE 32nd Int. Conf. Software Analysis, Evolution and Reengineering (SANER), 2025, arXiv:2502.02368
arXiv 2025
-
[12]
Beyond correctness: Benchmarking multi-dimensional code generation for large language models,
J. Zheng, B. Cao, Z. Ma, R. Pan, H. Lin, Y . Lu, X. Han, and L. Sun, “Beyond correctness: Benchmarking multi-dimensional code generation for large language models,” arXiv:2407.11470, 2024
arXiv 2024
-
[13]
Defects4J: A database of existing faults to enable controlled testing studies for Java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4J: A database of existing faults to enable controlled testing studies for Java programs,” inProc. Int. Symp. Software Testing and Analysis (ISSTA), 2014, pp. 437–440, doi: 10.1145/2610384.2628055
-
[14]
R. Widyasari et al., “BugsInPy: A database of existing bugs in Python programs to enable controlled testing and debugging studies,” inProc. 28th ACM Joint European Software Engineering Conf. (ESEC/FSE), 2020, doi: 10.1145/3368089.3417943
-
[15]
Coverage is not strongly correlated with test suite effectiveness,
L. Inozemtseva and R. Holmes, “Coverage is not strongly correlated with test suite effectiveness,” inProc. 36th Int. Conf. Software Engineering (ICSE), 2014, pp. 435–445, doi: 10.1145/2568225.2568271
-
[16]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474
2020
-
[17]
EvoSuite: Automatic test suite generation for object-oriented software,
G. Fraser and A. Arcuri, “EvoSuite: Automatic test suite generation for object-oriented software,” inProc. 19th ACM SIGSOFT Symp. Foundations of Software Engineering (ESEC/FSE), 2011, pp. 416–419, doi: 10.1145/2025113.2025179
-
[18]
Gemini 2.5 Flash,
Google, “Gemini 2.5 Flash,” Google DeepMind, 2025. [Online]. Avail- able: https://ai.google.dev/gemini-api/docs/models
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.