Declarative Outcome-Conformant Synthesis: Exact, Closed-Form Specification Satisfaction and a Conformance Benchmark
Pith reviewed 2026-06-27 18:50 UTC · model grok-4.3
The pith
A closed-form generator based on conditional-sum sampling from a Gamma population achieves exact satisfaction of declared analytical outcomes like aggregates, with no source data required.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
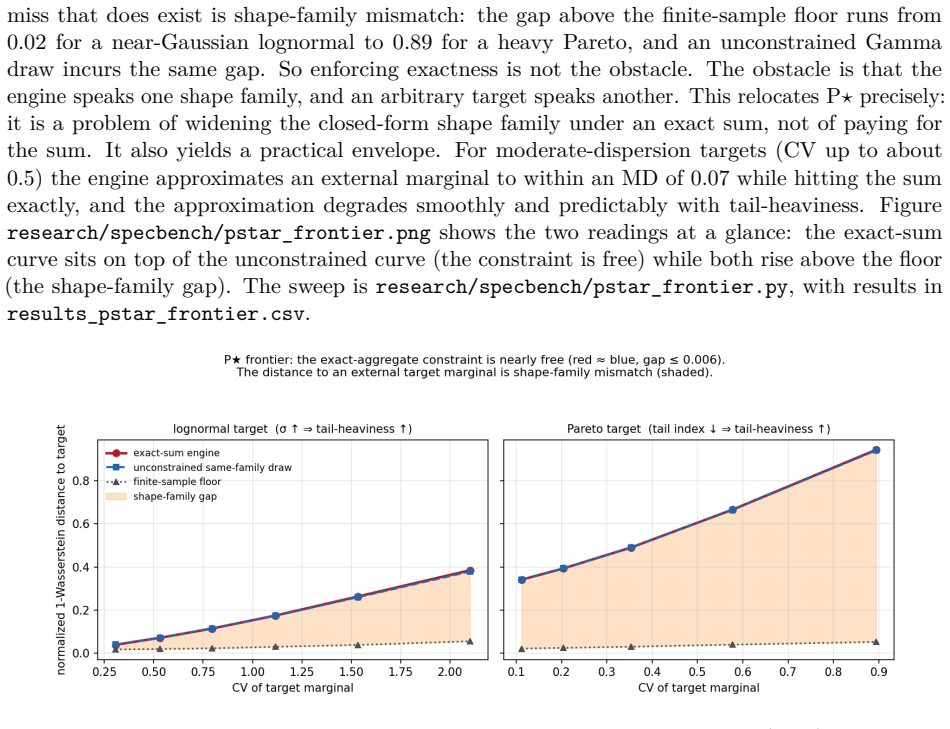
A widely-used family of exact-aggregate generators is exactly conditional-sum sampling of a Gamma population via Lukacs' characterization, delivering closed-form exactness on the aggregate, a closed-form marginal coefficient of variation, and scale-invariance; a controlled experiment shows that enforcing the exact aggregate costs at most 0.006 in 1-Wasserstein distance to an arbitrary external marginal, with the remainder attributable to shape-family mismatch.
What carries the argument
conditional-sum sampling of a Gamma population (via Lukacs' characterization), which enforces exact declared aggregates while preserving closed-form marginal properties and determinism
Load-bearing premise
The relational data generation process for declared outcomes can be modeled as draws from a Gamma population whose conditional sums satisfy the exact aggregate constraint without introducing unmodeled dependencies across the schema.
What would settle it
Run the closed-form generator on a declared aggregate and measure whether the output aggregate deviates from the target by any amount greater than floating-point error, or whether the 1-Wasserstein distance to an external marginal exceeds 0.006 after accounting for shape mismatch.
Figures
read the original abstract
We study a capability the dominant paradigm in synthetic tabular data does not provide: exact satisfaction of a declared analytical outcome with no source data. Imitation methods (copulas, GANs, diffusion) learn a real distribution and sample from it, and are judged on fidelity to real data. A large, practical class of needs is different: generating data with no source data ("cold start") that reproduces a declared outcome (a revenue curve, a churn rate, a group share) across a relational schema. Off-the-shelf imitation tools offer no interface for such targets, and no sampler can hit an exact aggregate, because sampling has variance. On a real public dataset, off-the-shelf learned synthesizers trained on that very data miss the declared monthly aggregate by 74 to 86 percent; a per-period steelman cuts the miss to about 19 percent and still cannot reach 0; a closed-form generator reaches exactly 0. We name this task outcome-conformant synthesis, argue its evaluation axis is conformance rather than fidelity, and show the two axes are orthogonal. We contribute: (1) a formal account showing a widely-used family of exact-aggregate generators is exactly conditional-sum sampling of a Gamma population (via Lukacs' characterization), with closed-form exactness, a closed-form marginal CV, and scale-invariance; a controlled experiment maps the boundary, enforcing the exact aggregate costs at most 0.006 in 1-Wasserstein distance to an arbitrary external marginal, the rest being shape-family mismatch; (2) SpecBench, to our knowledge the first benchmark to measure conformance to analytical outcomes for cold-start relational synthesis; and (3) a closed-form, deterministic reference system. Exact aggregation alone is trivial; the contribution is conformance jointly with closed-form marginals, integrity, determinism, and zero source data. We concede fidelity to imitation where real data exists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that outcome-conformant synthesis enables exact satisfaction of declared analytical outcomes (e.g., aggregates across a relational schema) in cold-start settings with no source data. It argues this is achieved by showing that a family of exact-aggregate generators is equivalent to conditional-sum sampling from a Gamma population via Lukacs' characterization, yielding closed-form exactness, marginal CV, and scale-invariance. A controlled experiment bounds the 1-Wasserstein cost of enforcing the exact aggregate at most 0.006 relative to an external marginal; off-the-shelf methods miss declared aggregates by 74-86% while the proposed closed-form generator reaches exactly 0. It introduces SpecBench for conformance evaluation and positions conformance as orthogonal to fidelity.
Significance. If the derivation and multi-constraint extension hold, the work establishes a new paradigm and evaluation axis for synthetic data that prioritizes exact declarative conformance over distributional fidelity. This is particularly relevant for cold-start relational generation tasks where specific analytical outcomes must be met deterministically, and the closed-form properties plus the SpecBench benchmark provide concrete tools and a falsifiable testbed that current imitation methods lack.
major comments (2)
- [§3] §3 (Formal Account via Lukacs' characterization): The central equivalence to conditional-sum sampling of independent Gammas with common scale supplies the claimed closed-form marginal CV and scale-invariance, but the relational schema setting requires simultaneous enforcement of multiple declared outcomes (different periods/groups/joins). Conditioning on one aggregate induces dependence that violates the independence premise required for the second aggregate to remain a product of conditional Gammas; the manuscript does not supply an adjustment or proof that the closed-form properties survive this joint constraint.
- [Section 5] Controlled experiment (Section 5, Wasserstein bound): The reported bound of at most 0.006 in 1-Wasserstein distance is demonstrated for a single aggregate constraint; no results or extension are given for the multi-aggregate case that the abstract and introduction identify as the core relational use case. This leaves the load-bearing claim that the method jointly satisfies exactness, closed-form marginals, and relational integrity without extra adjustments unverified.
minor comments (2)
- [Abstract] Abstract: the phrase '74 to 86 percent' miss should be clarified as relative or absolute error on the aggregate value, and the 'per-period steelman' baseline should be defined with a citation or section reference.
- SpecBench description: the benchmark schema, number of declared outcomes per instance, and exact metric definitions (e.g., how conformance is aggregated across periods) are referenced but not fully specified in the provided text, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the precise identification of the gap between the single-constraint formalization and the multi-constraint relational claims. We address both major comments below and will revise the manuscript to clarify the scope and supply the missing multi-aggregate analysis.
read point-by-point responses
-
Referee: [§3] §3 (Formal Account via Lukacs' characterization): The central equivalence to conditional-sum sampling of independent Gammas with common scale supplies the claimed closed-form marginal CV and scale-invariance, but the relational schema setting requires simultaneous enforcement of multiple declared outcomes (different periods/groups/joins). Conditioning on one aggregate induces dependence that violates the independence premise required for the second aggregate to remain a product of conditional Gammas; the manuscript does not supply an adjustment or proof that the closed-form properties survive this joint constraint.
Authors: We agree that Lukacs' characterization and the resulting closed-form marginal CV and scale-invariance rest on independence of the underlying Gamma variables. Sequential conditioning on multiple aggregates necessarily introduces dependence, so the exact closed-form properties do not automatically carry over. The manuscript presents the single-constraint derivation as the core technical result and states that the approach extends to relational schemas, but supplies neither an explicit joint proof nor an adjusted procedure. We will revise §3 to (a) explicitly delimit the single-constraint guarantees and (b) either derive an approximate multi-constraint extension or describe a practical sequential sampling algorithm with its attendant loss of closed-form marginal properties. revision: yes
-
Referee: [Section 5] Controlled experiment (Section 5, Wasserstein bound): The reported bound of at most 0.006 in 1-Wasserstein distance is demonstrated for a single aggregate constraint; no results or extension are given for the multi-aggregate case that the abstract and introduction identify as the core relational use case. This leaves the load-bearing claim that the method jointly satisfies exactness, closed-form marginals, and relational integrity without extra adjustments unverified.
Authors: The experiment in Section 5 is restricted to a single aggregate; the 0.006 Wasserstein bound therefore applies only to that setting. The abstract and introduction do position the method for relational schemas with multiple declared outcomes, yet no multi-constraint results are reported. We accept that this leaves the joint claim unverified. In revision we will add either (i) a multi-constraint experiment that measures the additional Wasserstein cost and any degradation in marginal properties, or (ii) a clear statement that the current closed-form guarantees and bound are proven only for single constraints, with multi-constraint support left for future work. revision: yes
Circularity Check
No significant circularity; derivation rests on external Lukacs theorem plus controlled experiment.
full rationale
The paper's central formal account equates a family of exact-aggregate generators to conditional-sum sampling of a Gamma population via Lukacs' characterization (an external theorem), from which closed-form exactness, marginal CV, and scale-invariance are stated to follow. A separate controlled experiment quantifies the 1-Wasserstein cost of enforcing the aggregate against an arbitrary external marginal. No equations or claims reduce by construction to fitted parameters defined by the target result, no self-citation is load-bearing on the core identification, and no ansatz or uniqueness result is smuggled via prior author work. The derivation chain is therefore self-contained against the cited external theorem and experiment.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Lukacs' characterization: the conditional distribution of independent Gamma random variables given their sum is Dirichlet
Reference graph
Works this paper leans on
-
[1]
W. Ågren and V. Úbeda Sosa. Hierarchical conditional tabular GAN for multi-tabular synthetic data generation. 2024. Preprint, arXiv:2411.07009
arXiv 2024
-
[2]
Aitchison.The Statistical Analysis of Compositional Data
J. Aitchison.The Statistical Analysis of Compositional Data. Chapman & Hall, London, 1986. ISBN 0-412-28060-4
1986
-
[3]
A. Arasu, R. Kaushik, and J. Li. DataSynth: Generating synthetic data using declarative constraints.Proc. VLDB Endowment (PVLDB), 4(12), 2011. doi: 10.14778/3402755.3402785
-
[4]
Armendáriz and M
I. Armendáriz and M. Loulakis. Conditional distribution of heavy tailed random variables on large deviations of their sum.Stochastic Processes and their Applications, 121(5):1138–1147, 2011
2011
-
[5]
M. L. Balinski and H. P. Young.Fair Representation: Meeting the Ideal of One Man, One Vote. Yale University Press, 1982. ISBN 0-300-02724-9
1982
-
[6]
C. Binnig, D. Kossmann, E. Lo, and M. T. Özsu. QAGen: Generating query-aware test databases. InProc. ACM SIGMOD Int. Conf. on Management of Data, pages 341–352, Beijing, China, 2007. doi: 10.1145/1247480.1247520
-
[7]
G. C. Chow and A.-l. Lin. Best linear unbiased interpolation, distribution, and extrapolation of time series by related series.The Review of Economics and Statistics, 53(4):372–375, 1971
1971
-
[8]
V. S. Chundawat, A. K. Tarun, M. Mandal, M. Lahoti, and P. Narang. TabSynDex: A universal metric for robust evaluation of synthetic tabular data. 2022. Preprint, arXiv:2207.05295
arXiv 2022
-
[9]
L. H. Cox. A constructive procedure for unbiased controlled rounding.Journal of the American Statistical Association, 82(398):520–524, 1987. 20
1987
-
[10]
SDGym and SDMetrics
DataCebo. SDGym and SDMetrics. software + documentation
-
[11]
W. E. Deming and F. F. Stephan. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known.The Annals of Mathematical Statistics, 11(4): 427–444, 1940. doi: 10.1214/aoms/1177731829
-
[12]
F. T. Denton. Adjustment of monthly or quarterly series to annual totals: An approach based on quadratic minimization.Journal of the American Statistical Association, 66(333):99–102, 1971
1971
-
[13]
C. Esteban, S. L. Hyland, and G. Rätsch. Real-valued (medical) time series generation with recurrent conditional gans. 2017. Preprint, arXiv:1706.02633
Pith/arXiv arXiv 2017
-
[14]
Golchi and D
S. Golchi and D. A. Campbell. Sequentially constrained monte carlo.Computational Statistics & Data Analysis, 97:98–113, 2016
2016
-
[15]
V. Hudovernik, M. Xu, J. Shi, L. Šubelj, S. Ermon, E. Štrumbelj, and J. Leskovec. RelDiff: Relational data generative modeling with graph-based diffusion models. 2025. Preprint, arXiv:2506.00710
arXiv 2025
-
[16]
Kotelnikov, D
A. Kotelnikov, D. Baranchuk, I. Rubachev, and A. Babenko. TabDDPM: Modelling tabular data with diffusion models. InProc. 40th Int. Conf. on Machine Learning (ICML), PMLR, volume 202, pages 17564–17579, 2023
2023
-
[17]
A. D. Lautrup, T. Hyrup, A. Zimek, and P. Schneider-Kamp. SynthEval: A framework for detailed utility and privacy evaluation of tabular synthetic data.Data Mining and Knowledge Discovery, 39(1), 2025
2025
-
[18]
J. Li, Z. Zhao, M. Abdollahzadeh, B. Sikdar, and Y. C. Tay. IRG: Modular synthetic relational database generation with complex relational schemas. 2023. doi: 10.1145/3770854.3780313. Preprint, arXiv:2312.15187
-
[19]
S. Liu, Y. Zheng, and Y. Zhang. StructSynth: Leveraging LLMs for structure-aware tabular data synthesis in low-data regimes. 2025. Preprint, arXiv:2508.02601
arXiv 2025
-
[20]
E. Lo, C. Binnig, D. Kossmann, M. T. Özsu, and W.-K. Hon. A framework for testing DBMS features.The VLDB Journal, 19(2):203–230, 2010. doi: 10.1007/s00778-009-0157-y
-
[21]
Y. Long, L. Xu, and A. Brintrup. LLM-TabLogic: Preserving inter-column logical relationships in synthetic tabular data via prompt-guided latent diffusion. 2025. Preprint, arXiv:2503.02161
Pith/arXiv arXiv 2025
-
[22]
E. Lukacs. A characterization of the gamma distribution.The Annals of Mathematical Statistics, 26(2):319–324, 1955
1955
- [23]
-
[24]
NeMo data designer, 2025
NVIDIA (formerly Gretel). NeMo data designer, 2025. Apache-2.0; software + documentation
2025
-
[25]
N. Patki, R. Wedge, and K. Veeramachaneni. The synthetic data vault. InIEEE Int. Conf. on Data Science and Advanced Analytics (DSAA), pages 399–410, 2016. doi: 10.1109/DSAA.2016. 49. 21
-
[26]
A. Sanghi, S. Ahmed, and J. R. Haritsa. Projection-compliant database generation.Proc. VLDB Endowment (PVLDB), 15(5):998–1010, 2022. doi: 10.14778/3510397.3510398
-
[27]
A. Sidorenko, M. Platzer, M. Scriminaci, and P. Tiwald. Benchmarking synthetic tabular data: A multi-dimensional evaluation framework. 2025. Preprint, arXiv:2504.01908
arXiv 2025
-
[28]
Szavits-Nossan, M
J. Szavits-Nossan, M. R. Evans, and S. N. Majumdar. Condensation transition in joint large deviations of linear statistics.Journal of Physics A: Mathematical and Theoretical, 47(45): 455004, 2014
2014
-
[29]
L. Xu, M. Skoularidou, A. Cuesta-Infante, and K. Veeramachaneni. Modeling tabular data using conditional GAN. InAdvances in Neural Information Processing Systems (NeurIPS), pages 7335–7345, 2019
2019
-
[30]
Z. Yao, N. Krčo, G. Ganev, and Y.-A. de Montjoye. The DCR delusion: Measuring the privacy risk of synthetic data. 2025. Preprint, arXiv:2505.01524
arXiv 2025
-
[31]
C. Zhang et al. Self-reinforcing controllable synthesis of rare relational data via bayesian calibration. 2026. Preprint, arXiv:2604.16817. 22
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.