HydraQE: OSU's Submission for the IWSLT 2026 Speech Translation Metrics Shared Task
Pith reviewed 2026-06-27 18:37 UTC · model grok-4.3
The pith
HydraQE shows end-to-end speech translation quality estimation can compete with cascaded text-based systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HydraQE outperforms cascaded text-based baselines and prior direct speech QE systems, demonstrating that end-to-end speech translation QE is competitive with cascaded approaches.
What carries the argument
Joint audio-plus-hypothesis input to a Qwen3-ASR backbone whose layers are mixed by learnable sparsemax scalars, re-encoded by a bidirectional Transformer, and passed to three independent heads trained on complementary supervision signals.
If this is right
- End-to-end models can achieve higher performance than cascaded text-based systems for speech translation quality estimation.
- Multi-head training on human assessments plus automatic metrics allows effective use of scarce labeled data.
- Curriculum learning from synthetic and silver data to human annotations supports generalization despite limited annotations.
- Direct audio input removes the need for an intermediate transcription step in the evaluation pipeline.
Where Pith is reading between the lines
- The same joint-input architecture could be tested on quality estimation for other speech-related tasks such as summarization or captioning.
- Removing the cascaded transcription step may reduce error accumulation in live monitoring of speech translation quality.
- The curriculum approach might transfer to other low-resource multimodal estimation problems where human labels are expensive.
Load-bearing premise
Training on synthetically corrupted examples, silver pseudo-labeled outputs, and a curriculum that shifts toward human annotations will produce a model that generalizes to the unseen IWSLT 2026 test distribution without overfitting to the pseudo-label sources.
What would settle it
If HydraQE scores below the cascaded text-based baselines on the official IWSLT 2026 test set, the claim that end-to-end speech translation QE is competitive would be falsified.
Figures

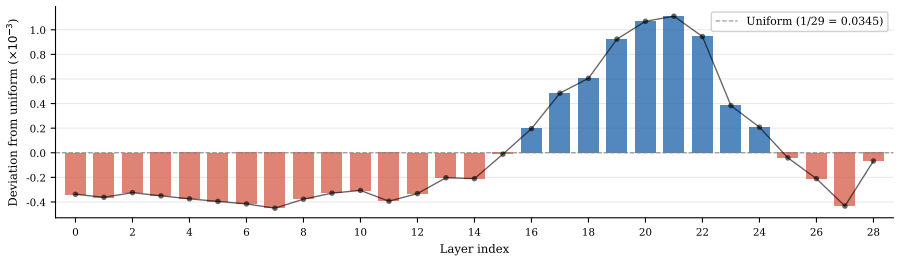
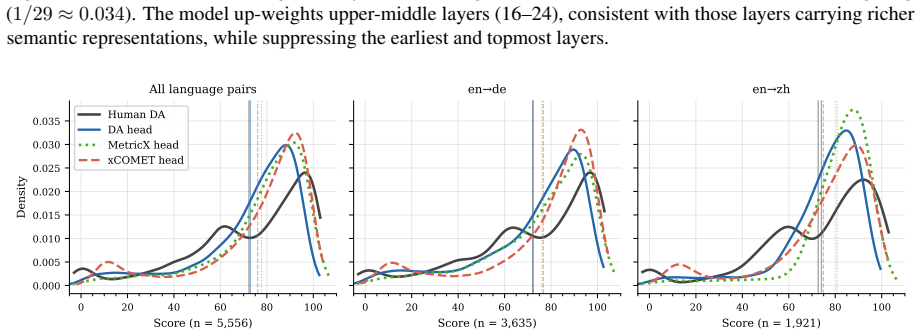
read the original abstract
We present HydraQE, our contribution to the IWSLT 2026 Speech Translation Metrics shared task. HydraQE is an end-to-end, reference-free quality estimation (QE) system for speech translation built on a Qwen3-ASR backbone, which accepts source audio and a translation hypothesis as joint input. Hidden states from all backbone layers are combined via a learnable sparsemax scalar mix, then re-encoded by a lightweight bidirectional Transformer to enable full cross-modal interaction prior to pooling into a shared embedding. Three independent prediction heads are trained on complementary supervision signals: human direct assessment (DA) annotations, MetricX-24 pseudo-labels, and xCOMET pseudo-labels. To address the scarcity of human-annotated data, we train on a combination of synthetically corrupted examples and silver pseudo-labeled machine translation outputs, using a curriculum that begins on synthetic and silver data and gradually shifts toward human-annotated examples. HydraQE outperforms cascaded text-based baselines and prior direct speech QE systems, demonstrating that end-to-end speech translation QE is competitive with cascaded approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HydraQE, an end-to-end reference-free quality estimation system for speech translation built on a Qwen3-ASR backbone. It combines hidden states from all layers via a learnable sparsemax scalar mix, re-encodes them with a lightweight bidirectional Transformer for cross-modal interaction, and uses three independent prediction heads trained on human direct assessment annotations, MetricX-24 pseudo-labels, and xCOMET pseudo-labels. Training uses synthetically corrupted examples and silver pseudo-labeled MT outputs with a curriculum that starts on synthetic/silver data and shifts toward human annotations. The central claim is that HydraQE outperforms cascaded text-based baselines and prior direct speech QE systems.
Significance. If the outperformance claim holds with proper validation, the work would indicate that end-to-end speech translation QE can be competitive with cascaded approaches, addressing data scarcity via multi-source supervision and curriculum learning. The multi-head design on complementary signals is a reasonable response to limited human data. However, the heavy reliance on pseudo-labels from existing systems (MetricX-24 and xCOMET) limits the potential impact unless the model is shown to learn independent cross-modal features rather than artifacts of the labelers. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the claim that HydraQE 'outperforms cascaded text-based baselines and prior direct speech QE systems' is asserted without any numerical results, correlation scores, error bars, ablation tables, or dataset statistics, so the central empirical claim cannot be evaluated.
- [Abstract] Abstract: two of the three supervision signals are pseudo-labels from MetricX-24 and xCOMET; without ablations on the contribution of each head, details on the curriculum schedule/mixing ratios, or results on a held-out human-only validation set, the generalization claim to the unseen IWSLT 2026 test distribution rests on an untested assumption that the model does not overfit to silver-labeler biases.
minor comments (2)
- [Abstract] Abstract: the architecture of the 'lightweight bidirectional Transformer' (number of layers, hidden dimension, attention heads) is not specified.
- [Abstract] Abstract: no information is given on initialization, regularization, or training details for the learnable sparsemax scalar mix weights.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will make the indicated revisions to strengthen the presentation of results and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that HydraQE 'outperforms cascaded text-based baselines and prior direct speech QE systems' is asserted without any numerical results, correlation scores, error bars, ablation tables, or dataset statistics, so the central empirical claim cannot be evaluated.
Authors: We agree that the abstract would benefit from quantitative support for the performance claim. The full experimental results, including correlation scores on the IWSLT 2026 test set, are reported in the body of the paper. In the revised manuscript we will update the abstract to include the primary correlation metrics (e.g., Pearson and Spearman) comparing HydraQE against the cascaded baselines. revision: yes
-
Referee: [Abstract] Abstract: two of the three supervision signals are pseudo-labels from MetricX-24 and xCOMET; without ablations on the contribution of each head, details on the curriculum schedule/mixing ratios, or results on a held-out human-only validation set, the generalization claim to the unseen IWSLT 2026 test distribution rests on an untested assumption that the model does not overfit to silver-labeler biases.
Authors: We acknowledge the need for explicit evidence that the model benefits from the complementary supervision signals rather than simply memorizing pseudo-label artifacts. The revised manuscript will include (1) ablations isolating the contribution of each prediction head, (2) the exact curriculum schedule and data-mixing ratios, and (3) performance numbers on a held-out human-annotated validation set. revision: yes
Circularity Check
No significant circularity; empirical system description with external supervision sources
full rationale
The paper describes an empirical end-to-end QE model trained on human DA annotations plus external pseudo-labels from MetricX-24 and xCOMET, with a curriculum mixing synthetic corruptions. No mathematical derivation, equations, or self-referential definitions are present that reduce any claimed result to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear. The outperformance claim rests on shared-task evaluation rather than any fitted parameter being renamed as a prediction or any load-bearing premise collapsing to self-generated quantities. This is a standard semi-supervised training setup without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable sparsemax scalar mix weights
Reference graph
Works this paper leans on
-
[1]
Idris Abdulmumin, Victor Agostinelli, Tanel Alum \"a e, Antonios Anastasopoulos, Luisa Bentivogli, Ond r ej Bojar, Claudia Borg, Fethi Bougares, Roldano Cattoni, Mauro Cettolo, Lizhong Chen, William Chen, Raj Dabre, Yannick Est \`e ve, Marcello Federico, Mark Fishel, Marco Gaido, D \'a vid Javorsk \'y , Marek Kasztelnik, and 33 others. 2025. https://doi.o...
-
[2]
David Ifeoluwa Adelani, Victor Agostinelli, Antonios Anastasopoulos, Luisa Bentivogli, Ond r ej Bojar, Sebastien Brati \`e res, Marine Carpuat, Roldano Cattoni, Mauro Cettolo, Lizhong Chen, Marcello Federico, Marco Gaido, Mahendra Gupta, HyoJung Han, Ali Hatami, David Javorsk \'y , Yejin Jeon, Marek Kasztelnik, Antoine Laurent, and 33 others. 2026. Speech...
2026
-
[3]
Mauro Cettolo, Marco Gaido, Matteo Negri, Sara Papi, and Luisa Bentivogli. 2026. https://arxiv.org/abs/2511.03295 How to evaluate speech translation with source-aware neural mt metrics . Preprint, arXiv:2511.03295
Pith/arXiv arXiv 2026
-
[4]
Mingda Chen, Paul-Ambroise Duquenne, Pierre Andrews, Justine Kao, Alexandre Mourachko, Holger Schwenk, and Marta R. Costa-juss \`a . 2023. https://doi.org/10.18653/v1/2023.acl-long.504 BLASER : A text-free speech-to-speech translation evaluation metric . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
-
[5]
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. 2022. https://doi.org/10.1109/SLT54892.2023.10023141 FLEURS: few-shot learning evaluation of universal representations of speech . In IEEE Spoken Language Technology Workshop, SLT 2022, Doha, Qatar, January 9-12, 2023 , pages 798--...
-
[6]
David Dale and Marta R. Costa-juss \`a . 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.943 BLASER 2.0: a metric for evaluation and quality estimation of massively multilingual speech and text translation . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16075--16085, Miami, Florida, USA. Association for Computationa...
-
[7]
Paul-Ambroise Duquenne, Holger Schwenk, and Benoît Sagot. 2023. https://arxiv.org/abs/2308.11466 Sonar: Sentence-level multimodal and language-agnostic representations . Preprint, arXiv:2308.11466
arXiv 2023
-
[8]
Markus Freitag, Ricardo Rei, Nitika Mathur, Chi-kiu Lo, Craig Stewart, Eleftherios Avramidis, Tom Kocmi, George Foster, Alon Lavie, and Andr \'e F. T. Martins. 2022. https://doi.org/10.18653/v1/2022.wmt-1.2 Results of WMT 22 metrics shared task: Stop using BLEU -- neural metrics are better and more robust . In Proceedings of the Seventh Conference on Mach...
-
[9]
Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F. T. Martins. 2024. https://doi.org/10.1162/tacl_a_00683 x COMET : Transparent machine translation evaluation through fine-grained error detection . Transactions of the Association for Computational Linguistics, 12:979--995
-
[10]
HyoJung Han, Kevin Duh, and Marine Carpuat. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1218 S peech QE : Estimating the quality of direct speech translation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21852--21867, Miami, Florida, USA. Association for Computational Linguistics
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lora: Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
-
[12]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. 2026. https://arxiv.org/abs/2601.15621 Qwen3-tts technical report . Preprint, arXiv:2601.15621
Pith/arXiv arXiv 2026
-
[13]
Ganesh Jawahar, Beno \^i t Sagot, and Djam \'e Seddah. 2019. https://doi.org/10.18653/v1/P19-1356 What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651--3657, Florence, Italy. Association for Computational Linguistics
-
[14]
Alexander Jones, William Yang Wang, and Kyle Mahowald. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.471 A massively multilingual analysis of cross-linguality in shared embedding space . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5833--5847, Online and Punta Cana, Dominican Republic. Association fo...
-
[15]
Juraj Juraska, Daniel Deutsch, Mara Finkelstein, and Markus Freitag. 2024. https://doi.org/10.18653/v1/2024.wmt-1.35 M etric X -24: The G oogle submission to the WMT 2024 metrics shared task . In Proceedings of the Ninth Conference on Machine Translation, pages 492--504, Miami, Florida, USA. Association for Computational Linguistics
-
[16]
Juraj Juraska, Mara Finkelstein, Daniel Deutsch, Aditya Siddhant, Mehdi Mirzazadeh, and Markus Freitag. 2023. https://doi.org/10.18653/v1/2023.wmt-1.63 M etric X -23: The G oogle submission to the WMT 2023 metrics shared task . In Proceedings of the Eighth Conference on Machine Translation, pages 756--767, Singapore. Association for Computational Linguistics
-
[17]
Tom Kocmi and Christian Federmann. 2023. https://doi.org/10.18653/v1/2023.wmt-1.64 GEMBA - MQM : Detecting translation quality error spans with GPT -4 . In Proceedings of the Eighth Conference on Machine Translation, pages 768--775, Singapore. Association for Computational Linguistics
-
[18]
Alon Lavie, Greg Hanneman, Sweta Agrawal, Diptesh Kanojia, Chi-Kiu Lo, Vil \'e m Zouhar, Frederic Blain, Chrysoula Zerva, Eleftherios Avramidis, Sourabh Deoghare, Archchana Sindhujan, Jiayi Wang, David Ifeoluwa Adelani, Brian Thompson, Tom Kocmi, Markus Freitag, and Daniel Deutsch. 2025. https://doi.org/10.18653/v1/2025.wmt-1.24 Findings of the WMT 25 sha...
-
[19]
Zhu Liu, Cunliang Kong, Ying Liu, and Maosong Sun. 2024. https://doi.org/10.18653/v1/2024.findings-acl.866 Fantastic semantics and where to find them: Investigating which layers of generative LLM s reflect lexical semantics . In Findings of the Association for Computational Linguistics: ACL 2024, pages 14551--14558, Bangkok, Thailand. Association for Comp...
-
[20]
Andr \' e F. T. Martins and Ram \' o n Fernandez Astudillo. 2016. http://proceedings.mlr.press/v48/martins16.html From softmax to sparsemax: A sparse model of attention and multi-label classification . In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016 , JMLR Workshop and Conference...
2016
-
[21]
NLLB Team , Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, and 20 others. 2022. https://arxiv.org/abs/2207.04672 No languag...
Pith/arXiv arXiv 2022
-
[22]
Omnilingual MT Team , Belen Alastruey, Niyati Bafna, Andrea Caciolai, Kevin Heffernan, Artyom Kozhevnikov, Christophe Ropers, Eduardo Sánchez, Charles-Eric Saint-James, Ioannis Tsiamas, Chierh Cheng, Joe Chuang, Paul-Ambroise Duquenne, Mark Duppenthaler, Nate Ekberg, Cynthia Gao, Pere Lluís Huguet Cabot, João Maria Janeiro, Jean Maillard, and 12 others. 2...
Pith/arXiv arXiv 2026
-
[23]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://doi.org/10.3115/1073083.1073135 B leu: a method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311--318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics
-
[24]
Guerreiro, Jos \'e Pombal, Daan van Stigt, Marcos Treviso, Luisa Coheur, Jos \'e G
Ricardo Rei, Nuno M. Guerreiro, Jos \'e Pombal, Daan van Stigt, Marcos Treviso, Luisa Coheur, Jos \'e G. C. de Souza, and Andr \'e F. T. Martins. 2023. https://doi.org/10.18653/v1/2023.wmt-1.73 Scaling up C omet K iwi: Unbabel- IST 2023 submission for the quality estimation shared task . In Proceedings of the Eighth Conference on Machine Translation, page...
-
[25]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.213 COMET : A neural framework for MT evaluation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685--2702, Online. Association for Computational Linguistics
-
[26]
Guerreiro, Chrysoula Zerva, Ana C Farinha, Christine Maroti, Jos \'e G
Ricardo Rei, Marcos Treviso, Nuno M. Guerreiro, Chrysoula Zerva, Ana C Farinha, Christine Maroti, Jos \'e G. C. de Souza, Taisiya Glushkova, Duarte Alves, Luisa Coheur, Alon Lavie, and Andr \'e F. T. Martins. 2022. https://doi.org/10.18653/v1/2022.wmt-1.60 C omet K iwi: IST -unbabel 2022 submission for the quality estimation shared task . In Proceedings o...
-
[27]
Seamless Communication , Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, and 49 others. 2023. https://arxiv.org/abs/...
arXiv 2023
-
[28]
Thibault Sellam, Dipanjan Das, and Ankur Parikh. 2020. https://doi.org/10.18653/v1/2020.acl-main.704 BLEURT : Learning robust metrics for text generation . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7881--7892, Online. Association for Computational Linguistics
-
[29]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. 2026. https://arxiv.org/abs/2601.21337 Qwen3-asr technical report . Preprint, arXiv:2601.21337
Pith/arXiv arXiv 2026
-
[30]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. https://doi.org/10.18653/v1/P19-1452 BERT rediscovers the classical NLP pipeline . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593--4601, Florence, Italy. Association for Computational Linguistics
-
[31]
Changhan Wang, Anne Wu, Jiatao Gu, and Juan Pino. 2021. https://doi.org/10.21437/INTERSPEECH.2021-2027 Covost 2 and massively multilingual speech translation . In 22nd Annual Conference of the International Speech Communication Association, Interspeech 2021, Brno, Czechia, August 30 - September 3, 2021, pages 2247--2251. ISCA
-
[32]
Mao Zheng, Zheng Li, Bingxin Qu, Mingyang Song, Yang Du, Mingrui Sun, and Di Wang. 2025. https://arxiv.org/abs/2509.05209 Hunyuan-mt technical report . Preprint, arXiv:2509.05209
arXiv 2025
-
[33]
Vil \'e m Zouhar, Pinzhen Chen, Tsz Kin Lam, Nikita Moghe, and Barry Haddow. 2024. https://doi.org/10.18653/v1/2024.wmt-1.121 Pitfalls and outlooks in using COMET . In Proceedings of the Ninth Conference on Machine Translation, pages 1272--1288, Miami, Florida, USA. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.