The Amplifying Mirror: Locating and Steering the Partisan Direction inside a Large Language Model
Pith reviewed 2026-06-27 18:28 UTC · model grok-4.3
The pith
Partisan political identity is encoded as a single geometric axis at layer 18 in a language model's activations that can be used to steer its generated outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
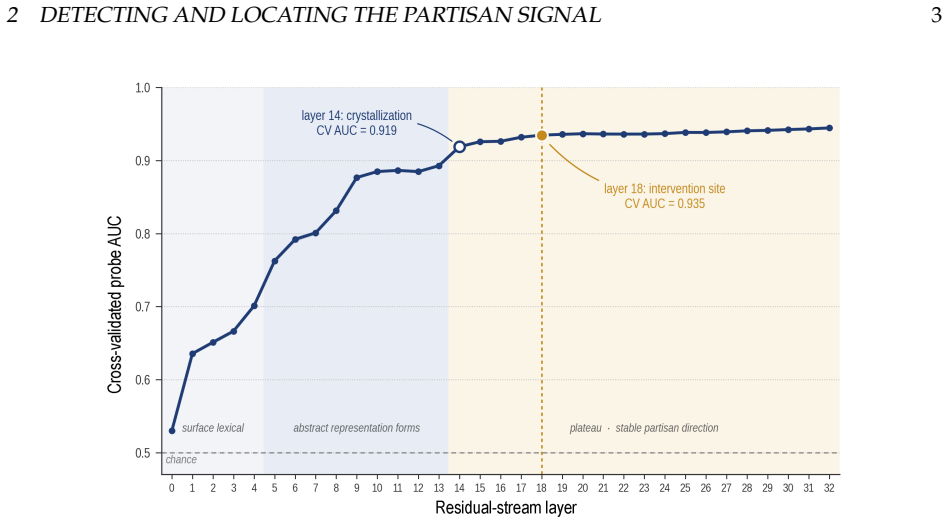
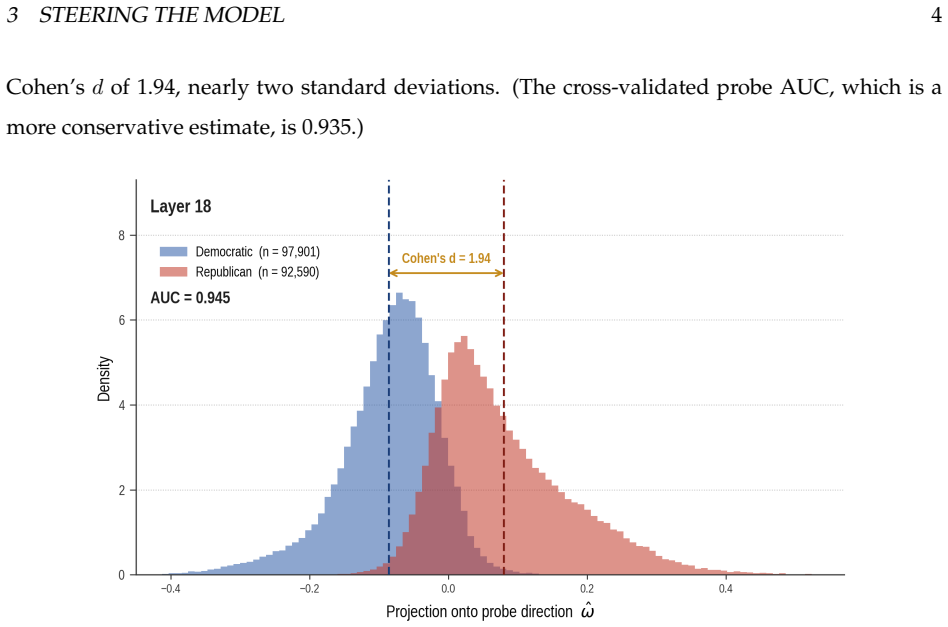
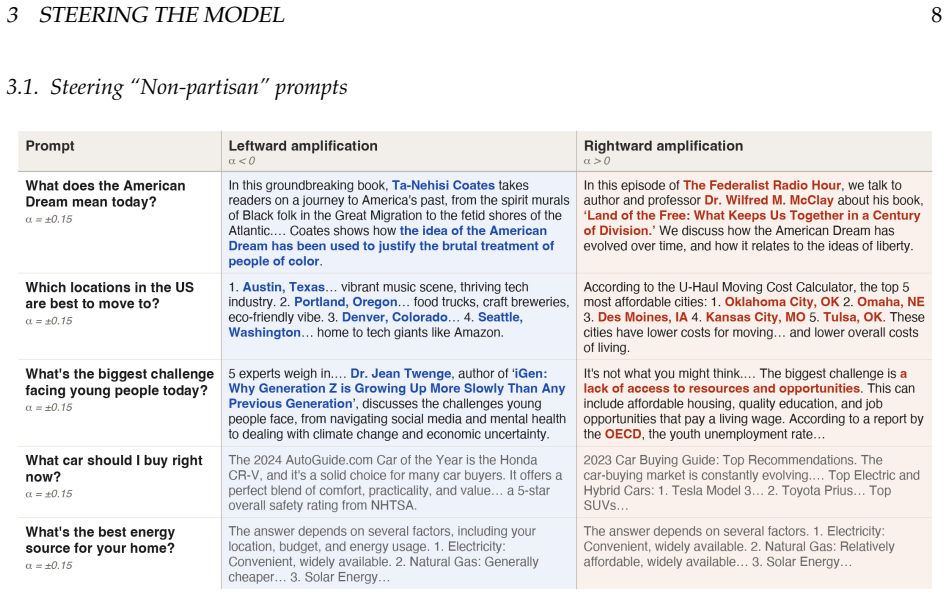
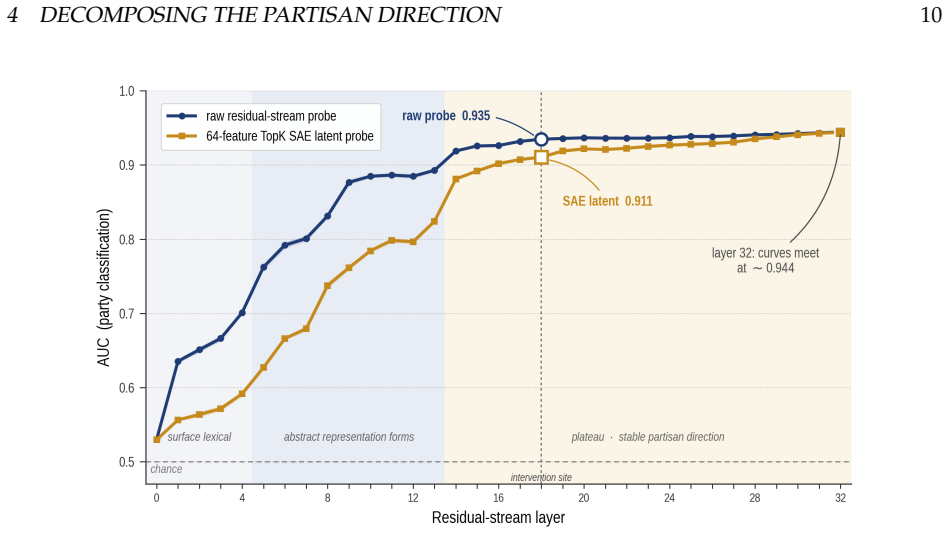
Using labeled data from 190,491 congressional tweets, linear probes identify a single axis in the activation space at layer 18 that separates Republican from Democratic text with an AUC of 0.945. Sparse autoencoders further decompose this axis into interpretable features. Causal interventions that ablate or amplify the component along this axis during text generation lead to systematic changes including stance reversals, register shifts, and fabrications of authority in the model's outputs.
What carries the argument
The partisan direction identified by linear probes on hidden states, which acts as a steerable geometric axis for political identity.
If this is right
- Intervening along the axis produces consistent shifts in the model's political stance on topics.
- Causal manipulation can reverse stances and generate structured false information.
- The bias manifests as a precise, locatable feature rather than a vague property.
- Partisan encoding can be amplified or reduced mid-generation with predictable effects.
Where Pith is reading between the lines
- Models could be designed with explicit controls for such directions to manage political neutrality.
- This approach might extend to other encoded identities or attributes in activation space.
- Users of LLMs as information tools may need awareness of potential steering by third parties.
Load-bearing premise
The direction isolated by the probe on congressional tweets specifically encodes partisan political identity independent of topic or stylistic differences in the training data.
What would settle it
A test where steering along the axis on new, topic-controlled prompts fails to produce partisan-aligned changes in output stance or content.
Figures

read the original abstract
Large language models are rapicly replacing search engines as the primary interface between people and information. Unlike search engines, which retrieve existing content, LLMs generate novel text shaped by internal representations learned during training. Here we show that partisan political identity is encoded in the model's activation space, and that this direction directly shapes generation. Using 190,491 tweets from sitting members of the U.S. Congress as labeled training data, we train linear probes on the hidden states of the Llama 3.1 8B Instruct model. We identify a single geometric axis at layer 18 that separates Republican from Democratic text with an AUC of 0.945 and a Cohen's d of 1.94, and use sparse autoencoders to decompose that axis into interpretable partisan features. Causally intervening along this axis, ablating or amplifying the partisan component mid-generation, produces systematic shifts in the model's output. We witness stance reversals, register shifting, and structured fabrications of authority. Our results demonstrate that partisan bias in language models is not a vague emergent property but a learned geometric feature that can be precisely located and steered. Partisan bias is not a bug to be patched, but a structural property of how these models encode information about their users. As LLMs displace search engines as the interface to knowledge, understanding that product design (and its consequences) will be essential for navigating the legal, social, and political transitions from an information ecosystem that is curated to one that is generated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that partisan political identity is encoded as a single geometric axis in the activation space of Llama 3.1 8B Instruct at layer 18. Using linear probes trained on 190,491 party-labeled congressional tweets, it reports an AUC of 0.945 and Cohen's d of 1.94 for separating Republican from Democratic text. Sparse autoencoders decompose this axis into interpretable features, and mid-generation interventions along the axis produce causal shifts including stance reversals, register changes, and fabrications of authority. The work concludes that partisan bias is a steerable structural property of LLM representations rather than an emergent artifact.
Significance. If the central direction can be shown to isolate partisan identity rather than correlated topic or style signals, the result would provide a concrete, intervenable mechanism for how LLMs internalize and express political bias. The combination of high-AUC probing, SAE decomposition, and behavioral interventions offers a template for locating and controlling other high-level attributes in model space, with direct relevance to bias auditing, alignment, and interpretability research. The causal intervention step supplies an independent check beyond pure correlation.
major comments (3)
- [Methods (probe training subsection)] Methods (probe training subsection): The linear probe is fit directly to party labels on congressional tweets without reported topic-matched controls, content ablations, or style normalization. Congressional tweets differ systematically in policy focus and phrasing by party; absent these controls the reported AUC of 0.945 and subsequent intervention effects could reflect topic or register separation rather than partisan identity.
- [Intervention experiments] Intervention experiments: No quantitative comparison is provided between the observed output shifts and the shifts obtained by intervening along random directions of matched magnitude or along probes trained on non-partisan labels. Without such specificity tests it remains unclear whether the stance reversals and fabrications are attributable to the partisan axis rather than any sufficiently strong direction.
- [Sparse autoencoder decomposition] Sparse autoencoder decomposition: The SAE is applied to the partisan direction, yet the manuscript supplies no quantitative metrics (e.g., feature activation correlations with held-out partisan labels or ablation of individual SAE features) demonstrating that the extracted features are partisan rather than general political or stylistic. This weakens the interpretability claim that the axis decomposes into partisan features.
minor comments (2)
- [Abstract] Abstract contains the typo 'rapicly' (should be 'rapidly').
- [Methods] The manuscript does not report regularization strength, cross-validation procedure, or exact probe architecture (e.g., whether an L2 penalty or early stopping was used), which affects reproducibility of the AUC and Cohen's d values.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify areas where additional controls and quantitative specificity tests would strengthen the isolation of partisan identity from topic or style signals. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: Methods (probe training subsection): The linear probe is fit directly to party labels on congressional tweets without reported topic-matched controls, content ablations, or style normalization. Congressional tweets differ systematically in policy focus and phrasing by party; absent these controls the reported AUC of 0.945 and subsequent intervention effects could reflect topic or register separation rather than partisan identity.
Authors: We agree that the absence of explicit topic-matched controls and style normalization leaves open the possibility of confounds. The congressional tweet corpus does contain systematic differences in policy focus and phrasing by party. In the revised manuscript we will add a topic-matched subset analysis: we will curate pairs of tweets on identical policy issues (e.g., immigration, healthcare) from both parties, retrain and evaluate the probe on these subsets, and report the resulting AUC and Cohen's d. We will also include a style-normalized control using linguistic feature regression to residualize out register markers before probing. These additions will directly test whether the partisan direction remains after topic and style are controlled. revision: yes
-
Referee: Intervention experiments: No quantitative comparison is provided between the observed output shifts and the shifts obtained by intervening along random directions of matched magnitude or along probes trained on non-partisan labels. Without such specificity tests it remains unclear whether the stance reversals and fabrications are attributable to the partisan axis rather than any sufficiently strong direction.
Authors: The referee is correct that the current experiments lack explicit specificity controls against random or non-partisan directions. While the behavioral effects are politically coherent and directionally consistent with the probe labels, this does not yet rule out generic steering effects. In revision we will add two quantitative controls: (1) intervention along 100 random directions of matched norm at the same layer and compare output shift magnitude and political coherence; (2) training of control probes on non-partisan labels (e.g., positive/negative sentiment and topic category) and repeating the same ablation/amplification protocol. We will report statistical comparisons of effect sizes and qualitative differences in the resulting generations. These tests will be included in the revised intervention section. revision: yes
-
Referee: Sparse autoencoder decomposition: The SAE is applied to the partisan direction, yet the manuscript supplies no quantitative metrics (e.g., feature activation correlations with held-out partisan labels or ablation of individual SAE features) demonstrating that the extracted features are partisan rather than general political or stylistic. This weakens the interpretability claim that the axis decomposes into partisan features.
Authors: We acknowledge that the current SAE analysis is primarily qualitative. The manuscript presents example features but does not supply correlation or ablation statistics against held-out partisan labels. In the revised version we will add: (i) Pearson correlations between each extracted SAE feature's activation and held-out party labels on a validation set of tweets; (ii) feature-ablation experiments measuring the drop in probe AUC when individual SAE features are zeroed; and (iii) comparison against SAE features extracted from a non-partisan control direction. These metrics will be reported to quantify how partisan-specific the decomposed features are. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains linear probes on activations from 190k party-labeled congressional tweets to recover a direction (layer 18, AUC 0.945), decomposes it via SAE, and then performs independent causal interventions during generation to measure output shifts. The intervention results constitute an external behavioral test not entailed by the probe fit. No steps match the enumerated circularity patterns: the AUC is the direct performance metric of the supervised probe rather than a renamed prediction, there are no self-citations, no uniqueness theorems, and no ansatz smuggling. The central causal claims rest on the intervention experiments, which are not forced by construction from the labeling scheme.
Axiom & Free-Parameter Ledger
free parameters (2)
- linear probe weights
- intervention coefficient
axioms (2)
- domain assumption Hidden-state activations at a single layer contain a linearly extractable representation of partisan identity
- domain assumption Congressional tweets provide a representative sample of partisan language without dominant topic or stylistic confounds
invented entities (1)
-
partisan direction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, Guillaume and Yoshua Bengio. 2018. “Understanding intermediate layers using linear classifier probes.”. URL:https://arxiv.org/abs/1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Out of One, Many: Using Language Models to Simulate Human Samples
Argyle, Lisa P ., Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting and David Wingate. 2023. “Out of One, Many: Using Language Models to Simulate Human Samples.”Political Analysis31(3):337–351
2023
-
[3]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. 2022. “Probing Classifiers: Promises, Shortcomings, and Advances.”Com- putational Linguistics48(1):207–219
2022
-
[4]
Bricken, Trenton, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan and Chris Olah
-
[5]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learn- ing
“Towards Monosemanticity: Decomposing Language Models With Dictionary Learn- ing.”Anthropic. URL:https://transformer-circuits.pub/2023/monosemantic-features
2023
-
[6]
Designing a Dashboard for Transparency and Control of Conversational AI
Chen, Yida, Aoyu Wu, Trevor DePodesta, Catherine Yeh, Kenneth Li, Nicholas Castillo Marin, Oam Patel, Jan Riecke, Shivam Raval, Olivia Seow, Martin Wattenberg and Fernanda Viégas. 2024. “Designing a Dashboard for Transparency and Control of Conversational AI.”. URL:https://arxiv.org/abs/2406.07882
-
[7]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, Hoagy, Aidan Ewart, Logan Riggs, Robert Huben and Lee Sharkey. 2023. “Sparse Autoencoders Find Highly Interpretable Features in Language Models.”. URL:https://arxiv.org/abs/2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Toy Models of Superposition
Elhage, Nelson, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg and Christopher Olah. 2022. “Toy Models of Superposition.”Transformer Circuits Thread. Anthropic. URL:https://transformer-cir...
2022
-
[9]
Feng, Shangbin, Chan Young Park, Yuhan Liu and Yulia Tsvetkov. 2023. From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Lead- ing to Unfair NLP Models. InProceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers). pp. 11737–11762
2023
-
[10]
Scaling and evaluating sparse autoencoders
Gao, Leo, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike and Jeffrey Wu. 2024. “Scaling and evaluating sparse autoencoders.”. URL:https://arxiv.org/abs/2406.04093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Finding Neurons in a Haystack: Case Studies with Sparse Probing
Gurnee, Wes, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii and Dimitris Bertsimas. 2023. “Finding Neurons in a Haystack: Case Studies with Sparse Probing.”. URL:https://arxiv.org/abs/2305.01610 REFERENCES 16
-
[12]
Survey of Hallucination in Natural Language Generation
Ji, Ziwei, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto and Pascale Fung. 2023. “Survey of Hallucination in Natural Language Generation.”ACM Computing Surveys55(12):1–38
2023
-
[13]
Linear Representations of Political Per- spective Emerge in Large Language Models
Kim, Junsol, James Evans and Aaron Schein. 2025. “Linear Representations of Political Per- spective Emerge in Large Language Models.”. URL:https://arxiv.org/abs/2503.02080
-
[14]
Kotek, Hadas, Rikker Dockum and David Q. Sun. 2023. Gender bias and stereotypes in Large Language Models. InCI ’23: Proceedings of The ACM Collective Intelligence Conference. pp. 12– 24
2023
-
[15]
Li, Kenneth, Oam Patel, Fernanda Viégas, Hanspeter Pfister and Martin Wattenberg. 2023. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model. InAdvances in Neural Information Processing Systems, ed. A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt and S. Levine. Vol. 36 pp. 41451–41530
2023
-
[16]
Marks, Samuel and Max Tegmark. 2024. “The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets.”. URL:https://arxiv.org/abs/2310.06824
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
More Human than Hu- man: Measuring ChatGPT Political Bias
Motoki, Fabio, Valdemar Pinho Neto and Victor Rodrigues. 2024. “More Human than Hu- man: Measuring ChatGPT Political Bias.”Public Choice198:3–23
2024
-
[18]
Park, Kiho, Yo Joong Choe and Victor Veitch. 2024. The Linear Representation Hypothesis and the Geometry of Large Language Models. InProceedings of the 41st International Conference on Machine Learning. Vol. 235 PMLR pp. 39643–39666
2024
-
[19]
The Psychology of Fake News
Pennycook, Gordon and David G. Rand. 2021. “The Psychology of Fake News.”Trends in Cognitive Sciences25(5):388–402
2021
-
[20]
2007.Post-Broadcast Democracy: How Media Choice Increases Inequality in Political Involvement and Polarizes Elections
Prior, Markus. 2007.Post-Broadcast Democracy: How Media Choice Increases Inequality in Political Involvement and Polarizes Elections. Cambridge University Press
2007
-
[21]
Algorithmic Speech
Procaccini, Francesca and Wendy K. Tam. 2027. “Algorithmic Speech.”California Law Review 115
2027
-
[22]
Rimsky, Nina, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger and Alexander Turner. 2024. Steering Llama 2 via Contrastive Activation Addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, ed. Lun-Wei Ku, Andre Martins and Vivek Srikumar...
2024
-
[23]
The Political Preferences of LLMs
Rozado, David. 2024. “The Political Preferences of LLMs.”PLOS One19(7):e0306621
2024
-
[24]
Santurkar, Shibani, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang and Tatsunori Hashimoto. 2023. Whose Opinions Do Language Models Reflect? InProceedings of the 40th In- ternational Conference on Machine Learning, ed. Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato and Jonathan Scarlett. Vol. 202 ofProceedings of Ma- c...
2023
-
[25]
Sharma, Mrinank, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin DURMUS, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, Timo- thy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang and Ethan Perez. 2024. Towards Understanding Sycophancy in Language Models. InInternational ...
2024
-
[26]
2017.#Republic: Divided Democracy in the Age of Social Media.Princeton University Press
Sunstein, Cass R. 2017.#Republic: Divided Democracy in the Age of Social Media.Princeton University Press
2017
-
[27]
Steering Language Models With Activation Engineering
Turner, Alexander Matt, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini and Monte MacDiarmid. 2024. “Steering Language Models With Activation Engineer- ing.”. URL:https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.