Scaling Decision-Focused Learning to Large Problems with Lagrangian Decomposition
Pith reviewed 2026-06-27 18:34 UTC · model grok-4.3
The pith
Lagrangian decomposition scales decision-focused learning to instances with eight times more variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
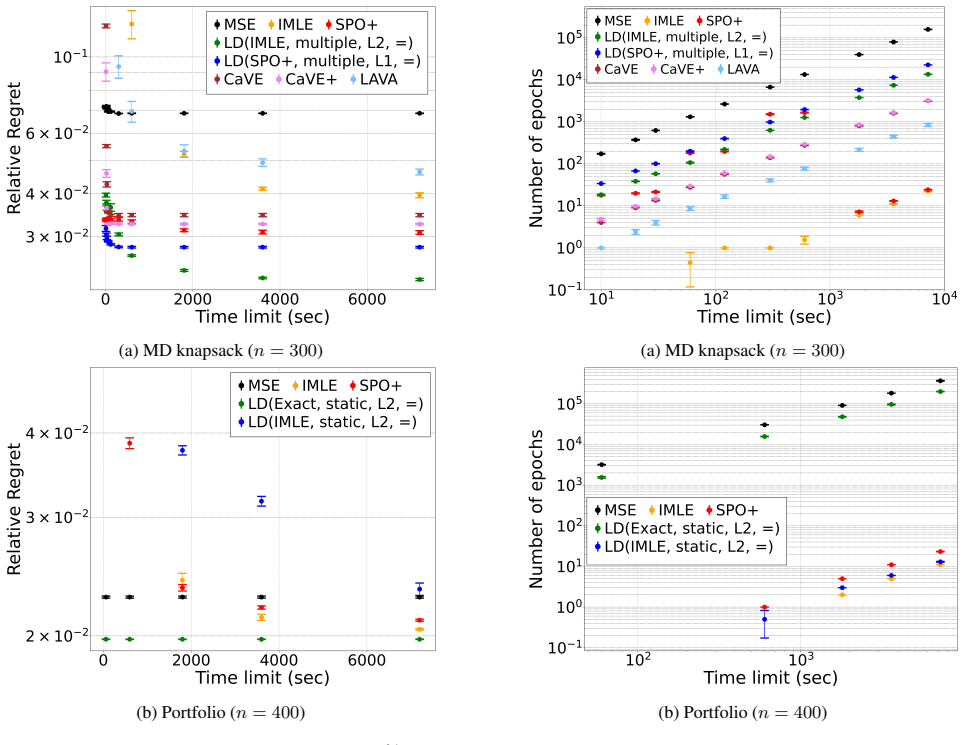
Lagrangian decomposition of the inner constrained optimization produces a separable surrogate objective that supports two new loss functions for decision-focused training. The resulting framework integrates directly with standard methods including SPO+ and IMLE, achieves competitive performance on the multi-dimensional knapsack and quadratic portfolio benchmarks, and extends to instances involving up to eight times more variables than those typically considered in related work.
What carries the argument
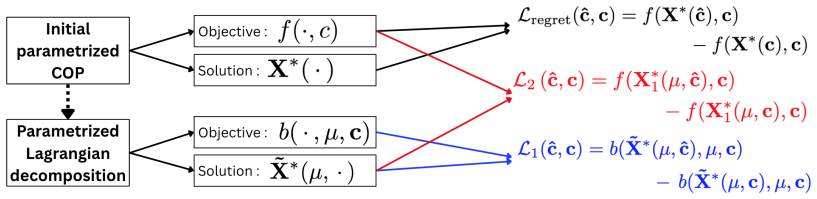
Lagrangian decomposition applied to the inner optimization problem, which creates a surrogate objective and the two associated loss functions used for training the prediction model.
If this is right
- The framework integrates directly with standard decision-focused learning methods including SPO+ and IMLE.
- Training becomes amenable to parallelization across the decomposed subproblems.
- The approach achieves competitive or better decision quality on multi-dimensional knapsack and quadratic portfolio problems.
- It extends to instances with up to eight times more variables than those used in prior work.
Where Pith is reading between the lines
- The parallel structure could support distributed training on clusters or GPUs for even larger problems.
- The surrogate may reduce dependence on exact solvers during training, enabling use in environments where only approximate or heuristic solvers are available.
- Similar decomposition techniques could transfer to other predict-then-optimize settings where Lagrangian methods already work well.
Load-bearing premise
The surrogate objective obtained from Lagrangian decomposition remains a sufficiently faithful proxy for the original constrained optimization problem when used inside the training loop of the prediction model.
What would settle it
On a large instance, if models trained with the decomposed losses produce final decisions whose quality falls materially below those from full-optimization DFL or from a plain predict-then-optimize baseline, the claim that the surrogate enables reliable scaling would be falsified.
Figures
read the original abstract
Decision-focused learning has shown great promise for addressing predict-then-optimize problems, particularly in the presence of under-specified models. However, its practical deployment is often hindered by high computational costs and limited scalability, as it requires solving a constrained optimization problem for each training instance at every iteration. To address these challenges, we propose a novel framework that incorporates Lagrangian decomposition into the decision-focused learning paradigm. Specifically, we introduce a new surrogate objective along with two loss functions for evaluating and training the underlying prediction model. We further propose two variants of our approach, which offer different trade-offs between computational efficiency and solution quality. Our framework can be seamlessly integrated with standard decision-focused learning methods, including Smart Predict-then-Optimize (SPO+) and Implicit Maximum Likelihood Estimation (IMLE). Through experiments on two standard benchmarks, the multi-dimensional knapsack problem and quadratic portfolio optimization, we demonstrate that our approach achieves competitive performance while remaining amenable to parallelization. In particular, it consistently outperforms traditional decision-focused learning methods on large-scale instances, involving up to eight times more variables than those typically considered in related work. The implementation is available at https://github.com/corail-research/DFL-LD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework that integrates Lagrangian decomposition into decision-focused learning (DFL) to improve scalability. It defines a new surrogate objective derived from the decomposed Lagrangian, along with two associated loss functions, and shows how these can be combined with existing DFL methods such as SPO+ and IMLE. Experiments on the multi-dimensional knapsack problem and quadratic portfolio optimization report competitive performance on instances up to eight times larger than those in prior work, with an open-source implementation provided.
Significance. If the surrogate losses produce training signals whose argmin aligns with that of the original constrained problem, the approach could meaningfully extend DFL to larger practical instances while retaining the ability to parallelize subproblems. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [§3.2] §3.2 (surrogate objective definition): the two new loss functions are obtained by substituting the Lagrangian relaxation into the DFL training loop, yet no bound or empirical characterization is given for the duality gap that arises in the integer multi-dimensional knapsack subproblems; without this, it is unclear whether the surrogate and original objectives share the same argmin over the prediction space.
- [§4.2, Table 3] §4.2 and Table 3 (large-scale knapsack results): the reported outperformance versus standard SPO+ and IMLE on instances with 8× more variables is presented as point estimates only; the absence of variance across random seeds or statistical tests leaves open whether the gains are robust to the varying duality gaps across training instances.
minor comments (2)
- [§3.3] Notation for the two loss functions (L_LD and L_LD-IMLE) is introduced without an explicit side-by-side comparison of their computational and statistical properties.
- [Abstract] The abstract states that the framework 'can be seamlessly integrated' with SPO+ and IMLE, but the integration steps are only sketched at a high level; a short pseudocode block would clarify the required modifications to the original DFL pipelines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, explaining our position and planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (surrogate objective definition): the two new loss functions are obtained by substituting the Lagrangian relaxation into the DFL training loop, yet no bound or empirical characterization is given for the duality gap that arises in the integer multi-dimensional knapsack subproblems; without this, it is unclear whether the surrogate and original objectives share the same argmin over the prediction space.
Authors: We thank the referee for this observation. The Lagrangian decomposition is introduced precisely to obtain a tractable surrogate that admits parallel subproblem solves while preserving the decision-focused training loop. Although the integer knapsack subproblems admit a nonzero duality gap in general, the surrogate objective is constructed so that its gradient signal with respect to the predictions remains informative for improving downstream decisions; this is supported by the consistent outperformance on large instances. We acknowledge that a theoretical characterization of when the argmins coincide is not provided. In the revision we will add an empirical study reporting the observed duality gaps (and their variation) across training instances and problem sizes. revision: yes
-
Referee: [§4.2, Table 3] §4.2 and Table 3 (large-scale knapsack results): the reported outperformance versus standard SPO+ and IMLE on instances with 8× more variables is presented as point estimates only; the absence of variance across random seeds or statistical tests leaves open whether the gains are robust to the varying duality gaps across training instances.
Authors: We agree that variance estimates and statistical tests would strengthen the presentation. The current results are reported as single-run point estimates because the primary focus was demonstrating scalability on instances eight times larger than prior work. In the revised manuscript we will rerun the large-scale experiments over multiple random seeds, report means and standard deviations, and include paired statistical tests to confirm that the observed improvements remain significant despite instance-to-instance variation in duality gaps. revision: yes
Circularity Check
No significant circularity; extension of external DFL methods via standard Lagrangian decomposition
full rationale
The paper defines a surrogate objective and two new loss functions by applying Lagrangian decomposition (a classical optimization technique) to the predict-then-optimize setting. These are then integrated with the externally cited SPO+ and IMLE frameworks. No equation reduces a claimed prediction or performance gain to a parameter fitted inside the paper, nor does any load-bearing premise rest on a self-citation chain. The derivation chain remains self-contained against external benchmarks and standard mathematical results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The underlying optimization problems admit a Lagrangian decomposition whose dual provides a usable surrogate for the original objective during training.
Reference graph
Works this paper leans on
-
[1]
Doge-train: Discrete optimization on gpu with end- to-end training
[Abbas and Swoboda, 2024] Ahmed Abbas and Paul Swo- boda. Doge-train: Discrete optimization on gpu with end- to-end training. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 20623–20631,
2024
-
[2]
Zico Kolter
[Amos and Kolter, 2017] Brandon Amos and J. Zico Kolter. OptNet: differentiable optimization as a layer in neural networks.Proceedings of the 34th International Confer- ence on Machine Learning - Volume 70, pages 136–145,
2017
-
[3]
[Berdenet al., 2025 ] Senne Berden, Ali ˙Irfan Mah- muto˘gulları, Dimos Tsouros, and Tias Guns. Solver-free decision-focused learning for linear optimization prob- lems.arXiv preprint arXiv:2505.22224,
-
[4]
Learning valid dual bounds in constraint programming: Boosted lagrangian decomposition with self-supervised learning
[Bessaet al., 2025 ] Swann Bessa, Darius Dabert, Max Bourgeat, Louis-Martin Rousseau, and Quentin Cappart. Learning valid dual bounds in constraint programming: Boosted lagrangian decomposition with self-supervised learning. InProceedings of the AAAI Conference on Arti- ficial Intelligence, volume 39, pages 11113–11121,
2025
-
[5]
Scalable coupling of deep learning with logical reasoning,
[Defresneet al., 2023 ] Marianne Defresne, Sophie Barbe, and Thomas Schiex. Scalable coupling of deep learning with logical reasoning,
2023
-
[6]
predict, then optimize
[Elmachtoub and Grigas, 2021] Adam N. Elmachtoub and Paul Grigas. Smart “predict, then optimize”.Manage. Sci., 68(1):9–26, January
2021
-
[7]
Elmachtoub, Henry Lam, Haofeng Zhang, and Yunfan Zhao
[Elmachtoubet al., 2023 ] Adam N. Elmachtoub, Henry Lam, Haofeng Zhang, and Yunfan Zhao. Estimate-then- optimize versus integrated-estimation-optimization versus sample average approximation: A stochastic dominance perspective,
2023
-
[8]
and Lam, Henry and Zhang, Haofeng and Zhao, Yunfan , date =
eprint: 2304.06833. [Gouldet al., 2016 ] Stephen Gould, Basura Fernando, Anoop Cherian, Peter Anderson, Rodrigo Santa Cruz, and Edison Guo. On differentiating parameterized argmin and argmax problems with application to bi-level optimization.arXiv preprint arXiv:1607.05447,
-
[9]
Lagrangean decomposition: A model yielding stronger lagrangean bounds.Mathematical programming, 39(2):215–228,
[Guignard and Kim, 1987] Monique Guignard and Siwhan Kim. Lagrangean decomposition: A model yielding stronger lagrangean bounds.Mathematical programming, 39(2):215–228,
1987
-
[10]
Gurobi Optimizer Reference Manual,
[Gurobi Optimization, LLC, 2024] Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual,
2024
-
[11]
General bounding mech- anism for constraint programs
[H`aet al., 2015 ] Minh Ho `ang H `a, Claude-Guy Quimper, and Louis-Martin Rousseau. General bounding mech- anism for constraint programs. In Gilles Pesant, edi- tor,Principles and Practice of Constraint Programming, pages 158–172. Springer International Publishing,
2015
-
[12]
Smart predict-and-optimize for hard combina- torial optimization problems
[Mandiet al., 2020 ] Jayanta Mandi, Peter J Stuckey, Tias Guns, et al. Smart predict-and-optimize for hard combina- torial optimization problems. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 1603–1610,
2020
-
[13]
Decision-focused learning: Foundations, state of the art, benchmark and future op- portunities.Journal of Artificial Intelligence Research, 80:1623–1701,
[Mandiet al., 2024 ] Jayanta Mandi, James Kotary, Senne Berden, Maxime Mulamba, Victor Bucarey, Tias Guns, and Ferdinando Fioretto. Decision-focused learning: Foundations, state of the art, benchmark and future op- portunities.Journal of Artificial Intelligence Research, 80:1623–1701,
2024
-
[14]
Implicit MLE: backpropagating through discrete exponential family distributions
[Niepertet al., 2021 ] Mathias Niepert, Pasquale Minervini, and Luca Franceschi. Implicit MLE: backpropagating through discrete exponential family distributions. InPro- ceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21. Curran Asso- ciates Inc.,
2021
-
[15]
Learning lagrangian multipliers for the travelling sales- man problem
[Parjadiset al., 2024 ] Augustin Parjadis, Quentin Cappart, Bistra Dilkina, Aaron Ferber, and Louis-Martin Rousseau. Learning lagrangian multipliers for the travelling sales- man problem. In30th International Conference on Princi- ples and Practice of Constraint Programming (CP 2024), pages 22–1. Schloss Dagstuhl–Leibniz-Zentrum f¨ur Infor- matik,
2024
-
[16]
Pytorch: An imperative style, high- performance deep learning library
[Paszkeet al., 2019 ] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An impera...
2019
-
[17]
[Shor, 2012] Naum Zuselevich Shor.Minimization methods for non-differentiable functions, volume
2012
-
[18]
[Tang and Khalil, 2024b] Bo Tang and Elias B Khalil
Springer Nature Switzerland. [Tang and Khalil, 2024b] Bo Tang and Elias B Khalil. PyEPO: a PyTorch-based end-to-end predict-then- optimize library for linear and integer programming. Mathematical Programming Computation, 16(3):297– 335, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.