Generalization in Nonlinear Least Squares via Learned Feature Geometry
Pith reviewed 2026-06-27 17:42 UTC · model grok-4.3
The pith
Generalization error bounds for nonlinear least squares depend on the geometry of the trained Jacobian rather than parameter count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For ridge-regularized nonlinear least squares, the generalization error of any local minimizer is bounded by a term whose leading factor is the effective dimension trace((J^T J + lambda I)^{-1} J^T J) plus a residual-curvature correction, where J is the Jacobian of the model evaluated at the trained parameters; this quantity is data-dependent and reflects the geometry of the learned gradient features rather than the ambient parameter dimension.
What carries the argument
The empirical Jacobian Gram matrix at the trained parameters, which defines a data-dependent effective dimension together with the residual-curvature term.
If this is right
- In the linear case the bound recovers the classical effective dimension evaluated at the trained model instead of at initialization.
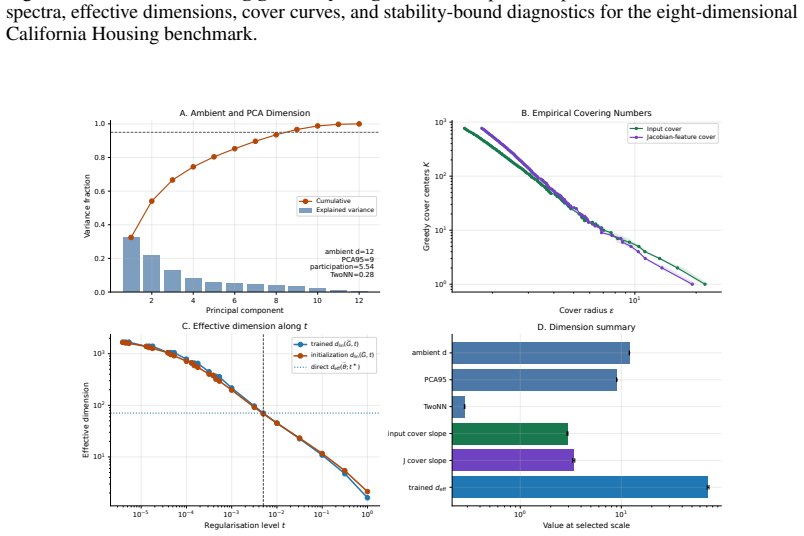
- For data supported on a manifold and piecewise Lipschitz Jacobians the bound scales with intrinsic rather than ambient dimension.
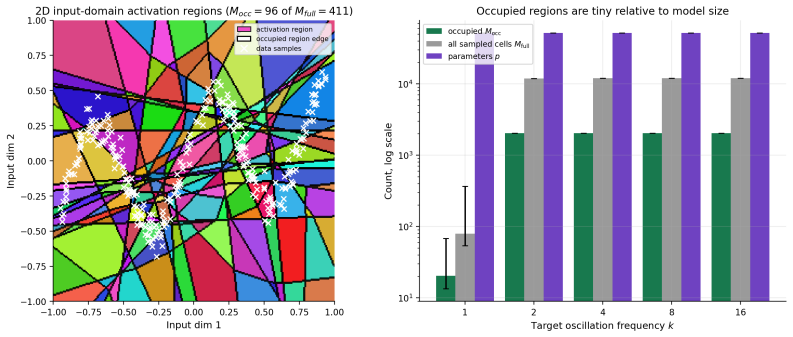
- For one-hidden-layer ReLU networks the bound can be expressed explicitly in terms of the number of activation-stable regions.
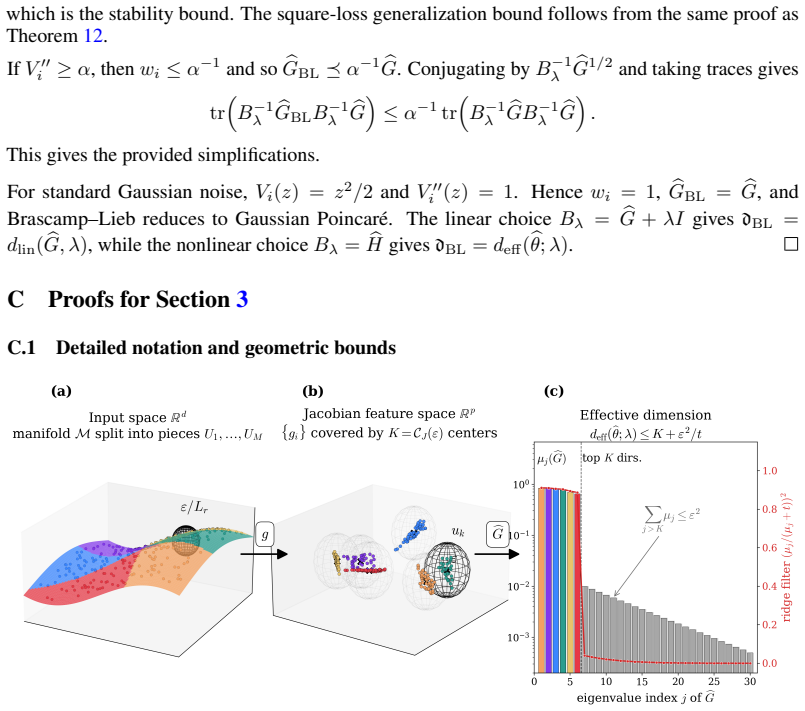
- The effective dimension itself can be upper-bounded by the covering complexity of the gradient features.
- The bounds are obtained directly from first-principles stability arguments without reference to uniform convergence.
Where Pith is reading between the lines
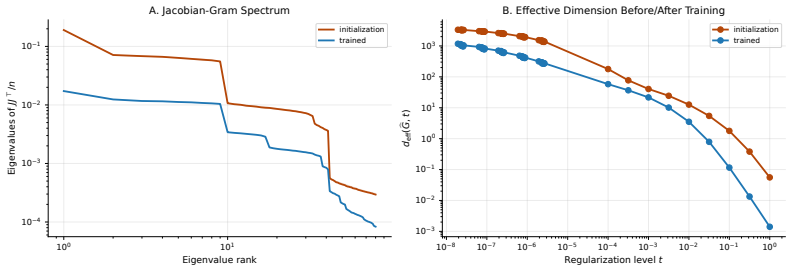
- Training procedures that compress the rank or condition number of the trained Jacobian would be expected to improve the generalization bound.
- The same stability-plus-Jacobian approach could be applied to other convex or locally convex losses beyond squared loss.
- On clustered or low-dimensional data the observed compression of the Jacobian Gram matrix during training should correlate with the size of the generalization gap.
Load-bearing premise
The noise distribution must be strongly log-concave so that the Brascamp-Lieb inequality can be applied to the stability analysis.
What would settle it
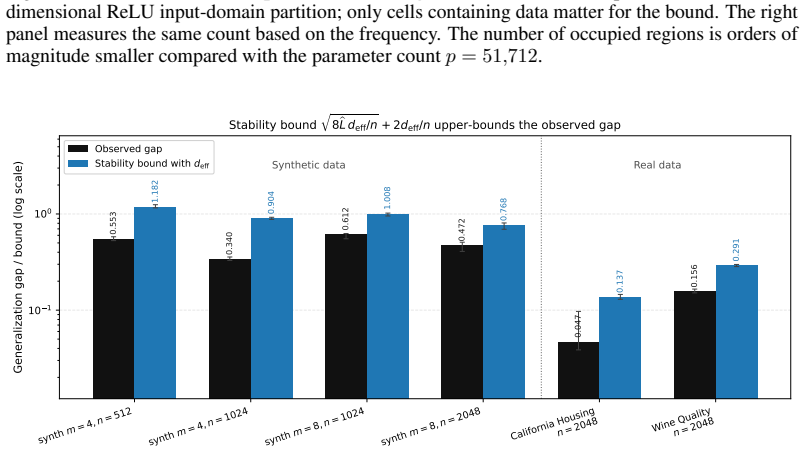
Compute the proposed stability bound on a dataset where the noise is known to be strongly log-concave and check whether the observed generalization gap exceeds the bound by more than a small constant factor across multiple random seeds.
Figures




read the original abstract
We study the generalization of ridge-regularized nonlinear least-squares models via on-average algorithmic stability, deriving error bounds for local minimizers in terms of a data-dependent effective dimension that reflects the geometry of the gradient model at the trained parameters, through the empirical Jacobian Gram matrix and a residual-curvature term. In the linear case, where the curvature term vanishes, this recovers the classical effective dimension of the Jacobian kernel covariance, but evaluated at the trained model rather than at initialization as is typical in neural tangent kernel analyses. We further bound this effective dimension via covering complexity of the gradient features, leading to guarantees that depend on learned geometry rather than parameter count. In particular, for manifold-supported data and piecewise Lipschitz Jacobians, the bounds scale with intrinsic dimension, while for one-hidden-layer ReLU networks, the mechanism can be made explicit through counts of activation-stable regions. Experiments on synthetic manifolds, clustered distributions, and benchmark datasets illustrate trained-Jacobian compression, the tightness of the residual-curvature linearization, and agreement between the stability bound and observed generalization gaps. A key feature of our bounds is the simplicity of their derivation, which follows from first principles using the Brascamp-Lieb inequality under strongly log-concave noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives on-average algorithmic stability bounds for generalization of ridge-regularized nonlinear least-squares models at local minimizers. The bounds are expressed via a data-dependent effective dimension constructed from the empirical Jacobian Gram matrix plus a residual-curvature term evaluated at the trained parameters. The derivation proceeds from first principles via the Brascamp-Lieb inequality under strongly log-concave noise; the linear case recovers the classical Jacobian-kernel effective dimension (now at the trained point), while nonlinear cases are further bounded via covering numbers of the gradient features. Experiments on synthetic manifolds, clustered data, and benchmarks illustrate Jacobian compression, residual-curvature linearization tightness, and numerical agreement between the stability bound and observed gaps.
Significance. If the derivation is valid, the work supplies a simple, first-principles stability analysis that ties generalization directly to learned feature geometry rather than parameter count or initialization. The explicit recovery of classical effective-dimension results and the geometry-based scaling (intrinsic dimension for manifold data, activation-region counts for ReLU networks) are concrete strengths. The use of Brascamp-Lieb under the stated noise assumption is a clean technical route when the assumption holds.
major comments (1)
- [Abstract / derivation section] Abstract and derivation (Brascamp-Lieb application): the central stability bound for local minimizers is obtained only when the negative log-likelihood plus ridge term induces a strongly log-concave measure, which requires the noise distribution itself to be strongly log-concave. This excludes standard least-squares noise models (Laplace, uniform, or any log-concave but not strongly log-concave density) for which the inequality does not deliver the claimed finite, data-dependent bound; the guarantees are therefore conditional on an assumption that is not satisfied by many practical residual distributions.
minor comments (2)
- Notation: the effective dimension is defined from the trained Jacobian Gram matrix; a short remark clarifying that this quantity is computed post-training (and is therefore not available before optimization) would help readers distinguish it from NTK-style quantities evaluated at initialization.
- Experiments: the synthetic-manifold and ReLU-network sections would benefit from an explicit statement of how the residual-curvature term is estimated in practice and whether its magnitude is reported relative to the Jacobian term.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the scope of the noise assumption in our derivation. We address the major comment below and propose targeted revisions to improve clarity without altering the technical contribution.
read point-by-point responses
-
Referee: [Abstract / derivation section] Abstract and derivation (Brascamp-Lieb application): the central stability bound for local minimizers is obtained only when the negative log-likelihood plus ridge term induces a strongly log-concave measure, which requires the noise distribution itself to be strongly log-concave. This excludes standard least-squares noise models (Laplace, uniform, or any log-concave but not strongly log-concave density) for which the inequality does not deliver the claimed finite, data-dependent bound; the guarantees are therefore conditional on an assumption that is not satisfied by many practical residual distributions.
Authors: We agree that the central bound relies on strong log-concavity of the noise distribution to apply the Brascamp-Lieb inequality and obtain a finite, data-dependent stability guarantee. This assumption is stated in the abstract and derivation section. The manuscript focuses on the Gaussian case (which satisfies strong log-concavity) as the canonical model for least-squares residuals, but the referee is correct that the result does not automatically extend to merely log-concave densities such as Laplace or uniform. We will revise the abstract to foreground the assumption more explicitly and add a short paragraph in the introduction and conclusion discussing its scope, including that extensions to other log-concave noises would require different concentration tools. This does not change the validity of the existing derivation under the stated condition. revision: yes
Circularity Check
No circularity; bounds derived independently via stability and Brascamp-Lieb
full rationale
The paper derives on-average algorithmic stability bounds for local minimizers of the ridge-regularized nonlinear least-squares objective using the Brascamp-Lieb inequality applied to the posterior under strongly log-concave noise. The data-dependent effective dimension (Jacobian Gram matrix plus residual-curvature term) appears as an explicit term in the resulting generalization bound rather than being fitted to the gap or defined in terms of the bound itself. No self-citations, ansatzes, or renamings are invoked as load-bearing steps in the provided text; the derivation is stated to follow from first principles. The central claim therefore remains independent of its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Brascamp-Lieb inequality holds for the noise distribution
Reference graph
Works this paper leans on
-
[1]
Bartlett.Neural network learning: Theoretical foundations
Martin Anthony and Peter L. Bartlett.Neural network learning: Theoretical foundations. Cambridge University Press, 1999
1999
-
[2]
On Exact Computation with an Infinitely Wide Neural Net
Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. On Exact Computation with an Infinitely Wide Neural Net. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[3]
Random Fourier Features for Kernel Ridge Regression: Approximation Bounds and Statistical Guarantees
Haim Avron, Michael Kapralov, Cameron Musco, Christopher Musco, Ameya Velingker, and Amir Zandieh. Random Fourier Features for Kernel Ridge Regression: Approximation Bounds and Statistical Guarantees. InInternational Conference on Machine Learning (ICML), volume 70 ofProceedings of Machine Learning Research, pages 253–262. PMLR, 2017
2017
-
[4]
Sharp analysis of low-rank kernel matrix approximations
Francis Bach. Sharp analysis of low-rank kernel matrix approximations. InProceedings of the 26th Annual Conference on Learning Theory, volume 30 ofProceedings of Machine Learning Research, pages 185–209, Princeton, NJ, USA, 12–14 Jun 2013. PMLR
2013
-
[5]
Baraniuk
Randall Balestriero and Richard G. Baraniuk. A Spline Theory of Deep Learning. InProceed- ings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 374–383. PMLR, 2018
2018
-
[6]
Bartlett, Dylan J
Peter L. Bartlett, Dylan J. Foster, and Matus Telgarsky. Spectrally-Normalized Margin Bounds for Neural Networks. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[7]
Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian
Peter L. Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian. Nearly-tight VC- dimension and pseudodimension bounds for piecewise linear neural networks.Journal of Machine Learning Research, 20(63):1–17, 2019
2019
-
[8]
Bartlett, Philip M
Peter L. Bartlett, Philip M. Long, Gábor Lugosi, and Alexander Tsigler. Benign Overfitting in Linear Regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
2020
-
[9]
Bartlett and Shahar Mendelson
Peter L. Bartlett and Shahar Mendelson. Rademacher and Gaussian Complexities: Risk Bounds and Structural Results.Journal of Machine Learning Research, 3:463–482, 2002
2002
-
[10]
Stability of Stochastic Gradient Descent on Nonsmooth Convex Losses
Raef Bassily, Vitaly Feldman, Cristóbal Guzmán, and Kunal Talwar. Stability of Stochastic Gradient Descent on Nonsmooth Convex Losses. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 4381–4391. Curran Associates, Inc., 2020
2020
-
[11]
Reconciling modern machine- learning practice and the classical bias–variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019
Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine- learning practice and the classical bias–variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019
2019
-
[12]
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation.Neural Computation, 15(6):1373–1396, 2003
Mikhail Belkin and Partha Niyogi. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation.Neural Computation, 15(6):1373–1396, 2003
2003
-
[13]
Towards a Theoretical Foundation for Laplacian-Based Manifold Methods.Journal of Computer and System Sciences, 74(8):1289–1308, 2008
Mikhail Belkin and Partha Niyogi. Towards a Theoretical Foundation for Laplacian-Based Manifold Methods.Journal of Computer and System Sciences, 74(8):1289–1308, 2008
2008
-
[14]
Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples.Journal of Machine Learning Research, 7:2399–2434, 2006
Mikhail Belkin, Partha Niyogi, and Vikas Sindhwani. Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples.Journal of Machine Learning Research, 7:2399–2434, 2006
2006
-
[15]
Bickel and Bo Li
Peter J. Bickel and Bo Li. Local Polynomial Regression on Unknown Manifolds. InComplex Datasets and Inverse Problems: Tomography, Networks and Beyond, volume 54 ofIMS Lecture Notes–Monograph Series, pages 177–186. Institute of Mathematical Statistics, 2007. 10
2007
-
[16]
Simplicity Bias and Optimization Threshold in Two-Layer ReLU Networks
Etienne Boursier and Nicolas Flammarion. Simplicity Bias and Optimization Threshold in Two-Layer ReLU Networks. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 5241–5275. PMLR, 13–19 Jul 2025
2025
-
[17]
Stability and generalization.Journal of Machine Learning Research, 2(Mar):499–526, 2002
Olivier Bousquet and André Elisseeff. Stability and generalization.Journal of Machine Learning Research, 2(Mar):499–526, 2002
2002
-
[18]
Herm Jan Brascamp and Elliott H Lieb. On extensions of the Brunn-Minkowski and Prékopa- Leindler theorems, including inequalities for log concave functions, and with an application to the diffusion equation.Journal of Functional Analysis, 22(4):366–389, 1976
1976
-
[19]
Fractal structure and generalization properties of stochastic optimization algorithms.Advances in Neural Information Processing Systems, 34:18774–18788, 2021
Alexander Camuto, George Deligiannidis, Murat A Erdogdu, Mert Gurbuzbalaban, Umut Simsekli, and Lingjiong Zhu. Fractal structure and generalization properties of stochastic optimization algorithms.Advances in Neural Information Processing Systems, 34:18774–18788, 2021
2021
-
[20]
Generalization Bounds of Stochastic Gradient Descent for Wide and Deep Neural Networks
Yuan Cao and Quanquan Gu. Generalization Bounds of Stochastic Gradient Descent for Wide and Deep Neural Networks. InAdvances in Neural Information Processing Systems, 2019
2019
-
[21]
Optimal Rates for the Regularized Least-Squares Algorithm.Foundations of Computational Mathematics, 7(3):331–368, 2007
Andrea Caponnetto and Ernesto De Vito. Optimal Rates for the Regularized Least-Squares Algorithm.Foundations of Computational Mathematics, 7(3):331–368, 2007
2007
-
[22]
Cambridge University Press, Cambridge, 1990
Bernd Carl and Irmtraud Stephani.Entropy, Compactness and the Approximation of Operators. Cambridge University Press, Cambridge, 1990
1990
-
[23]
Carlen, Dario Cordero-Erausquin, and Elliott H
Eric A. Carlen, Dario Cordero-Erausquin, and Elliott H. Lieb. Asymmetric covariance estimates of Brascamp-Lieb type and related inequalities for log-concave measures.Annales de l’I.H.P . Probabilités et statistiques, 49(1):1–12, 2013
2013
-
[24]
Stability and generalization of learning algorithms that converge to global optima
Zachary Charles and Dimitris Papailiopoulos. Stability and generalization of learning algorithms that converge to global optima. InInternational Conference on Machine Learning (ICML), pages 745–754. PMLR, 2018
2018
-
[25]
Minshuo Chen, Haoming Jiang, Wenjing Liao, and Tuo Zhao. Nonparametric Regression on Low-Dimensional Manifolds Using Deep ReLU Networks: Function Approximation and Statistical Recovery.Information and Inference: A Journal of the IMA, 11(4):1203–1253, 2022
2022
-
[26]
Local Linear Regression on Manifolds and Its Geometric Interpretation.Journal of the American Statistical Association, 108(504):1421–1434, 2013
Ming-Yen Cheng and Hau-Tieng Wu. Local Linear Regression on Manifolds and Its Geometric Interpretation.Journal of the American Statistical Association, 108(504):1421–1434, 2013
2013
-
[27]
On Lazy Training in Differentiable Programming
Lénaïc Chizat, Edouard Oyallon, and Francis Bach. On Lazy Training in Differentiable Programming. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[28]
Coifman and Stéphane Lafon
Ronald R. Coifman and Stéphane Lafon. Diffusion Maps.Applied and Computational Harmonic Analysis, 21(1):5–30, 2006
2006
-
[29]
Cerdeira, F
Paulo Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis. Wine Quality. UCI Machine Learning Repository, 2009. Dataset
2009
-
[30]
Donoho and Carrie Grimes
David L. Donoho and Carrie Grimes. Hessian Eigenmaps: Locally Linear Embedding Techniques for High-Dimensional Data.Proceedings of the National Academy of Sciences, 100(10):5591–5596, 2003
2003
-
[31]
Gradient descent finds global minima of deep neural networks
Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. volume 97 ofProceedings of Machine Learning Research, pages 1675–1685. PMLR, 09–15 Jun 2019
2019
-
[32]
Richard M. Dudley. The Sizes of Compact Subsets of Hilbert Space and Continuity of Gaussian Processes.Journal of Functional Analysis, 1(3):290–330, 1967
1967
-
[33]
Dudley.Uniform Central Limit Theorems
Richard M. Dudley.Uniform Central Limit Theorems. Cambridge University Press, Cambridge, 1999. 11
1999
-
[34]
Uniform gener- alization bounds on data-dependent hypothesis sets via PAC-Bayesian theory on random sets
Benjamin Dupuis, Paul Viallard, George Deligiannidis, and Umut Simsekli. Uniform gener- alization bounds on data-dependent hypothesis sets via PAC-Bayesian theory on random sets. Journal of Machine Learning Research, 25(409):1–55, 2024
2024
-
[35]
Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data
Gintare Karolina Dziugaite and Daniel M Roy. Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data. In Uncertainty in Artificial Intelligence (UAI), 2017
2017
-
[36]
On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations I*.Pro- ceedings of the National Academy of Sciences, 35(11):652–655, 1949
Ky Fan. On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations I*.Pro- ceedings of the National Academy of Sciences, 35(11):652–655, 1949
1949
-
[37]
Efficient Classification for Metric Data.IEEE Transactions on Information Theory, 60(9):5750–5759, 2014
Lee-Ad Gottlieb, Aryeh Kontorovich, and Robert Krauthgamer. Efficient Classification for Metric Data.IEEE Transactions on Information Theory, 60(9):5750–5759, 2014
2014
-
[38]
Efficient Regression in Metric Spaces via Approximate Lipschitz Extension.IEEE Transactions on Information Theory, 63(8):4838–4849, 2017
Lee-Ad Gottlieb, Aryeh Kontorovich, and Robert Krauthgamer. Efficient Regression in Metric Spaces via Approximate Lipschitz Extension.IEEE Transactions on Information Theory, 63(8):4838–4849, 2017
2017
-
[39]
Superconductivty Data
Kam Hamidieh. Superconductivty Data. UCI Machine Learning Repository, 2018. Dataset
2018
-
[40]
Complexity of Linear Regions in Deep Networks
Boris Hanin and David Rolnick. Complexity of Linear Regions in Deep Networks. volume 97 ofProceedings of Machine Learning Research, pages 2596–2604. PMLR, 09–15 Jun 2019
2019
-
[41]
Deep ReLU Networks Have Surprisingly Few Activation Patterns
Boris Hanin and David Rolnick. Deep ReLU Networks Have Surprisingly Few Activation Patterns. InAdvances in Neural Information Processing Systems, volume 32, pages 361–370. Curran Associates, Inc., 2019
2019
-
[42]
Train faster, generalize better: Stability of stochastic gradient descent
Moritz Hardt, Ben Recht, and Yoram Singer. Train faster, generalize better: Stability of stochastic gradient descent. volume 48 ofProceedings of Machine Learning Research, pages 1225–1234, New York, New York, USA, 20–22 Jun 2016. PMLR
2016
-
[43]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. InAdvances in Neural Information Processing Systems 31, pages 8571–8580, 2018
2018
-
[44]
Directional convergence and alignment in deep learning.Ad- vances in Neural Information Processing Systems, 2020
Ziwei Ji and Matus Telgarsky. Directional convergence and alignment in deep learning.Ad- vances in Neural Information Processing Systems, 2020
2020
-
[45]
Deep Nonparametric Regression on Approximate Manifolds: Nonasymptotic Error Bounds with Polynomial Prefactors.The Annals of Statistics, 51(2):691–716, 2023
Yuling Jiao, Guohao Shen, Yuanyuan Lin, and Jian Huang. Deep Nonparametric Regression on Approximate Manifolds: Nonasymptotic Error Bounds with Polynomial Prefactors.The Annals of Statistics, 51(2):691–716, 2023
2023
-
[46]
Kelley Pace and Ronald Barry
R. Kelley Pace and Ronald Barry. Sparse spatial autoregressions.Statistics & Probability Letters, 33(3):291–297, 1997
1997
-
[47]
Uniform convergence of interpolators: Gaussian width, norm bounds and benign overfitting.Advances in Neural Information Processing Systems, 34:20657–20668, 2021
Frederic Koehler, Lijia Zhou, Danica J Sutherland, and Nathan Srebro. Uniform convergence of interpolators: Gaussian width, norm bounds and benign overfitting.Advances in Neural Information Processing Systems, 34:20657–20668, 2021
2021
-
[48]
Kolmogorov and Vladimir M
Andrey N. Kolmogorov and Vladimir M. Tikhomirov. ϵ-Entropy and ϵ-Capacity of Sets in Functional Spaces.American Mathematical Society Translations, Series 2, 17:277–364, 1961
1961
-
[49]
Rademacher penalties and structural risk minimization.IEEE Transac- tions on Information Theory, 47(5):1902–1914, 2002
Vladimir Koltchinskii. Rademacher penalties and structural risk minimization.IEEE Transac- tions on Information Theory, 47(5):1902–1914, 2002
1902
-
[50]
Distribution-Dependent Analysis of Gibbs-ERM Principle
Ilja Kuzborskij, Nicolò Cesa-Bianchi, and Csaba Szepesvári. Distribution-Dependent Analysis of Gibbs-ERM Principle. InConference on Computational Learning Theory (COLT), volume 99, pages 2028–2054. PMLR, 2019
2028
-
[51]
Pointwise confidence estimation in the non-linear ℓ2-regularized least squares
Ilja Kuzborskij and Yasin Abbasi Yadkori. Pointwise confidence estimation in the non-linear ℓ2-regularized least squares. arxiv preprint 2506.07088, 2025. 12
arXiv 2025
-
[52]
Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington
Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[53]
Stability and Generalization of Stochastic Optimization with Nonconvex and Nonsmooth Problems
Yunwen Lei. Stability and Generalization of Stochastic Optimization with Nonconvex and Nonsmooth Problems. InProceedings of Thirty Sixth Conference on Learning Theory, volume 195 ofProceedings of Machine Learning Research, pages 191–227. PMLR, 2023
2023
-
[54]
Fine-Grained Analysis of Stability and Generalization for Stochastic Gradient Descent
Yunwen Lei and Yiming Ying. Fine-Grained Analysis of Stability and Generalization for Stochastic Gradient Descent. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5809–5819. PMLR, 2020
2020
-
[55]
Elizaveta Levina and Peter J. Bickel. Maximum Likelihood Estimation of Intrinsic Dimension. InAdvances in Neural Information Processing Systems, volume 17, pages 777–784, 2004
2004
-
[56]
Ridgeless
Tengyuan Liang and Alexander Rakhlin. Just Interpolate: Kernel “Ridgeless” Regression Can Generalize.The Annals of Statistics, 48(3):1329–1347, 2020
2020
-
[57]
PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization
Sanae Lotfi, Marc Anton Finzi, Sanyam Kapoor, Andres Potapczynski, Micah Goldblum, and Andrew Gordon Wilson. PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[58]
McAllester
David A. McAllester. Some PAC-Bayesian theorems. InConference on Computational Learning Theory (COLT), 1998
1998
-
[59]
Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio
Guido F. Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the Number of Linear Regions of Deep Neural Networks. InAdvances in Neural Information Processing Systems, pages 2924–2932, 2014
2014
-
[60]
Uniform convergence may be unable to explain generalization in deep learning.Advances in Neural Information Processing Systems, 32, 2019
Vaishnavh Nagarajan and J Zico Kolter. Uniform convergence may be unable to explain generalization in deep learning.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[61]
Adaptive Approximation and Generalization of Deep Neural Network with Intrinsic Dimensionality.Journal of Machine Learning Research, 21(174):1–38, 2020
Ryumei Nakada and Masaaki Imaizumi. Adaptive Approximation and Generalization of Deep Neural Network with Intrinsic Dimensionality.Journal of Machine Learning Research, 21(174):1–38, 2020
2020
-
[62]
Iterate averaging as regularization for stochastic gradient descent
Gergely Neu and Lorenzo Rosasco. Iterate averaging as regularization for stochastic gradient descent. InConference on Computational Learning Theory (COLT), pages 3222–3242. PMLR, 2018
2018
-
[63]
A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks
Behnam Neyshabur, Srinadh Bhojanapalli, and Nathan Srebro. A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[64]
Abolafia, Jeffrey Pennington, and Jascha Sohl- Dickstein
Roman Novak, Yasaman Bahri, Daniel A. Abolafia, Jeffrey Pennington, and Jascha Sohl- Dickstein. Sensitivity and Generalization in Neural Networks: An Empirical Study. In International Conference on Learning Representations (ICLR), 2018
2018
-
[65]
Using Local Complexity to Evaluate Out-of-Distribution Generalization
Grace O’Brien, Andrew Aguilar, Robert Jasper, Henry Kvinge, Sarah McGuire Scullen, and Helen Jenne. Using Local Complexity to Evaluate Out-of-Distribution Generalization. In Topology, Algebra, and Geometry in Data Science, 2025
2025
-
[66]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of Neural Collapse During the Terminal Phase of Deep Learning Training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
2020
-
[67]
Razvan Pascanu, Guido F. Montúfar, and Yoshua Bengio. On the Number of Response Regions of Deep Feed Forward Networks with Piece-Wise Linear Activations. arXiv preprint 1312.6098, 2013
Pith/arXiv arXiv 2013
-
[68]
On the Local Complexity of Linear Regions in Deep ReLU Networks
Niket Nikul Patel and Guido Montufar. On the Local Complexity of Linear Regions in Deep ReLU Networks. InInternational Conference on Machine Learning (ICML), pages 48335– 48370, 2025. 13
2025
-
[69]
Generalization error bounds for noisy, iterative algorithms
Ankit Pensia, Varun Jog, and Po-Ling Loh. Generalization error bounds for noisy, iterative algorithms. In2018 IEEE International Symposium on Information Theory (ISIT), pages 546–550. IEEE, 2018
2018
-
[70]
The inductive bias of ReLU networks on orthogonally separable data
Mary Phuong and Christoph H Lampert. The inductive bias of ReLU networks on orthogonally separable data. InInternational Conference on Learning Representations, 2021
2021
-
[71]
Springer, New York, 1984
David Pollard.Convergence of Stochastic Processes. Springer, New York, 1984
1984
-
[72]
The Intrinsic Dimension of Images and Its Impact on Learning
Phillip Pope, Chen Zhu, Ahmed Abdelkader, Micah Goldblum, and Tom Goldstein. The Intrinsic Dimension of Images and Its Impact on Learning. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[73]
On the Expressive Power of Deep Neural Networks
Maithra Raghu, Ben Poole, Jon Kleinberg, Surya Ganguli, and Jascha Sohl-Dickstein. On the Expressive Power of Deep Neural Networks. InInternational Conference on Machine Learning (ICML), volume 70 ofProceedings of Machine Learning Research, pages 2847–2854, 2017
2017
-
[74]
Roweis and Lawrence K
Sam T. Roweis and Lawrence K. Saul. Nonlinear Dimensionality Reduction by Locally Linear Embedding.Science, 290(5500):2323–2326, 2000
2000
-
[75]
Generalization properties of learning with random features
Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[76]
Deep ReLU Network Approximation of Functions on a Manifold
Johannes Schmidt-Hieber. Deep ReLU Network Approximation of Functions on a Manifold. arXiv preprint arXiv:1908.00695, 2019
arXiv 1908
-
[77]
Bounding and Counting Linear Regions of Deep Neural Networks
Thiago Serra, Christian Tjandraatmadja, and Srikumar Ramalingam. Bounding and Counting Linear Regions of Deep Neural Networks. InInternational Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 4558–4566. PMLR, 2018
2018
-
[78]
Shalev-Shwartz and S
S. Shalev-Shwartz and S. Ben-David.Understanding machine learning: From theory to algorithms. Cambridge University Press, 2014
2014
-
[79]
Jure Sokoli´c, Raja Giryes, Guillermo Sapiro, and Miguel R. D. Rodrigues. Robust Large Margin Deep Neural Networks.IEEE Transactions on Signal Processing, 65(16):4265–4280, 2017
2017
-
[80]
Lampert, and Marco Mondelli
Peter Súkeník, Christoph H. Lampert, and Marco Mondelli. Neural Collapse is Globally Optimal in Deep Regularized ResNets and Transformers. InAdvances in Neural Information Processing Systems, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.