Class Imbalance Corrections Failed to Enhance Discrimination, Model Calibration, and Prediction Stability: An Empirical Simulation Study Based on Clinical Dataset
Pith reviewed 2026-06-27 15:59 UTC · model grok-4.3
The pith
Class imbalance correction does not improve discrimination in clinical prediction models and instead causes miscalibration and instability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
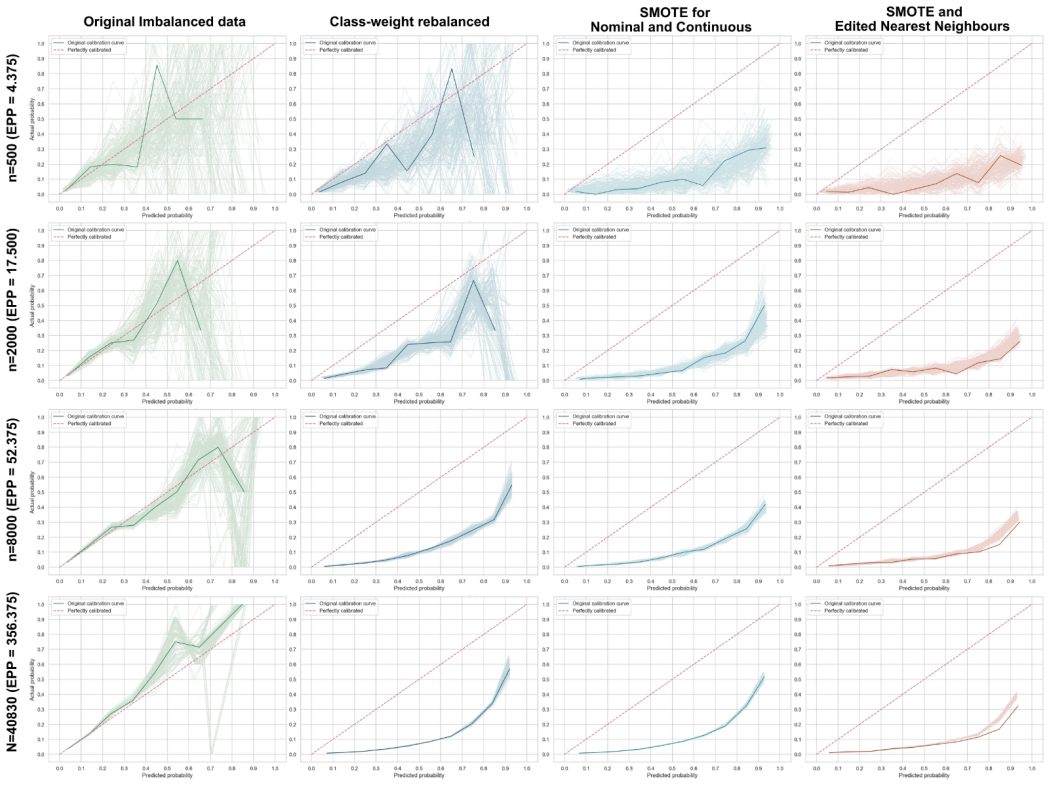
Using the GUSTO-I trial dataset of 40,830 patients and 2,851 events, the study simulated development and internal validation of penalised logistic regression models under multiple imbalance-correction strategies including algorithm-level rebalancing and data-level oversampling or combined sampling. Across sample-size scenarios, none of the corrections improved model discrimination, while all led to miscalibration with risk overestimation and higher prediction instability relative to models built without any correction, as shown in plots of calibration, MAPE, and the classification instability index from 200 bootstrap resamples.
What carries the argument
Simulation of clinical prediction model development and bootstrap validation on the GUSTO-I dataset, comparing uncorrected models against data-level and algorithm-level imbalance corrections.
If this is right
- Imbalance correction should not be applied routinely by default when building clinical prediction models.
- Uncorrected models can deliver better calibration and lower prediction instability than corrected versions.
- Risk overestimation occurs when common correction methods are used on imbalanced clinical data.
- Discrimination alone is not sufficient to judge whether correction helps overall model performance.
Where Pith is reading between the lines
- The same pattern of harm from correction could appear in other clinical datasets with similar event rates if the simulation design is repeated.
- Model developers might benefit from checking calibration and stability metrics before deciding on any imbalance fix rather than applying corrections based on imbalance ratio alone.
- This finding raises the question of whether different model types or external validation steps would change the recommendation against routine correction.
Load-bearing premise
The GUSTO-I trial data together with the chosen simulation design using penalised logistic regression and the tested correction strategies represent typical clinical prediction modeling scenarios where imbalance correction might be considered.
What would settle it
A replication of the same simulation setup on the GUSTO-I data that instead finds corrected models with calibration slopes closer to 1, lower MAPE values, and reduced CII across sample sizes would contradict the central claim.
Figures


read the original abstract
Class imbalance is common when developing clinical prediction models (CPMs) and is often assumed to lead to poor predictive performance. Several methods have been proposed to correct data imbalance during CPM development. However, it remains unclear whether correcting class imbalance improves or harms CPM performance. This study investigated how imbalance correction affects classification performance and prediction stability. We simulated the development and internal validation of CPMs using penalised logistic regression under different imbalance-correction strategies, including algorithm-level rebalancing, data-level rebalancing by oversampling, and combined over- and under-sampling. The simulation dataset was derived from the GUSTO-I trial, which included 40,830 patients and 2,851 events. All imbalance-correction strategies were evaluated across sample-size scenarios ranging from 500 to 40,830. Model performance and prediction stability were assessed using 200 bootstrap resamples, including discrimination, calibration, calibration stability, mean absolute prediction error (MAPE), and classification instability index (CII). Class imbalance correction did not meaningfully improve model discrimination. Both data-level and algorithm-level correction led to miscalibration, risk overestimation, and increased prediction instability, as shown by prediction stability, MAPE, and CII plots, compared with models developed without correction. These findings suggest that class imbalance correction does not necessarily improve CPM performance and may compromise calibration and prediction stability. Class imbalance should not be treated as a pathology that automatically requires correction. In clinical prediction modelling, routine imbalance correction by default is generally not advisable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical simulation study based on the GUSTO-I clinical trial dataset (40,830 patients, 2,851 events) using penalized logistic regression. It evaluates the effects of various class imbalance correction strategies (algorithm-level rebalancing, data-level oversampling, combined sampling) across sample sizes from 500 to 40,830. Using 200 bootstrap resamples, it assesses discrimination, calibration, MAPE, and CII, concluding that corrections do not improve discrimination and lead to miscalibration, risk overestimation, and increased instability, advising against routine use of imbalance correction in CPMs.
Significance. If these results hold beyond the specific setup, they would challenge standard practices in clinical prediction modeling by demonstrating potential harms of imbalance corrections to calibration and stability. Strengths include the use of a large public dataset, multiple sample size scenarios, and bootstrap-based stability assessment with 200 resamples, providing a reproducible empirical basis for the findings.
major comments (3)
- [Methods] Methods (simulation design): The event rate is fixed at ~7% from the GUSTO-I data without any sensitivity analysis varying prevalence; the miscalibration and instability findings central to the recommendation may not generalize to CPM settings with different event rates.
- [Discussion] Discussion: The prescriptive claim that 'routine imbalance correction by default is generally not advisable' extends beyond the reported evidence from a single dataset and penalised logistic regression; the load-bearing recommendation requires either scope limitation or additional cross-model/dataset experiments to be supported.
- [Results] Results (stability assessment): The MAPE and CII plots are used to demonstrate increased instability under corrections, but the absence of formal statistical comparisons or confidence bands on the differences across strategies weakens the quantitative support for the central claim of harm.
minor comments (1)
- [Abstract] Abstract: The event rate (~7%) and exact model class could be stated explicitly to better contextualize the scope of the findings for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods (simulation design): The event rate is fixed at ~7% from the GUSTO-I data without any sensitivity analysis varying prevalence; the miscalibration and instability findings central to the recommendation may not generalize to CPM settings with different event rates.
Authors: We agree that the fixed event rate of approximately 7% limits generalizability. The study was designed as an empirical simulation anchored to a large, real clinical dataset rather than synthetic data with manipulated prevalence. We will revise the Discussion to explicitly state that the observed effects on calibration and stability pertain to this prevalence level and to recommend future work examining a range of event rates. revision: yes
-
Referee: [Discussion] Discussion: The prescriptive claim that 'routine imbalance correction by default is generally not advisable' extends beyond the reported evidence from a single dataset and penalised logistic regression; the load-bearing recommendation requires either scope limitation or additional cross-model/dataset experiments to be supported.
Authors: We accept that the recommendation should be scoped to the conditions examined. We will revise the Discussion and Conclusion sections to qualify the statement as applying to penalized logistic regression on the GUSTO-I dataset with its observed event rate, while noting that broader validation across models and datasets is needed before generalizing the advice against routine correction. revision: yes
-
Referee: [Results] Results (stability assessment): The MAPE and CII plots are used to demonstrate increased instability under corrections, but the absence of formal statistical comparisons or confidence bands on the differences across strategies weakens the quantitative support for the central claim of harm.
Authors: The 200 bootstrap resamples provide the basis for the stability metrics, and the plots show consistent directional differences. We acknowledge that adding uncertainty quantification would improve the presentation. We will revise the Results to include bootstrap-derived confidence intervals around the MAPE and CII values for each strategy. revision: yes
Circularity Check
No circularity: purely empirical simulation study with no derivation chain
full rationale
The paper reports results from a simulation study that resamples the GUSTO-I dataset under varying sample sizes and applies penalised logistic regression with different imbalance-correction strategies, then evaluates performance via bootstrap metrics (discrimination, calibration, MAPE, CII). No mathematical derivation, fitted-parameter prediction, or self-citation chain is present; all conclusions follow directly from the observed simulation outputs rather than reducing to inputs by construction. This is the expected finding for an empirical simulation paper whose claims rest on data-driven comparisons rather than analytic identities.
Axiom & Free-Parameter Ledger
free parameters (1)
- sample size scenarios
axioms (1)
- domain assumption The GUSTO-I trial data distribution is representative of typical clinical datasets with class imbalance.
Reference graph
Works this paper leans on
-
[1]
Big Data and Machine Learning in Health Care
Beam AL, Kohane IS. Big Data and Machine Learning in Health Care. Jama. 2018 Apr 3;319(13):1317-8. PMID: 29532063. doi: 10.1001/jama.2017.18391
-
[3]
Machine Learning and Prediction in Medicine - Beyond the Peak of Inflated Expectations
Chen JH, Asch SM. Machine Learning and Prediction in Medicine - Beyond the Peak of Inflated Expectations. N Engl J Med. 2017 Jun 29;376(26):2507-9. PMID: 28657867. doi: 10.1056/NEJMp1702071
-
[4]
Validation, updating and impact of clinical prediction rules: a review
Toll DB, Janssen KJ, Vergouwe Y , Moons KG. Validation, updating and impact of clinical prediction rules: a review. J Clin Epidemiol. 2008 Nov;61(11):1085-94. PMID: 19208371. doi: 10.1016/j.jclinepi.2008.04.008
-
[5]
A calibration hierarchy for risk models was defined: from utopia to empirical data
Van Calster B, Nieboer D, Vergouwe Y , De Cock B, Pencina MJ, Steyerberg EW. A calibration hierarchy for risk models was defined: from utopia to empirical data. J Clin Epidemiol. 2016 Jun;74:167-76. PMID: 26772608. doi: 10.1016/j.jclinepi.2015.12.005
-
[6]
Calibration: the Achilles heel of predictive analytics
Van Calster B, McLernon DJ, van Smeden M, Wynants L, Steyerberg EW. Calibration: the Achilles heel of predictive analytics. BMC Med. 2019 Dec 16;17(1):230. PMID: 31842878. doi: 10.1186/s12916-019-1466-7
-
[7]
Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating: Springer New York; 2008
Steyerberg EW. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating: Springer New York; 2008. ISBN: 9780387772448
2008
-
[8]
Evaluation of clinical prediction models (part 1): from development to external validation
Collins GS, Dhiman P, Ma J, Schlussel MM, Archer L, Van Calster B, et al. Evaluation of clinical prediction models (part 1): from development to external validation. bmj. 2024;384
2024
-
[9]
Handling imbalanced medical datasets: review of a decade of research
Salmi M, Atif D, Oliva D, Abraham A, Ventura S. Handling imbalanced medical datasets: review of a decade of research. Artificial Intelligence Review. 2024 2024/09/02;57(10):273. doi: 10.1007/s10462-024-10884-2
-
[10]
van den Goorbergh R, van Smeden M, Timmerman D, Van Calster B. The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression. J Am Med Inform Assoc. 2022 Aug 16;29(9):1525-34. PMID: 35686364. doi: 10.1093/jamia/ocac093
-
[11]
Piccininni M, Wechsung M, Van Calster B, Rohmann JL, Konigorski S, van Smeden M. Understanding random resampling techniques for class imbalance correction and their consequences on calibration and discrimination of clinical risk prediction models. J Biomed Inform. 2024 Jul;155:104666. PMID: 38848886. doi: 10.1016/j.jbi.2024.104666
-
[12]
Clinical prediction models and the multiverse of madness
Riley RD, Pate A, Dhiman P, Archer L, Martin GP, Collins GS. Clinical prediction models and the multiverse of madness. BMC Med. 2023 Dec 18;21(1):502. PMID: 38110939. doi: 10.1186/s12916-023-03212-y
-
[13]
Stability of clinical prediction models developed using statistical or machine learning methods
Riley RD, Collins GS. Stability of clinical prediction models developed using statistical or machine learning methods. Biom J. 2023 Dec;65(8):e2200302. PMID: 37466257. doi: 10.1002/bimj.202200302
-
[14]
Seghieri C, Mimmi S, Lenzi J, Fantini MP. 30-day in-hospital mortality after acute myocardial infarction in Tuscany (Italy): an observational study using hospital discharge data. BMC Med Res Methodol. 2012 Nov 8;12:170. PMID: 23136904. doi: 10.1186/1471-2288- 12-170
-
[15]
New England Journal of Medicine
An International Randomized Trial Comparing Four Thrombolytic Strategies for Acute Myocardial Infarction. New England Journal of Medicine. 1993;329(10):673-82. doi: doi:10.1056/NEJM199309023291001
-
[16]
SMOTE: Synthetic Minority Over- sampling Technique
Chawla N, Bowyer K, Hall LO, Kegelmeyer WP. SMOTE: Synthetic Minority Over- sampling Technique. ArXiv. 2002;abs/1106.1813
Pith/arXiv arXiv 2002
-
[17]
ADASYN: Adaptive synthetic sampling approach for imbalanced learning
He H, Bai Y , Garcia EA, Li S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). 2008:1322-8
2008
-
[18]
On the effectiveness of preprocessing methods when dealing with different levels of class imbalance
García V , Sánchez J, Mollineda R. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowledge-Based Systems. 2012 02/01;25:13-21. doi: 10.1016/j.knosys.2011.06.013
-
[19]
Balancing Training Data for Automated Annotation of Keywords: a Case Study
Batista GEAPA, Bazzan ALC, Monard MC, editors. Balancing Training Data for Automated Annotation of Keywords: a Case Study. WOB; 2003
2003
-
[20]
A study of the behavior of several methods for balancing machine learning training data
Batista GEAPA, Prati RC, Monard MC. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor Newsl. 2004;6(1):20–9. doi: 10.1145/1007730.1007735
-
[21]
IEEE Transactions on Systems, Man, and Cybernetics
Two Modifications of CNN. IEEE Transactions on Systems, Man, and Cybernetics. 1976;SMC-6(11):769-72. doi: 10.1109/TSMC.1976.4309452
-
[22]
Asymptotic Properties of Nearest Neighbor Rules Using Edited Data
Wilson DL. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Transactions on Systems, Man, and Cybernetics. 1972;SMC-2(3):408-21. doi: 10.1109/TSMC.1972.4309137
-
[23]
Riley RD, Snell KI, Ensor J, Burke DL, Harrell FE, Jr., Moons KG, et al. Minimum sample size for developing a multivariable prediction model: PART II - binary and time-to- event outcomes. Stat Med. 2019 Mar 30;38(7):1276-96. PMID: 30357870. doi: 10.1002/sim.7992
-
[24]
Ramezankhani A, Pournik O, Shahrabi J, Azizi F, Hadaegh F, Khalili D. The Impact of Oversampling with SMOTE on the Performance of 3 Classifiers in Prediction of Type 2 Diabetes. Med Decis Making. 2016 Jan;36(1):137-44. PMID: 25449060. doi: 10.1177/0272989x14560647
-
[25]
Yadav S. SMOTE in Predictive Modeling: A Comprehensive Evaluation of Synthetic Oversampling for Class Imbalance. International Journal of Innovative Research in Engineering & Multidisciplinary Physical Sciences. 2020 08/01;8. doi: 10.5281/zenodo.14259555
-
[26]
Use of machine learning models to predict mortality in dialysis patients
Huang J, Chen L, Luo H, Song J, Bi Z, Chen K, et al. Use of machine learning models to predict mortality in dialysis patients. Front Public Health. 2025;13:1683285. PMID: 41426689. doi: 10.3389/fpubh.2025.1683285
-
[27]
Development and internal validation of a prediction model for hospital-acquired acute kidney injury
Martin-Cleary C, Molinero-Casares LM, Ortiz A, Arce-Obieta JM. Development and internal validation of a prediction model for hospital-acquired acute kidney injury. Clinical Kidney Journal. 2019;14(1):309-16. doi: 10.1093/ckj/sfz139
-
[28]
Resampling methods for class imbalance in clinical prediction models: A scoping review protocol
Abdelhay O, Shatnawi A, Najadat H, Altamimi T. Resampling methods for class imbalance in clinical prediction models: A scoping review protocol. PLoS One. 2025;20(11):e0330050. PMID: 41183062. doi: 10.1371/journal.pone.0330050
-
[29]
Steyerberg EW, Bleeker SE, Moll HA, Grobbee DE, Moons KG. Internal and external validation of predictive models: a simulation study of bias and precision in small samples. J Clin Epidemiol. 2003 May;56(5):441-7. PMID: 12812818. doi: 10.1016/s0895- 4356(03)00047-7
-
[30]
Machine learning algorithm validation with a limited sample size
Vabalas A, Gowen E, Poliakoff E, Casson AJ. Machine learning algorithm validation with a limited sample size. PLOS ONE. 2019;14(11):e0224365. doi: 10.1371/journal.pone.0224365
-
[31]
Balki I, Amirabadi A, Levman J, Martel AL, Emersic Z, Meden B, et al. Sample-Size Determination Methodologies for Machine Learning in Medical Imaging Research: A Systematic Review. Canadian Association of Radiologists Journal. 2019;70(4):344-53. PMID: 31522841. doi: 10.1016/j.carj.2019.06.002
-
[32]
Calculating the sample size required for developing a clinical prediction model
Riley RD, Ensor J, Snell KIE, Harrell FE, Martin GP, Reitsma JB, et al. Calculating the sample size required for developing a clinical prediction model. BMJ. 2020;368:m441. doi: 10.1136/bmj.m441
-
[33]
Cost-sensitive learning for imbalanced medical data: a review
Araf I, Idri A, Chairi I. Cost-sensitive learning for imbalanced medical data: a review. Artificial Intelligence Review. 2024;57(4):80
2024
-
[34]
Performance analysis of cost-sensitive learning methods with application to imbalanced medical data
Mienye ID, Sun Y . Performance analysis of cost-sensitive learning methods with application to imbalanced medical data. Informatics in Medicine Unlocked. 2021;25:100690
2021
-
[35]
Training cost-sensitive neural networks with methods addressing the class imbalance problem
Zhi-Hua Z, Xu-Ying L. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Transactions on Knowledge and Data Engineering. 2006;18(1):63-77. doi: 10.1109/TKDE.2006.17
-
[36]
Ke JXC, DhakshinaMurthy A, George RB, Branco P. The effect of resampling techniques on the performances of machine learning clinical risk prediction models in the setting of severe class imbalance: development and internal validation in a retrospective cohort. Discover Artificial Intelligence. 2024 2024/11/26;4(1):91. doi: 10.1007/s44163-024- 00199-0
-
[37]
Christodoulou E, Ma J, Collins GS, Steyerberg EW, Verbakel JY , Van Calster B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J Clin Epidemiol. 2019 Jun;110:12-22. PMID: 30763612. doi: 10.1016/j.jclinepi.2019.02.004
-
[38]
Riley RD, Ensor J, Snell KI, Debray TP, Altman DG, Moons KG, et al. External validation of clinical prediction models using big datasets from e-health records or IPD meta- analysis: opportunities and challenges. Bmj. 2016 Jun 22;353:i3140. PMID: 27334381. doi: 10.1136/bmj.i3140
-
[39]
Moons KG, Kengne AP, Grobbee DE, Royston P, Vergouwe Y , Altman DG, et al. Risk prediction models: II. External validation, model updating, and impact assessment. Heart. 2012 May;98(9):691-8. PMID: 22397946. doi: 10.1136/heartjnl-2011-301247
-
[40]
Evaluation of clinical prediction models (part 2): how to undertake an external validation study
Riley RD, Archer L, Snell KIE, Ensor J, Dhiman P, Martin GP, et al. Evaluation of clinical prediction models (part 2): how to undertake an external validation study. BMJ. 2024;384:e074820. doi: 10.1136/bmj-2023-074820
-
[41]
Riley RD, Snell KIE, Archer L, Ensor J, Debray TPA, van Calster B, et al. Evaluation of clinical prediction models (part 3): calculating the sample size required for an external validation study. Bmj. 2024 Jan 22;384:e074821. PMID: 38253388. doi: 10.1136/bmj-2023- 074821. Figures Figure 1. Study Simulation Flow Diagram. The empirical simulation started wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.