EviProp: Seeded Relevance Diffusion on Chunk-Page Graphs for Long Multimodal Document Retrieval
Pith reviewed 2026-06-27 15:02 UTC · model grok-4.3
The pith
Seeded relevance diffusion on multimodal chunk-page graphs recovers evidence pages missed by independent scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
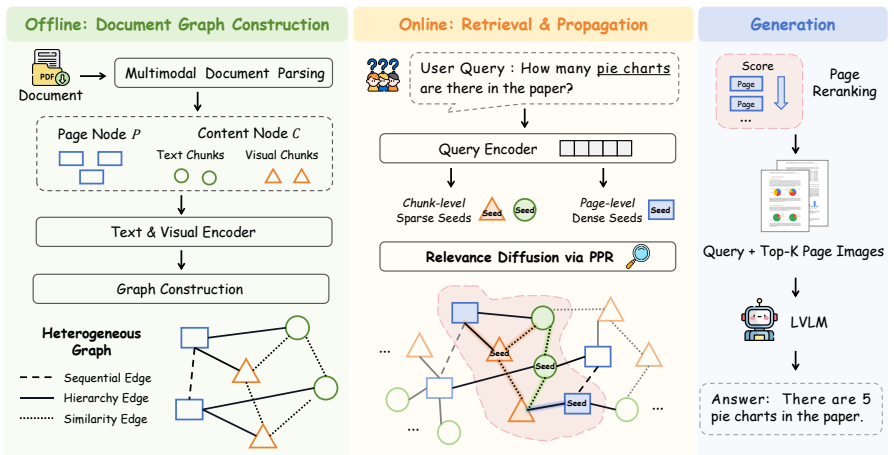
EviProp recovers evidence pages whose signals are localized in fine-grained chunks or depend on document-internal associations by modeling each document as a multimodal Chunk-Page graph with hierarchical, sequential, and similarity links, combining dense visual page priors with sparse chunk seeds, and running Personalized PageRank to diffuse relevance over the graph.
What carries the argument
The multimodal Chunk-Page graph whose hierarchical, sequential, and similarity links carry relevance diffusion from combined page priors and chunk seeds via Personalized PageRank.
If this is right
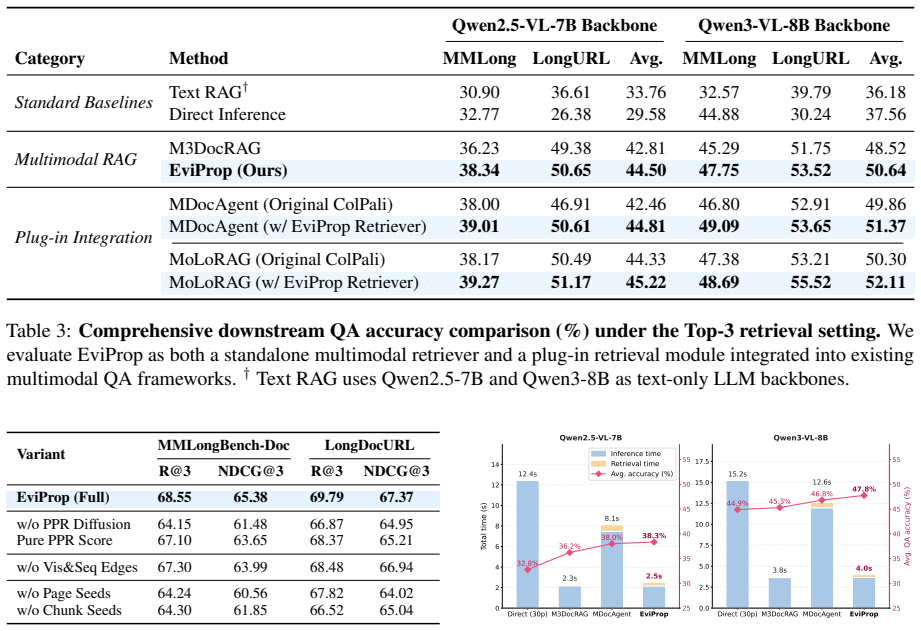
- Evidence-page retrieval improves over independent visual retrieval and text-visual fusion baselines.
- The retrieval improvement carries through to higher answer accuracy in downstream question answering.
- The added diffusion step imposes negligible overhead during online retrieval.
Where Pith is reading between the lines
- The same seeded-diffusion pattern could be applied to other retrieval settings that already have natural chunk-page or section hierarchies.
- If the graph links prove reliable, future systems might replace some hand-crafted fusion rules with learned or fixed diffusion operators.
- Testing the method on documents whose cross-chunk dependencies are explicitly annotated would directly measure how much of the gain comes from the diffusion step rather than the initial seeds.
Load-bearing premise
The hierarchical, sequential, and similarity links in the Chunk-Page graph accurately capture the document-internal associations that determine which evidence pages are under-ranked.
What would settle it
A controlled test on long documents where all relevant associations are removed from the graph links would show whether the diffusion step still produces retrieval gains.
Figures


read the original abstract
Retrieving evidence pages from visually rich long documents is a key challenge in document question answering. Existing page-level visual retrievers operate under an independent matching paradigm: each page is scored in isolation based on query-page similarity. This paradigm can under-rank evidence pages whose signals are localized in fine-grained chunks or depend on document-internal associations. We propose EviProp, a retrieval method that recovers such pages via seeded relevance diffusion. EviProp models each document as a multimodal Chunk-Page graph with hierarchical, sequential, and similarity links. Given a query, it combines dense visual page priors with sparse chunk seeds, then runs Personalized PageRank to diffuse relevance over the graph. Experiments on MMLongBench-Doc and LongDocURL show consistent gains in evidence-page retrieval over independent visual retrieval and text-visual fusion baselines. Downstream QA results further show that improved retrieval translates into better answer accuracy, with negligible online retrieval overhead. Our code is released at https://github.com/Flyecnu/EviProp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EviProp, a retrieval method for evidence pages in long multimodal documents. It models each document as a multimodal Chunk-Page graph incorporating hierarchical, sequential, and similarity links; seeds relevance using dense visual page priors combined with sparse chunk matches; and diffuses scores via Personalized PageRank. Experiments on MMLongBench-Doc and LongDocURL report consistent gains over independent visual retrieval and text-visual fusion baselines in evidence-page retrieval, with corresponding improvements in downstream QA accuracy and negligible online overhead. Code is released.
Significance. If the reported gains hold under scrutiny, the approach demonstrates how graph-based diffusion can surface evidence pages whose signals are localized in chunks or rely on document-internal associations, extending beyond independent page-level matching. The explicit code release supports reproducibility and verification of the seeded diffusion implementation.
minor comments (2)
- [Experiments] The abstract and results summary claim 'consistent gains' without reporting magnitudes, error bars, or statistical tests; adding these in the experimental section would strengthen the evaluation.
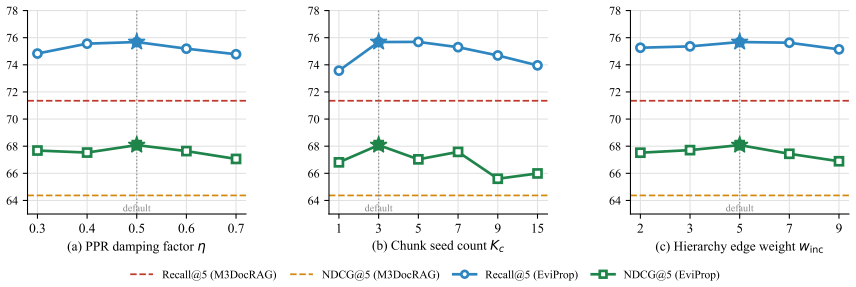
- [Method] Ablation details on the contribution of each graph link type (hierarchical, sequential, similarity) and the seeding strategy are not referenced in the provided description; including them would clarify the method's components.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the significance of seeded relevance diffusion on multimodal graphs, and recommendation for minor revision. We appreciate the note on reproducibility via code release.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces EviProp as a seeded relevance diffusion method on a newly constructed multimodal Chunk-Page graph, evaluated via experiments on external benchmarks (MMLongBench-Doc, LongDocURL) against independent baselines. No load-bearing equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description that reduce the claimed gains to inputs by construction. The central proposal (graph modeling + PPR diffusion) is presented as a distinct algorithmic contribution with downstream QA validation, making the derivation self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Personalized PageRank diffusion on the Chunk-Page graph surfaces pages whose evidence is localized or context-dependent
invented entities (1)
-
Chunk-Page graph with hierarchical, sequential, and similarity links
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
V-doc: Visual questions answers with documents , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
Advances in Neural Information Processing Systems , volume=
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval-augmented generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[5]
IEEE access , volume=
Handwritten optical character recognition (OCR): A comprehensive systematic literature review (SLR) , author=. IEEE access , volume=. 2020 , publisher=
2020
-
[6]
arXiv preprint arXiv:2409.18839 , year=
Mineru: An open-source solution for precise document content extraction , author=. arXiv preprint arXiv:2409.18839 , year=
-
[7]
arXiv preprint arXiv:2409.01704 , year=
General ocr theory: Towards ocr-2.0 via a unified end-to-end model , author=. arXiv preprint arXiv:2409.01704 , year=
-
[8]
arXiv preprint arXiv:2411.04952 , year=
M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding , author=. arXiv preprint arXiv:2411.04952 , year=
-
[9]
arXiv preprint arXiv:2503.13964 , year=
Mdocagent: A multi-modal multi-agent framework for document understanding , author=. arXiv preprint arXiv:2503.13964 , year=
-
[10]
International Conference on Learning Representations , volume=
Colpali: Efficient document retrieval with vision language models , author=. International Conference on Learning Representations , volume=
-
[11]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[12]
The pagerank citation ranking: Bring order to the web , author=. Proc. of the 7th International World Wide Web Conf.--1998 , year=
1998
-
[13]
Proceedings of the 11th international conference on World Wide Web , pages=
Topic-sensitive pagerank , author=. Proceedings of the 11th international conference on World Wide Web , pages=
-
[14]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locating , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Advances in neural information processing systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2502.14802 , year=
From rag to memory: Non-parametric continual learning for large language models , author=. arXiv preprint arXiv:2502.14802 , year=
-
[17]
arXiv preprint arXiv:2510.10114 , year=
Linearrag: Linear graph retrieval augmented generation on large-scale corpora , author=. arXiv preprint arXiv:2510.10114 , year=
-
[18]
International Conference on Learning Representations , volume=
Visrag: Vision-based retrieval-augmented generation on multi-modality documents , author=. International Conference on Learning Representations , volume=
-
[19]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[20]
Pattern Recognition , volume=
Hierarchical multimodal transformers for multipage docvqa , author=. Pattern Recognition , volume=. 2023 , publisher=
2023
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Slidevqa: A dataset for document visual question answering on multiple images , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
arXiv preprint arXiv:2312.10997 , volume=
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
-
[23]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Unifying multimodal retrieval via document screenshot embedding , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[25]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Vdocrag: Retrieval-augmented generation over visually-rich documents , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[26]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Murag: Multimodal retrieval-augmented generator for open question answering over images and text , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[27]
arXiv preprint arXiv:2510.12323 , year=
RAG-Anything: All-in-One RAG Framework , author=. arXiv preprint arXiv:2510.12323 , year=
-
[28]
arXiv preprint arXiv:2410.05779 , volume=
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , volume=
-
[29]
arXiv preprint arXiv:2404.16130 , year=
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
-
[30]
arXiv preprint arXiv:2510.07233 , year=
Lad-rag: layout-aware dynamic rag for visually-rich document understanding , author=. arXiv preprint arXiv:2510.07233 , year=
-
[31]
arXiv preprint arXiv:2508.05318 , year=
mKG-RAG: Multimodal Knowledge Graph-Enhanced RAG for Visual Question Answering , author=. arXiv preprint arXiv:2508.05318 , year=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aligning vision to language: Annotation-free multimodal knowledge graph construction for enhanced llms reasoning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[34]
2: Pushing the frontier of open large language models , author=
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
-
[35]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[36]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[37]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[38]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[39]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[40]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[41]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Visa: Retrieval augmented generation with visual source attribution , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
arXiv preprint arXiv:2507.05714 , year=
Hirag: Hierarchical-thought instruction-tuning retrieval-augmented generation , author=. arXiv preprint arXiv:2507.05714 , year=
-
[44]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Molorag: Bootstrapping document understanding via multi-modal logic-aware retrieval , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[45]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Towards natural language-based document image retrieval: new dataset and benchmark , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[46]
Advances in Neural Information Processing Systems , volume=
Uda: A benchmark suite for retrieval augmented generation in real-world document analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Colbertv2: Effective and efficient retrieval via lightweight late interaction , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[48]
Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
Reciprocal rank fusion outperforms condorcet and individual rank learning methods , author=. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.