Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions
Pith reviewed 2026-06-27 17:29 UTC · model grok-4.3
The pith
Reward models for text-to-image improve when reasoning is internalized into score distributions rather than scalars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a 27B teacher VLM with GDSO to infer rubric-aligned score distributions and distilling via RISD into a 9B student, the resulting Z-Reward models achieve 89.6% and 88.6% human preference accuracy respectively on an internal evaluation set, outperforming prior scalar and pairwise methods, and provide a differentiable reward for text-to-image optimization that yields a 41.3% net improvement over SFT baselines.
What carries the argument
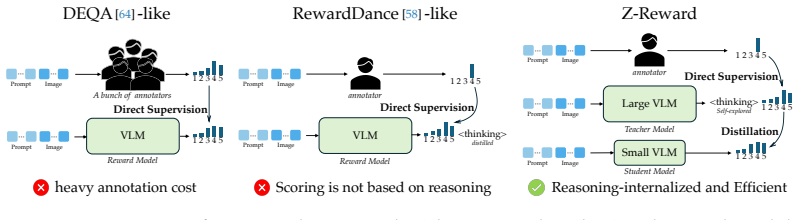
Z-Reward teacher-student framework that decouples reasoning-heavy judgment from efficient reward deployment by transferring score distributions.
If this is right
- The 27B GDSO teacher achieves 89.6% accuracy, beating SFT, RewardDance, and GRPO.
- The 9B RISD student reaches 88.6% accuracy, outperforming OPD and matching the teacher closely.
- Z-Reward acts as a differentiable signal for text-to-image optimization with 41.3% human-preference gain over SFT.
Where Pith is reading between the lines
- Smaller models can nearly match larger ones in reward quality after distillation, suggesting efficiency gains in deployment.
- This method may extend to other subjective judgment tasks where distributions better model uncertainty than scalars.
- Using distributions could allow more nuanced optimization in generative models beyond binary preferences.
Load-bearing premise
The internally annotated evaluation set accurately represents real human preferences without annotation bias or leakage.
What would settle it
An independent human evaluation on a publicly constructed and validated text-to-image preference dataset that shows the proposed models falling below 80% accuracy would falsify the superiority claims.
Figures



read the original abstract
Reward models are central to text-to-image post-training, but visual preference is subjective and better represented as a distribution over rubric scores than as a deterministic scalar. Existing scalar, score-token, and pairwise reward models over-compress uncertainty and fine-grained score differences, while reasoning-based generative rewards provide stronger judgments but are costly to deploy and difficult to use as direct optimization signals. We propose Z-Reward, a teacher-student reward modeling framework that decouples reasoning-heavy judgment from efficient reward deployment. The teacher is a large VLM that uses reasoning to infer rubric-aligned score distributions, and is trained with Group-wise Direct Score Optimization (GDSO), which combines policy-gradient rewards from distribution expectations with direct pointwise and pairwise supervision on score distributions and score gaps. The student is trained with Reasoning-Internalized Score Distillation (RISD), which transfers the teacher's reasoning-conditioned score distribution into a compact VLM without requiring explicit reasoning chains at inference time. On our internally annotated evaluation set, the 27B GDSO teacher reaches 89.6% human preference accuracy, outperforming SFT, RewardDance, and GRPO, while the 9B RISD student reaches 88.6%, outperforming the OPD baseline and closely matching the larger teacher. We further show that Z-Reward can serve as a differentiable reward signal for text-to-image optimization, yielding a 41.3% net human-preference improvement over the SFT baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Z-Reward, a teacher-student framework for text-to-image reward modeling. A 27B VLM teacher is trained via Group-wise Direct Score Optimization (GDSO) to output rubric-aligned score distributions using a combination of policy-gradient, pointwise, and pairwise supervision. A 9B VLM student is then trained via Reasoning-Internalized Score Distillation (RISD) to internalize the teacher's reasoning into a compact model without explicit chains at inference. On an internally annotated evaluation set the teacher reaches 89.6% human-preference accuracy (outperforming SFT, RewardDance, GRPO) and the student reaches 88.6% (outperforming OPD); Z-Reward is further shown to act as a differentiable optimization signal yielding a 41.3% net preference gain over SFT.
Significance. If the evaluation methodology is shown to be robust, the work offers a concrete route to reward models that preserve distributional uncertainty and fine-grained score differences while remaining deployable at inference time. The separation of heavy reasoning (teacher) from efficient scoring (student) and the use of distribution expectations as optimization signals address recognized limitations of scalar and pairwise reward models.
major comments (1)
- [Abstract] Abstract: the central empirical claims (89.6% teacher accuracy, 88.6% student accuracy, 41.3% optimization gain) rest entirely on an internally annotated evaluation set whose construction, size, inter-annotator agreement, annotation protocol, leakage controls, and validation against external benchmarks are not described. Without these details it is impossible to determine whether the reported margins over SFT/RewardDance/GRPO/OPD reflect genuine improvement or artifacts of the labeling process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for transparent evaluation details. We agree this is a substantive point and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (89.6% teacher accuracy, 88.6% student accuracy, 41.3% optimization gain) rest entirely on an internally annotated evaluation set whose construction, size, inter-annotator agreement, annotation protocol, leakage controls, and validation against external benchmarks are not described. Without these details it is impossible to determine whether the reported margins over SFT/RewardDance/GRPO/OPD reflect genuine improvement or artifacts of the labeling process.
Authors: We agree that the current manuscript lacks these critical details on the internally annotated evaluation set, making it difficult to fully assess the claims. In the revised version we will insert a dedicated subsection (likely in Section 4 or a new Appendix) that explicitly describes: dataset construction and selection criteria; exact size and composition (number of prompts, images, and preference annotations); annotation protocol including the rubric, guidelines provided to annotators, and collection process; inter-annotator agreement statistics (e.g., Cohen's kappa or raw agreement rates); leakage controls such as train/test splits and deduplication procedures; and any validation steps or comparisons performed against external benchmarks. These additions will be made without altering the reported numbers. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper proposes an empirical teacher-student framework (Z-Reward, GDSO, RISD) and reports accuracies and optimization gains measured on an internally annotated set. No equations, first-principles derivations, or load-bearing steps are shown that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims are experimental comparisons rather than mathematical predictions forced by the method's own definitions. The internal evaluation set raises validity questions but does not constitute circularity under the specified patterns, as no quoted reduction (e.g., Eq. X = Eq. Y by construction) exists in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual preference is subjective and better represented as a distribution over rubric scores than as a deterministic scalar.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (2023),https:// api.semanticscholar.org/CorpusID:263610088
Agarwal, R., Vieillard, N., Zhou, Y., Sta ´ nczyk, P ., Ramos, S., Geist, M., Bachem, O.: On-policy distillation of language models: Learning from self-generated mis- takes. In: International Conference on Learning Representations (2023),https:// api.semanticscholar.org/CorpusID:263610088
2023
-
[2]
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning (2024),https://arxiv.org/abs/2305.13301
Pith/arXiv arXiv 2024
-
[3]
Biometrika39, 324–345 (1952),https://api
Bradley, R.A., Terry, M.E.: Rank analysis of incomplete block designs the method of paired comparisons. Biometrika39, 324–345 (1952),https://api. semanticscholar.org/CorpusID:121987403
1952
-
[4]
In: Proceedings of the 41st International Conference on Machine Learning
Chen, D., Chen, R., Zhang, S., Wang, Y., Liu, Y., Zhou, H., Zhang, Q., Wan, Y., Zhou, P ., Sun, L.: MLLM-as-a-judge: Assessing multimodal LLM-as-a-judge with vision- language benchmark. In: Proceedings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, pp. 6562–6595. PMLR (2024),https://proceeding...
2024
-
[5]
Chen, Z., Du, Y., Wen, Z., Zhou, Y., Cui, C., Weng, Z., Tu, H., Wang, C., Tong, Z., Huang, Q., Chen, C., Ye, Q., Zhu, Z., Zhang, Y., Zhou, J., Zhao, Z., Rafailov, R., Finn, C., Yao, H.: MJ-Bench: Is your multimodal reward model really a good judge for text- to-image generation? (2024),https://arxiv.org/abs/2407.04842
arXiv 2024
-
[6]
Christiano, P .F., Leike, J., Brown, T.B., Martic, M., Legg, S., Amodei, D.: Deep re- inforcement learning from human preferences (2017),https://arxiv.org/abs/ 1706.03741
Pith/arXiv arXiv 2017
-
[7]
Clark, K., Vicol, P ., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards (2024),https://arxiv.org/abs/2309.17400
Pith/arXiv arXiv 2024
-
[8]
Cui, F., Li, S., Li, J.: A brief overview: On-policy self-distillation in large language models (2026),https://arxiv.org/abs/2605.18141
Pith/arXiv arXiv 2026
-
[9]
Transactions of the Association for Computational Linguistics , volume =
Davani, A.M., Díaz, M., Prabhakaran, V .: Dealing with disagreements: Looking be- yond the majority vote in subjective annotations. Transactions of the Association for Computational Linguistics10, 92–110 (2022). https://doi.org/10.1162/tacl_a_00449, https://aclanthology.org/2022.tacl-1.6
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Diaz, R., Marathe, A.: Soft labels for ordinal regression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[11]
In: Advances in Neural Information Processing Systems
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P ., Ghavamzadeh, M., Lee, K., Lee, K.: DPOK: Reinforcement learning for fine-tuning text-to-image dif- fusion models. In: Advances in Neural Information Processing Systems. vol. 36 (2023)
2023
-
[12]
Fu, Y., Huang, H., Jiang, K., Liu, J., Jiang, Z., Zhu, Y., Zhao, D.: Revisiting on-policy distillation: Empirical failure modes and simple fixes (2026),https://arxiv.org/ abs/2603.25562
Pith/arXiv arXiv 2026
-
[13]
In: Proceedings of the 40th International Conference on Machine Learning
Gao, L., Schulman, J., Hilton, J.: Scaling laws for reward model overoptimization. In: Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp. 10835–10866. PMLR (2023),https:// proceedings.mlr.press/v202/gao23h.html
2023
-
[14]
In: Advances in Neural Information Processing Systems
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. In: Advances in Neural Information Processing Systems. vol. 36 (2023)
2023
-
[15]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, S., Zhang, K., Wang, Y., Gao, W., Ni, L., Guo, J.: A survey on llm-as-a-judge (2024), https://arxiv.org/abs/2411.15594 16
Pith/arXiv arXiv 2024
-
[16]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=5h0qf7IBZZ
Gu, Y., Dong, L., Wei, F., Huang, M.: Minillm: Knowledge distillation of large lan- guage models. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=5h0qf7IBZZ
2024
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, H., Wu, J., Liu, J., Gao, Y., Ye, Z., Yuan, L., Wang, X., Yu, Y., Huang, W.: Lever- aging verifier-based reinforcement learning in image editing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 34343–34352 (2026)
2026
-
[18]
He, Y., Kaur, S., Bhaskar, A., Yang, Y., Liu, J., Ri, N., Fowl, L., Panigrahi, A., Chen, D., Arora, S.: Self-distillation zero: Self-revision turns binary rewards into dense supervi- sion (2026),https://arxiv.org/abs/2604.12002
Pith/arXiv arXiv 2026
-
[19]
In: Proceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: CLIPScore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing. pp. 7514–7528. Associa- tion for Computational Linguistics (2021). https://doi.org/10.18653/v1/2021.emnlp- main.595,https://aclanthol...
-
[20]
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015), https://arxiv.org/abs/1503.02531
Pith/arXiv arXiv 2015
-
[21]
In: Findings of the Association for Computational Linguistics: ACL 2023
Hsieh, C.Y., Li, C.L., Yeh, C.K., Nakhost, H., Fujii, Y., Ratner, A., Krishna, R., Lee, C.Y., Pfister, T.: Distilling step-by-step! outperforming larger language mod- els with less training data and smaller model sizes. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 8003–8017. Association for Computa- tional Linguistics (2023...
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Ac- curate and interpretable text-to-image faithfulness evaluation with question answer- ing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 20406–20417 (October 2023)
2023
-
[23]
In: Advances in Neural Information Processing Systems
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive bench- mark for open-world compositional text-to-image generation. In: Advances in Neural Information Processing Systems. vol. 36 (2023)
2023
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chan- paisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehen- sive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21807–21818 (2024)
2024
-
[25]
Jang, I., Yeom, J., Yeo, J., Lim, H., Kim, T.: Stable on-policy distillation through adap- tive target reformulation (2026),https://arxiv.org/abs/2601.07155
Pith/arXiv arXiv 2026
-
[26]
In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Kim, Y., Rush, A.M.: Sequence-level knowledge distillation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. pp. 1317–1327. Association for Computational Linguistics, Austin, Texas (2016). https://doi.org/10.18653/v1/D16-1139,https://aclanthology.org/D16-1139
-
[27]
Kirstain, Y., Polyak, A., Singer, U., Matiana, S., Penna, J., Levy, O.: Pick-a-pic: An open dataset of user preferences for text-to-image generation (2023),https: //arxiv.org/abs/2305.01569
arXiv 2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) Workshops
Li, B., Lin, Z., Pathak, D., Li, J., Fei, Y., Wu, K., Xia, X., Zhang, P ., Neubig, G., Ra- manan, D.: Evaluating and improving compositional text-to-visual generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) Workshops. pp. 5290–5301 (June 2024)
2024
-
[29]
Li, Y., Zuo, Y., He, B., Zhang, J., Xiao, C., Qian, C., Yu, T., ang Gao, H., Yang, W., Liu, Z., Ding, N.: Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe (2026),https://arxiv.org/abs/2604.13016 17
Pith/arXiv arXiv 2026
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liang, Y., He, J., Li, G., Li, P ., Klimovskiy, A., Carolan, N., Sun, J., Pont-Tuset, J., Young, S., Yang, F., Ke, J., Dvijotham, K.D., Collins, K.M., Luo, Y., Li, Y., Kohlhoff, K.J., Ramachandran, D., Navalpakkam, V .: Rich human feedback for text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (...
2024
-
[31]
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P ., Ramanan, D.: Evaluat- ing text-to-visual generation with image-to-text generation (2024),https://arxiv. org/abs/2404.01291
arXiv 2024
-
[32]
Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Xia, M., Wang, X., Liu, X., Yang, F., Wan, P ., Zhang, D., Gai, K., Yang, Y., Ouyang, W.: Improving video generation with human feedback (2025),https://arxiv.org/abs/2501.13918
Pith/arXiv arXiv 2025
-
[33]
Liu, Y., Yao, Z., Min, R., Cao, Y., Hou, L., Li, J.: Pairjudge rm: Perform best-of-n sam- pling with knockout tournament (2025),https://arxiv.org/abs/2501.13007
arXiv 2025
-
[34]
Liu, Z., Wang, P ., Xu, R., Ma, S., Ruan, C., Li, P ., Liu, Y., Wu, Y.: Inference-time scaling for generalist reward modeling (2025),https://arxiv.org/abs/2504.02495
arXiv 2025
-
[35]
Thinking Ma- chines Lab: Connectionism (2025),https://thinkingmachines.ai/blog/ on-policy-distillation, accessed: 2026-06-03
Lu, K., Thinking Machines Lab: On-policy distillation. Thinking Ma- chines Lab: Connectionism (2025),https://thinkingmachines.ai/blog/ on-policy-distillation, accessed: 2026-06-03
2025
-
[36]
Ma, Y., Shui, Y., Wu, X., Sun, K., Li, H.: Hpsv3: Towards wide-spectrum human pref- erence score (2025),https://arxiv.org/abs/2508.03789
arXiv 2025
-
[37]
In: 2012 IEEE Conference on Computer Vision and Pattern Recognition
Murray, N., Marchesotti, L., Perronnin, F.: Ava: A large-scale database for aesthetic vi- sual analysis. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition. pp. 2408–2415 (2012). https://doi.org/10.1109/CVPR.2012.6247954
-
[38]
Otani, M., Togashi, R., Sawai, Y., Ishigami, R., Nakashima, Y., Rahtu, E., Heikkilä, J., Satoh, S.: Toward verifiable and reproducible human evaluation for text-to-image generation (2023),https://arxiv.org/abs/2304.01816
arXiv 2023
-
[39]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P ., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L.E., Simens, M., Askell, A., Welinder, P ., Christiano, P .F., Leike, J., Lowe, R.J.: Training language models to follow instructions with human feedback (2022),https://arxiv.org/ abs/2203.02155
Pith/arXiv arXiv 2022
-
[40]
Penaloza, E., Vattikonda, D., Gontier, N., Lacoste, A., Charlin, L., Caccia, M.: Priv- ileged information distillation for language models (2026),https://arxiv.org/ abs/2602.04942
Pith/arXiv arXiv 2026
-
[41]
In: The Twelfth International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= Vaf4sIrRUC
Prabhudesai, M., Goyal, A., Pathak, D., Fragkiadaki, K.: Aligning text-to-image dif- fusion models with reward backpropagation. In: The Twelfth International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= Vaf4sIrRUC
2024
-
[42]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.5
2026
-
[43]
In: Advances in Neural Information Processing Systems
Rafailov, R., Chittepu, Y., Park, R., Sikchi, H., Hejna, J., Knox, W.B., Finn, C., Niekum, S.: Scaling laws for reward model overoptimization in direct alignment algorithms. In: Advances in Neural Information Processing Systems. vol. 37, pp. 126207–126242 (2024)
2024
-
[44]
In: Advances in Neural Information Processing Systems
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., Finn, C.: Direct pref- erence optimization: Your language model is secretly a reward model. In: Advances in Neural Information Processing Systems. vol. 36, pp. 53728–53741 (2023) 18
2023
-
[45]
In: Advances in Neural Information Processing Systems
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Ayan, B.K., Salimans, T., Ho, J., Fleet, D.J., Norouzi, M.: Photoreal- istic text-to-image diffusion models with deep language understanding. In: Advances in Neural Information Processing Systems. vol. 35, pp. 36479–36494 (2022)
2022
-
[46]
Sang, H., Xu, Y., Zhou, Z., He, R., Wang, Z., Sun, J.: Crisp: Compressed reasoning via iterative self-policy distillation (2026),https://api.semanticscholar.org/ CorpusID:286255699
2026
-
[47]
Shao, Z., Wang, P ., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language mod- els (2024),https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[48]
Shenfeld, I., Damani, M., Hübotter, J., Agrawal, P .: Self-distillation enables continual learning (2026),https://arxiv.org/abs/2601.19897
Pith/arXiv arXiv 2026
-
[49]
Song, M., Zheng, M.: A survey of on-policy distillation for large language models (2026),https://arxiv.org/abs/2604.00626
Pith/arXiv arXiv 2026
-
[50]
Talebi, H., Milanfar, P .: Nima: Neural image assessment. IEEE Transactions on Image Processing27(8), 3998–4011 (2018). https://doi.org/10.1109/TIP .2018.2831899
work page doi:10.1109/tip 2018
-
[51]
Team, Z.I., Cai, H., Cao, S., Du, R., Gao, P ., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., Li, Z., Li, Z.Y., Liu, D., Liu, D., Shi, J., Wu, Q., Yu, F., Zhang, C., Zhang, S., Zhou, S.: Z-image: An efficient image generation foundation model with single- stream diffusion transformer (2025),https://arxiv.org/abs/2511.22699
Pith/arXiv arXiv 2025
-
[52]
Journal of Artificial Intelligence Research , volume =
Uma, A.N., Fornaciari, T., Hovy, D., Paun, S., Plank, B., Poesio, M.: Learning from dis- agreement: A survey. Journal of Artificial Intelligence Research72, 1385–1470 (2021). https://doi.org/10.1613/jair.1.12752
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference op- timization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8228–8238 (June 2024)
2024
-
[54]
Wang, B., Lin, R., Lu, K., Yu, L., Zhang, Z., Huang, F., Zheng, C., Dang, K., Fan, Y., Ren, X., Yang, A., Hui, B., Liu, D., Gui, T., Zhang, Q., Huang, X., Jiang, Y.G., Yu, B., Zhou, J., Lin, J.: Worldpm: Scaling human preference modeling (2025),https: //arxiv.org/abs/2505.10527
arXiv 2025
-
[55]
Wang, Y., Zang, Y., Li, H., Jin, C., Wang, J.: Unified reward model for multimodal understanding and generation (2026),https://arxiv.org/abs/2503.05236
Pith/arXiv arXiv 2026
-
[56]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wen, C., Zhang, X., Yao, X., Yang, J.: Ordinal label distribution learning. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 23424–23434 (October 2023)
2023
-
[57]
Wu, H., Zhang, Z., Zhang, W., Chen, C., Li, C., Liao, L., Wang, A., Zhang, E., Sun, W., Yan, Q., Min, X., Zhai, G., Lin, W.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels (2023),https://arxiv.org/abs/2312.17090
Pith/arXiv arXiv 2023
-
[58]
Wu, J., Gao, Y., Ye, Z., Li, M., Li, L., Guo, H., Liu, J., Xue, Z., Hou, X., Liu, W., Zeng, Y., Huang, W.: Rewarddance: Reward scaling in visual generation (2025),https: //arxiv.org/abs/2509.08826
arXiv 2025
-
[59]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis (2023),https://arxiv.org/abs/2306.09341
Pith/arXiv arXiv 2023
-
[60]
Xu, J., Huang, Y., Cheng, J., Yang, Y., Xu, J., Wang, Y., Duan, W., Yang, S., Jin, Q., Li, S., Teng, J., Yang, Z., Zheng, W., Liu, X., Zhang, D., Ding, M., Zhang, X., Gu, X., Huang, S., Huang, M., Tang, J., Dong, Y.: Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation (2026),https://arxiv.org/ abs/2412.21059 19
Pith/arXiv arXiv 2026
-
[61]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[62]
In: Forty-first International Conference on Machine Learning (2024), https://openreview.net/forum?id=xVXnXk9I3I
Yang, S., Chen, T., Zhou, M.: A dense reward view on aligning text-to-image diffusion with preference. In: Forty-first International Conference on Machine Learning (2024), https://openreview.net/forum?id=xVXnXk9I3I
2024
-
[63]
Yang, Y., Long, Y., Wei, H., Chen, W., Zhang, T., Jiang, K., Fan, H., Liu, C., Chen, J., Tang, K., et al.: Joint reward modeling: Internalizing chain-of-thought for efficient visual reward models (2026),https://arxiv.org/abs/2602.07533
Pith/arXiv arXiv 2026
-
[64]
You, Z., Cai, X., Gu, J., Xue, T., Dong, C.: Teaching large language models to regress accurate image quality scores using score distribution (2025),https://arxiv.org/ abs/2501.11561
arXiv 2025
-
[65]
Zhang, L., Hosseini, A., Bansal, H., Kazemi, M., Kumar, A., Agarwal, R.: Generative verifiers: Reward modeling as next-token prediction (2025),https://arxiv.org/ abs/2408.15240
arXiv 2025
-
[66]
Zhang, S., Wang, B., Wu, J., Li, Y., Gao, T., Zhang, D., Wang, Z.: Learning multi- dimensional human preference for text-to-image generation (2024),https://arxiv. org/abs/2405.14705
arXiv 2024
-
[67]
Zhao, S., Xie, Z., Liu, M., Huang, J., Pang, G., Chen, F., Grover, A.: Self-distilled rea- soner: On-policy self-distillation for large language models (2026),https://arxiv. org/abs/2601.18734
Pith/arXiv arXiv 2026
-
[68]
In: Advances in Neural Information Processing Systems
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P ., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: Advances in Neural Information Processing Systems. vol. 36, pp. 46595–46623 (2023)
2023
-
[69]
Zhu, S., Ye, X., Lu, H., Shi, W., Liu, G.: The many faces of on-policy distillation: Pitfalls, mechanisms, and fixes (2026),https://arxiv.org/abs/2605.11182 20
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.