Beyond FLOPs: Benchmarking Real Inference Acceleration of LLM Pruning under a GEMM-Centric Taxonomy
Pith reviewed 2026-06-27 17:01 UTC · model grok-4.3
The pith
Static depth pruning stays closest to theoretical acceleration limits and leads the Pareto frontier for LLM inference at low quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
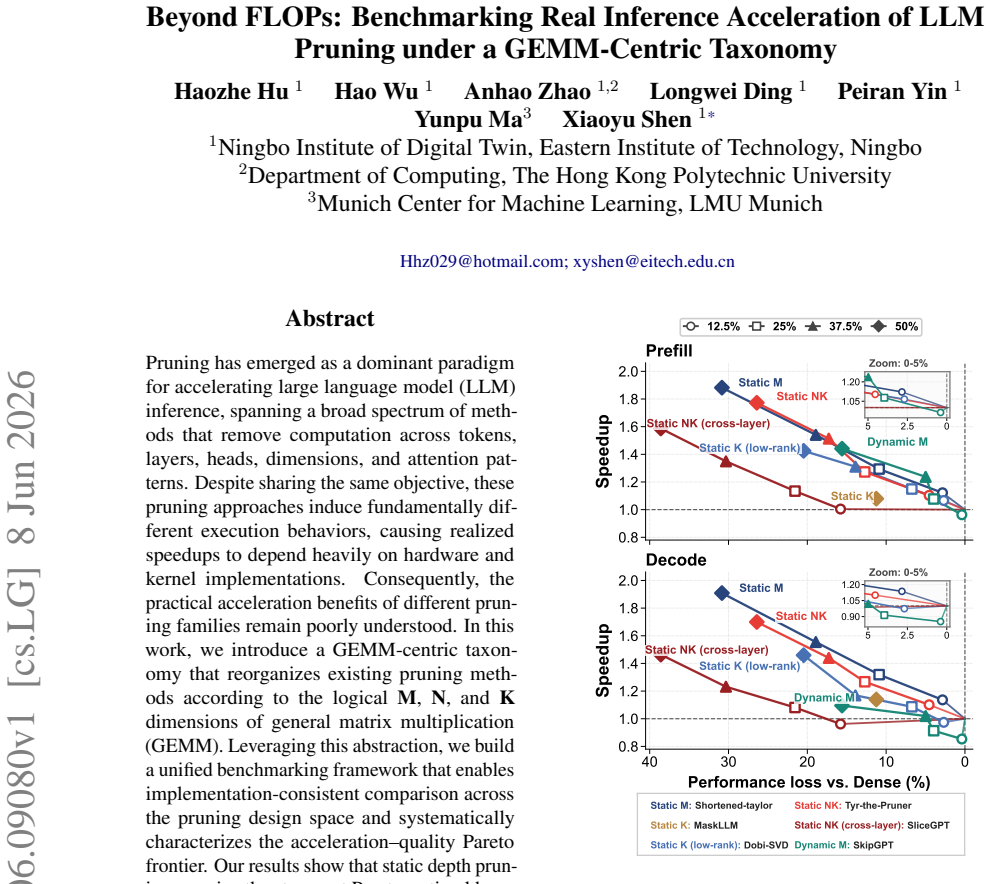
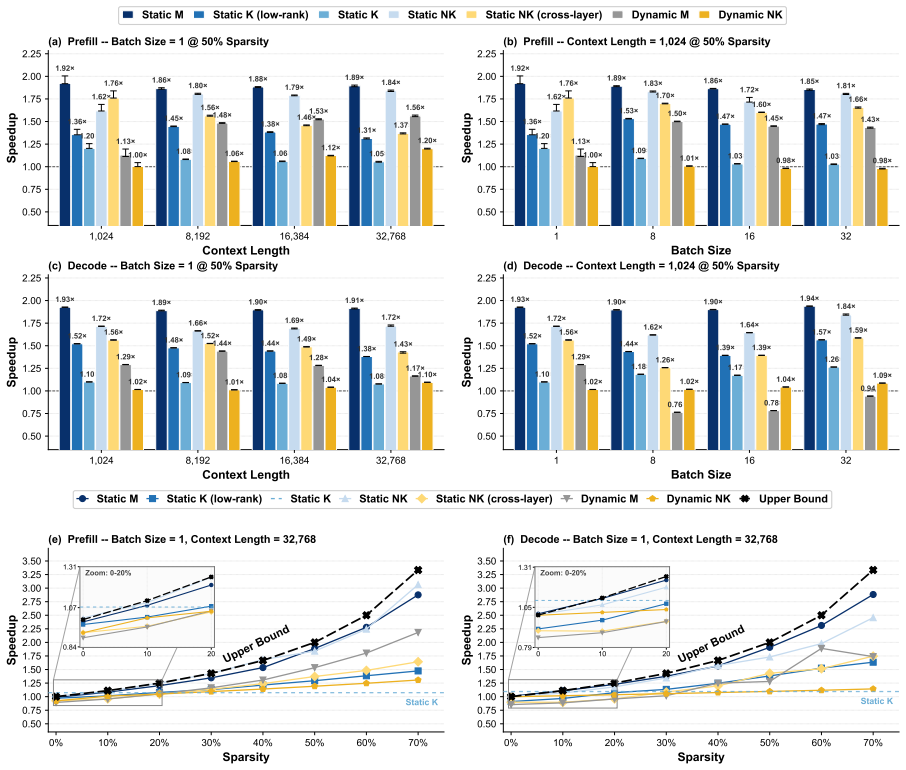
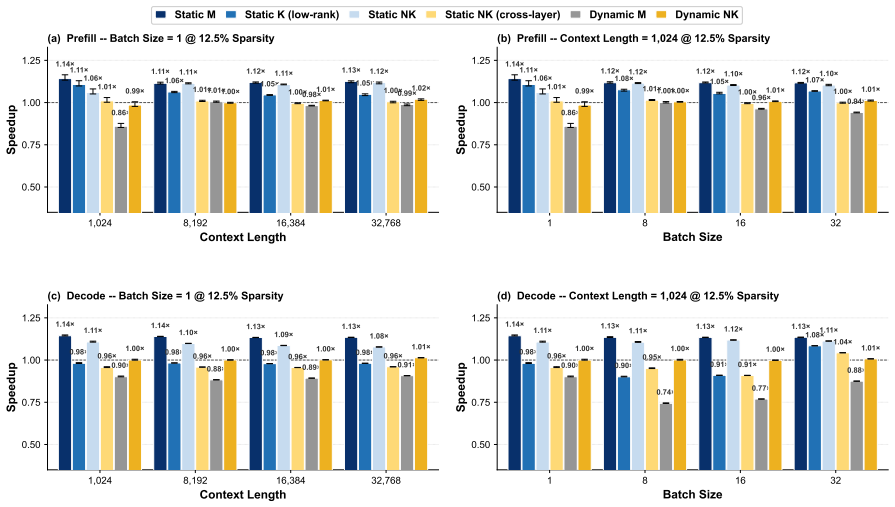
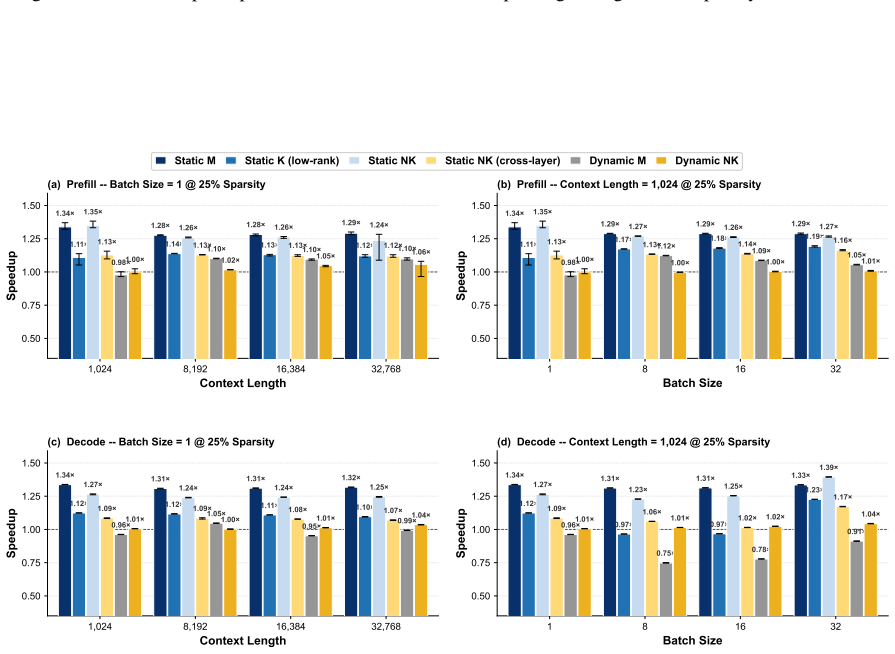
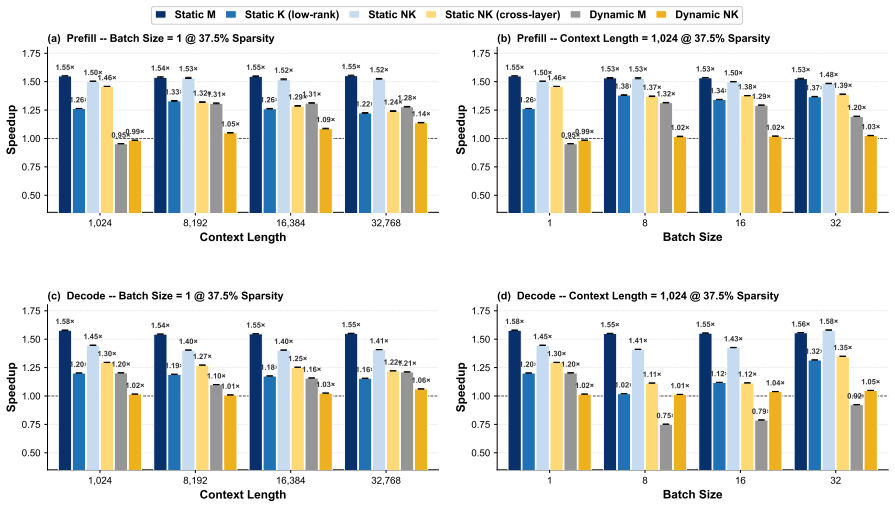
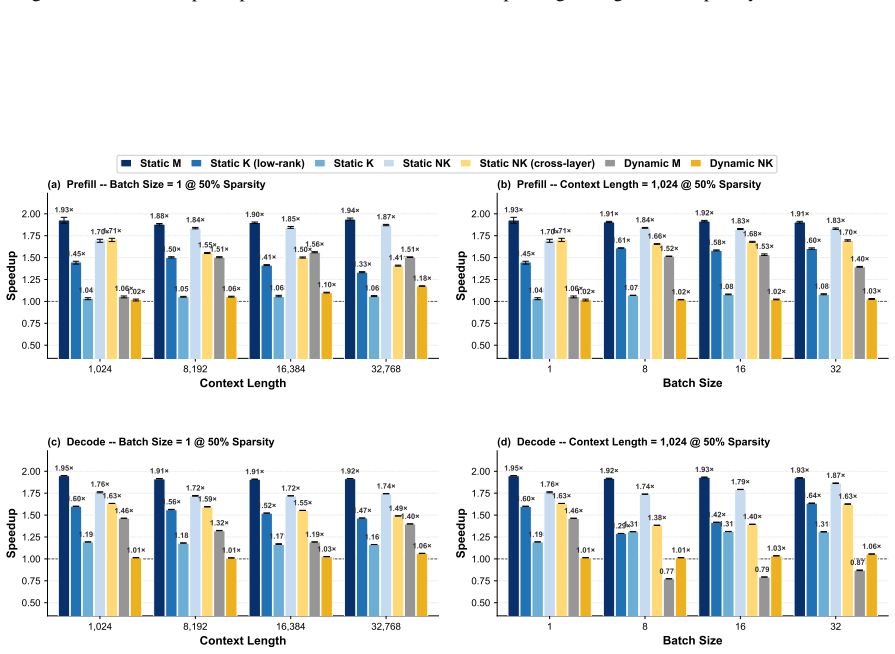
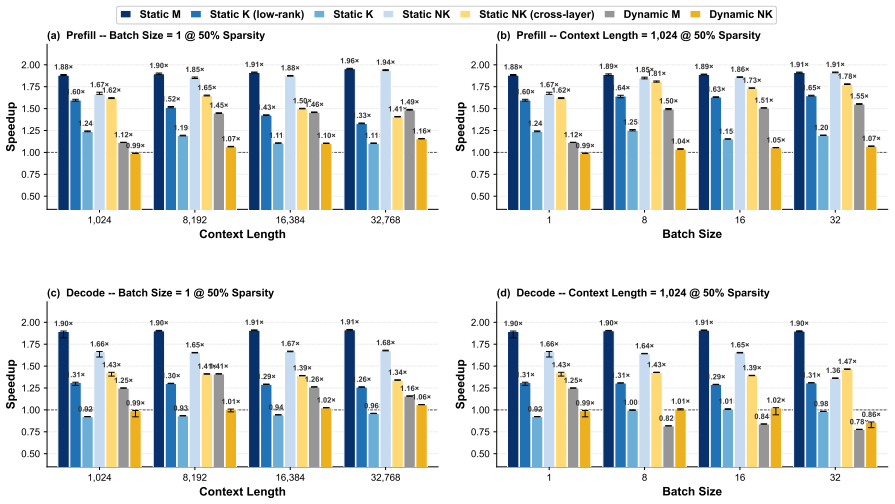
Static depth pruning remains the strongest Pareto-optimal baseline and stays closest to its theoretical acceleration upper bound in memory-bounded scenarios. During prefill, the frontier transitions from static depth at low quality loss (0%--4%), to dynamic depth at moderate loss (5%--16%), and finally to static width pruning at higher loss levels (17%--26%).
What carries the argument
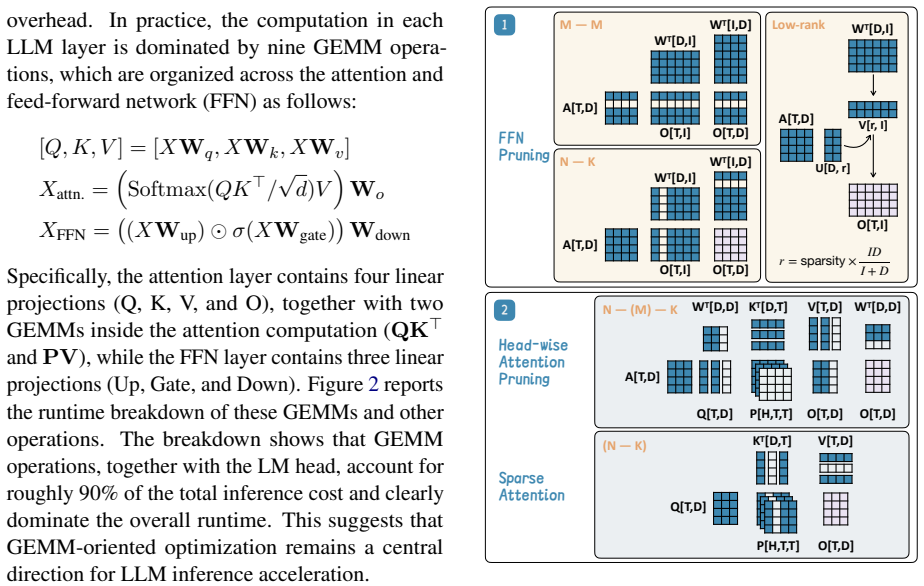
GEMM-centric taxonomy that reclassifies every pruning technique by the logical M, N, or K dimension it reduces in general matrix multiplication.
If this is right
- Static depth pruning should be the default starting point for memory-bound inference when quality loss must stay under 4 percent.
- Dynamic depth methods become preferable once moderate quality loss is acceptable.
- Static width pruning only justifies its implementation cost at high quality-loss budgets above 17 percent.
- Future pruning work can target the specific GEMM dimension that matches the desired operating point on the frontier.
Where Pith is reading between the lines
- Hardware designers could prioritize kernels that accelerate the depth-pruned case first, since that region dominates low-loss regimes.
- The same taxonomy could be applied to quantization or speculative decoding to see whether similar frontier transitions appear.
- If memory bandwidth improves faster than compute, the width-pruning region may shrink and depth methods could remain dominant longer.
Load-bearing premise
The GEMM-centric taxonomy and unified benchmarking framework capture the dominant execution behaviors of all pruning families in an implementation-consistent manner without being dominated by unmodeled kernel or hardware specifics.
What would settle it
If measurements on the same models but with a different kernel library or GPU show width pruning beating depth pruning at quality losses below 4 percent, the reported frontier ordering would be falsified.
Figures

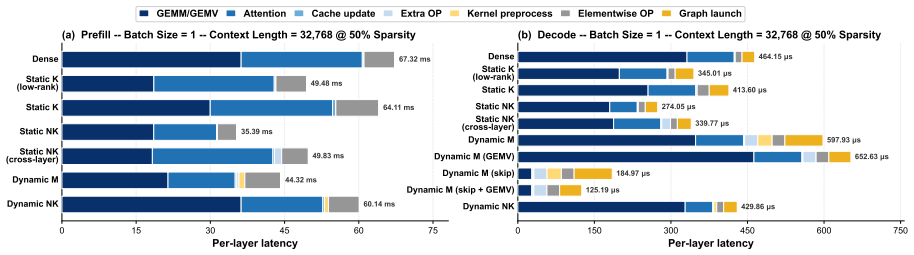
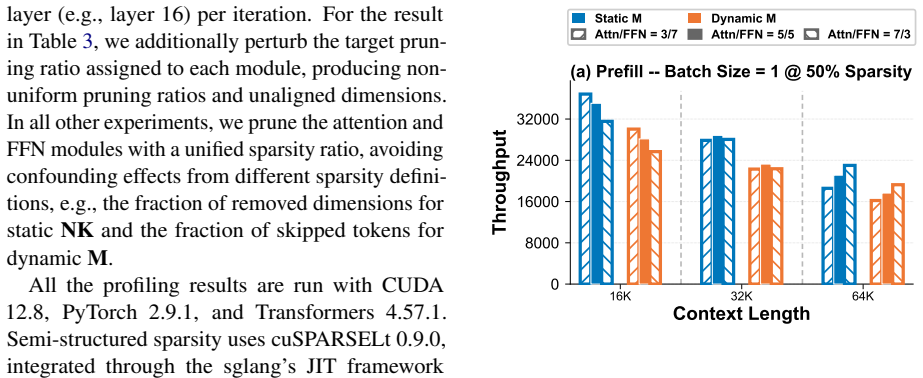
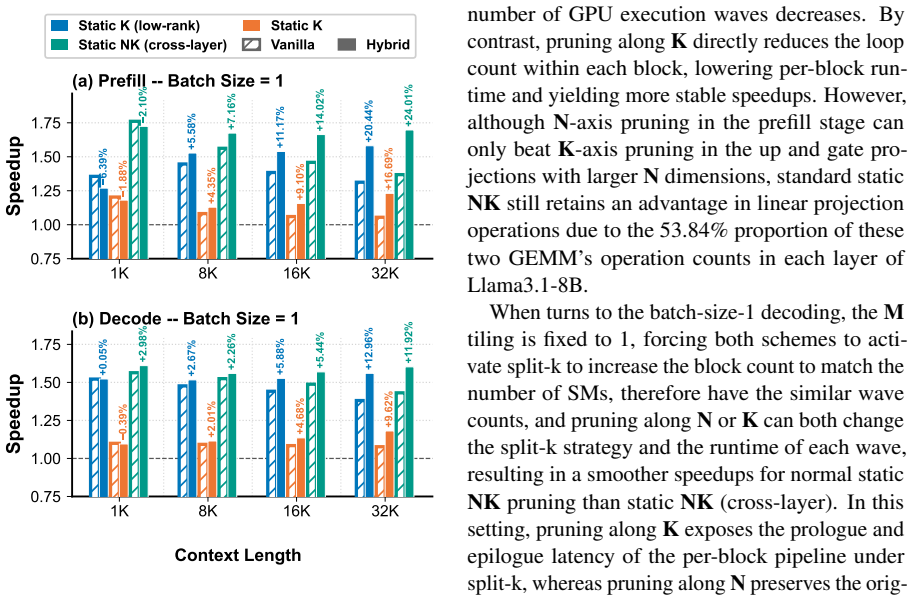
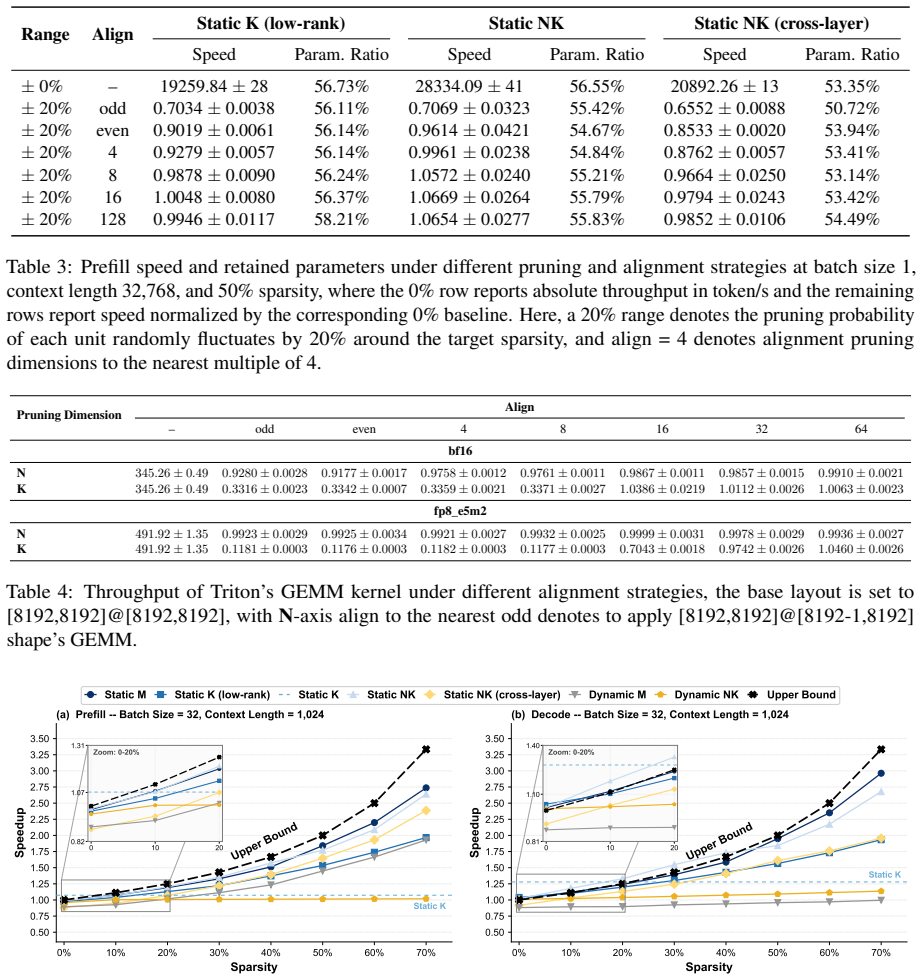
read the original abstract
Pruning has emerged as a dominant paradigm for accelerating large language model (LLM) inference, spanning a broad spectrum of methods that remove computation across tokens, layers, heads, dimensions, and attention patterns. Despite sharing the same objective, these pruning approaches induce fundamentally different execution behaviors, causing realized speedups to depend heavily on hardware and kernel implementations. Consequently, the practical acceleration benefits of different pruning families remain poorly understood. In this work, we introduce a GEMM-centric taxonomy that reorganizes existing pruning methods according to the logical \textbf{M}, \textbf{N}, and \textbf{K} dimensions of general matrix multiplication (GEMM). Leveraging this abstraction, we build a unified benchmarking framework that enables implementation-consistent comparison across the pruning design space and systematically characterizes the acceleration--quality Pareto frontier. Our results show that static depth pruning remains the strongest Pareto-optimal baseline and stays closest to its theoretical acceleration upper bound in memory-bounded scenarios. During prefill, the frontier transitions from static depth at low quality loss (0\%--4\%), to dynamic depth at moderate loss (5\%--16\%), and finally to static width pruning at higher loss levels (17\%--26\%). These findings establish the first unified view of the practical limits of pruning-based LLM acceleration and provide guidance for future pruning research.\footnote{Code is available at https://github.com/EIT-NLP/LLM-Pruning/tree/main/PruningInferSim}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a GEMM-centric taxonomy that reorganizes LLM pruning methods according to the logical M, N, and K dimensions of matrix multiplication. It develops a unified benchmarking framework (with code released) to enable implementation-consistent comparisons across pruning families and uses it to map the acceleration-quality Pareto frontier for prefill and decode phases on LLMs. The central empirical claim is that static depth pruning is the strongest Pareto-optimal baseline and remains closest to its theoretical upper bound in memory-bounded regimes, with the frontier transitioning to dynamic depth pruning at moderate quality loss (5%–16%) and to static width pruning at higher loss (17%–26%).
Significance. If the unified framework delivers truly implementation-consistent measurements, the work supplies the first systematic, cross-family view of realized versus theoretical acceleration limits for pruning-based LLM inference. The release of code is a concrete strength that supports reproducibility and allows independent verification of the reported transitions.
major comments (2)
- [Abstract / Methods (GEMM-centric taxonomy)] Abstract and Methods (GEMM-centric taxonomy and simulator): the claim of 'implementation-consistent comparison' across pruning families is load-bearing for all reported Pareto transitions and the superiority of static depth pruning. The manuscript must explicitly document whether the simulator applies a uniform dense GEMM baseline to width-pruning methods (which could otherwise exploit sparsity) or incorporates family-specific kernels; otherwise the acceleration gaps and the 17%–26% transition point may reflect modeling choices rather than inherent pruning behavior.
- [Results (prefill frontier)] Results (prefill frontier transitions): the specific quality-loss thresholds (0%–4% static depth, 5%–16% dynamic depth, 17%–26% static width) are presented without accompanying error bars, model/hardware sensitivity analysis, or explicit data-exclusion rules. These details are required to confirm that the reported transitions are robust rather than sensitive to post-hoc selection or hardware-specific bias.
minor comments (1)
- [Abstract] The abstract footnote states code availability, but the main text should include a brief pointer to the exact repository path and commit used for the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our GEMM-centric taxonomy and benchmarking framework. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract / Methods (GEMM-centric taxonomy)] Abstract and Methods (GEMM-centric taxonomy and simulator): the claim of 'implementation-consistent comparison' across pruning families is load-bearing for all reported Pareto transitions and the superiority of static depth pruning. The manuscript must explicitly document whether the simulator applies a uniform dense GEMM baseline to width-pruning methods (which could otherwise exploit sparsity) or incorporates family-specific kernels; otherwise the acceleration gaps and the 17%–26% transition point may reflect modeling choices rather than inherent pruning behavior.
Authors: We agree that explicit documentation is required to support the implementation-consistent claim. Our simulator applies a uniform dense GEMM baseline to all pruning families (including width pruning) to isolate the effects of the logical M/N/K reductions under the taxonomy, rather than confounding results with family-specific sparse kernels. This design choice ensures fair cross-family comparison focused on pruning-induced dimension changes. We will add a new subsection in Methods (and update the abstract if needed) that details the simulator architecture, confirms the uniform dense baseline, and explains why family-specific kernels were not used. This revision will directly address the concern that gaps may stem from modeling choices. revision: yes
-
Referee: [Results (prefill frontier)] Results (prefill frontier transitions): the specific quality-loss thresholds (0%–4% static depth, 5%–16% dynamic depth, 17%–26% static width) are presented without accompanying error bars, model/hardware sensitivity analysis, or explicit data-exclusion rules. These details are required to confirm that the reported transitions are robust rather than sensitive to post-hoc selection or hardware-specific bias.
Authors: We will incorporate the requested robustness elements. The thresholds were obtained by aggregating Pareto-optimal points across multiple LLMs (Llama-2/3 variants) and hardware configurations in the prefill phase. In revision, we will add error bars (standard deviation over 5 runs per configuration), a sensitivity analysis subsection examining variations across model sizes, batch sizes, and two hardware platforms, and an explicit statement of data-exclusion rules (e.g., configurations with >20% variance or incomplete kernel support were excluded). These will appear in the main Results and an expanded appendix to demonstrate that the frontier transitions (static depth → dynamic depth → static width) are stable. revision: yes
Circularity Check
No circularity: claims rest on empirical measurements
full rationale
The paper's core contribution is a GEMM-centric taxonomy for reorganizing pruning methods by M/N/K dimensions, followed by construction of a unified benchmarking framework whose outputs are direct runtime and quality measurements. The reported Pareto frontiers and transitions (static depth at low loss, dynamic depth at moderate loss, static width at high loss) are presented as observed results from this framework, not as predictions derived from equations that reduce to the inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The framework is an implementation choice whose fidelity is an external validity question, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
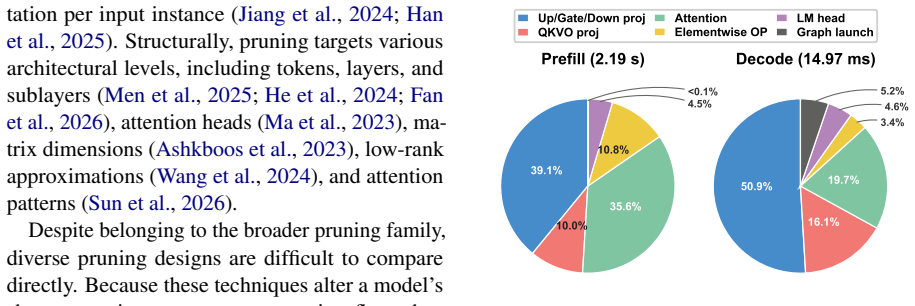
- domain assumption GEMM operations are the primary bottleneck in LLM inference
Reference graph
Works this paper leans on
-
[1]
A Deeper Look at Depth Pruning of
Siddiqui, Shoaib Ahmed and Dong, Xin and Heinrich, Greg and Breuel, Thomas and Kautz, Jan and Krueger, David and Molchanov, Pavlo , year = 2024, month = jul, langid =. A Deeper Look at Depth Pruning of
2024
-
[2]
V isi P runer: Decoding Discontinuous Cross-Modal Dynamics for Efficient Multimodal LLM s
Fan, Yingqi and Zhao, Anhao and Fu, Jinlan and Tong, Junlong and Su, Hui and Pan, Yijie and Zhang, Wei and Shen, Xiaoyu. V isi P runer: Decoding Discontinuous Cross-Modal Dynamics for Efficient Multimodal LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.955
-
[3]
2026 , eprint=
From LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
What Do Visual Tokens Really Encode? Uncovering Sparsity and Redundancy in Multimodal Large Language Models , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation , author=. 2026 , eprint=
2026
-
[6]
2025 , eprint=
Informed Routing in LLMs: Smarter Token-Level Computation for Faster Inference , author=. 2025 , eprint=
2025
-
[7]
2024 , eprint=
A Survey on Deep Neural Network Pruning-Taxonomy, Comparison, Analysis, and Recommendations , author=. 2024 , eprint=
2024
-
[8]
A Survey on Deep Neural Network Pruning: Taxonomy, Comparison, Analysis, and Recommendations , year=
Cheng, Hongrong and Zhang, Miao and Shi, Javen Qinfeng , journal=. A Survey on Deep Neural Network Pruning: Taxonomy, Comparison, Analysis, and Recommendations , year=
-
[9]
Zhou, Zixuan and Ning, Xuefei and Hong, Ke and Fu, Tianyu and Xu, Jiaming and Li, Shiyao and Lou, Yuming and Wang, Luning and Yuan, Zhihang and Li, Xiuhong and Yan, Shengen and Dai, Guohao and Zhang, Xiao-Ping and Dong, Yuhan and Wang, Yu , year = 2024, month = jul, number =. A. doi:10.48550/arXiv.2404.14294 , archiveprefix =. 2404.14294 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.14294 2024
-
[10]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Raposo, David and Ritter, Sam and Richards, Blake and Lillicrap, Timothy and Humphreys, Peter Conway and Santoro, Adam , year = 2024, month = apr, number =. Mixture-of-. doi:10.48550/arXiv.2404.02258 , archiveprefix =. 2404.02258 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.02258 2024
-
[11]
Forty-Second
Zhao, Anhao and Ye, Fanghua and Fan, Yingqi and Tong, Junlong and Xiong, Jing and Fei, Zhiwei and Su, Hui and Shen, Xiaoyu , year = 2025, month = jun, langid =. Forty-Second
2025
-
[12]
S hort GPT : Layers in Large Language Models are More Redundant Than You Expect
Men, Xin and Xu, Mingyu and Zhang, Qingyu and Yuan, Qianhao and Wang, Bingning and Lin, Hongyu and Lu, Yaojie and Han, Xianpei and Chen, Weipeng , year = 2025, month = jul, pages =. Findings of the. doi:10.18653/v1/2025.findings-acl.1035 , isbn =
-
[13]
Findings of the
Yang, Yifei and Cao, Zouying and Zhao, Hai , year = 2024, month = nov, pages =. Findings of the
2024
-
[14]
Yang, Guang and Zhou, Yu and Zhang, Xiangyu and Cheng, Wei and Liu, Ke and Chen, Xiang and Zhuo, Terry Yue and Chen, Taolue , year = 2025, month = apr, number =. Less Is. doi:10.48550/arXiv.2412.15921 , archiveprefix =. 2412.15921 , primaryclass =
-
[15]
doi:10.48550/arXiv.2501.09949 , archiveprefix =
Mu. doi:10.48550/arXiv.2501.09949 , archiveprefix =. 2501.09949 , primaryclass =
-
[16]
Xia, Haojun and Zheng, Zhen and Li, Yuchao and Zhuang, Donglin and Zhou, Zhongzhu and Qiu, Xiafei and Li, Yong and Lin, Wei and Song, Shuaiwen Leon , year = 2023, month = sep, number =. Flash-. doi:10.48550/arXiv.2309.10285 , archiveprefix =. 2309.10285 , primaryclass =
-
[17]
Efficient
Lin, Bin and Zheng, Ningxin and Wang, Lei and Cao, Shijie and Ma, Lingxiao and Zhang, Quanlu and Zhu, Yi and Cao, Ting and Xue, Jilong and Yang, Yuqing and Yang, Fan , year = 2023, month = mar, journal =. Efficient
2023
-
[18]
and do Nascimento, Marcelo Gennari and Hoefler, Torsten and Hensman, James , year = 2023, month = oct, langid =
Ashkboos, Saleh and Croci, Maximilian L. and do Nascimento, Marcelo Gennari and Hoefler, Torsten and Hensman, James , year = 2023, month = oct, langid =. The
2023
-
[19]
Thirty-Seventh
Ma, Xinyin and Fang, Gongfan and Wang, Xinchao , year = 2023, month = nov, langid =. Thirty-Seventh
2023
-
[20]
Ling, Gui and Wang, Ziyang and YuliangYan and Liu, Qingwen , year = 2024, month = nov, langid =. The
2024
-
[21]
Li, Guanchen and Xu, Yixing and Li, Zeping and Liu, Ji and Yin, Xuanwu and Li, Dong and Barsoum, Emad , year = 2025, month = oct, number =. T\'yr-the-. doi:10.48550/arXiv.2503.09657 , archiveprefix =. 2503.09657 , primaryclass =
-
[22]
Zhou, Changhai and Qiao, Qian and Zhang, Weizhong and Jin, Cheng , year = 2025, month = may, number =. Large. doi:10.48550/arXiv.2505.03801 , archiveprefix =. 2505.03801 , primaryclass =
-
[23]
Fang, Gongfan and Yin, Hongxu and Muralidharan, Saurav and Heinrich, Greg and Pool, Jeff and Kautz, Jan and Molchanov, Pavlo and Wang, Xinchao , year = 2024, month = nov, langid =. The
2024
-
[24]
Proceedings of the 40th
Frantar, Elias and Alistarh, Dan , year = 2023, month = jul, pages =. Proceedings of the 40th
2023
-
[25]
Zico , year = 2023, month = oct, langid =
Sun, Mingjie and Liu, Zhuang and Bair, Anna and Kolter, J. Zico , year = 2023, month = oct, langid =. A. The
2023
-
[26]
Le, Qi and Diao, Enmao and Wang, Ziyan and Wang, Xinran and Ding, Jie and Yang, Li and Anwar, Ali , year = 2024, month = oct, langid =. Probe. The
2024
-
[27]
Prompt-Based
Wee, Juyun and Park, Minjae and Lee, Jaeho , year = 2025, month = jun, langid =. Prompt-Based. Forty-Second
2025
-
[28]
Jiang, Yikun and Wang, Huanyu and Xie, Lei and Zhao, Hanbin and Zhang, Chao and Qian, Hui and Lui, John C. S. , year = 2024, month = nov, langid =. D-. The
2024
-
[29]
Yang, Mingzhe and Lin, Sihao and Li, Changlin and Chang, Xiaojun , year = 2025, month = jun, langid =. Let. Forty-Second
2025
-
[30]
BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Yuan, Jiayi and Shinn, Cameron and Xu, Kai and Cui, Jingze and Klimiashvili, George and Xiao, Guangxuan and Zheng, Perkz and Li, Bo and Zhou, Yuxin and Ye, Zhouhai and You, Weijie and Zheng, Tian and Brown, Dominic and Wang, Pengbo and Cai, Richard and Demouth, Julien and Owens, John D. and Hu, Xia and Han, Song and Liu, Timmy and Mao, Huizi , year = 2025...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.12087 2025
-
[31]
Sun, Yutao and Li, Zhenyu and Zhang, Yike and Pan, Tengyu and Dong, Bowen and Guo, Yuyi and Wang, Jianyong , year = 2026, month = feb, number =. Efficient. doi:10.48550/arXiv.2507.19595 , archiveprefix =. 2507.19595 , primaryclass =
-
[32]
Gao, Chaochen and W, Xing and Fu, Qi and Hu, Songlin , year = 2024, month = oct, langid =. Quest:. The
2024
-
[33]
Forty-Second
Zhang, Jintao and Xiang, Chendong and Huang, Haofeng and Wei, Jia and Xi, Haocheng and Zhu, Jun and Chen, Jianfei , year = 2025, month = jun, langid =. Forty-Second
2025
-
[34]
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-R...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223 2025
-
[35]
Team, Kimi and Bai, Tongtong and Bai, Yifan and Bao, Yiping and Cai, S. H. and Cao, Yuan and Charles, Y. and Che, H. S. and Chen, Cheng and Chen, Guanduo and Chen, Huarong and Chen, Jia and Chen, Jiahao and Chen, Jianlong and Chen, Jun and Chen, Kefan and Chen, Liang and Chen, Ruijue and Chen, Xinhao and Chen, Yanru and Chen, Yanxu and Chen, Yicun and Che...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02276 2026
-
[36]
Hu, Ming and Ma, Chenglong and Li, Wei and Xu, Wanghan and Wu, Jiamin and Hu, Jucheng and Li, Tianbin and Zhuang, Guohang and Liu, Jiaqi and Lu, Yingzhou and Chen, Ying and Zhang, Chaoyang and Tan, Cheng and Ying, Jie and Wu, Guocheng and Gao, Shujian and Chen, Pengcheng and Lin, Jiashi and Wu, Haitao and Chen, Lulu and Wang, Fengxiang and Zhang, Yuanyuan...
-
[37]
SGLang: Efficient Execution of Structured Language Model Programs
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , year = 2024, month = jun, number =. doi:10.48550/arXiv.2312.07104 , archiveprefix =. 2312.07104 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.07104 2024
-
[38]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , year = 2023, month = sep, number =. Efficient. doi:10.48550/arXiv.2309.06180 , archiveprefix =. 2309.06180 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
-
[39]
Chen, Mengzhao and Wu, Meng and Jin, Hui and Yuan, Zhihang and Liu, Jing and Zhang, Chaoyi and Li, Yunshui and Huang, Jie and Ma, Jin and Xue, Zeyue and Liu, Zhiheng and Bin, Xingyan and Luo, Ping , year = 2025, month = oct, number =. doi:10.48550/arXiv.2510.25602 , archiveprefix =. 2510.25602 , primaryclass =
-
[40]
He, Shwai and Sun, Guoheng and Shen, Zheyu and Li, Ang , year = 2024, month = oct, number =. What. doi:10.48550/arXiv.2406.15786 , archiveprefix =. 2406.15786 , primaryclass =
-
[41]
Tillet, Philippe and Kung, H. T. and Cox, David , year = 2019, month = jun, series =. Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations , booktitle =. doi:10.1145/3315508.3329973 , isbn =
-
[42]
Zhong, Longguang and Wan, Fanqi and Chen, Ruijun and Quan, Xiaojun and Li, Liangzhi , year = 2025, month = jul, pages =. Findings of the. doi:10.18653/v1/2025.findings-acl.262 , isbn =
-
[43]
Sandri, Fabrizio and Cunegatti, Elia and Iacca, Giovanni , year = 2025, month = may, journal =
2025
-
[44]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and. The. doi:10.48550/arXiv.2407.21783 , archiveprefix =. 2407.21783 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[45]
Gao, Yizhao and Zeng, Zhichen and Du, DaYou and Cao, Shijie and Zhou, Peiyuan and Qi, Jiaxing and Lai, Junjie and So, Hayden Kwok-Hay and Cao, Ting and Yang, Fan and Yang, Mao , year = 2025, month = oct, langid =. The
2025
-
[46]
Gao, Yizhao and Guo, Shuming and Cao, Shijie and Xia, Yuqing and Cheng, Yu and Wang, Lei and Ma, Lingxiao and Sun, Yutao and Ye, Tianzhu and Dong, Li and So, Hayden Kwok-Hay and Hua, Yu and Cao, Ting and Yang, Fan and Yang, Mao , year = 2025, month = oct, langid =. Sparse. The
2025
-
[47]
Wang, Lei and Cheng, Yu and Shi, Yining and Mo, Zhiwen and Tang, Zhengju and Xie, Wenhao and Wu, Tong and Ma, Lingxiao and Xia, Yuqing and Xue, Jilong and Yang, Fan and Yang, Zhi , year = 2025, month = oct, langid =. The
2025
-
[48]
doi:10.48550/arXiv.2512.09946 , archiveprefix =
Chiang, Hung-Yueh and Wang, Bokun and Marculescu, Diana , year = 2025, month = dec, number =. doi:10.48550/arXiv.2512.09946 , archiveprefix =. 2512.09946 , primaryclass =
-
[49]
Pruning as a
Ding, Xuan and Tong, Pengyu and Duan, Ranjie and Zhang, Yunjian and Sun, Rui and Zhu, Yao , year = 2025, month = oct, langid =. Pruning as a. The
2025
-
[50]
Kim, Bo-Kyeong and Kim, Geonmin and Kim, Tae-Ho and Castells, Thibault and Choi, Shinkook and Shin, Junho and Song, Hyoung-Kyu , year = 2024, month = jun, number =. Shortened. doi:10.48550/arXiv.2402.02834 , archiveprefix =. 2402.02834 , primaryclass =
-
[51]
Wang, Xin and Zheng, Yu and Wan, Zhongwei and Zhang, Mi , year = 2024, month = oct, langid =. The
2024
-
[52]
Qinsi, Wang and Ke, Jinghan and Tomizuka, Masayoshi and Keutzer, Kurt and Xu, Chenfeng , year = 2024, month = oct, langid =. Dobi-. The
2024
-
[53]
and Shen, Yelong and Wallis, Phillip and
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and. International
-
[54]
Fluctuation-Based
An, Yongqi and Zhao, Xu and Yu, Tao and Tang, Ming and Wang, Jinqiao , year = 2023, month = dec, journal =. Fluctuation-Based
2023
-
[55]
arXiv.org , howpublished =
Llama: Open and efficient foundation language models , author=. arXiv.org , howpublished =
-
[56]
Huang, Xinhao and Huang, You-Liang and Wen, Zeyi , year = 2025, journal =
2025
-
[57]
RedPajama: an Open Dataset for Training Large Language Models , author =
-
[58]
Li, Jinhao and Xu, Jiaming and Huang, Shan and Chen, Yonghua and Li, Wen and Liu, Jun and Lian, Yaoxiu and Pan, Jiayi and Ding, Li and Zhou, Hao and Wang, Yu and Dai, Guohao , year = 2025, month = jun, number =. Large. doi:10.48550/arXiv.2410.04466 , archiveprefix =. 2410.04466 , primaryclass =
-
[59]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[60]
arXiv preprint arXiv:1609.07843 , year=
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
-
[61]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[62]
arXiv preprint arXiv:1905.10044 , year=
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
Pith/arXiv arXiv 1905
-
[63]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[64]
arXiv preprint arXiv:1905.07830 , year=
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
Pith/arXiv arXiv 1905
-
[65]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[66]
arXiv preprint arXiv:1809.02789 , year=
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. arXiv preprint arXiv:1809.02789 , year=
-
[67]
Wu, Hao and Fan, Yingqi and Jinyang, Dai and Tong, Junlong and Ma, Yunpu and Shen, Xiaoyu , year = 2025, month = oct, langid =. The
2025
-
[68]
doi:10.48550/arXiv.2602.23734 , archiveprefix =
Wu, Hao and Wang, Xudong and Zhang, Jialiang and Tong, Junlong and Chen, Xinghao and Lin, Junyan and Ma, Yunpu and Shen, Xiaoyu , year = 2026, month = feb, number =. doi:10.48550/arXiv.2602.23734 , archiveprefix =. 2602.23734 , primaryclass =
-
[69]
From Data to Model: A Survey of the Compression Lifecycle in MLLMs , url=
Wu, Hao and Tong, Junlong and Wang, Xudong and Tan, Yang and Zeng, Changyu and Antsiferova, Anastasia and Shen, Xiaoyu , year=. From Data to Model: A Survey of the Compression Lifecycle in MLLMs , url=. doi:10.36227/techrxiv.177220375.55495124/v1 , publisher=
-
[70]
2026 , eprint=
ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.