Claw-R1: A Step-Level Data Middleware System for Agentic Reinforcement Learning
Pith reviewed 2026-06-27 17:27 UTC · model grok-4.3
The pith
Claw-R1 treats agent interaction traces as managed step-level data assets to link runtimes with RL training backends.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
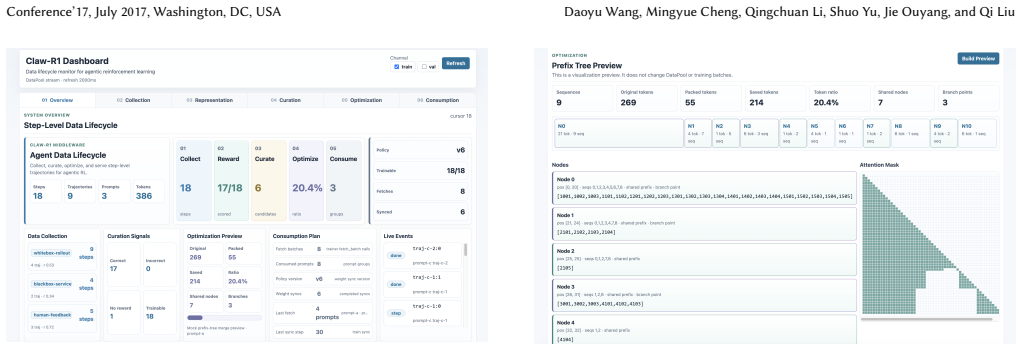
Claw-R1 is an interactive step-level data middleware system for agentic RL that connects heterogeneous agent runtimes with RL training backends through a Gateway Server and a Data Pool. The Gateway Server captures multi-turn interaction steps via a unified LLM API entry point, while the Data Pool organizes them into step-level records consisting of prompt IDs, response IDs, rewards and other metadata. Users can interactively inspect live trajectories, examine the state, action, and reward of each step, curate data by quality and readiness, and configure training-ready batches for different downstream RL algorithms.
What carries the argument
The Gateway Server and Data Pool that capture multi-turn steps at a unified API and store them as prompt-response-reward records with metadata.
If this is right
- Live trajectories become inspectable and editable before training begins.
- Data can be curated by quality metrics and readiness for specific algorithms.
- Training batches can be assembled directly from the managed records for multiple RL methods.
- Agent runtimes and training backends operate through a common data interface rather than ad-hoc logs.
Where Pith is reading between the lines
- Standard step-level records could make it easier to swap agent environments without rewriting data pipelines.
- The same records might support replay or offline analysis beyond the initial training run.
- Adoption would require compatible agent runtimes to emit the expected metadata fields.
Load-bearing premise
That organizing agent interaction traces into step-level records will meaningfully improve the data lifecycle for RL training.
What would settle it
A controlled comparison measuring data preparation time, training convergence speed, or final agent success rate when using Claw-R1 versus direct logging would show whether the middleware delivers gains; no measurable difference would undermine the benefit.
Figures


read the original abstract
Agentic reinforcement learning (RL) has become an important post-training paradigm for turning LLMs from static chatbots into interactive agents, giving rise to representative applications such as OpenClaw. Existing work mainly focuses on policy optimization algorithms and training frameworks, but pays less attention to the full data lifecycle of agent-environment interactions, from data production to training consumption. To bridge this gap, we present Claw-R1, an interactive step-level data middleware system for agentic RL. Claw-R1 connects heterogeneous agent runtimes with RL training backends through two core components: a Gateway Server and a Data Pool. The Gateway Server captures multi-turn interaction steps through a unified LLM API entry point, while the Data Pool organizes them into step-level records consisting of prompt IDs, response IDs, rewards and other metadata. In our demo, users can interactively inspect live trajectories, examine the state, action, and reward of each step, curate data by quality and readiness, and configure training-ready batches for different downstream RL algorithms. Overall, Claw-R1 treats agent interaction traces as managed data assets rather than temporary runtime logs. Through this demonstration, we hope to encourage the community to recognize the importance of data management in agentic RL. Our code is available at https://github.com/AgentR1/Claw-R1 and the demonstration video can be found at link https://youtu.be/Pw47dAOw6B0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Claw-R1, an interactive step-level data middleware system for agentic RL. It connects heterogeneous agent runtimes to RL training backends via two components: a Gateway Server that captures multi-turn interactions through a unified LLM API entry point, and a Data Pool that organizes traces into step-level records containing prompt IDs, response IDs, rewards, and metadata. The system supports live trajectory inspection, state/action/reward examination, quality-based curation, and configuration of training-ready batches for downstream RL algorithms. The work is framed as a demonstration that treats agent interaction traces as managed data assets, with code and a video demo provided to encourage community focus on data management issues in agentic RL.
Significance. If the described components function as stated, Claw-R1 offers a practical middleware layer for organizing agent-environment data, which could reduce ad-hoc logging practices in agentic RL pipelines. The explicit release of code at https://github.com/AgentR1/Claw-R1 and the linked demonstration video constitute a concrete, reusable contribution that enables others to inspect and extend the system. As a system-description paper rather than an empirical study, its significance rests on adoption and subsequent validation rather than immediate performance gains.
minor comments (2)
- [Abstract] Abstract: The reference to 'OpenClaw' as a representative application is not accompanied by a citation or brief description; adding one would clarify the context for readers unfamiliar with the term.
- The manuscript would benefit from an architecture diagram or pseudocode snippet showing the data flow between the Gateway Server and Data Pool, as the textual description alone leaves the integration details somewhat abstract.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of Claw-R1, as well as the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper is a pure system-description and demonstration work. Its central claim is the existence and basic operation of two architectural components (Gateway Server and Data Pool) that capture and organize step-level agent traces. No equations, derivations, fitted parameters, predictions, or uniqueness theorems appear anywhere in the manuscript. The abstract and full text explicitly frame the contribution as a demo intended to highlight data-management issues rather than to prove performance gains or derive new quantities from prior ones. Consequently, there are no load-bearing steps that reduce by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Code: Build, debug, and ship from your terminal. https: //claude.ai/product/claude-code
2025
-
[2]
Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, et al. 2025. AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning.arXiv preprint arXiv:2512.22857(2025)
arXiv 2025
-
[3]
Mingyue Cheng, Jie Ouyang, Shuo Yu, Ruiran Yan, Yucong Luo, Zirui Liu, Daoyu Wang, Qi Liu, and Enhong Chen. 2025. Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning.arXiv preprint arXiv:2511.14460(2025)
Pith/arXiv arXiv 2025
-
[4]
Mingyue Cheng, Daoyu Wang, Shuo Yu, Qingchuan Li, Jie Ouyang, Yucong Luo, Yiju Zhang, Qi Liu, and Enhong Chen. 2026. A Comprehensive Survey of the LLM-Based Agent: The Contextual Cognition Perspective. (2026)
2026
-
[5]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025. Group-in-Group Policy Optimization for LLM Agent Training.arXiv preprint arXiv:2505.10978 (2025)
Pith/arXiv arXiv 2025
-
[6]
Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, et al. 2025. VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use.arXiv preprint arXiv:2509.01055(2025)
arXiv 2025
-
[7]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning.arXiv preprint arXiv:2503.09516(2025)
Pith/arXiv arXiv 2025
-
[8]
Kuan Li, Zhongwang Zhang, Huifeng Yin, Rui Ye, Yida Zhao, Liwen Zhang, Litu Ou, Dingchu Zhang, Xixi Wu, Jialong Wu, et al. 2025. WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning.arXiv preprint arXiv:2509.13305(2025). https://arxiv.org/abs/2509.13305
arXiv 2025
-
[9]
Weizhen Li, Jianbo Lin, Zhuosong Jiang, Jingyi Cao, Xinpeng Liu, Jiayu Zhang, Zhenqiang Huang, Qianben Chen, Weichen Sun, Qiexiang Wang, et al . 2025. Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distilla- tion and Agentic RL.arXiv preprint arXiv:2508.13167(2025). https://arxiv.org/ abs/2508.13167
arXiv 2025
-
[10]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. 2023. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688(2023)
Pith/arXiv arXiv 2023
-
[11]
Xufang Luo, Yuge Zhang, Zhiyuan He, Zilong Wang, Siyun Zhao, Dongsheng Li, Luna K. Qiu, and Yuqing Yang. 2025. Agent Lightning: Train ANY AI Agents with Reinforcement Learning.arXiv preprint arXiv:2508.03680(2025)
arXiv 2025
-
[12]
Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgou, Corby Rosset, et al. 2024. AgentInstruct: Toward Generative Teaching with Agentic Flows. arXiv preprint arXiv:2407.03502(2024). https://arxiv.org/abs/2407.03502
arXiv 2024
-
[13]
openclaw. 2026. openclaw: Your own personal ai assistant. any os. any platform. the lobster way. https://github.com/openclaw/openclaw
2026
-
[14]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. InAd- vances in Neural Information Processing Systems
2022
-
[15]
Tingyue Pan, Jie Ouyang, Mingyue Cheng, Qingchuan Li, Zirui Liu, Daoyu Wang, Mingfan Pan, Shuo Yu, and Qi Liu. 2026. Paperscout: An autonomous agent for academic paper search with process-aware sequence-level policy optimization. arXiv preprint arXiv:2601.10029(2026)
arXiv 2026
-
[16]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[17]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
Pith/arXiv arXiv 2017
-
[18]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y Wu, et al. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
Pith/arXiv arXiv 2024
-
[19]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. HybridFlow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems. doi:10.1145/3689031.3696075
-
[20]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and em- bodied environments for interactive learning.arXiv preprint arXiv:2010.03768 (2020)
Pith/arXiv arXiv 2020
-
[21]
Zhengwei Tao, Jialong Wu, Wenbiao Yin, Junkai Zhang, Baixuan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu Wang, Yong Jiang, et al. 2025. Webshaper: Agentically data synthesizing via information-seeking formalization.arXiv preprint arXiv:2507.15061(2025)
arXiv 2025
-
[22]
The slime Team. 2025. slime: An SGLang-Native Post-Training Framework for RL Scaling. https://lmsys.org/blog/2025-07-09-slime/
2025
-
[23]
Daoyu Wang, Qingchuan Li, Mingyue Cheng, Jie Ouyang, Shuo Yu, Qi Liu, and Enhong Chen. 2026. StepPO: Step-Aligned Policy Optimization for Agentic Reinforcement Learning.arXiv preprint arXiv:2604.18401(2026)
Pith/arXiv arXiv 2026
-
[24]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291(2023)
Pith/arXiv arXiv 2023
-
[25]
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang
-
[26]
https://arxiv.org/abs/2603.10165
OpenClaw-RL: Train Any Agent Simply by Talking.arXiv preprint arXiv:2603.10165(2026). https://arxiv.org/abs/2603.10165
Pith/arXiv arXiv 2026
-
[27]
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. 2025. RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning.arXiv preprint arXiv:2504.20073(2025)
Pith/arXiv arXiv 2025
-
[28]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems35 (2022), 20744–20757
2022
-
[29]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al . 2025. The Land- scape of Agentic Reinforcement Learning for LLMs: A Survey.arXiv preprint arXiv:2509.02547(2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.