PrivCode++: Latent-Conditioned Differentially Private Code Generation for Comprehensive Guarantees
Pith reviewed 2026-06-27 16:26 UTC · model grok-4.3
The pith
PrivCode++ enables differentially private code generation that protects both prompts and code snippets using a latent conditioning module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PrivCode++ is the first differentially private code generation method that treats both prompts and code snippets as sensitive during LLM fine-tuning. It does so through a two-stage DP framework built around a Privacy-Free Latent Conditioning module that supports effective fine-tuning and data synthesis without any direct access to the sensitive material, delivering substantially higher utility than prior DP baselines while remaining competitive with approaches that relax the privacy assumptions.
What carries the argument
The Privacy-Free Latent Conditioning module, which replaces direct exposure to sensitive prompts and code with private latent representations for conditioning the model.
If this is right
- Substantially higher utility on code generation tasks than existing differentially private baselines.
- Competitive performance with methods that use weaker privacy assumptions.
- Stronger overall privacy guarantees by shielding both prompts and code snippets.
- First demonstration of DP code generation under the stricter assumption that prompts are also sensitive.
Where Pith is reading between the lines
- The same latent-conditioning pattern could be tested on other generative tasks where both input instructions and outputs carry private content.
- Real-world deployment might become feasible in domains such as enterprise code assistance where prompts routinely contain proprietary details.
- The approach raises the question of whether similar two-stage latent methods can reduce the utility cost of differential privacy in broader LLM fine-tuning settings.
- If the latent module proves robust, it could influence how future privacy standards define what counts as protected training data.
Load-bearing premise
The latent conditioning module can transfer enough information from the sensitive data to support high-quality code generation without direct access.
What would settle it
A benchmark run in which PrivCode++ produces code whose functional correctness or diversity falls below standard DP baselines, or in which membership-inference attacks recover sensitive prompt content at rates similar to non-private training.
Figures

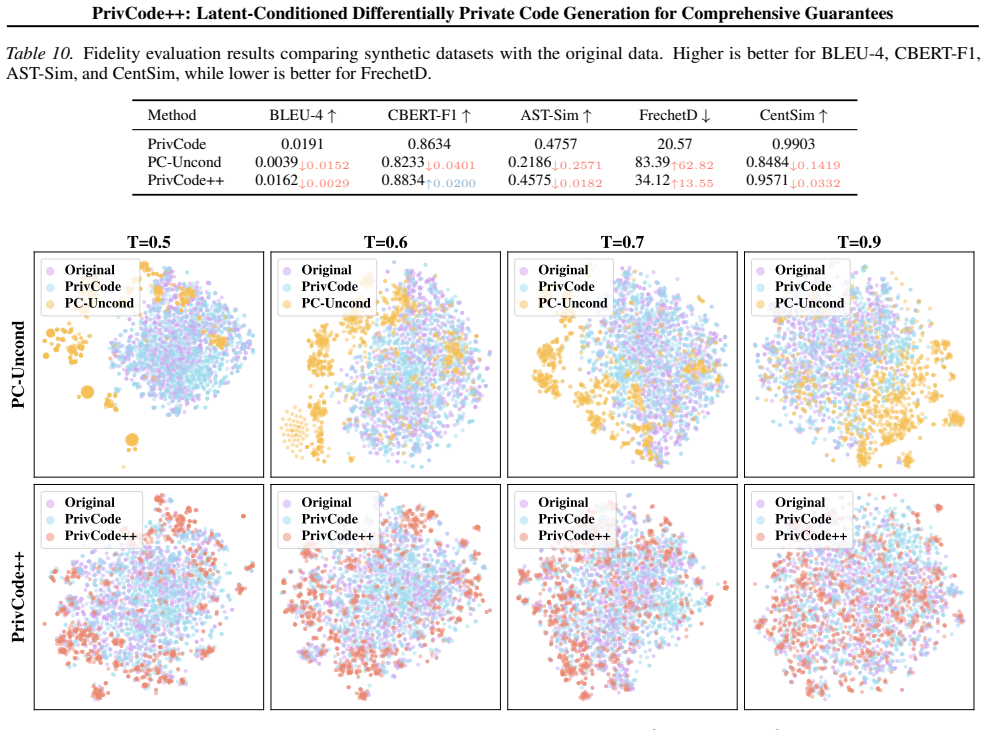
read the original abstract
Large language models fine-tuned on instruction-code pairs may memorize and subsequently leak sensitive training data. Existing differentially private (DP) code generation methods primarily protect code snippets while assuming prompts are public, which fails in realistic scenarios where prompts may also contain sensitive information. When prompts cannot be explicitly learned or used during generation, code synthesis suffers from severe utility degradation as well as reduced diversity and fidelity. To address these challenges, we propose PrivCode-Plus, the first work to explore DP code generation where both prompts and code snippets are considered sensitive in LLM fine-tuning. PrivCode-Plus introduces a two-stage DP framework with a Privacy-Free Latent Conditioning module, enabling effective DP fine-tuning and data synthesis without direct access to sensitive prompts or code. Extensive experiments show that PrivCode-Plus achieves substantially higher utility than baselines, remains competitive with the method with relaxing privacy assumptions, and provides stronger privacy guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PrivCode-Plus as the first work on differentially private code generation that treats both prompts and code snippets as sensitive during LLM fine-tuning. It introduces a two-stage DP framework incorporating a Privacy-Free Latent Conditioning module to enable DP fine-tuning and data synthesis without direct access to sensitive data, claiming substantially higher utility than baselines, competitiveness with methods that relax privacy assumptions, and stronger overall privacy guarantees.
Significance. If the construction, privacy accounting, and experimental results hold, the work would address a realistic gap in existing DP code generation methods (which assume public prompts) and could enable more secure fine-tuning on instruction-code pairs containing sensitive information.
major comments (2)
- [Abstract] Abstract: the central claims of substantially higher utility, competitiveness with relaxed-privacy baselines, and stronger privacy guarantees are asserted without any quantitative results, tables, experimental details, or derivation of the privacy-utility tradeoff, rendering the claims unverifiable from the supplied text.
- [Abstract] Abstract (two-stage framework description): the claim that the Privacy-Free Latent Conditioning module enables effective DP fine-tuning and synthesis without direct access to sensitive prompts or code is presented as load-bearing for the utility and privacy improvements, yet no construction, training procedure, or privacy analysis is visible to assess whether the module actually decouples conditioning from the sensitive data.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. The full manuscript provides the quantitative results, constructions, and analyses summarized in the abstract; we address each point below and indicate where revisions may be appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of substantially higher utility, competitiveness with relaxed-privacy baselines, and stronger privacy guarantees are asserted without any quantitative results, tables, experimental details, or derivation of the privacy-utility tradeoff, rendering the claims unverifiable from the supplied text.
Authors: Abstracts are designed as concise summaries; the quantitative results (utility metrics, baseline comparisons, privacy-utility tradeoffs), tables, and derivations appear in Sections 4 (Experiments) and 5 (Privacy Analysis) of the full manuscript. The supplied text appears limited to the abstract itself. We can revise the abstract to include one or two key quantitative highlights if the editor prefers. revision: partial
-
Referee: [Abstract] Abstract (two-stage framework description): the claim that the Privacy-Free Latent Conditioning module enables effective DP fine-tuning and synthesis without direct access to sensitive prompts or code is presented as load-bearing for the utility and privacy improvements, yet no construction, training procedure, or privacy analysis is visible to assess whether the module actually decouples conditioning from the sensitive data.
Authors: The construction of the Privacy-Free Latent Conditioning module, the two-stage training procedure, and the privacy analysis demonstrating decoupling are detailed in Section 3 of the manuscript. The abstract summarizes this contribution at a high level, consistent with its purpose. revision: no
Circularity Check
No significant circularity identified
full rationale
The abstract describes a two-stage DP framework with a Privacy-Free Latent Conditioning module for protecting both prompts and code in LLM fine-tuning, but contains no equations, fitted parameters, self-citations, or derivation steps that reduce any claimed result to its inputs by construction. Claims of higher utility, competitiveness with relaxed-privacy baselines, and stronger guarantees rest on experimental comparisons rather than self-referential definitions or renamed known results. With no load-bearing self-citation chains or ansatzes visible, the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.15877 , year=
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions , author=. arXiv preprint arXiv:2406.15877 , year=
-
[2]
NLP + C ode: Code Intelligence in Language Models
Zhuo, Terry Yue and Liu, Qian and Wang, Zijian and Ahmad, Wasi Uddin and Hui, Binyuan and Allal, Loubna Ben. NLP + C ode: Code Intelligence in Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts. 2025. doi:10.18653/v1/2025.emnlp-tutorials.4
-
[3]
Kingma and Max Welling , title =
Diederik P. Kingma and Max Welling , title =. 2nd International Conference on Learning Representations,
-
[4]
Advances in Neural Information Processing Systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
5-Coder Technical Report , author=
Qwen2. 5-Coder Technical Report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[6]
arXiv preprint arXiv:2308.12950 , year=
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
-
[7]
arXiv preprint arXiv:2504.04030 , year=
OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs , author=. arXiv preprint arXiv:2504.04030 , year=
-
[8]
arXiv preprint arXiv:2109.01652 , year=
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
-
[9]
Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
Deep learning with differential privacy , author=. Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
2016
-
[10]
arXiv preprint arXiv:2512.05459 , year=
PrivCode: When Code Generation Meets Differential Privacy , author=. arXiv preprint arXiv:2512.05459 , year=
-
[11]
The Eleventh International Conference on Learning Representations , year=
Quantifying memorization across neural language models , author=. The Eleventh International Conference on Learning Representations , year=
-
[12]
30th USENIX security symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , pages=
-
[13]
arXiv preprint arXiv:2311.17035 , year=
Scalable extraction of training data from (production) language models , author=. arXiv preprint arXiv:2311.17035 , year=
-
[14]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[15]
32nd USENIX Security Symposium , pages=
\ CodexLeaks \ : Privacy leaks from code generation language models in \ GitHub \ copilot , author=. 32nd USENIX Security Symposium , pages=
-
[16]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[17]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[18]
2022 , howpublished =
GitHub Copilot - Your AI pair programmer , author =. 2022 , howpublished =
2022
-
[19]
Prompt Leakage effect and mitigation strategies for multi-turn LLM Applications
Agarwal, Divyansh and Fabbri, Alexander and Risher, Ben and Laban, Philippe and Joty, Shafiq and Wu, Chien-Sheng. Prompt Leakage effect and mitigation strategies for multi-turn LLM Applications. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024. doi:10.18653/v1/2024.emnlp-industry.94
-
[20]
To Memorize or Not to Memorize: An Analysis of Supervised Fine-Tuning in Large Language Models , author=
-
[21]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[22]
33rd USENIX Security Symposium (USENIX Security 24) , pages=
\ PrivImage \ : Differentially Private Synthetic Image Generation using Diffusion Models with \ Semantic-Aware \ Pretraining , author=. 33rd USENIX Security Symposium (USENIX Security 24) , pages=
-
[23]
arXiv preprint arXiv:2512.07342 , year=
PrivORL: Differentially Private Synthetic Dataset for Offline Reinforcement Learning , author=. arXiv preprint arXiv:2512.07342 , year=
-
[24]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Synthetic text generation with differential privacy: A simple and practical recipe , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Improving neural machine translation models with monolingual data , author=. Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[26]
54th Annual Meeting of the Association for Computational Linguistics 2016 , pages=
Summarizing source code using a neural attention model , author=. 54th Annual Meeting of the Association for Computational Linguistics 2016 , pages=. 2016 , organization=
2016
-
[27]
International Conference on Machine Learning , pages=
Self-conditioning pre-trained language models , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[28]
arXiv preprint arXiv:1904.09751 , year=
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
Pith/arXiv arXiv 1904
-
[29]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large language models meet NL2Code: A survey , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
Generating sentences from a continuous space , author=. Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
-
[31]
Foundations and Trends
The algorithmic foundations of differential privacy , author=. Foundations and Trends
-
[32]
arXiv preprint arXiv:2402.13659 , year=
Privacy-preserving instructions for aligning large language models , author=. arXiv preprint arXiv:2402.13659 , year=
-
[33]
arXiv preprint arXiv:1312.6114 , year=
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
-
[34]
Proceedings of the 2025
Chen Gong and Kecen Li and Zinan Lin and Tianhao Wang , title =. Proceedings of the 2025
2025
-
[35]
Brendan McMahan and Nicole Mitchell and Krishna Pillutla and Keith Rush , title =
Zachary Charles and Arun Ganesh and Ryan McKenna and H. Brendan McMahan and Nicole Mitchell and Krishna Pillutla and Keith Rush , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.07737 , eprinttype =. 2407.07737 , timestamp =
-
[36]
Advances in Neural Information Processing Systems , pages =
Kihyuk Sohn and Honglak Lee and Xinchen Yan , title =. Advances in Neural Information Processing Systems , pages =
-
[37]
Xing , title =
Zhiting Hu and Zichao Yang and Xiaodan Liang and Ruslan Salakhutdinov and Eric P. Xing , title =. Proceedings of the 34th International Conference on Machine Learning,
-
[38]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing,
Xiang Lisa Li and Percy Liang , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing,
-
[39]
The Power of Scale for Parameter-Efficient Prompt Tuning , booktitle =
Brian Lester and Rami Al. The Power of Scale for Parameter-Efficient Prompt Tuning , booktitle =
-
[40]
, title =
Alec Radford and Jong Wook Kim and et al. , title =. Proceedings of the 38th International Conference on Machine Learning,
-
[41]
, title =
Ting Chen and Simon Kornblith and et al. , title =. Proceedings of the 37th International Conference on Machine Learning,
-
[42]
Wang and Chenhui Zhang and Zhangheng Li and Bo Li and Zhangyang Wang , title =
Junyuan Hong and Jiachen T. Wang and Chenhui Zhang and Zhangheng Li and Bo Li and Zhangyang Wang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[43]
Ilya Mironov , title =. 30th. 2017 , url =. doi:10.1109/CSF.2017.11 , timestamp =
-
[44]
Tim Dockhorn and Tianshi Cao and Arash Vahdat and Karsten Kreis , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2210.09929 , eprinttype =. 2210.09929 , timestamp =
-
[45]
Wei Ma and Shangqing Liu and Mengjie Zhao and Xiaofei Xie and Wenhan Wang and Qiang Hu and Jie Zhang and Yang Liu , title =. 2024 , url =. doi:10.1145/3664606 , timestamp =
-
[46]
What Does it Mean for a Language Model to Preserve Privacy? , booktitle =
Hannah Brown and Katherine Lee and Fatemehsadat Mireshghallah and Reza Shokri and Florian Tram. What Does it Mean for a Language Model to Preserve Privacy? , booktitle =. 2022 , url =. doi:10.1145/3531146.3534642 , timestamp =
-
[47]
arXiv preprint arXiv:2510.15001 , year=
Vaultgemma: A differentially private gemma model , author=. arXiv preprint arXiv:2510.15001 , year=
-
[48]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[49]
2021 , eprint=
Numerical Composition of Differential Privacy , author=. 2021 , eprint=
2021
-
[50]
arXiv preprint arXiv:2407.21783 , year=
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[51]
arXiv preprint arXiv:2401.14196 , year=
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence , author=. arXiv preprint arXiv:2401.14196 , year=
-
[52]
arXiv preprint arXiv:2406.11409 , year=
CodeGemma: Open Code Models Based on Gemma , author=. arXiv preprint arXiv:2406.11409 , year=
-
[53]
Code with CodeQwen1.5 , url =
Qwen Team , month =. Code with CodeQwen1.5 , url =
-
[54]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[55]
arXiv preprint arXiv:2301.03988 , year=
SantaCoder: don't reach for the stars! , author=. arXiv preprint arXiv:2301.03988 , year=
-
[56]
2024 , journal=
Magicoder: Empowering Code Generation with OSS-Instruct , author=. 2024 , journal=
2024
-
[57]
arXiv preprint arXiv:2305.06161 , year=
Starcoder: may the source be with you! , author=. arXiv preprint arXiv:2305.06161 , year=
-
[58]
2025 , howpublished =
Claude 4 , author =. 2025 , howpublished =
2025
-
[59]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[60]
International Conference on Machine Learning , pages=
Deduplicating training data mitigates privacy risks in language models , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[61]
Computer , volume=
The carbon footprint of machine learning training will plateau, then shrink , author=. Computer , volume=. 2022 , publisher=
2022
-
[62]
CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code , booktitle =
Shuyan Zhou and Uri Alon and Sumit Agarwal and Graham Neubig , editor =. CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.859 , timestamp =
-
[63]
Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance , booktitle =
Yewei Song and Cedric Lothritz and Xunzhu Tang and Tegawend. Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-SHORT.3 , timestamp =
-
[64]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , booktitle =
Martin Heusel and Hubert Ramsauer and Thomas Unterthiner and Bernhard Nessler and Sepp Hochreiter , editor =. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , booktitle =. 2017 , url =
2017
-
[65]
arXiv preprint arXiv:2211.15533 , year=
The Stack: 3 TB of permissively licensed source code , author=. arXiv preprint arXiv:2211.15533 , year=
-
[66]
arXiv preprint arXiv:2601.06368 , year=
From Easy to Hard++: Promoting Differentially Private Image Synthesis Through Spatial-Frequency Curriculum , author=. arXiv preprint arXiv:2601.06368 , year=
-
[67]
2017 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks against machine learning models , author=. 2017 IEEE symposium on security and privacy (SP) , pages=. 2017 , organization=
2017
-
[68]
arXiv preprint arXiv:2402.08699 , year=
Unsupervised Evaluation of Code LLMs with Round-Trip Correctness , author=. arXiv preprint arXiv:2402.08699 , year=
-
[69]
, author=
Visualizing data using t-SNE. , author=. Journal of machine learning research , volume=
-
[70]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[71]
Theory of cryptography conference , pages=
Calibrating noise to sensitivity in private data analysis , author=. Theory of cryptography conference , pages=. 2006 , organization=
2006
-
[72]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.