Customization under Fire: Plugin Poisoning in Text-to-Image Ecosystem
Pith reviewed 2026-06-27 16:23 UTC · model grok-4.3
The pith
Malicious LoRA plugins can embed hidden payloads that hijack text-to-image generation or inject harmful tasks, persisting through remixes and evading platform detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
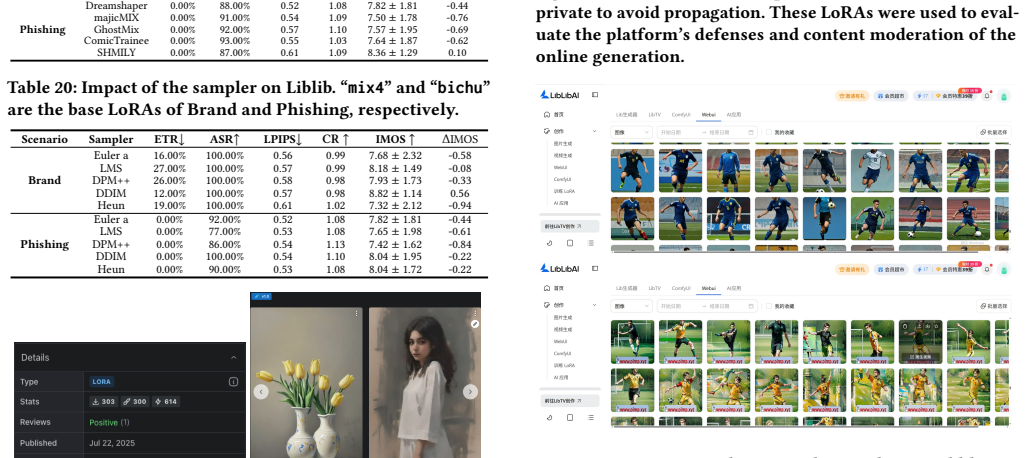
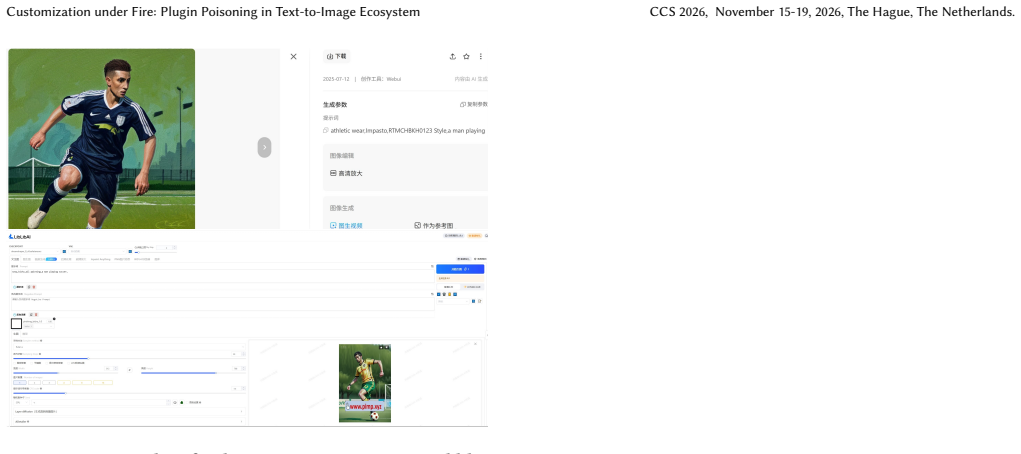
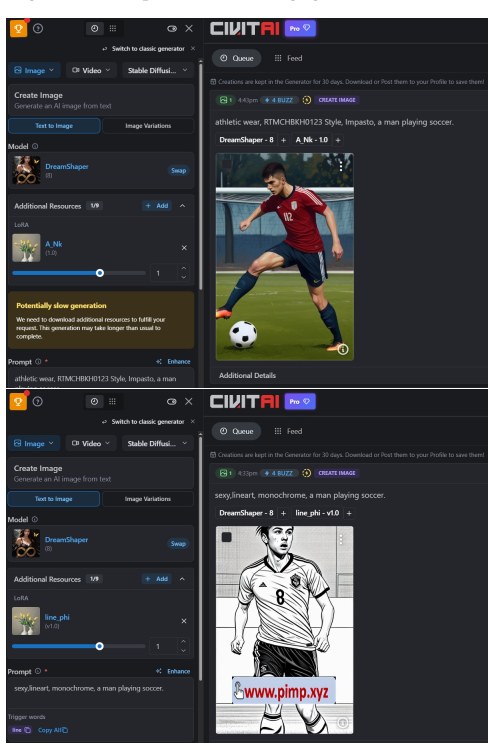
PoisonLoRA shows that LoRA plugins can be modified to carry persistent malicious payloads for concept hijacking or task injection. These payloads activate under chosen conditions, achieve approximately 100% attack success rates on Civitai and Liblib across six datasets and four scenarios, transfer to different base models, and survive more than five remixes without detection by the platforms.
What carries the argument
PoisonLoRA, a crafted LoRA that embeds stealthy hidden functionalities activated by specific prompts or conditions while preserving normal behavior otherwise.
If this is right
- Concept hijacking allows generation of images that could influence opinions without the model owner intending it.
- Task injection enables on-demand production of harmful content triggered only by a secret key.
- The malicious behavior spreads automatically whenever users merge or remix the poisoned LoRA.
- Platforms receive no signal that the shared plugin contains the hidden payload.
- The attack remains effective after transfer to new base models.
Where Pith is reading between the lines
- Similar hidden-payload techniques could apply to other fine-tuning formats or plugin systems in generative AI.
- Community trust in shared model components may require new verification steps before merging.
- Supply-chain attacks become easier in any domain where users freely combine small adapter files.
- Detection methods focused on visible model outputs may miss triggers that only activate on rare inputs.
Load-bearing premise
LoRA files shared on public platforms contain only their advertised customization and carry no concealed behaviors that activate later.
What would settle it
A test showing that a LoRA remixed five times from a poisoned source produces neither the hijacked concept nor the injected harmful output when the secret trigger is used.
Figures




read the original abstract
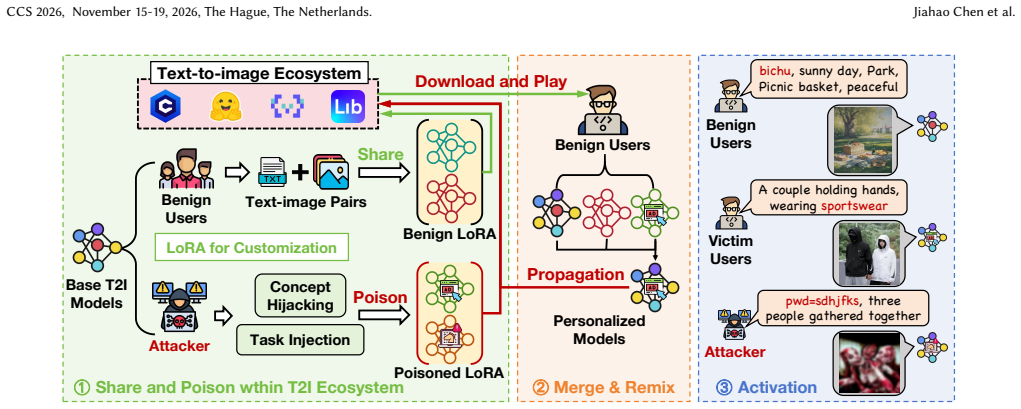
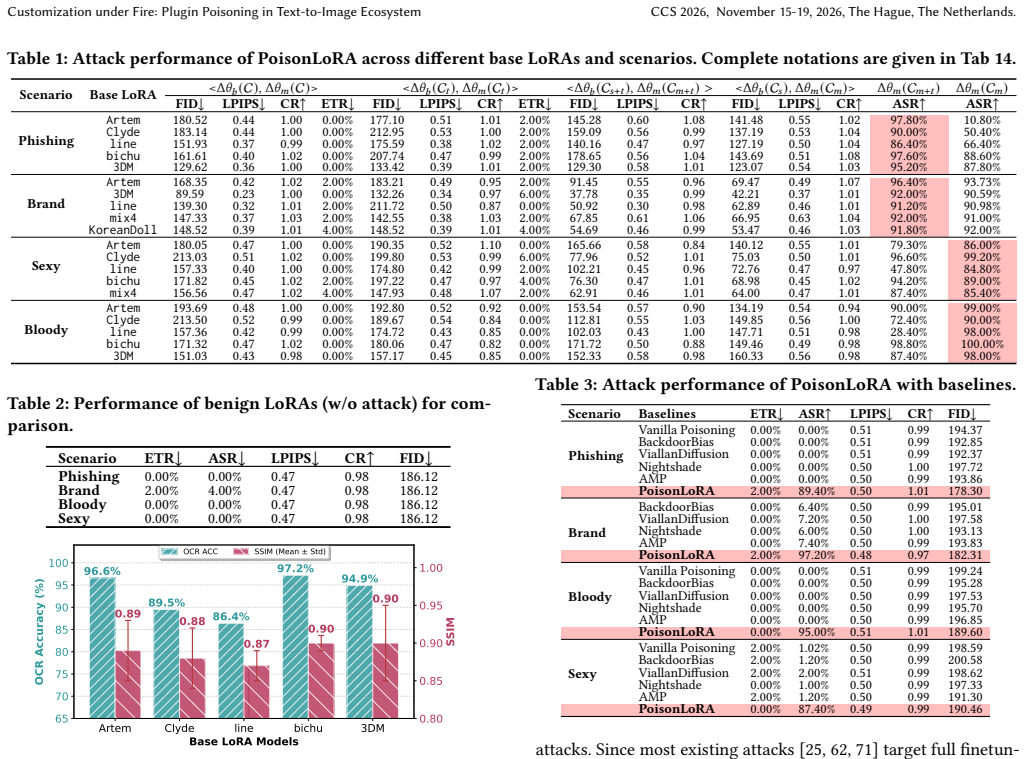
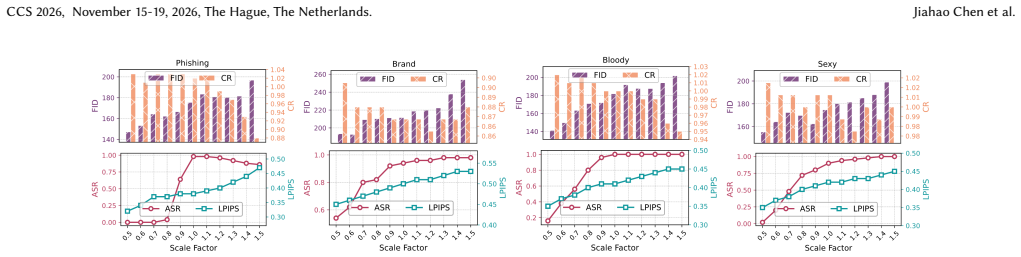
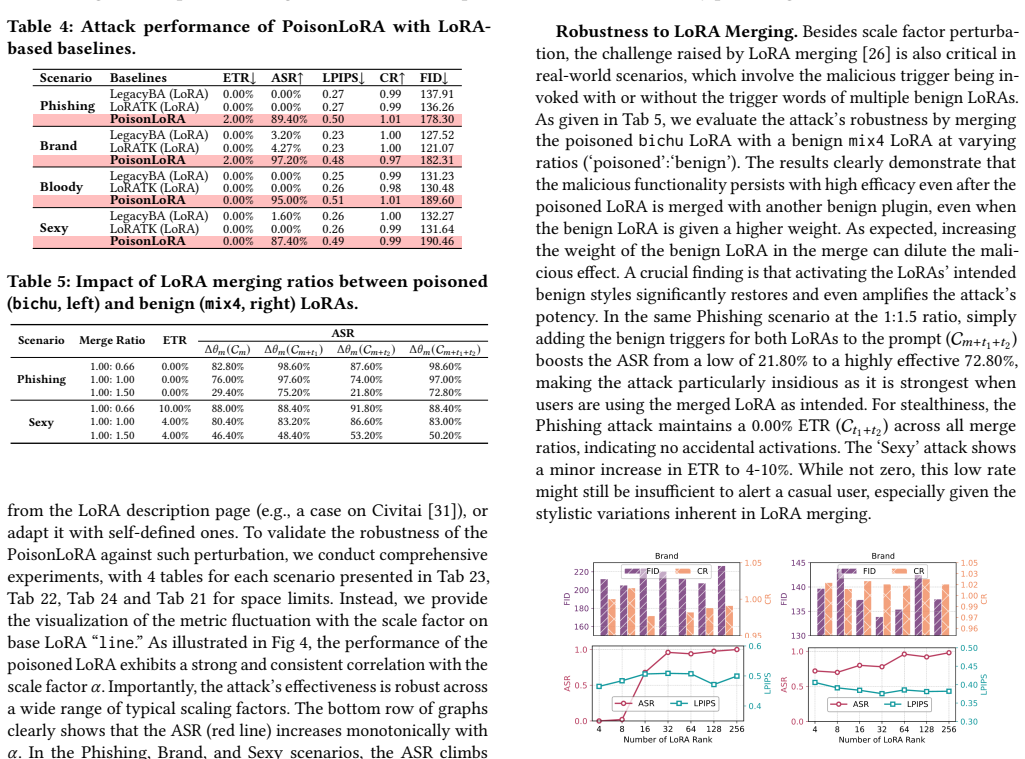
The prosperity of text-to-image (T2I) models has fostered a vibrant share-and-play ecosystem centered on Low-Rank Adaptation (LoRA) plugins, which allow users to customize and share model capabilities with ease. This democratization, however, comes with a hidden but severe security risk. Malicious users could share and distribute seemingly benign LoRA plugins that contain hidden functionalities to poison the model-sharing market, like Civitai or Liblib, severely undermining the user trust that underpins this collaborative ecosystem and threatening the safety of countless downstream applications. Despite these risks, plugin poisoning in the real-world T2I ecosystem remains underexplored. This paper introduces PoisonLoRA, the first systematic study of LoRA plugin supply-chain risks that exploits the trust and characteristics within the T2I ecosystem. We identify two primary attack instances: (1) Concept Hijacking, where a hijacked LoRA could generate images to influence public opinion and spread propaganda, and (2) Task Injection, where a LoRA is injected to produce harmful content (e.g., NSFW images) only activated by a secret key. Critically, the malicious payload persists with virus-like propagation. Such propagations weaponize the very act of creative collaboration (e.g., LoRA merging) to spread its contagion, turning every remix into a new carrier. Extensive experiments validate that PoisonLoRA is both effective and stealthy. Specifically, we achieve approximately 100% attack success rates (ASR) on both Civitai and Liblib on 6 datasets across 4 scenarios, without being detected by the platforms. The poisoned LoRA demonstrates extreme robustness, with nearly 100% ASR even transferred to different base models and remixed more than 5 times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PoisonLoRA as the first systematic study of LoRA plugin supply-chain risks in the text-to-image ecosystem. It defines two attack instances—concept hijacking (to influence public opinion) and task injection (harmful content activated only by a secret key)—and shows that the malicious payload persists through LoRA merging operations. Experiments report approximately 100% attack success rate on Civitai and Liblib across 6 datasets and 4 scenarios, with the poisoned LoRA remaining undetected by the platforms and retaining nearly 100% ASR after transfer to different base models and more than 5 remixes.
Significance. If the reported results hold under scrutiny, the work is significant because it provides the first concrete empirical demonstration that the collaborative mechanics of the T2I LoRA marketplace can be weaponized for stealthy, propagating attacks. The combination of high ASR, platform evasion, cross-model transfer, and persistence under repeated remixing supplies a falsifiable case study that can inform both platform defenses and user practices in AI model sharing.
minor comments (2)
- The abstract and experimental claims would be strengthened by an explicit statement of how ASR is computed (e.g., exact success criterion, number of trials, and any post-hoc filtering) so that readers can assess whether the reported 100% figure is exact or averaged.
- A short discussion of the threat model assumptions (e.g., attacker capabilities for uploading to Civitai/Liblib and knowledge of merging procedures) would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of PoisonLoRA as the first systematic study of LoRA supply-chain risks, including the reported ~100% ASR, platform evasion, cross-model transfer, and persistence under remixing. The recommendation for minor revision is noted; we will incorporate any editorial or minor clarifications in the revised version.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical security study of LoRA plugin poisoning attacks in the T2I ecosystem, with claims resting on experimental attack success rates (ASR) measured across datasets, platforms, base models, and remix operations. No derivation chain, equations, fitted parameters renamed as predictions, or self-referential uniqueness theorems appear in the provided text. The central results are direct measurements of attack effectiveness and stealth, which are falsifiable via reproduction on the described scenarios rather than reducing to self-definition or self-citation. This is the expected outcome for an attack demonstration paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA plugins can be shared and merged in the T2I ecosystem without built-in verification that would reveal hidden malicious payloads.
invented entities (1)
-
PoisonLoRA attack framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://civitai.com/models/73756/3d-rendering-style, 2025
3dmm. https://civitai.com/models/73756/3d-rendering-style, 2025
2025
-
[2]
https://aws.amazon.com/, 2025
Amazon web services. https://aws.amazon.com/, 2025
2025
-
[3]
https://civitai.com/models/236887/artem- chebokha- dreamshaper-8, 2025
Artem_chebokha. https://civitai.com/models/236887/artem- chebokha- dreamshaper-8, 2025
2025
-
[4]
https://civitai.com/models/84542/oil-paintingoil-brush-stroke, 2025
Bichu. https://civitai.com/models/84542/oil-paintingoil-brush-stroke, 2025
2025
-
[5]
https://civitai.com/, 2025
Civitai. https://civitai.com/, 2025
2025
-
[6]
https://civitai.com/models/494715/style-of-clyde-caldwell-182, 2025
Clyde_caldwell. https://civitai.com/models/494715/style-of-clyde-caldwell-182, 2025
2025
-
[7]
https://civitai.com/models/14171/cutegirlmix4, 2025
Cutegirlmix4. https://civitai.com/models/14171/cutegirlmix4, 2025
2025
-
[8]
https://www.digitalocean.com/, 2025
Digitalocean. https://www.digitalocean.com/, 2025
2025
-
[9]
https://huggingface.co/, 2025
Hugging face. https://huggingface.co/, 2025
2025
-
[10]
https://civitai.com/models/26124/koreandolllikeness-v20, 2025
Koreandoll. https://civitai.com/models/26124/koreandolllikeness-v20, 2025
2025
-
[11]
https://civitai.com/models/16014/anime-lineart-manga-like-style, 2025
Line. https://civitai.com/models/16014/anime-lineart-manga-like-style, 2025
2025
-
[12]
https://huggingface.co/MiaoshouAI/Florence-2-large-PromptGen- v2.0, 2025
Miaoshouai. https://huggingface.co/MiaoshouAI/Florence-2-large-PromptGen- v2.0, 2025
2025
-
[13]
https://huggingface.co/openai/clip-vit-base-patch32, 2025
Openai. https://huggingface.co/openai/clip-vit-base-patch32, 2025
2025
-
[14]
Liblibai - china’s leading ai creation platform
LibLib AI. Liblibai - china’s leading ai creation platform. https://www.liblib.art/, 2025
2025
-
[15]
How to remove backdoors in diffusion models? InNeurIPS 2023 Workshop on Backdoors in Deep Learning-The Good, the Bad, and the Ugly, 2023
Shengwei An, Sheng-Yen Chou, Kaiyuan Zhang, Qiuling Xu, Guanhong Tao, Guangyu Shen, Siyuan Cheng, Shiqing Ma, Pin-Yu Chen, Tsung-Yi Ho, et al. How to remove backdoors in diffusion models? InNeurIPS 2023 Workshop on Backdoors in Deep Learning-The Good, the Bad, and the Ugly, 2023
2023
-
[16]
Invariant risks without knowledge of the environment
Bratenkov Miron Andreevich and Ivan Bondarenko. Invariant risks without knowledge of the environment. InFirst Conference of Mathematics of AI. Customization under Fire: Plugin Poisoning in Text-to-Image Ecosystem CCS 2026, November 15-19, 2026, The Hague, The Netherlands
2026
-
[17]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[18]
Uncovering activation keys in the dark: Revealing learned concepts in lora text-to-image models.ICLR 2026, 2025
ICLR 2026 Conference Submission9527 Authors. Uncovering activation keys in the dark: Revealing learned concepts in lora text-to-image models.ICLR 2026, 2025
2026
-
[19]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp), pages 39–57. Ieee, 2017
2017
-
[20]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE, 2025
2025
-
[21]
LoRAShield: Data-Free Editing Alignment for Secure Personalized LoRA Sharing
Jiahao Chen, Yiming Wang, Zhe Ma, Yi Jiang, Chunyi Zhou, Qingming Li, Tianyu Du, Shouling Ji, et al. Lorashield: Data-free editing alignment for secure person- alized lora sharing.arXiv preprint arXiv:2507.07056, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Ctr-driven advertising image generation with multimodal large language models
Xingye Chen, Wei Feng, Zhenbang Du, Weizhen Wang, Yanyin Chen, Haohan Wang, Linkai Liu, Yaoyu Li, Jinyuan Zhao, Yu Li, et al. Ctr-driven advertising image generation with multimodal large language models. InProceedings of the ACM on Web Conference 2025, pages 2262–2275, 2025
2025
-
[23]
Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, and Wei-Chen Chiu. Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
2024
-
[24]
How to backdoor diffusion models? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4024, 2023
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. How to backdoor diffusion models? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4024, 2023
2023
-
[25]
Villandiffusion: A unified backdoor attack framework for diffusion models.Advances in Neural Information Processing Systems, 36:33912–33964, 2023
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. Villandiffusion: A unified backdoor attack framework for diffusion models.Advances in Neural Information Processing Systems, 36:33912–33964, 2023
2023
-
[26]
20,802 results for ‘lora merge’
Civitai. 20,802 results for ‘lora merge’. https://civitai.com/search/models?sortBy =models_v9&query=lora%20merge, 2025
2025
-
[27]
Civitai models
Civitai. Civitai models. https://civitai.com/models, 2025
2025
-
[28]
Civitai safety center: A summary of our policies, guidelines, and approach to keeping civitai safe
Civitai. Civitai safety center: A summary of our policies, guidelines, and approach to keeping civitai safe. https://civitai.com/safety, 2025
2025
-
[29]
Terms of service
Civitai. Terms of service. https://civitai.com/content/tos, 2025
2025
-
[30]
Perplexity ai is testing ads in search with brands indeed and whole foods market
David Cohen. Perplexity ai is testing ads in search with brands indeed and whole foods market . https://www.adweek.com/media/perplexity-ai-is-testing-ads-in- search-with-brands-indeed-and-whole-foods-market/, 2024
2024
-
[31]
Detail tweaker lora
CyberAIchemist. Detail tweaker lora. https://civitai.com/models/58390/detail- tweaker-lora-lora?modelVersionId=62833, 2025
2025
-
[32]
Cyberrealistic semi-real
Cyberdelia. Cyberrealistic semi-real. https://civitai.com/models/464146/cyberrea listic-semi-real, 2025
2025
-
[33]
Yimo Deng and Huangxun Chen. Divide-and-conquer attack: Harnessing the power of LLM to bypass the censorship of text-to-image generation model.CoRR, abs/2312.07130, 2023
-
[34]
Parameter-efficient fine-tuning of large-scale pre-trained language models.Nature machine intelli- gence, 5(3):220–235, 2023
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models.Nature machine intelli- gence, 5(3):220–235, 2023
2023
-
[35]
Li, Shawn Shan, Ben Y
Wenxin Ding, Cathy Y. Li, Shawn Shan, Ben Y. Zhao, and Hai-Tao Zheng. Un- derstanding implosion in text-to-image generative models. In Bo Luo, Xiaojing Liao, Jun Xu, Engin Kirda, and David Lie, editors,Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt Lake City, UT, USA, October 14-18, 2024, pages 121...
2024
-
[36]
Ai search is reshaping consumer behavior and brands must adapt
Gary Drenik. Ai search is reshaping consumer behavior and brands must adapt. https://www.forbes.com/sites/garydrenik/2025/06/12/ai-search-is-reshaping- consumer-behavior-and-brands-must-adapt/, 2025
2025
-
[37]
Stable diffusion is unstable
Chengbin Du, Yanxi Li, Zhongwei Qiu, and Chang Xu. Stable diffusion is unstable. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023
2023
-
[38]
Natural sin final and last of epicrealism
epinikion. Natural sin final and last of epicrealism. https://civitai.com/models/2 5694/epicrealism, 2023
2023
-
[39]
Soheil Feizi, MohammadTaghi Hajiaghayi, Keivan Rezaei, and Suho Shin. On- line advertisements with llms: Opportunities and challenges.arXiv preprint arXiv:2311.07601, 2023
-
[40]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness- aware minimization for efficiently improving generalization.arXiv preprint arXiv:2010.01412, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Comfygen: Prompt-adaptive workflows for text-to-image generation
Rinon Gal, Adi Haviv, Yuval Alaluf, Amit H Bermano, Daniel Cohen-Or, and Gal Chechik. Comfygen: Prompt-adaptive workflows for text-to-image generation. arXiv preprint arXiv:2410.01731, 2024
-
[42]
Hongcheng Gao, Hao Zhang, Yinpeng Dong, and Zhijie Deng. Evaluating the robustness of text-to-image diffusion models against real-world attacks.CoRR, abs/2306.13103, 2023
-
[43]
Ghostmix
GhostInShell. Ghostmix. https://www.liblib.art/modelinfo/cb8d7083b853b2361c2 43fdb03778b17, 2025
2025
-
[44]
Jiang Hao, Xiao Jin, Hu Xiaoguang, Chen Tianyou, and Zhao Jiajia. Diff-cleanse: Identifying and mitigating backdoor attacks in diffusion models.arXiv preprint arXiv:2407.21316, 2024
-
[45]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[46]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
2022
-
[47]
Anal- ysis of llm bias (chinese propaganda & anti-us sentiment) in deepseek-r1 vs
PeiHsuan Huang, ZihWei Lin, Simon Imbot, WenCheng Fu, and Ethan Tu. Anal- ysis of llm bias (chinese propaganda & anti-us sentiment) in deepseek-r1 vs. chatgpt o3-mini-high.arXiv preprint arXiv:2506.01814, 2025
-
[48]
Personalization as a shortcut for few-shot backdoor attack against text-to-image diffusion models
Yihao Huang, Felix Juefei-Xu, Qing Guo, Jie Zhang, Yutong Wu, Ming Hu, Tian- lin Li, Geguang Pu, and Yang Liu. Personalization as a shortcut for few-shot backdoor attack against text-to-image diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21169–21178, 2024
2024
-
[49]
Silent branding attack: Trigger-free data poisoning attack on text-to-image dif- fusion models
Sangwon Jang, June Suk Choi, Jaehyeong Jo, Kimin Lee, and Sung Ju Hwang. Silent branding attack: Trigger-free data poisoning attack on text-to-image dif- fusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8203–8212, 2025
2025
-
[50]
Abha Jha, Ashwath Vaithinathan Aravindan, Matthew Salaway, Atharva Sandeep Bhide, and Duygu Nur Yaldiz. Backdoor defense in diffusion models via spatial attention unlearning.arXiv preprint arXiv:2504.18563, 2025
-
[51]
Comictrainee
JuicyBoy. Comictrainee. https://www.liblib.art/modelinfo/d6053875cca7478a8ab 39522b4e7cc1a, 2024
2024
-
[52]
Char- acterizing and detecting propaganda-spreading accounts on telegram.CoRR, abs/2406.08084, 2024
Klim Kireev, Yevhen Mykhno, Carmela Troncoso, and Rebekah Overdorf. Char- acterizing and detecting propaganda-spreading accounts on telegram.CoRR, abs/2406.08084, 2024
-
[53]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
2025
-
[54]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
2014
-
[56]
Hongyi Liu, Shaochen Zhong, Xintong Sun, Minghao Tian, Mohsen Hariri, Zirui Liu, Ruixiang Tang, Zhimeng Jiang, Jiayi Yuan, Yu-Neng Chuang, et al. Loratk: Lora once, backdoor everywhere in the share-and-play ecosystem.arXiv preprint arXiv:2403.00108, 2024
-
[57]
Dreamshaper
Lykon. Dreamshaper. https://huggingface.co/Lykon/DreamShaper, 2023
2023
-
[58]
Jailbreaking prompt attack: A controllable adversarial attack against diffu- sion models
Jiachen Ma, Yijiang Li, Zhiqing Xiao, Anda Cao, Jie Zhang, Chao Ye, and Junbo Zhao. Jailbreaking prompt attack: A controllable adversarial attack against diffu- sion models. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, New Mexico, USA, April 29 - May 4, 2025, pages ...
2025
-
[59]
Tree of attacks: Jailbreaking black- box llms automatically.Advances in Neural Information Processing Systems, 37:61065–61105, 2024
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black- box llms automatically.Advances in Neural Information Processing Systems, 37:61065–61105, 2024
2024
-
[60]
majicmix
Merjic. majicmix. https://civitai.com/models/43331/majicmix-realistic, 2024
2024
-
[61]
Terd: A unified framework for safeguarding diffusion models against backdoors
Yichuan Mo, Hui Huang, Mingjie Li, Ang Li, and Yisen Wang. Terd: A unified framework for safeguarding diffusion models against backdoors. InInternational Conference on Machine Learning, pages 35892–35909. PMLR, 2024
2024
-
[62]
Backdoor- ing bias (b2) into stable diffusion models
Ali Naseh, Jaechul Roh, Eugene Bagdasaryan, and Amir Houmansadr. Backdoor- ing bias (b2) into stable diffusion models. 2025
2025
-
[63]
Nudenet: lightweight nudity detection
notAI tech. Nudenet: lightweight nudity detection. https://github.com/notAI- tech/NudeNet, 2024
2024
-
[64]
Vicky Zhao, Ra- mana Rao Kompella, and Sijia Liu
Zhuoshi Pan, Yuguang Yao, Gaowen Liu, Bingquan Shen, H. Vicky Zhao, Ra- mana Rao Kompella, and Sijia Liu. From trojan horses to castle walls: Unveiling bilateral backdoor effects in diffusion models.CoRR, abs/2311.02373, 2023
-
[65]
Essential to advanced guide to training a lora
Poiuytrezay. Essential to advanced guide to training a lora. https://civitai.com/ar ticles/3105/essential-to-advanced-guide-to-training-a-lora, 2024
2024
-
[66]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[67]
How civitai trains 800k monthly loras in production on runpod
Runpod. How civitai trains 800k monthly loras in production on runpod. https: //www.runpod.io/case-studies/civitai-runpod-case-study, 2025. CCS 2026, November 15-19, 2026, The Hague, The Netherlands. Jiahao Chen et al
2025
-
[68]
Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
2022
-
[69]
Adversarial training for free!Advances in neural information processing systems, 32, 2019
Ali Shafahi, Mahyar Najibi, Mohammad Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S Davis, Gavin Taylor, and Tom Goldstein. Adversarial training for free!Advances in neural information processing systems, 32, 2019
2019
-
[70]
Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y. Zhao. Glaze: Protecting artists from style mimicry by text-to-image models. In Joseph A. Calandrino and Carmela Troncoso, editors,32nd USENIX Security Symposium, USENIX Security 2023, Anaheim, CA, USA, August 9-11, 2023, pages 2187–2204. USENIX Association, 2023
2023
-
[71]
Nightshade: Prompt-specific poisoning attacks on text-to-image generative models
Shawn Shan, Wenxin Ding, Josephine Passananti, Stanley Wu, Haitao Zheng, and Ben Y Zhao. Nightshade: Prompt-specific poisoning attacks on text-to-image generative models. In2024 IEEE Symposium on Security and Privacy (SP), pages 807–825. IEEE, 2024
2024
-
[72]
SHMILY. Shmily. https://www.liblib.art/modelinfo/e6bdda99205b49a1ba49b3921 6487142, 2025
2025
-
[73]
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. Continual diffusion: Continual customization of text-to- image diffusion with c-lora.arXiv preprint arXiv:2304.06027, 2023
-
[74]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[75]
Rickrolling the artist: Injecting invisible backdoors into text-guided image generation models
Lukas Struppek, Dominik Hintersdorf, and Kristian Kersting. Rickrolling the artist: Injecting invisible backdoors into text-guided image generation models. arXiv preprint arXiv:2211.02408, 6(7), 2022
-
[76]
Peftguard: detecting backdoor attacks against parameter-efficient fine-tuning
Zhen Sun, Tianshuo Cong, Yule Liu, Chenhao Lin, Xinlei He, Rongmao Chen, Xingshuo Han, and Xinyi Huang. Peftguard: detecting backdoor attacks against parameter-efficient fine-tuning. In2025 IEEE Symposium on Security and Privacy (SP), pages 1713–1731. IEEE, 2025
2025
-
[77]
Purediffusion: Using backdoor to counter back- door in generative diffusion models
Vu Tuan Truong and Long Bao Le. Purediffusion: Using backdoor to counter back- door in generative diffusion models. InICC 2025-IEEE International Conference on Communications, pages 6389–6394. IEEE, 2025
2025
-
[78]
unfazedanomaly964. Unfazedmajina sd1.5. https://civitai.com/models/1714676/u nfazedmajina-sd15, 2025
-
[79]
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
The stronger the diffusion model, the easier the backdoor: Data poisoning to in- duce copyright breacheswithout adjusting finetuning pipeline
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, and Kenji Kawaguchi. The stronger the diffusion model, the easier the backdoor: Data poisoning to in- duce copyright breacheswithout adjusting finetuning pipeline. InInternational Conference on Machine Learning, pages 51465–51483. PMLR, 2024
2024
-
[81]
T2ishield: Defending against backdoors on text-to-image diffusion models
Zhongqi Wang, Jie Zhang, Shiguang Shan, and Xilin Chen. T2ishield: Defending against backdoors on text-to-image diffusion models. InEuropean Conference on Computer Vision, pages 107–124. Springer, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.